
Hadoop HDFS و NoSQL: مزيج قوي للبيانات الضخمة
نشرت: 2023-01-05Hadoop هو إطار عمل مفتوح المصدر يسمح بالمعالجة الموزعة لمجموعات البيانات الكبيرة عبر مجموعات من أجهزة الكمبيوتر باستخدام نموذج برمجة بسيط. HDFS هو نظام الملفات الموزعة Hadoop الذي يوفر طريقة قابلة للتطوير وتتحمل الأخطاء لتخزين البيانات. قواعد بيانات NoSQL هي فئة جديدة من قواعد البيانات المصممة لتوفير بديل قابل للتطوير ومرن وعالي الأداء لقواعد البيانات العلائقية التقليدية.
يتمثل الاختلاف الأساسي بين Hadoop و HDFS في أن Hadoop هو إطار عمل مفتوح المصدر لتخزين البيانات ومعالجتها وتحليلها ، في حين أن HDFS هو نظام ملفات يسمح للمستخدمين بالوصول إلى بيانات Hadoop. نتيجة لذلك ، HDFS هي وحدة Hadoop .
يمكن لكل من SQL و Hadoop إدارة البيانات بطرق مختلفة. يتم استخدام إطار عمل Hadoop لتجميع مكونات البرامج ، بينما يتم استخدام إطار عمل SQL لتجميع قواعد البيانات. بالنسبة للبيانات الضخمة ، من الأهمية بمكان مراعاة إيجابيات وسلبيات كل أداة. تقوم منصة Hadoop بتخزين البيانات مرة واحدة فقط ، بينما يقوم Hadoop بتخزين عدد أكبر بكثير من مجموعات البيانات.
Hadoop ليست قاعدة بيانات ، بل هي جزء من البرنامج الذي يسمح بالحوسبة المتوازية الضخمة. تسمح هذه التقنية لقواعد بيانات NoSQL (مثل HBase) بنشر البيانات عبر آلاف الخوادم مع تدهور ضئيل في الأداء.
لا يقوم Hadoop بتخزين البيانات بنفس طريقة تخزين البيانات الارتباطية. الخادم الموزع هو أحد التطبيقات الأكثر استخدامًا له. على الرغم من أنها قاعدة بيانات Hadoop ، إلا أنها غير مؤهلة كقاعدة بيانات علائقية لأنها تخزن الملفات في HDFS (نظام الملفات الموزعة).
ما هو الفرق بين Nosql و Hdfs؟
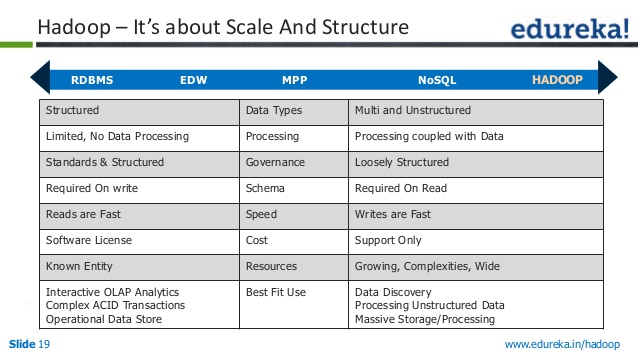
إنه نظام ملفات ، ويشار إليه أيضًا باسم نظام الملفات. من الواضح بالفعل أن هذا التطبيق يقدم عددًا من الميزات. من أين تحصل على أشياء NOSQL هذه؟ سنكون قادرين على معالجة كميات كبيرة من البيانات في الوقت الفعلي باستخدامها لأنها لا تتطلب منا استخدام قواعد البيانات العلائقية أو الميزات الأخرى.
يوفر مدير التخزين HBase ، الذي يعمل في Hadoop ، عمليات قراءة وكتابة عشوائية بزمن انتقال منخفض. يستخدم نظام HBase ميزة التجزئة التلقائية التي يتم فيها توزيع الجداول الكبيرة ديناميكيًا. كل خادم منطقة مسؤول عن خدمة مجموعة من المناطق ، ولا يوجد سوى خادم منطقة واحد قادر على خدمة منطقة واحدة (على سبيل المثال ، HMaster و HRegion هما خدمتان رئيسيتان توفرهما HBase. مكون HRegion لجدول HBase مسؤول عن التعامل مجموعات فرعية من بيانات الجدول. عند بدء تشغيل خادم المنطقة ، يتم تعيينه لكل منطقة. ونتيجة لذلك ، لا يشارك الرئيسي في عمليات القراءة والكتابة.
