
العوامل المميزة لـ Hadoop: قابلية توسيع المصدر المفتوح وتحمل الأخطاء
نشرت: 2022-11-18Hadoop هو إطار عمل برمجي مفتوح المصدر للتخزين الموزع ومعالجة مجموعات البيانات الضخمة عبر مجموعات من أجهزة الكمبيوتر. إنه مصمم للارتقاء من خادم واحد إلى آلاف الأجهزة ، كل منها يقدم عمليات الحوسبة والتخزين المحلية. بدلاً من الاعتماد على الأجهزة لتقديم إتاحة عالية ، تم تصميم إطار العمل لاكتشاف حالات الفشل ومعالجتها في طبقة التطبيق. Hadoop هي قاعدة بيانات nosql لأنها تستخدم بنية مختلفة تمامًا عن قاعدة البيانات العلائقية التقليدية. تم تصميم Hadoop للتوسيع أفقيًا ، مما يعني أنه يمكن توسيعه لاستيعاب المزيد من البيانات عن طريق إضافة المزيد من خوادم السلع إلى المجموعة. تم تصميم Hadoop أيضًا ليكون متسامحًا مع الأخطاء ، مما يعني أنه في حالة تعطل خادم في المجموعة ، يمكن للنظام الاستمرار في العمل بدون هذا الخادم.
لا يتم استخدام Hadoop لتخزين البيانات ، ولا يتطلب استخدام التخزين العلائقي ؛ بدلاً من ذلك ، يتم استخدامه لتخزين كميات هائلة من البيانات على الخوادم الموزعة. قاعدة بيانات Hadoop هي نوع من البيانات وليس نظام برمجي يتيح الحوسبة المتوازية الضخمة. إنه نوع ملزم لقاعدة بيانات NoSQL (مثل HBase) يسمح للمستخدمين بالاستعلام عن قواعد البيانات والبحث فيها في مجموعة متنوعة مرتبطة. لن يتمكن RDBMS ، في شكله الحالي ، من التنافس مع Hadoop لأنه قادر على إدارة كل من البيانات النسبية والمعاملات. يمتلك Hadoop القدرة على التعامل مع أي نوع من البيانات ، سواء كانت منظمة أو شبه منظمة أو غير منظمة ، وهو يدعم مجموعة واسعة من الأساليب. تمنح تحليلات البيانات الضخمة للشركات ميزة تنافسية في العالم الحقيقي من خلال توفير رؤى أعمق. تدعم Hadoop ، كخدمة ، استخدام المعالجة التحليلية عبر الإنترنت (OLAP) في معالجة البيانات. من المهم أن تتذكر أن سرعة معالجة البيانات يتم تحديدها من خلال عدد طلبات البيانات. يمكنك استخدام Hadoop إذا كنت لا تريد معاملات ACID أو دعم OLAP ، على سبيل المثال.
Hadoop وقواعد البيانات في الذاكرة هما تقنيتان مختلفتان تمامًا تتداخلان. إنهما ليسا متشابهين ، لكنهما يتفقان على بعض الأشياء.
تجمع التطبيقات التحليلية التي تستخدم SQL-on- Hadoop بين أساليب الاستعلام القائمة على نمط SQL مع عناصر إطار عمل بيانات Hadoop الأحدث . يسمح SQL-on- Hadoop لمطوري المؤسسات ومحللي الأعمال بالتعاون في مجموعات Hadoop باستخدام استعلامات SQL المألوفة.
إنها قاعدة بيانات NoSQL توفر وسيلة لتخزين واسترجاع البيانات. غير العلائقية / غير SQL هو أحد المصطلحات المستخدمة بشكل شائع في هذا الفضاء.
تتم إدارة البيانات بطرق مختلفة بواسطة Hadoop و SQL. SQL هي لغة برمجة ، في حين أن Hadoop هو إطار لمكونات في البرنامج. كلتا الأداتين مفيدتان للبيانات الضخمة ، لكن لهما عيوب. يمكن لمنصة Hadoop التعامل مع مجموعة أكبر من البيانات ، لكنها تكتب البيانات مرة واحدة فقط.
