
قاعدة بيانات NoSQL: إمبالا
نشرت: 2023-03-03NoSQL هو مصطلح يستخدم لوصف قاعدة البيانات التي لا تستخدم بنية قاعدة البيانات العلائقية التقليدية. بدلاً من ذلك ، غالبًا ما يتم تصميم قواعد بيانات NoSQL لتوفير حل أبسط وأكثر قابلية للتوسع.
Impala هي قاعدة بيانات NoSQL تم تصميمها لتوفير حل سريع وقابل للتطوير لإدارة مجموعات البيانات الكبيرة. تعتمد إمبالا على نموذج بيانات Google Bigtable وتستخدم تنسيق تخزين عمودي. إمبالا متاحة كمشروع مفتوح المصدر وتدعمه Cloudera.
Apache Impala هو محرك استعلام SQL مفتوح المصدر يتم تثبيته على مجموعة Hadoop ويقوم بمعالجة متوازية ضخمة (MPP) للبيانات المخزنة على النظام. تم تطوير المشروع مفتوح المصدر في الأصل عام 2012 ، ويُعرف باسم "Microsoft Formula 1."
تتيح منصة Impala للمستخدمين إجراء استعلامات SQL بزمن انتقال منخفض لبيانات Hadoop المخزنة في HDFS و Apache HBase دون الحاجة إلى نقل البيانات أو تحويلها.
هل إمبالا أس كيو إل مقرها؟
Impala هو محرك استعلام قائم على SQL يتم تشغيله على Apache Hadoop. يسمح للمستخدمين بالاستعلام عن البيانات المخزنة في HDFS و HBase باستخدام SQL. توفر إمبالا أداءً عاليًا وزمن انتقال منخفضًا مقارنة بمحركات استعلام Hadoop الأخرى مثل Hive and Pig.
توفر قاعدة بيانات إمبالا التحليلية MPP أسرع وقت للحصول على نظرة ثاقبة في الصناعة. إنه مدمج مع CDH ويمكن الوصول إليه من خلال Cloudera Enterprise. تستخدم قواعد بيانات MPP لـ Apache Hadoop ، مثل Impala ، HDFS لتوفير وقت أسرع للرؤية.
إمبالا هي قاعدة بيانات
أعتقد أنها قاعدة بيانات.
هل إمبالا أداة Etl؟
إمبالا ليست أداة ETL ، إنها محرك استعلام SQL يمكن استخدامه لإجراء استعلامات SQL بعد تنظيف البيانات من خلال عملية.
ما هو اباتشي امبالا المستخدمة؟
باستخدام استعلامات تشبه SQL ، يمكننا قراءة البيانات من مجموعة متنوعة من المصادر باستخدام Impala. يعمل Apache Impala بشكل أفضل من Hive ومحركات SQL الأخرى عندما يتعلق الأمر بالوصول إلى البيانات المخزنة في نظام الملفات الموزعة Hadoop . نستخدم Impala لتخزين البيانات في Hadoop HBase و HDFS و Amazon S3.
19 شركة تستخدم Apache Impala في أكوام التكنولوجيا الخاصة بها
يعد Apache Impala محركًا شائعًا لمعالجة البيانات لمجموعة متنوعة من الشركات الكبيرة. وفقًا للتقارير ، تستخدم 19 شركة تقنية ، بما في ذلك Stripe و Agoda و Forex ، Apache Impala. منصة إمبالا مرنة وفعالة وقادرة على التعامل مع مجموعات البيانات الكبيرة بسرعة وفعالية. يوضح الاستخدام الواسع لهذه الأداة مدى فائدتها ومدى فائدتها في معالجة البيانات.
ما هي الاختلافات بين خلية النحل وإمبالا؟
يتمثل هدف Hive في معالجة الاستعلامات طويلة المدى التي تتطلب عمليات تحويل وربط متعددة. نظرًا لانخفاض وقت الاستجابة والقدرة على التعامل مع الاستعلامات الأصغر ، يعد محرك معالجة استعلام Impala مثاليًا للحوسبة التفاعلية. يدعم Spark كلاً من الاستعلامات القصيرة والطويلة المدى بالإضافة إلى الاستعلامات القصيرة والطويلة المدى.