عندما يتعلق الأمر بالتعامل مع البيانات الضخمة وغير المنظمة ، فإن قواعد بيانات NoSQL مثل MongoDB و Cassandra تبرز على قواعد البيانات العلائقية التقليدية. تفضل الشركات التي لديها أعباء عمل كبيرة للبيانات ، مثل البيانات الضخمة ، استخدام هذه الأدوات لمعالجة وتحليل كميات هائلة من البيانات المتنوعة وغير المنظمة بسرعة. يقوم MongoDB بتخزين البيانات في مجموعات ، بينما يقوم hadoop بتخزين البيانات في نظام ملفات مختلف يُعرف باسم HDFS. من المفيد أن يكون لديك بنية مختلفة نتيجة لهذا الاختلاف. كما أن الاستعلام عن البيانات في MongoDB أسرع بكثير من البحث في الملفات الفردية. علاوة على ذلك ، نظرًا لأن mongodb مصمم للبيئات ذات الحجم الكبير ، فهو مناسب تمامًا للتعامل مع كميات كبيرة من البيانات بتكلفة منخفضة نسبيًا. يوصى بأن تستخدم الشركات التي تتطلب حلول البيانات الضخمة قواعد بيانات NoSQL. لديهم مزايا عديدة مقارنة بقواعد البيانات التقليدية من حيث سرعة المعالجة والتحليلات ، وهي مناسبة تمامًا لتحليل البيانات وإدارتها على نطاق واسع.
هل Hadoop قاعدة بيانات Nosql؟
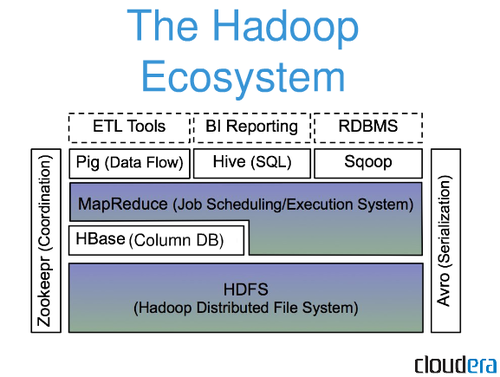
Hadoop ليس نظامًا تقليديًا لإدارة قواعد البيانات الارتباطية. إنه نظام ملفات موزع يساعد على تخزين مجموعات البيانات الكبيرة ومعالجتها عبر مجموعة من خوادم السلع. تم تصميم Hadoop للارتقاء من الخوادم الفردية إلى آلاف الأجهزة ، كل منها يقدم عمليات الحوسبة والتخزين المحلية.
يتم إحداث ثورة في استخدام البيانات على نطاق هائل من خلال التقنيات الجديدة. تحتوي البنية التحتية للبيانات الضخمة على العديد من اللاعبين ، بما في ذلك Hadoop و NoSQL و Spark. يعمل مسؤولو قواعد البيانات ومهندسو / مطورو البنية التحتية الآن لصالحهم لإدارة الأنظمة المعقدة في سلالة جديدة من مسؤولي قواعد البيانات ومهندسي البنية التحتية. نظرًا لأن Hadoop هو نظام بيئي للبرامج وليس قاعدة بيانات ، فإنه يسمح بحساب كميات هائلة من البيانات بمعدل فعال وفعال. كانت الفوائد التي يوفرها للكميات الهائلة من البيانات التي تتعامل معها بمثابة تغيير في قواعد اللعبة لمعالجة البيانات الضخمة. يمكن إكمال معاملة البيانات الكبيرة ، مثل تلك التي تستغرق 20 ساعة لإكمالها على نظام قاعدة بيانات ارتباطية مركزية ، في ثلاث دقائق فقط على مجموعة Hadoop.
