
MapReduce: نموذج برمجة لمجموعات البيانات الكبيرة
نشرت: 2023-01-08MapReduce هو نموذج برمجة وتنفيذ مرتبط بمعالجة وإنشاء مجموعات بيانات كبيرة باستخدام خوارزمية متوازية وموزعة على مجموعة.
نحن نغير طريقة عملنا بكميات هائلة من البيانات باستخدام تقنيات جديدة. تعد مستودعات البيانات ، مثل Hadoop و NoSQL و Spark ، من أبرز اللاعبين في هذا المجال. مسؤولو قواعد البيانات ومهندسو / مطورو البنية التحتية هم من بين الجيل الجديد من المحترفين المتخصصين في إدارة الأنظمة بمستوى عالٍ من التطور. بدلاً من قاعدة البيانات ، يعد Hadoop نظامًا إيكولوجيًا للبرامج يسمح بالحوسبة المتوازية في شكل ملفات ضخمة. قدمت هذه التقنية فوائد كبيرة من حيث دعم احتياجات المعالجة الضخمة للبيانات الضخمة. بالنسبة لمعاملة البيانات الكبيرة ، قد يستغرق متوسط كتلة Hadoop ثلاث دقائق فقط لمعالجة معاملة كبيرة تستغرق عادةً 20 ساعة في نظام قاعدة بيانات علائقية مركزية.
الكتلة mapreduce هي مجموعة ذات خوارزمية متوازية ونموذج برمجة يعالج ويولد مجموعات كبيرة من البيانات بنفس طريقة الكتلة العادية.
تم تصميم نظام Apache Hadoop البيئي لدعم الحوسبة الموزعة ويوفر بيئة يمكن الاعتماد عليها وقابلة للتطوير وجاهزة للاستخدام. وحدة MapReduce لهذا المشروع هي نموذج برمجة يستخدم لمعالجة مجموعات البيانات الضخمة الموجودة على Hadoop (نظام ملفات موزع).
هذه الوحدة هي أحد مكونات نظام Apache Hadoop مفتوح المصدر وتستخدم للاستعلام عن البيانات وتحديدها في نظام الملفات الموزعة Hadoop (HDFS). يمكن تحديد البيانات لمجموعة متنوعة من الاستعلامات باستخدام خوارزمية MapReduce المتوفرة لأغراض إجراء مثل هذه التحديدات.
باستخدام MapReduce ، من الممكن تشغيل مهام معالجة البيانات الكبيرة. يمكنك إنشاء برامج MapReduce بأي لغة برمجة ، بما في ذلك C و Ruby و Java و Python وغيرها. يمكن استخدام هذه البرامج بشكل متزامن لتشغيل برامج MapReduce ، مما يجعلها مفيدة جدًا في تحليل البيانات على نطاق واسع.
ما هو استخدام Mapreduce في Mongodb؟
تعد الخرائط في MongoDB نموذجًا لبرمجة معالجة البيانات يمكّن المستخدمين من أداء مجموعات كبيرة من البيانات وإنشاء نتائج مجمعة منها. MapReduce هي الطريقة المستخدمة من قبل MongoDB لتقليل الخرائط. تنقسم هذه الوظيفة إلى مكونين: وظيفة خريطة ووظيفة تصغير.
باستخدام أداة MapReduce من MongoDB ، من الممكن تنظيم مجموعات البيانات الكبيرة وتجميعها. يستخدم هذا الأمر ، في MongoDB ، المدخلين الأساسيين في MongoDB: وظيفة الخريطة وتقليل الوظيفة ، من أجل معالجة كمية كبيرة من البيانات. لتعريف الأمثلة ، اتبع الخطوات أدناه. سنحدد وظيفة الخريطة ، وظيفة التخفيض ، والأمثلة.