ما هو الفرق بين Hadoop و Nosql؟
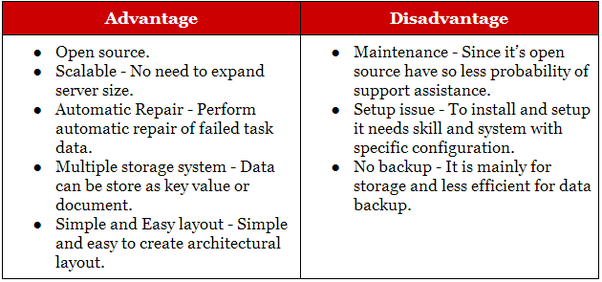
يعد Hadoop مناسبًا لتطبيقات الأرشفة التحليلية والتاريخية ، بينما يعد NoSQL مثاليًا لأحمال العمل التشغيلية التي تكمل نظيراتها العلائقية. بدأت قواعد بيانات NoSQL كقواعد بيانات تخزين ذات قيمة رئيسية ، ولكن لاحقًا ، انضمت إليها قواعد بيانات المستند / json والرسم البياني.
تعد المعالجة في الوقت الفعلي والبيانات الكبيرة والبيانات غير المهيكلة مجرد عدد قليل من السيناريوهات التي يمكن فيها استخدام تقنية NoSQL. ونتيجة لذلك ، يمكن معالجة بعض هذه التحديات ، مثل قابلية التوسع والتوافر. تتمتع قاعدة بيانات NoSQL بعدد من المزايا مقارنة بقاعدة البيانات العلائقية التقليدية. يمكنهم معالجة مجموعات البيانات بطريقة أسرع وأكثر قابلية للتوسع من ذي قبل. تستفيد أنظمة إدارة قواعد البيانات أيضًا من معرفة وخبرة أقل من قواعد البيانات التقليدية ، مما يجعلها أسهل في الاستخدام. تتمتع قاعدة بيانات NoSQL بمجموعة متنوعة من المزايا مقارنة بقاعدة البيانات العلائقية التقليدية. أهم شيء يجب مراعاته هو ما إذا كنت تحتاجها للمعالجة في الوقت الفعلي ومجموعات البيانات الكبيرة.
قواعد بيانات Nosql هي الخيار الأفضل للشركات التي لديها أعباء عمل البيانات الضخمة
إذا كانت أعباء عمل البيانات لديك أكثر تركيزًا على تحليل ومعالجة كميات كبيرة من البيانات المتنوعة وغير المهيكلة ، مثل البيانات الكبيرة ، فإن قواعد بيانات NoSQL تعد خيارًا أفضل. على عكس قواعد البيانات العلائقية ، لا تعتمد قواعد بيانات NoSQL على نموذج مخطط ثابت. يعد نظام RDBMS أكثر مرونة من أنظمة RDBMS التقليدية من حيث تخزين البيانات ومعالجتها وإدارتها ، مما يجعله خيارًا أفضل للشركات التي تتطلب القدرة على الوصول بسرعة إلى كميات كبيرة من البيانات وتحتاج إلى تخزينها إلى أجل غير مسمى.
هل البيانات الضخمة SQL أم Nosql؟

إذا كانت أعباء عمل البيانات الخاصة بك معنية في المقام الأول بمعالجة وتحليل كميات كبيرة من البيانات المختلفة وغير المهيكلة بسرعة ، مثل البيانات الكبيرة ، فإن NoSQL هو أفضل رهان لك. يعتبر نموذج قاعدة بيانات NoSQL فريدًا من حيث أنه لا يعتمد على نفس بنية المخطط مثل قاعدة البيانات العلائقية.
لم يعد الأمر يتعلق بما إذا كانت البيانات الضخمة ستحسن التصنيع ؛ إنها مسألة وقت. في البيانات الضخمة ، تتوفر كميات هائلة ومتنوعة ومعقدة من البيانات المهيكلة وغير المهيكلة. يمكن استخدام المستشعرات والكاميرات الموجودة في أرضية الإنتاج والأجهزة الاستهلاكية لجمع البيانات الضخمة في التصنيع. نظرًا لأن معظم البيانات في التصنيع غير منظمة ، لا يمكن لبنى NoSQL التنافس مع الأساليب الصارمة مثل SQL. لا تتطلب قاعدة بيانات NoSQL أي مخططات لتخزين البيانات في نفس جدول قاعدة البيانات ، مما يسمح للمستخدمين بتخزين البيانات في هياكل مختلفة. يمكن تحديد خط فصل الشركة من خلال مقدار البيانات التي تنوي استخدامها. يجب أن تلتزم المعاملات بأربعة مبادئ تشغيل أساسية حتى يتم اعتبارها معاملة قاعدة بيانات علائقية.