هناك أكثر من لغة SQL للاختيار من بينها. MongoDB ، قاعدة بيانات المستندات الخالصة ، هي نوع واحد من قواعد بيانات NoSQL ؛ كاساندرا ، قاعدة بيانات ذات عمود عريض ، هي قاعدة بيانات أخرى. و Neo4j ، قاعدة بيانات الرسم البياني ، هي قاعدة أخرى. تم إنشاء هذه الميزة بواسطة SQL- on- Hadoop . SQL-on-Hadoop هي فئة جديدة من الأدوات التحليلية التي تجمع بين استعلامات SQL المنشأة وأطر بيانات Hadoop. يسمح SQL-on- Hadoop لمطوري المؤسسات ومحللي الأعمال بالتعاون مع Hadoop في مجموعات حوسبة السلع من خلال السماح بتشغيل استعلامات SQL المألوفة. مزايا SQL-on-hadoop. مزايا SQL-on- Hadoop العديدة ، بالإضافة إلى سهولة استخدامها ، تستحق وقت وموارد مطوري ومحللي بيانات المؤسسة. للبدء ، يمكنهم العمل مع Hadoop على مجموعات حوسبة السلع ، والتي ستسمح لهم بالبدء بسرعة وسهولة في تحليلات البيانات الضخمة. يسمح SQL-on-Hadoop لهم أيضًا بالاستفادة من استعلامات SQL المألوفة ، مما يسهل عليهم تعلم تحليلات البيانات الضخمة. علاوة على ذلك ، يوفر SQL-on-Hadoop خريطة Hadoop / تقليل الوظائف بالإضافة إلى إمكانات تحليل البيانات الغنية التي يوفرها.
قواعد بيانات نوصل في صعود
نتيجة لذلك ، أصبحت قواعد بيانات NoSQL أكثر شيوعًا بسبب قابليتها للتوسع وأداء القراءة / الكتابة ومرونة البيانات. هناك العديد من الأمثلة الجيدة لقواعد بيانات NoSQL في السوق ، بما في ذلك DynamoDB و Riak و Redis.
Hive هي قاعدة بيانات NoSQL خفيفة الوزن ومعيارية مع مقاييس أداء ممتازة. إنه مكتوب بلغة برمجة Dart النقية وهو مشهور بين المطورين بسبب بساطته.
ما هو الفرق بين Hadoop وقاعدة البيانات؟

بينما لا يقوم نظام RDBMS بتخزين البيانات ومعالجتها ، فإن Hadoop يقوم بتخزين البيانات ومعالجتها كنظام ملفات موزع. من ناحية أخرى ، فإن RDBMS عبارة عن قاعدة بيانات منظمة تخزن البيانات في صفوف وأعمدة ويمكن تحديثها باستخدام SQL وتقديمها في مجموعة متنوعة من الجداول.
نما اعتماد تقنيات وأدوات البيانات الضخمة بوتيرة سريعة. يعمل توزيع Hadoop مفتوح المصدر على نظام ملفات موزع ويسمح بتبادل ومعالجة مجموعات البيانات الكبيرة. يعد RDB نظامًا أساسيًا لإدارة قواعد البيانات يتم استخدامه في أبسط أشكال أنظمة إدارة قواعد البيانات مثل Microsoft SQL Server و Oracle و MySQL. على الرغم من تصنيفها على أنها تطور ، فإن نظام RDBMS يشبه إلى حد كبير أي قاعدة بيانات قياسية أخرى وليس مهمة رئيسية. إنها ليست قاعدة بيانات ، بل هي نظام ملفات موزع يمكنه استضافة ومعالجة مجموعات كبيرة من ملفات البيانات. على الرغم من أن أنظمة مثل Hadoop يمكن أن توفر أداءً أفضل ، إلا أن هناك بعض العيوب التي نادرًا ما تتم مناقشتها. يجب أن تفكر في كيفية إدارة مجموعة Hadoop أو الأمان أو Presto أو أي واجهة أخرى تستخدمها.
غالبية أنظمة قواعد بيانات العلاقات ، مثل SQL Server و Oracle ، أسهل كثيرًا في الاستخدام. تواجه معظم المنظمات مشكلة كبيرة في عدم وجود عدد كافٍ من الأشخاص المهرة الذين يمكنهم تشغيل Hadoop بفعالية ، فضلاً عن التكلفة الكبيرة للمواهب. إذا كان لديك 10000 موظف ، فستحتاج إلى الكثير من البيانات لتتبعهم جميعًا. يمكن تخزين هذه المعلومات بعدة طرق مع Presto. يمكن استخدام قسم التاريخ لتخزين موقع الشخص كل يوم. من ناحية أخرى ، يمكن استخدام نظام RDBMS كمثال لنموذج البيانات. الطريقة الوحيدة لاستخدام هذه الطريقة هي إذا كان لديك بالفعل وصول إلى بيانات اليوم السابق.