سيقارن MapReduce السلاسل لفرز الإخراج باستخدام طريقة الفرز الافتراضية ، بغض النظر عما إذا كنت تستخدم الطريقة الافتراضية أم لا. لتغيير طريقة فرز البيانات ، يجب عليك أولاً إنشاء خوارزمية الفرز ثم تنفيذها باستخدام فئة معين.
SpiderMonkey هو محرك JavaScript يستخدم على نطاق واسع. إنه جيد للتطبيقات الصغيرة ، لكن له بعض القيود. لا يحتوي SpiderMonkey على خوارزمية فرز ، على سبيل المثال. نتيجة لذلك ، إذا كنت تريد استخدام Mapmapper لفرز البيانات ، فيجب عليك أولاً إنشاء خوارزمية الفرز الخاصة بك وتنفيذها في فئة Reduce.
على الرغم من شعبيته ، لا يستخدم SpiderMonkey خوارزمية الفرز. هناك قيود أخرى على SpiderMonkey ، ولكن هذا واحد ملحوظ. لا يحتوي SpiderMonkey ، على سبيل المثال ، على أداة تجميع نفايات جيدة ، لذلك إذا بدأ برنامجك في التباطؤ ، فقد تحتاج إلى اتخاذ بعض الإجراءات لجعله أسرع.
لماذا تستخدم وظيفة Mapreduce؟
يمكن أن تكون وظيفة MapReduce مفيدة في مجموعة متنوعة من المواقف. يمكن استخدام هذه الطريقة لمعالجة البيانات المجمعة في بعض الحالات. إنه مفيد أيضًا إذا كنت تحتاج إلى معالجة كمية كبيرة من البيانات بواسطة تطبيق أو عملية واحدة. يمكن أيضًا استخدام وظيفة MapReduce لمعالجة البيانات المنتشرة عبر عقد متعددة في نظام موزع. من خلال استخدام وظيفة MapReduce ، يمكن دمج البيانات من العقد في إخراج واحد. عادةً ما يتم استخدام تطبيق MapReduce لمعالجة كميات كبيرة من البيانات ، على الرغم من أنه قد يكون مطلوبًا للتعامل مع كميات كبيرة جدًا.
لماذا يسمى Mapreduce؟
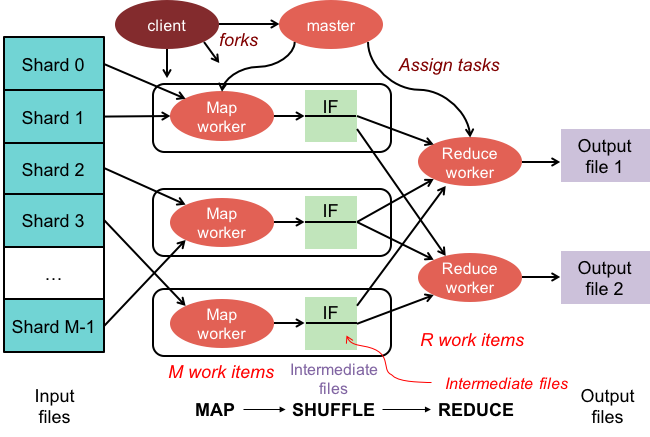
هناك بعض النظريات حول سبب تسميته MapReduce. أحدهما هو أنه تلاعب بالكلمات ، لأن خوارزميات تقليل الخريطة تتضمن تقسيم المشكلة إلى أجزاء أصغر (رسم الخرائط) ، ثم حل هذه الأجزاء وإعادة تجميعها معًا (تقليل). نظرية أخرى هي أنها إشارة إلى ورقة كتبها موظفو Google في عام 2004 بعنوان "MapReduce: معالجة البيانات المبسطة على مجموعات كبيرة". في الورقة ، يستخدم المؤلفون مصطلح "خريطة" و "تقليل" لوصف المرحلتين الرئيسيتين لنموذج المعالجة المقترح.