نظرًا لأنه يمكن دمج أنظمة NoSQL وأنظمة السحابة ، فمن الجيد استخدام أطر عمل الحوسبة السحابية لدعم أنظمة NoSQL. يمكن تحسين عملية التصنيع في الوقت الفعلي عبر NoSQL من خلال التكامل مع أنظمة تنفيذ التصنيع (MES). أصبح هذا النجاح ممكنًا باستخدام تحليلات البيانات الضخمة لإنتاج استجابات أسرع للظروف المتغيرة. MongoDB هي قاعدة بيانات NoSQL جيدة لأنها سهلة الإعداد ويمكن استخدامها للتحليلات. يتيح استخدام هياكل قواعد البيانات ذات الاستجابة الأسرع مثل NoSQL للإدارة أداء عمليات محاكاة أفضل ، مما يسمح لهم باتخاذ قرارات أفضل بشأن المنتجات في العالم الحقيقي. قواعد بيانات B2B عرضة للهجمات عبر المواقع ، بالإضافة إلى هجمات الحقن وهجمات القوة الغاشمة. يحدث هجوم الحقن عندما يضيف المهاجم البيانات إلى أوامر استعلام NoSQL أو عبارات التخزين.

يهتم قطاع التصنيع بشكل خاص بأمان بنية NoSQL. إذا تم تسليم هجوم رفض الخدمة أو هجوم الحقن بنجاح ، فقد تتمكن الشركة المصنعة من تعديل المواصفات. لهذا السبب ، قد يتمكن المنافسون من الحصول على ميزة في سوق شديدة التنافسية.
أصبحت العمليات التجارية التي تعتمد على البيانات في الوقت الفعلي أكثر شيوعًا حيث تبحث الشركات عن طرق لتحسين كفاءتها واستجابتها لاحتياجات العملاء. توفر قواعد بيانات NoSQL المستندة إلى السحابة ، مثل Cloud Bigtable ، طريقة سريعة وفعالة لتخزين مجموعات البيانات الكبيرة والوصول إليها ، مما يجعلها حلاً ممتازًا لهذه الأنواع من التطبيقات.
Cloud Bigtable هي خدمة قاعدة بيانات NoSQL تتم إدارتها بالكامل وتوفر وقت تشغيل بنسبة 99.999٪. إنه مثالي لأحمال العمل التحليلية والتشغيلية لأنه يحتوي على سرعات عالية لتغذية البيانات ويسهل توسيع نطاقه وتقليصه. نتيجة لذلك ، يعد اختيارًا ممتازًا لمعالجة البيانات في الوقت الفعلي في تطبيقات مثل ألعاب الهاتف وتحليلات البيع بالتجزئة.
هل نصقل أفضل قاعدة بيانات للبيانات الكبيرة؟
MongoDB ، على سبيل المثال ، هو خيار ممتاز لتخزين كميات كبيرة من البيانات. أنها تتيح مجموعة واسعة من سيناريوهات المعالجة عالية الأداء ورشيقة. علاوة على ذلك ، يتم تخزين البيانات غير المهيكلة في قواعد بيانات NoSQL على عقد معالجة متعددة وعلى خوادم متعددة. نتيجة لذلك ، كانت قواعد بيانات NoSQL هي الاختيار الافتراضي لبعض أكبر مستودعات البيانات في العالم. ما هي أفضل قاعدة بيانات للبيانات الكبيرة؟ عندما يتعلق الأمر بهذا السؤال ، لا يمكن التنبؤ بقاعدة البيانات الأفضل للبيانات الكبيرة نظرًا للاحتياجات المتغيرة للمؤسسة. تعد Amazon Redshift و Azure Synapse Analytics و Microsoft SQL Server و Oracle Database و MySQL و IBM DB2 والعديد من قواعد البيانات الأخرى من بين الخيارات الأكثر شيوعًا لتخزين البيانات الكبيرة.
هل Hadoop قاعدة بيانات
Hadoop هو نظام ملفات موزع وإطار عمل لتشغيل التطبيقات على مجموعات كبيرة من الأجهزة السلعية. Hadoop ليس قاعدة بيانات.
يسمح Hadoop ، وهو إطار مفتوح المصدر ، بالتخزين الفعال ومعالجة مجموعات البيانات الضخمة. يمكن إنشاء جداول الخلية والحتمية باستخدام ملفات نصية في HDFS. وهو يدعم تنسيقات الملفات الرئيسية الثلاثة: ملفات التسلسل وملفات بيانات Avro وملفات باركيه. يتم تمثيل سلسلة البايت من خلال تسلسل البيانات كوحدة ذاكرة. Avro ، إطار عمل تسلسل بيانات فعال ، مدعوم على نطاق واسع بواسطة Hadoop ونظامه البيئي.