ما هو الفرق الرئيسي بين قواعد البيانات العلائقية والبيانات الضخمة؟
يتمثل التمييز الأساسي بين قواعد البيانات العلائقية والبيانات الضخمة في أن قواعد البيانات العلائقية مُحسَّنة لتخزين البيانات المنظمة ، بينما يتم تحسين البيانات الضخمة لتخزين البيانات غير المنظمة وشبه المنظمة. تم تصميم قاعدة البيانات العلائقية على غرار النموذج العلائقي ، في حين تم تصميم قاعدة البيانات الضخمة على غرار النموذج الموزع. يمكن تخزين البيانات المنظمة ومعالجتها في قواعد البيانات العلائقية بطريقة فعالة. يحتوي الجدول على بيانات ويتيح الوصول إلى لغة الاستعلام المهيكلة (SQL) واستعادتها. يتم تعريف البيانات الضخمة على أنها أي بيانات غير منظمة أو شبه منظمة.

ما هو الفرق بين Hadoop و Mongodb؟
نظرًا لأن MongoDB يعمل في لغة C ، فهو أفضل في إدارة الذاكرة من أي قاعدة بيانات أخرى. Hadoop عبارة عن مجموعة من البرامج المستندة إلى Java توفر إطارًا لتخزين البيانات واستردادها ومعالجتها. يعمل Hadoop على تحسين المساحة بشكل أكثر فعالية من MongoDB.
كانت MongoDB قاعدة بيانات NoSQL (ليست فقط SQL) تم إنشاؤها في C. Hadoop هي منصة برمجية مفتوحة المصدر تتكون أساسًا من Java والتي تتيح معالجة كميات كبيرة من البيانات. علاوة على ذلك ، يتضمن MongoDB Atlas البحث عن نص كامل ، وتحليلات متقدمة ، ولغة استعلام بديهية. Hadoop فعال في تخزين ومعالجة كمية كبيرة من البيانات ، لكنه يفعل ذلك على دفعات صغيرة. هناك مجموعة متنوعة من أدوات معالجة البيانات المضمنة في الوقت الفعلي المتاحة في MongoDB. بسبب موصلاته للأدوات الخارجية مثل كافكا وسبارك ، يجعل MongoDB استيعاب البيانات ومعالجتها أمرًا بسيطًا. مزايا Hadoop و MongoDB على قواعد البيانات التقليدية في مجال البيانات الضخمة عديدة. يمكن استخدام Hadoop ، وهو نظام ملفات موزع ، للتعامل مع الملفات الضخمة. MongoDB هي قاعدة البيانات الوحيدة القادرة على أن تكون بديلاً لقاعدة البيانات التقليدية من حيث الأداء.
Rdbms مقابل Nosql مقابل Hadoop
هناك ثلاثة أنواع رئيسية من مخازن البيانات - RDBMS و NoSQL و Hadoop. لكل منهم نقاط قوته وضعفه ، لذلك من المهم اختيار النقطة المناسبة لاحتياجاتك.
RDBMS (نظام إدارة قواعد البيانات العلائقية) هو أكثر أنواع تخزين البيانات شيوعًا. إنه سهل الاستخدام وسهل القياس. ومع ذلك ، فهي ليست مرنة مثل NoSQL أو Hadoop ، وقد تكون صيانتها أكثر تكلفة.
NoSQL (ليس فقط SQL) هو نوع جديد من مخازن البيانات أصبح أكثر شيوعًا. إنه أكثر مرونة من RDBMS ، ويمكن أن يكون أكثر قابلية للتوسع. ومع ذلك ، فهي ليست سهلة الاستخدام ويمكن أن تكون أكثر تكلفة في الصيانة.
Hadoop هو نوع من مخازن البيانات مصمم للبيانات الضخمة. إنه قابل للتطوير للغاية ويمكنه التعامل مع الكثير من البيانات. ومع ذلك ، فهي ليست سهلة الاستخدام مثل RDBMS أو NoSQL ، وقد تكون صيانتها أكثر تكلفة.
يمكن تحسين نهج المؤسسة في تخزين البيانات ومعالجتها وتحليلها بشكل كبير باستخدام منصة Apache Hadoop . يمكن لمخزن البيانات تشغيل أنواع متعددة من أحمال العمل التحليلية على نفس الأجهزة والبرامج ، بالإضافة إلى إدارة أحجام البيانات على نطاق واسع. يمكن للمحللين الآن التفاعل بشكل فعال مع البيانات أثناء التنقل باستخدام أدوات مثل Apache Impala و Apache Spark. لا يمتلك Hadoop ، على عكس نظام إدارة قواعد البيانات العلائقية (RDBMS) ، نفس القدرات التي تتمتع بها قاعدة البيانات ، ولكنه بدلاً من ذلك نظام ملفات موزع قادر على معالجة كميات هائلة من البيانات. يشار إلى كمية البيانات التي يمكن معالجتها بسهولة وفعالية باسم حجم حجم البيانات. بمعنى آخر ، يمكن تحسين عملية حجم البيانات الإجمالية خلال فترة زمنية محددة. لديه القدرة على تخزين ومعالجة البيانات من مجموعة واسعة من المصادر وإعدادها للتحليل.
