
3 wichtige Dinge, die Sie beim Modellieren von Daten in einer NoSQL-Datenbank beachten sollten
Veröffentlicht: 2023-02-27Bei der Modellierung von Daten in einer NoSQL-Datenbank sind einige wichtige Dinge zu beachten. Zunächst ist es wichtig, den Unterschied zwischen relationalen und nicht relationalen Datenbanken zu verstehen. Relationale Datenbanken wie MySQL speichern Daten in Tabellen und Zeilen. Nicht relationale Datenbanken wie MongoDB speichern Daten in Dokumenten. Das bedeutet, dass Sie beim Modellieren von Daten in einer NoSQL-Datenbank darüber nachdenken müssen, wie Sie Ihre Daten so strukturieren, dass sie für eine dokumentenbasierte Datenbank sinnvoll sind. Zweitens ist es wichtig, die Arten von Abfragen zu berücksichtigen, die Sie für Ihre Daten durchführen müssen. In einer relationalen Datenbank verwenden Sie normalerweise SQL zum Abfragen von Daten. In einer NoSQL-Datenbank müssen Sie jedoch eine andere Abfragesprache verwenden. In MongoDB verwenden Sie beispielsweise die MongoDB Query Language (MQL). Schließlich ist es wichtig, darüber nachzudenken, wie Sie Ihre Daten indizieren. In einer relationalen Datenbank indizieren Sie Daten normalerweise, indem Sie Indizes für Tabellen und Spalten erstellen. In einer NoSQL-Datenbank müssen Sie die Daten jedoch anders indizieren. In MongoDB können Sie beispielsweise Indizes für Dokumente und Felder erstellen. Wenn Sie diese drei Dinge beachten, können Sie Daten in einer NoSQL-Datenbank effizient und skalierbar modellieren.
SQL-Datenbanken, die auf mehrere Computer verteilt sind, sollen sich vom relationalen Modell lösen. Es gibt ein weit verbreitetes Missverständnis, dass NoSQL-Datenbanken kein Datenmodell haben. Der erste Schritt beim Erstellen eines Schemas besteht darin, zu beschreiben, wie die Daten organisiert werden. Da jeder Typ von NoSQL-Datenbank seinen eigenen Satz von Datenmodellen hat, sind die Unterschiede zwischen ihnen natürlich. Infolgedessen wird das Schemadesign während der gesamten Lebensdauer der Anwendung iterativ sein. Eine der wichtigsten Überlegungen bei der Entscheidung, welche NoSQL-Datenbank verwendet werden soll, ist der Anwendungsfall, für den das Datenmodell am besten geeignet ist. Jedes Dokument speichert neben einer Vielzahl von Datentypen und Datenstrukturen mehrere Felder und Werte.
Eine Vielzahl leistungsfähiger Abfragesprachen wurde entwickelt, um mit verschiedenen Arten von Feldwerten umzugehen, und Abfragen können verwendet werden, um Feldwerte abzurufen. Eine NoSQL-Datenbank enthält in jeder Zeile einen Schlüssel und eine zugehörige Spalte, die als Spaltenfamilien bezeichnet werden. Es ist die zugrunde liegende Struktur, die Daten in jedem der vier Haupttypen von NoSQL-Datenbanken speichert. Obwohl die Details der Datenorganisation sehr flexibel sind, kann manchmal sogar ein „schemaloses“ System erforderlich sein. Dokumentdatenbanken, Datenbanken mit breiten Spalten und Graphdatenbanken haben typischerweise eine spezifische Abfragesprache, die in sie eingebaut ist.