يؤدي استخدام الملفات النصية كتنسيق تخزين لجداول Hive و Implicit إلى تبسيط إدارة البيانات ومعالجتها. نتيجة لذلك ، يعد اختيارًا جيدًا لمعالجة الدُفعات أو تخزين البيانات بتنسيقات متنوعة. علاوة على ذلك ، يتيح تسلسل البيانات عبر Avro إمكانية تخزين البيانات واستعادتها بطريقة فعالة وملائمة. نتيجة لذلك ، يعد خيارًا جيدًا لتخزين البيانات في مجموعة متنوعة من التنسيقات أو إجراء معالجة متوازية.
Hadoop مقابل Nosql
يعالج Hadoop البيانات الضخمة لمجموعة من الأجهزة السلعية. إذا كانت الوظيفة لا تلبي احتياجاتك أو لا تعمل ، فيمكن تغييرها. يشار إلى هذا باسم NoSQL ، وهو نوع من نظام إدارة قواعد البيانات الذي يخزن البيانات المهيكلة وشبه المهيكلة وغير المهيكلة.
تم إنشاء MongoDB ، باعتبارها قاعدة بيانات NoSQL (ليس فقط SQL) ، في عام 2007 كنتيجة لتطوير C ++. Hadoop عبارة عن مجموعة من البرامج مفتوحة المصدر التي تمت كتابتها بشكل أساسي بلغة Java لمعالجة البيانات الكبيرة. يتضمن هذا النظام الأساسي أيضًا البحث عن نص كامل ، وأدوات تحليلات متقدمة ، ولغة استعلام سهلة الاستخدام. على الرغم من أن Hadoop معروف بقدرته على تخزين ومعالجة كميات كبيرة من البيانات ، إلا أنه يفعل ذلك أيضًا على دفعات صغيرة. يوفر MongoDB مجموعة متنوعة من أدوات معالجة البيانات في الوقت الفعلي. تجعل موصلات MongoDB للأدوات الخارجية ، مثل كافكا وسبارك ، استيعاب البيانات ومعالجتها أمرًا بسيطًا. عندما يتعلق الأمر بمعالجة البيانات ، يوفر Hadoop و MongoDB مجموعة واسعة من المزايا مقارنة بقواعد البيانات التقليدية. Hadoop هي أداة ممتازة للتعامل مع هياكل البيانات الكبيرة بسبب نظام الملفات الموزع. MongoDB هي قاعدة البيانات الوحيدة التي يمكن استخدامها كبديل لقواعد البيانات التقليدية.
هو شرارة قاعدة بيانات Nosql
في التوثيق ، تم النص على أن NoSQL DataFrame هو Spark DataFrame استنادًا إلى تنسيق Spark لتخزين البيانات. على عكس مصادر البيانات السابقة ، يدعم هذا المصدر تقليم البيانات والتصفية (الضغط المسند) ، مما يسمح لاستعلامات Spark بالاستعلام عن بيانات أقل وتحميل البيانات المطلوبة فقط حسب الحاجة.
من الأهمية بمكان الحفاظ على الوعي التكتيكي عند استخدام قواعد بيانات Apache Spark و NoSQL ( Apache Cassandra و MongoDB) معًا في أحد التطبيقات. تركز هذه المدونة على كيفية استخدام Apache Spark في تطبيق NoSQL. تعتبر CassandraLand و MongoLand في TCP / IP sPark من أكثر الألعاب شعبية ، وهي مكان رائع للزيارة إذا كنت تحب الحدائق الترفيهية. أثناء البحث عن بيانات وزارة الطاقة ، بدأ تطبيق Spark الخاص بنا في تدوير عجلاته. إليك درس سريع حول مدى أهمية تسلسل مفتاح Cassandra عندما يتعلق الأمر بالاستعلام. هناك أيضًا قطار الأفعوانية التقسيم في CassandraLand. يمكن للعملاء الذين يستمتعون بركوب الأفعوانية مشاركة معلوماتهم مع مشغلي الركوب حتى يتمكنوا من تتبع من ركبهم على أساس يومي.
الدرس الأول في درس MongoDB 1 هو إدارة اتصالات MongoDB بشكل صحيح. عندما تحتاج إلى تحديث المعلومات حول حالة عضوية المتنزه الجديدة لوزارة الطاقة ، فإن فهارس Mongo مفيدة للغاية. بصفتك عميل MongoDB أو Spark ، يجب عليك الحفاظ على اتصال وفهارس مناسبين في حالة تحديثات النظام.