ومع ذلك ، من المهم ملاحظة أن نموذج MapReduce يستخدم فقط على أساس محدود. إنه غير مناسب لمجموعات البيانات الكبيرة ويجب أن يكون متوازيًا حتى يعمل بشكل صحيح. عندما يتعلق الأمر بمعالجة هذه المشكلات ، فإن لدى Apache Spark بديلًا قويًا لبرنامج MapReduce. يعتمد نظام الحوسبة العنقودية Spark على Hadoop ويعمل كمنصة حوسبة للأغراض العامة. يمكن استخدام هذه الأداة لتسريع مهام تحليل البيانات التقليدية مثل استخراج البيانات والتعلم الآلي بالإضافة إلى مهام معالجة البيانات الأكثر تعقيدًا مثل تخزين البيانات وتحليل البيانات الضخمة. تم تصميم هذا البرنامج باستخدام Erlang ، وهي لغة برمجة قابلة للتطوير ومتسامحة مع الأخطاء. يمكنه التعامل مع كميات كبيرة من البيانات ويمكن تشغيله على أجهزة متعددة في نفس الوقت. علاوة على ذلك ، يستخدم Spark التوازي ، مما يسمح للعقد المتعددة بتنفيذ نفس المهمة في نفس الوقت. بشكل عام ، لديها القدرة على أتمتة مهام تحليل البيانات واسعة النطاق وجعلها أكثر قابلية للتوسع. إذا كنت بحاجة إلى موازنة المعالجة الخاصة بك والتعامل مع مجموعات البيانات الكبيرة ، فهي بديل ممتاز لـ MapReduce.
ما هو الفرق بين Mapreduce والتجميع؟
عند العمل باستخدام البيانات الضخمة ، يعد mapreduce طريقة مهمة لاستخراج البيانات من كمية كبيرة من البيانات. يتضمن MongoDB 2.2 ، اعتبارًا من الآن ، إطار عمل التجميع الجديد. من حيث الوظائف ، التجميع مشابه لتقليل الخرائط ، ولكن على الورق ، يبدو أنه أسرع.
في هذا السيناريو ، يتم تشغيل MongoDB Aggregation و MapReduce على حاويات Docker في إعداد مشترك. يتفوق أداء خط أنابيب المُجمِّع على Mapreduce لأنه يسمح بالتنقل بشكل أسرع وأسهل. إليك كيفية عمل المشكلة: tweet يحسب الضمائر السويدية مثل "den" و "denne" و "denna" و "det" و "han" و "hon" و "hen" (حساس لحالة الأحرف) في علامة تصنيف Twitter. كم عدد مقابض تويتر التي يمتلكها المستخدم؟ تم إرسال أكثر من 4 ملايين تغريدة. في هذه التجربة ، سنقوم أولاً بإنشاء قاعدة بيانات MongoDB وتمكين التجزئة. تم استيراد تدفقات Twitter إلى قاعدة البيانات ، وتم تنفيذ الاستعلامات باستخدام MapReduce و Aggregation Pipeline.
Mapreduce: أداة تجميع البيانات النهائية
يقرأ برنامج mapReduce قائمة الوثائق من مجموعة ويعالجها باستخدام مجموعة من الوظائف المحددة مسبقًا. تنشئ عملية mapReduce دفقًا من المستندات الجاهزة للمعالجة والتي ستتم معالجتها في مرحلة التخفيض. من الممكن الجمع بين اختزال الخرائط والتجميع في مجموعة متنوعة من المواقف. عامل التجميع $ group هو أداة يمكن استخدامها لتجميع المستندات في حقل واحد. عندما يتم دمج مستندات متعددة باستخدام عامل التجميع $ merge ، يمكن إنشاء مستند جديد. يمكن استخدام عامل التجميع المتراكم $ لتمثيل نتائج عمليات تقليل الخريطة المتعددة في مستند واحد.