الخلية مناسبة بشكل أفضل لوظائف الدُفعات طويلة المدى
الغرض الأساسي من الأدوات ليس معالجة الدُفعات. تعد الخلية أكثر ملاءمة للعمل الجماعي طويل الأجل من Impulsa ، التي يمكنها التعامل مع مجموعات البيانات الأصغر.
هل إمبالا قاعدة بيانات
إمبالا هي قاعدة بيانات تخزن البيانات بتنسيق عمودي. وهي مصممة لتكون قابلة للتطوير ولتوفير أداء عالٍ لمجموعات البيانات الكبيرة.
في الإصدار الأولي من Impala ، يتم دعم أنواع بيانات الأعمدة الأساسية التالية: STRING و VARCHAR و VARCHar2 و INT و FLOAT بدلاً من الرقم ، ولا يتم دعم أي نوع BLOB. يتضمن Impala SQL-92 بعض التحسينات لمعايير معايير SQL ، لكنه لا يدمجها جميعًا. عندما تكون البيانات كبيرة جدًا بحيث لا يمكن إنتاجها ومعالجتها وتحليلها على خادم واحد ، فإن أداء Impala يكون أفضل من مستودعات البيانات الأخرى ويتم تمكين قابلية التوسع بشكل أكبر. ليست هناك حاجة لإزالة الموقع الأصلي لملفات البيانات عند تحميل إمبالا لأنه خفيف الوزن. عادةً ما تكون الخطوة الأولى في التعرف على اختبار الأداء وقابلية التوسع وتكوينات الكتلة متعددة العقد هي جمع كميات هائلة من البيانات. تم تحسين Cloudera Impala لتحميل البيانات والقراءة المجمعة في مجموعات البيانات الكبيرة ، مما يتيح لك القيام بالمزيد بموارد أقل. يسمح حجم الكتلة متعدد الميجابايت في HDFS لإمبالا بمعالجة كميات هائلة من البيانات بالتوازي عبر خوادم متعددة متصلة بالشبكة.
بدلاً من التخطيط للفهارس التي تمت تسويتها والوقت والجهد اللازمين لإنشائها ، ستفعل ذلك في إمبالا. يمكن لمحرك استعلام Impala التعامل مع كميات كبيرة من البيانات التي تأتي من مستودعات البيانات. يقوم بتحليل الكتلة وتوزيع المهام بين العقد من أجل تقليل كمية الموارد المستهلكة. يعد تقسيم مستودع البيانات مفهومًا مألوفًا في إمبالا. يقلل التقسيم من إدخال / إخراج القرص ويزيد من قابلية توسيع الاستعلام في إمبالا. ملفات البيانات مطلوبة حيث لن تتمكن من الوصول إلى أي جداول مضمنة في Impala. INSERT هو أحد الخيارات المتاحة.
لبناء طاولتي لعب ، استخدم بيان القيمة. إذا كنت تستخدم برنامجًا موجهًا للدفعات ، فيمكنك تجربته. يمكنك دمج تقنية SQL-on- hadoop في تكوين Apache Hive الخاص بك. لا يتم تحميل جداول Hive في Impala أو تحويلها بطريقة تستغرق وقتًا طويلاً.
إمبالا: أداة قوية لإدارة البيانات لبرنامج Hadoop
بناء جملة SQL مألوف لمستخدمي Impala ، والذي يمكنه الاستعلام عن البيانات المخزنة في HDFS و Apache HBase. بهذه الطريقة ، يمكن استخدام Hadoop و Impulsa بدلاً من قواعد البيانات العلائقية التقليدية . علاوة على ذلك ، فهي أداة قوية لإدارة البيانات بفضل ميزاتها. علاوة على ذلك ، فإن قدراته على مجموعات البيانات الكبيرة مثيرة للإعجاب ، ويمكنه التعامل معها بسهولة كبيرة.
إمبالا في البيانات الضخمة
Impala هو محرك استعلام MPP SQL مفتوح المصدر يعمل على Apache Hadoop. يوفر استعلامات SQL تفاعلية سريعة حول البيانات المخزنة في HDFS و HBase. تم تصميم Impala لتحسين أداء Apache Hadoop من خلال توفير واجهة SQL تفاعلية سريعة للبيانات المخزنة في HDFS و HBase.