بكمية صغيرة ، يمكن لنظام RDBMS فقط إدارة البيانات المهيكلة وشبه المنظمة. Hadoop غير قادر على معالجة البيانات من مجموعة متنوعة من المصادر أو أي بنية منظمة. يعد وقت الاستجابة وقابلية التوسع والتكلفة بعضًا من العوامل المهمة الأخرى التي يجب مراعاتها.
لماذا لا يزال Rdbms أكثر أنظمة إدارة قواعد البيانات شيوعًا
نظام إدارة قواعد البيانات الأكثر استخدامًا في العالم هو نظام RDBMS. إنه يوفر مجموعة واسعة من الميزات ، فضلاً عن كونه موثوقًا للغاية. تعد قاعدة البيانات العلائقية هي الأنسب لتخزين البيانات المطلوبة لعدة مستخدمين للوصول إليها.
تكتسب قواعد بيانات NoSQL شعبيةً ويرجع ذلك جزئيًا إلى مزايا أدائها مقارنة بقواعد البيانات العلائقية. كما أنها تسمح لك بتخزين كميات كبيرة من البيانات التي لا تحتاج إلى مشاركتها مع عدة مستخدمين.
حدوب نصقل
في مجموعة الأجهزة السلعية ، يقوم Hadoop بتخزين البيانات الكبيرة. لديك خيار تغيير أي وظيفة لا تعمل أو تلبي احتياجاتك إذا لزم الأمر. في المقابل ، فإن نظام إدارة قاعدة بيانات NoSQL هو نوع من نظام إدارة قواعد البيانات الذي يتم استخدامه لتخزين البيانات المهيكلة وشبه الهيكلية وغير المهيكلة.
هل Hdfs قاعدة بيانات
نظام ملفات HDFS هو نظام ملفات موزع يعمل على أجهزة سلعة. يمكن تكوين مجموعة Apache Hadoop واحدة لدعم المئات (وحتى الآلاف) من العقد باستخدام هذه الميزة. يتكون Apache Hadoop ، والذي يتضمن أيضًا MapReduce و YARN ، من عدة مكونات رئيسية.
يتم توفير وصول عالي الأداء إلى البيانات بواسطة نظام الملفات الموزعة Hadoop (HDFS) ، وهو أحد مكونات نظام التشغيل Hadoop . تكون عقدة الاسم الأساسي للكتلة مسؤولة عن تتبع مكان تخزين بيانات ملف الكتلة. بالإضافة إلى إدارة الوصول إلى الملفات ، تدير عقدة الاسم الوصول إلى الملفات مثل القراءة والكتابة والإنشاء والحذف وما إلى ذلك. قدمت Yahoo مكتوب نظام الملفات الموزعة Hadoop كجزء من متطلبات موضع الإعلان عبر الإنترنت ومتطلبات محرك البحث. يكشف بروتوكول HDFS عن مساحة اسم نظام الملفات من أجل تخزين بيانات المستخدم. يمكن أن تتواصل DataNodes مع بعضها البعض أثناء عمليات الملفات العادية لأنها تتواصل مع بعضها البعض. يعد نظام الملفات الموزعة Hadoop (HDFS) أحد مكونات العديد من بحيرات البيانات مفتوحة المصدر. يتم استخدام HDFS بواسطة eBay و Facebook و LinkedIn و Twitter لتحليل كميات كبيرة من البيانات. في حالة فشل العقدة أو الأجهزة ، يلزم نسخ البيانات حتى يعمل HDFS بشكل صحيح.
مثال على قاعدة بيانات Hadoop
قاعدة بيانات Hadoop هي قاعدة بيانات تستخدم نظام الملفات الموزعة Hadoop (HDFS) لتخزينها الأساسي. تُستخدم قواعد بيانات Hadoop عادةً لتخزين كميات كبيرة من البيانات التي تكون أكبر من أن تتناسب مع خادم واحد.