مابريدس في مونجودب
Mongodb mapreduce هي تقنية لمعالجة البيانات لمجموعات البيانات الكبيرة. إنها أداة قوية لتحليل البيانات وتوفر طريقة لمعالجة البيانات وتجميعها بطريقة متوازية وموزعة. تم استخدام MapReduce على نطاق واسع لتحليل البيانات في مجموعة متنوعة من المجالات ، بما في ذلك تحليل حركة مرور الويب وتحليل السجل وتحليل الشبكة الاجتماعية.

عند استخدام الأمر mapReduce ، يمكنك تشغيل عمليات التجميع لتقليل الخريطة على مجموعة. يمكن لوظيفة الخريطة تحويل أي مستند إلى صفر أو العديد من المستندات الأخرى. في إصدارات MongoDB التي تتراوح من 4.2 إلى أقدم ، يمكن أن يحتوي كل إصدار فقط على نصف الحد الأقصى لحجم مستند BSON. لم يعد رمز JavaScript من نوع BSON المستخدم في MapReduce مدعومًا ، ولم يعد من الممكن استخدام الكود لوظائفه. لم يعد MongoDB 4.4 يتضمن الآن رمز JavaScript من نوع BSON المهمل مع النطاق (نوع BSON 15). تحدد معلمة النطاق المتغيرات التي يُسمح بالوصول إليها بواسطة دالة التصغير. لتقليل المدخلات ، يحدد MongoDB حجم مستند BSON إلى نصف حجمه الأقصى.
قد يتم إرجاع المستندات الكبيرة التي يتم إرجاعها إلى الخادم ثم دمجها في التخفيضات اللاحقة ، مما قد يخالف المتطلبات. يعد MongoDB 4.2 أحدث إصدار. يمكن استخدام هذا الخيار لإنشاء مجموعة مجزأة جديدة بالإضافة إلى تقليل الخريطة لإنشاء مجموعة جديدة بنفس اسم المجموعة. تستقبل وظيفة الإنهاء كوسيطات قيمة أساسية وقيمة مخفضة من دالة الاختزال. هناك ثلاثة خيارات لتكوين معلمة الإخراج. هذا الخيار ، بالإضافة إلى إنشاء مجموعة جديدة ، لا يعمل على الأعضاء الثانويين لمجموعات النسخ المتماثلة. لا يمكن توفير خيار NonAtomic: false إلا إذا كانت المجموعة موجودة بالفعل لتمرير المواصفات الصريحة.
استخدام وظيفة التصغير في كل من نتائج المستند الجديدة والحالية إذا كان المفتاح الموجود في المستند الجديد هو نفس المفتاح الموجود في المستند الحالي. لا يعمل تقليل الخريطة عندما تكون collectionName عبارة عن مجموعة غير مجدية تم إعدادها. في هذه الحالة ، يتم منع MongoDB من قفل قاعدة البيانات الخاصة به إذا كانت nonAtomic صحيحة. يمكن فقط أن يكون الأعضاء الثانويون لمجموعات النسخ المتماثلة التي تستخدم هذا الخيار خارج المجموعة. لا توجد وظائف مخصصة مطلوبة لإعادة كتابة عملية تقليل الخريطة. يُستخدم cust_id لحساب حقل القيمة لمجموعة مرحلة المجموعة $ بواسطة طريقة cust_id. تدمج مرحلة الدمج $ نتائج مرحلة الدمج $ في مجموعة المخرجات باستخدام مشغلي خطوط أنابيب التجميع المتاحين.
كمثال ، يمكن استخدام المرحلة out $ لكتابة ناتج المجموعة agg_alternative_1. يمكن معالجة كل مستند إدخال باستخدام وظيفة الخريطة. يرتبط كل عنصر في الترتيب بقيمة عنصر جديدة تحتوي على كل من عدد 1 وكمية العنصر في الترتيب. في RedVal ، يمثل حقل العدد مجموع حقول الجرد التي تم إنشاؤها بواسطة عناصر الصفيف. إذا قامت وظيفة الإنهاء بتعديل كائن RedVal لتضمين حقل محسوب يسمى avg ، فسيتم إرجاع الكائن المعدل إلى المستخدم. تقسم مرحلة التراجع $ المستند إلى مستند لكل عنصر مصفوفة باستخدام حقل مصفوفة العناصر. تعيد مرحلة المشروع $ تشكيل مستند الإخراج لعكس مخرجات mapreduce بتضمين حقلين -id و value.