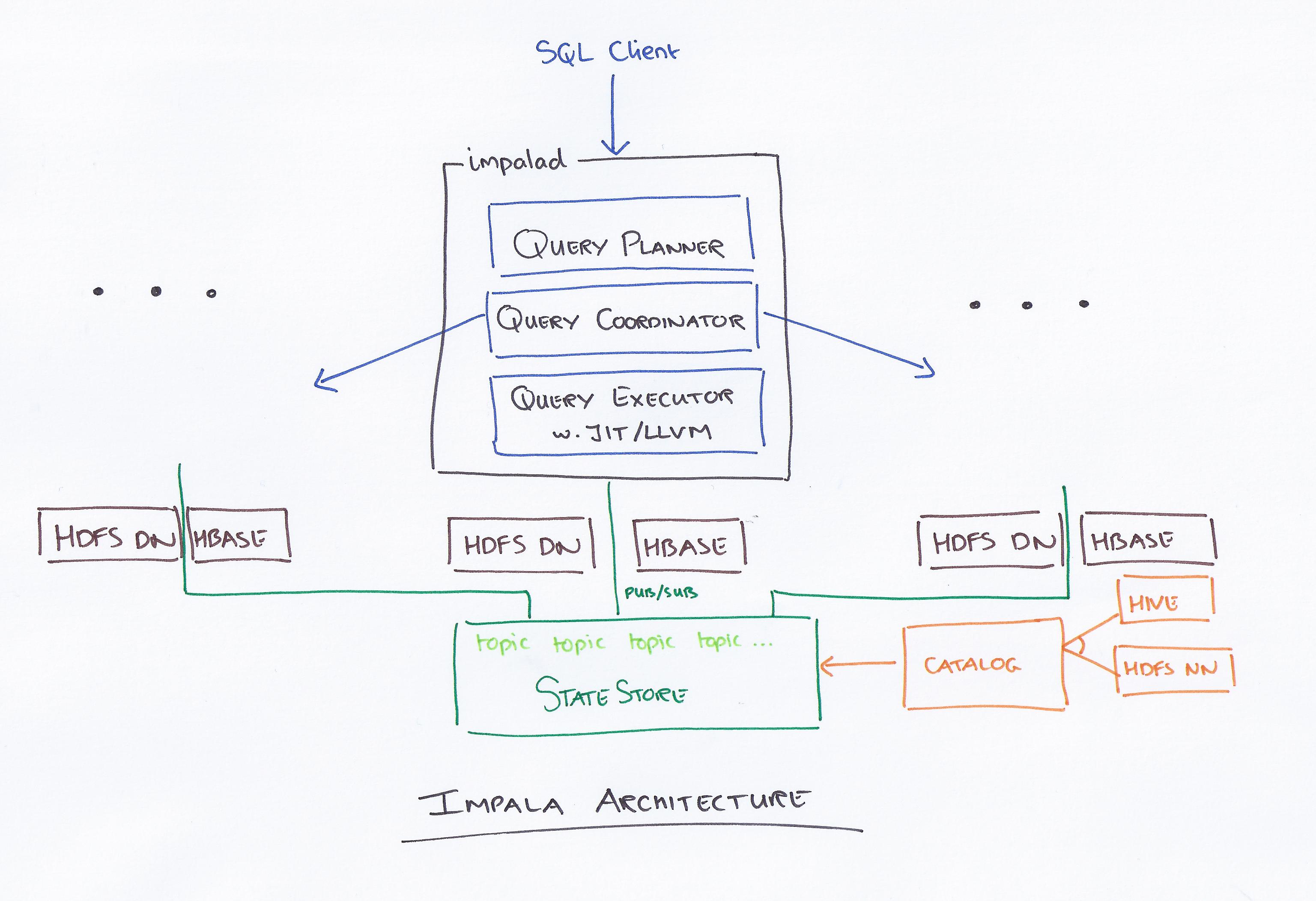
Impala ، بقيادة Cloudera ، هو نظام استعلام جديد. يحتوي Hadoop على HDFS و HBase ، لذلك يمكنه الاستعلام عن البيانات الكبيرة على مستوى PB المخزنة هناك. تعتمد هذه التقنية على الخلية والذاكرة للحساب ، بالإضافة إلى مراعاة مستودع البيانات ، وتوفر معالجة دُفعات في الوقت الفعلي ومعالجة متزامنة متعددة. يرسل العميل طلب استعلام إلى عقدة داخل شبكة إمبالاد ، حيث يتم إرجاع معرف استعلام لعمليات العميل اللاحقة. أثناء الخطوة الأولى من عملية إنشاء المحلل ، يتم إنشاء خطة تنفيذ قائمة بذاتها (خطة جهاز واحد ، وخطة تنفيذ موزعة) ، وسيتم أيضًا تنفيذ SQL ، مثل تغييرات أمر الانضمام ، وعمليات الدفع لأسفل ، وما إلى ذلك. تحتفظ جميع العقد بنسخة من أحدث معلومات البيانات الوصفية لضمان عدم تركك خارج الحلقة. قبل استخدام Hadoop أو Hive أو Impurbia ، يجب عليك أولاً تثبيت برنامج معالجة البيانات الضروري.