إطار عمل مفتوح المصدر لتخزين ومعالجة مجموعات البيانات الكبيرة بطريقة موزعة على الأجهزة السلعية ، يستخدم Apache Hadoop في مجموعة متنوعة من التطبيقات. إنها نسخة مفتوحة المصدر من نموذج Google الذي تم استخدامه في ورقة MapReduce 2004 الخاصة بهم. سنستعرض بعض الأسئلة الأكثر شيوعًا من قبل المبتدئين في نظام البيانات الضخمة في هذه المقالة. تركز منصة Apache Hadoop على معالجة البيانات الموزعة بدلاً من تخزين قاعدة البيانات أو التخزين العلائقي. على الرغم من وجود مكون تخزين يعرف باسم HDFS (نظام الملفات الموزعة Hadoop) ، والذي يخزن الملفات المستخدمة للمعالجة ، فإن HDFS يندرج تحت فئة قاعدة البيانات العلائقية. يمكن استخدام Hive ، وكذلك HiveQL ، للاستعلام عن تخزين HDFS الخاص بـ HDFS ، والمدمج في HDFS.
ما هو مثال على Hadoop؟
يمكن لشركات الخدمات المالية استخدام Hadoop لتقييم المخاطر ، وبناء نماذج الاستثمار ، وإنشاء خوارزميات التداول ؛ تم استخدام Hadoop أيضًا للمساعدة في إنشاء تلك التطبيقات وإدارتها. يستخدم تجار التجزئة هذه التكنولوجيا لمساعدتهم على فهم وخدمة عملائهم بشكل أفضل من خلال تحليل البيانات المنظمة وغير المنظمة.
الاستخدامات العديدة لبرنامج Hadoop
يمكن استخدام Hadoop لإدارة البيانات في تطبيقات البيانات الكبيرة مثل تحليلات البيانات الضخمة ، وتحليلات البيانات في الوقت الفعلي ، والبحث العلمي ، وتخزين البيانات. نتيجة لذلك ، فهي منصة متعددة الاستخدامات وقابلة للتكيف مثالية لمجموعة واسعة من التطبيقات.
هو سبارك قاعدة بيانات Nosql
يعد NoSQL DataFrame ، وفقًا للوثائق ، تنسيق مصدر بيانات لـ Spark DataFrame. تتوفر DataPruning والتصفية (الضغط المسند لأسفل) في مصدر البيانات هذا ، مما يسمح بتشغيل استعلامات Spark على كميات أصغر من البيانات ، ويتم تحميل البيانات المطلوبة للمهمة النشطة فقط.
يتطلب الأمر الكثير من الجهد التكتيكي لتوصيل قاعدة بيانات Apache Spark و NoSQL (Apache Cassandra و MongoDB) ببعضها البعض. تتناول هذه المدونة كيفية إنشاء تطبيقات Apache Spark على خلفيات NoSQL. TCP / IP sPark هي وجهة منتزهات شهيرة تضم عددًا كبيرًا من الألعاب في أقسام CassandraLand و MongoLand المعروفة. عندما كان تطبيق Spark الخاص بنا يبحث عن بيانات من وزارة الطاقة ، قام بتدوير عجلاته وأصبح محبطًا. الدرس المستفاد هنا هو أن التسلسل الأساسي لـ Cassandra أمر بالغ الأهمية في عملية جلب البيانات. لدى CassandraLand أيضًا أفعوانية مشهورة تسمى Partitioner. يتم تشجيع العملاء الذين يركبون الأفعوانية على تتبع سجل رحلاتهم حتى يتمكن المشغلون من تتبع من ركبها كل يوم. درس Mongo 1 - إدارة اتصالات MongoDB بشكل صحيح عند تحديث البيانات ، مثل حالة عضوية المتنزه الجديدة التابعة لوزارة الطاقة ، يمكن أن تكون فهارس Mongo مفيدة جدًا. في حالة وجود تحديثات محددة ، يجب أن يضمن كل من MongoDB و Spark إدارة الاتصال والفهرسة بشكل صحيح.
سبارك: مستقبل البيانات الضخمة
Apache Spark ، وهو نظام معالجة موزعة تم تطويره بالتعاون مع Apache Software Foundation ، هو نظام معالجة البيانات الضخمة المستند إلى Hadoop. إطار عمل مفتوح المصدر يمكن استخدامه لتحسين مجموعات البيانات الكبيرة وسد الفجوة بين النماذج الإجرائية والعلائقية. بالإضافة إلى ذلك ، يدعم Spark MongoDB ، مما يسمح باستخدامه للتحليلات في الوقت الفعلي والتعلم الآلي.