يتم الكتابة فوق المستند الحالي إذا لم يكن هناك مستند موجود بنفس المفتاح مثل النتيجة الجديدة. إذا قمت بتحديد معلمة out ، فإن mapReduce يُرجع مستندًا كمخرج بالتنسيق التالي إذا كنت تريد كتابة النتائج إلى مجموعة. يتم إرجاع مصفوفة من المستندات الناتجة إذا تمت كتابة الإخراج بشكل مضمّن. يحتوي كل مستند على حقلين: اسم المستند المصدر واسم مستند المستلم. عند إدخال قيمة المفتاح في الحقل -id ، يتم إنشاء حقل قيمة لتقليل قيم المفتاح أو إنهائها.
ما هو المنبعث في مونغودب؟
كوظيفة خريطة ، يمكن لوظيفة الخريطة استدعاء عمليات البث (مفتاح ، قيمة) في أي وقت لإنشاء مستند إخراج يتضمن المفتاح والقيمة. يمكن أن يحتوي الإصدار المنفرد في MongoDB 4.2 والإصدارات الأقدم على نصف الحجم الأقصى لملفات BSON الخاصة بـ MongoDB. بدءًا من الإصدار 4.4 من MongoDB ، تتم إزالة القيد.
لماذا يعتبر Mongodb الخيار الأفضل للبيانات المرنة والقابلة للتطوير
نظرًا لافتقار MongoDB إلى مخطط صارم ، غالبًا ما يرتبط بـ NoSQL. نظرًا لافتقارها إلى مخطط صارم ، يمكن تخزين البيانات بأي تنسيق مناسب للتطبيق. توفر مرونة قاعدة البيانات ميزة مهمة عند توسيع نطاقها أو تصغيرها ، حيث تعني أنه يمكن تخزين البيانات بطريقة تتناسب مع احتياجات التطبيق.
يمكن استخدام مخطط البيانات مع مخططات ER لتصور العلاقات بين أجزاء مختلفة من البيانات. يصور مخطط ER سلسلة من العقد التي تمثل مجموعة من البيانات ، وتعمل الاتصالات بينها كمعرف.
لا يتم فرض العلاقات في MongoDB لأنها ليست قاعدة بيانات علائقية. يصور مخطط ER العلاقات الموجودة داخل البيانات ، ويساعد أيضًا في تصورها.
يعد MongoDB اختيارًا ممتازًا للبيانات المرنة والقابلة للتطوير. تسمح مرونته بتخزين البيانات بطريقة منطقية للتطبيق ، وتتيح قابلية التوسع التعامل مع مجموعات البيانات الكبيرة بسرعة وسهولة.
مثال مونغودب لخفض الخريطة
في MongoDB ، يعد تقليل الخريطة نموذجًا لمعالجة البيانات لتجميع البيانات من المجموعات. إنه مشابه للخريطة ويقلل من الوظائف في البرمجة الوظيفية.
تتكون عمليات تقليل الخريطة من مرحلتين:
1. تطبق مرحلة الخريطة وظيفة تعيين لكل مستند في المجموعة. ترسل وظيفة التعيين عنصرًا واحدًا أو أكثر لكل مستند إدخال.
2. تطبق مرحلة التخفيض وظيفة تصغير على المستندات المنبعثة من مرحلة الخريطة. تعمل وظيفة التصغير على تجميع الكائنات وتنتج كائنًا واحدًا كإخراج.
على سبيل المثال ، ضع في اعتبارك مجموعة من المقالات. يمكننا استخدام map-تقليل لحساب عدد الكلمات في كل مقال.