يمكن تغيير ملف تكوين إمبالا. كل عقدة تقوم بتغيير التكوين في إمبالا. جميع العقد مسؤولة عن توصيل حزمة برنامج تشغيل MySQL بقاعدة بيانات. العقد تغير مسار Java لـ Bigtop.
مقارنة بين Hive و Impala
هناك بعض الاختلافات الطفيفة أيضًا ، بالإضافة إلى هذه الاختلافات الثلاثة الرئيسية. في الخلية ، توجد مجموعة فرعية من HiveQL ، بينما في ضمني ، توجد مجموعة فرعية من HiveQL. يتم استخدام Hive و Impala لتخزين البيانات والاستعلام التفاعلي ، على التوالي. Hive ، على عكس Impala ، غير مخصص للحوسبة التفاعلية.
ما هو امبالا في Hadoop
Impala هو محرك استعلام SQL مفتوح المصدر للبيانات المخزنة في مجموعة Hadoop. تم تصميمه لتوفير استعلامات SQL تفاعلية وسريعة حول البيانات المخزنة في HDFS أو HBase أو أي مصدر بيانات Hadoop آخر.
تستخدم إمبالا مجموعة واسعة من مكونات Hadoop المألوفة . يمكن لـ INSERT فقط كتابة البيانات من النوع الذي يمكن لـ Impala قراءته ، بينما يمكن لـ SELECT قراءة البيانات من النوع الذي يمكن لـ Impala قراءته. عند استخدام تنسيق ملف Avro أو RCFile أو SequenceFile ، يتم تحميل البيانات في Hive. يمكن استخدام إحصائيات الجدول وإحصائيات العمود بالإضافة إلى إحصائيات الجدول والأعمدة. يتم تحديث جميع عبارات DDL و DML تلقائيًا باستخدام عفريت الكتالوج في Impala 1.2 والإصدارات الأحدث إذا تم إرسالها من خلال عفريت الكتالوج. تقوم طريقة INVALIDATE METADATA بإرجاع بيانات التعريف لجميع الجداول الموجودة في مخزن البيانات الأساسي التي تم الوصول إليها. يتم تخزين ملفات البيانات في أدلة لجدول جديد وتتم قراءتها بغض النظر عن اسم الملف عند تشغيل Impala.
بشكل عام ، تعمل Apache Hive بشكل جيد كمنصة لتخزين البيانات ، في حين أن Impala هي الأنسب للمعالجة المتوازية. الخلية متسامحة مع الخطأ ، في حين أن Impulsa ليست كذلك.
اباتشي امبالا
Apache Impala هو محرك استعلام SQL سريع وتفاعلي لـ Apache Hadoop. إنه يمكّن المستخدمين من إصدار استعلامات SQL بزمن انتقال منخفض للبيانات المخزنة في HDFS و Apache HBase دون الحاجة إلى نقل البيانات أو التحويل.
يمكّن مفهوم هندسة إمبالا من التعامل مع الاستعلامات التفاعلية باستخدام HDFS بكفاءة أكبر من أي محرك استعلام آخر. الخلية أبطأ كثيرًا بسبب عمليات إدخال / إخراج القرص ، لكن Apache أسرع بكثير لأنه محرك مختلف تمامًا. لا يوجد تمييز بين Impulsa و Presto لأن Impulsa يستخدم تقنية أسرع بكثير ويستخدم Presto بنية مماثلة. عندما يتعلق الأمر بملفات الباركيه ، فإن أداء إمبالا هو الأفضل. حدد البيانات التي يجب تقسيمها بناءً على استفسارات المحللين. باستخدام إحصائيات إحصائيات الحساب ، ستكون استعلاماتك أسهل بكثير ، خاصةً إذا كانت تتضمن أكثر من جدول واحد (صلات). كان لدينا تعطل خادم كتالوج Impala أربع مرات في الأسبوع ، واستغرقت استفساراتنا وقتًا طويلاً لإكمالها.
علاوة على ذلك ، فإن كمية الملفات التي نقوم بإنشائها تؤثر بشكل كبير على أداء الاستعلام. نتيجة لذلك ، بدأنا في إدارة أقسامنا ودمجها في الحجم الأمثل للملف الذي يبلغ حوالي 256 ميجابايت. يذكر أن كل قسم يحتوي على ملف واحد فقط (ما لم يكن حجمه> 256 ميجا بايت). يجب اختيار أنسب نوع العمود من بين جميع أنواع البيانات التي يدعمها ضمني. للحد من عدد الاستعلامات المتزامنة أو ذاكرة Y التي يصل إليها المستخدم ، استخدم التحكم بإذن الدخول Impala. إذا استمر الاستعلام لأكثر من 30 دقيقة ، فسيتم اعتباره ميتًا.
أفضل محرك للبيانات الضخمة: إمبالا
محرك Impala هو محرك معالجة بيانات Hadoop مصمم خصيصًا للمجموعات الكبيرة. إنه يستخدم طاقة أقل بكثير ويستهلك موارد أقل بكثير من محرك MapReduce القياسي في Hadoop. يستخدم ضمني نظام الملفات الموزع HDFS كوسيط تخزين البيانات الأساسي الخاص به ، ويعتمد على التكرار في HDFS لمنع انقطاع الأجهزة أو الشبكة على أساس كل عقدة على حدة. يتم تمثيل ملفات البيانات التي تمثل بيانات الجدول فعليًا بواسطة تنسيقات ملفات HDFS المألوفة وبرامج ترميز الضغط.
محرك استعلام المعالجة المتوازية
محرك استعلام المعالجة المتوازية هو نوع من محرك قاعدة البيانات المصمم لمعالجة الاستعلامات بشكل متوازٍ. يمكن القيام بذلك باستخدام معالجات متعددة أو نوى متعددة أو أجهزة متعددة. يمكن للمعالجة المتوازية أن تحسن أداء محرك الاستعلام بشكل كبير ، خاصة للاستعلامات المعقدة.
يتم استخدام الكمبيوتر متعدد المعالجات لتحويل الاستعلامات المعقدة إلى خطط تنفيذ يمكن تنفيذها بشكل متزامن ، مما يسمح لها بمعالجة كميات كبيرة من البيانات في وقت واحد. التنفيذ الفعال ، مثل وقت الاستجابة الجيد للاستعلام أو معدل نقل الاستعلام العالي ، مطلوب لتحقيق أداء عالٍ. يتم تحقيق ذلك من خلال استخدام تقنيات التنفيذ المتوازي الفعالة وتحسين الاستعلام.
المعالجة الموازية: مستقبل Etl؟
يمكن تحويل الاستعلام عالي المستوى إلى خطة تنفيذ يمكن تنفيذها بكفاءة بواسطة كمبيوتر متعدد المعالجات باستخدام معالجة الاستعلام المتوازية. تستخدم المعالجة المتوازية تقنية الجمع بين البيانات المتوازية والموزعة ، بالإضافة إلى تقنيات التنفيذ المختلفة التي يوفرها نظام قاعدة البيانات المتوازية . يتم تنفيذ معالجة الاستعلام المتوازية في ETL عن طريق تقسيم مجموعة السجلات في كل جدول مصدر مخصص للنقل إلى أجزاء من نفس الحجم ، ثم تنفيذ عملية تحويل البيانات لكل جدول مصدر في دورة ، واختيار البيانات على التوالي ، مقطعة بقطعة .