أولاً ، نحدد وظيفة تعيين تُصدر زوجًا من قيم المفاتيح لكل مستند ، حيث يكون المفتاح هو معرف المقالة والقيمة هي عدد الكلمات في المقالة.
بعد ذلك ، نحدد دالة تصغير تجمع القيم لكل مفتاح.
أخيرًا ، نقوم بتنفيذ عملية تقليل الخريطة على المجموعة. والنتيجة هي مستند يحتوي على البيانات المجمعة.
في المنغوش ، توجد قاعدة بيانات. طريقة mapReduce () عبارة عن غلاف حول الأمر mapReduce. يتم توفير العديد من الأمثلة في هذا القسم ، مثل بديل خط أنابيب التجميع بدون تعبير تجميع مخصص. يمكن ترجمة الخرائط بتعبيرات مخصصة باستخدام أمثلة ترجمة Map-Reduce إلى تجميع تجميع خطوط الأنابيب. يمكن تغيير عملية تقليل الخريطة دون الحاجة إلى تحديد وظائف مخصصة باستخدام مشغلي خطوط أنابيب التجميع المتاحين. يمكن استخدام وظيفة الخريطة لمعالجة كل مستند في الإدخال. كل عنصر له قيمة كائن خاصة به مرتبطة بقيمة جديدة تحتوي على الرقم 1 ورقم الكمية للطلب وقائمة العناصر.
إذا كان المفتاح الموجود في المستند الحالي هو نفسه المفتاح الموجود في المستند الجديد ، فستستبدل العملية هذا المستند. يمكنك إعادة كتابة عملية تقليل الخريطة باستخدام عوامل تشغيل خطوط أنابيب التجميع بدلاً من تحديد الوظائف المخصصة. تقسم مرحلة التراجع $ المستند عن طريق حقل مصفوفة العناصر ، مما ينتج عنه مستند لكل عنصر مصفوفة. عندما تعيد مرحلة المشروع $ تشكيل مستند الإخراج ، يتم عكس إخراج تقليل الخريطة. تقوم العملية بالكتابة فوق مستند موجود له نفس مفتاح النتيجة الجديدة.
ما هي وظيفة مخطط الخرائط في Hadoop؟
كمخفض ، يجب عليك دمج البيانات من مصممي الخرائط من أجل إنشاء إجابة موحدة. يتم إنتاج تقليل المخرجات عند قبول مجموعة من مخرجات الخريطة كمدخلات ، يمثل كل منها مجموعة فرعية من النتيجة التي تم إنشاؤها.
يتم استخدام مصممي الخرائط لتقسيم البيانات إلى أجزاء يمكن إدارتها ، ثم تعيين كل جزء لمهمة بناءً على حجمها. يتم تلقي بيانات الإدخال بواسطة وظيفة معين ، حيث توجد معلمات تشير إلى المهمة المراد تنفيذها.
تتوافق سلسلة من العناصر مع أجزاء البيانات التي تم تعيينها بواسطة مخطط الخرائط في الإخراج. نتيجة لذلك ، يتم إعادة توجيه إخراج الخريطة إلى المخفض ، والذي يحولها إلى مخرجات مخفضة.
يتم معالجة الأخطاء أيضًا بواسطة وظيفة معين. سيعيد مخطط الخرائط ناتج خطأ في هذه الحالة ، وهو ليس ناتجًا للخريطة. نظرًا لأن المخفض لا يمكنه معالجة هذه البيانات ، سيعيد المخطط رسالة خطأ.
نظام Hadoop البيئي
نظام Hadoop البيئي هو عبارة عن منصة لمعالجة البيانات الضخمة وتخزينها. يتكون من عدد من المكونات ، لكل منها دور محدد يلعبه في معالجة البيانات وتخزينها. أهم مكونات النظام البيئي هي نظام الملفات الموزعة Hadoop (HDFS) ، وإطار عمل MapReduce ، ومكتبة Hadoop المشتركة .