Beispiel für ein Nosql-Datenbankschema
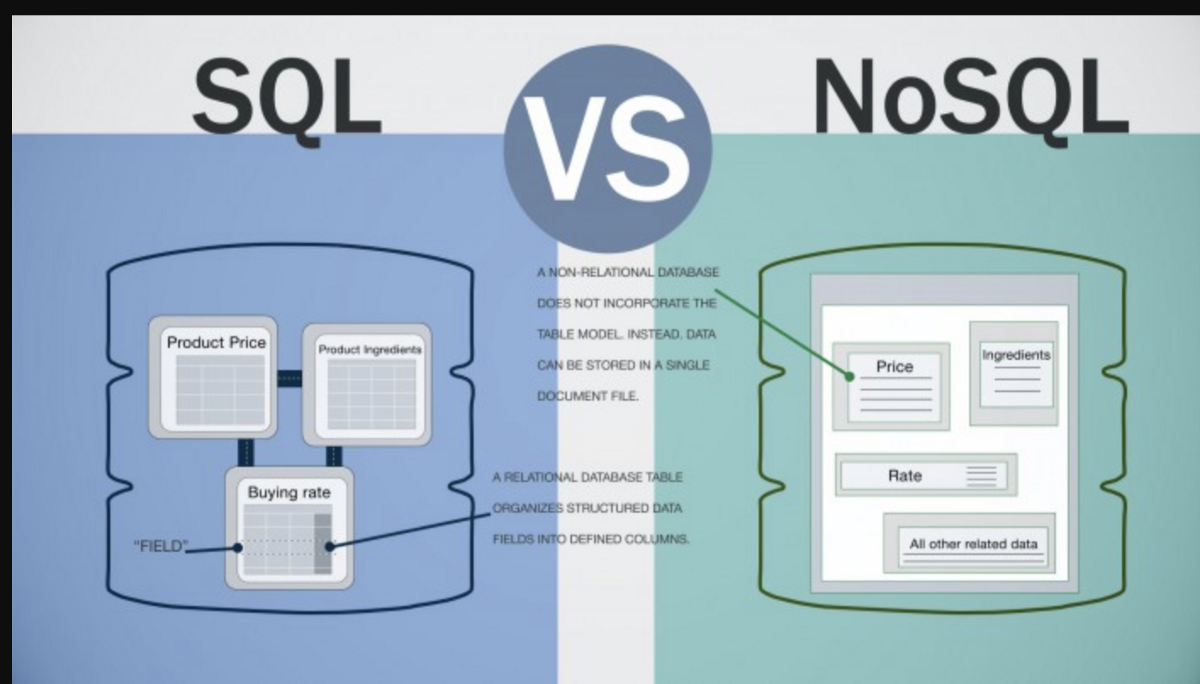
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das traditionelle tabellenbasierte Schema einer relationalen Datenbank verwendet. NoSQL-Datenbanken werden häufig zum Speichern großer Datenmengen verwendet, die für eine relationale Datenbank nicht gut geeignet sind, z. B. Daten, die unstrukturiert sind, eine große Anzahl von Beziehungen aufweisen oder sich ständig ändern.
Es ist nicht notwendig, ein festes Schema zu verwenden, um Daten in NoSQL-Datenbanken zu verwalten, da sie keine Hierarchie haben. Aufgrund der Menge an generierten und verbrauchten Daten werden NoSQL-Datenbanken für verteilte Datenspeicher mit hohem Speicherbedarf verwendet. Twitter, Facebook und Google gehören zu den Unternehmen, die NoSQL verwenden, um Daten zu speichern und Echtzeit-Webanwendungen zu erstellen. Daten können in einer Schlüssel-Wert-Datenbank gespeichert und als Schlüssel-Wert-Paar verwendet werden, indem sie aus der Datenbank abgerufen werden. Assoziative Array- und Sammlungsdatenbanktypen sind übliche Anwendungen dieser Art von NoSQL-Datenbank. Ein Dokumenttyp dient normalerweise als Grundlage für Content-Management-Systeme (CMS), Blogging-Plattformen, Echtzeitanalysen und E-Commerce-Anwendungen. Daten in der Graphdatenbank können verwendet werden, um soziale Netzwerke, Logistik oder räumliche Karten aufzubauen.
CouchDB Views können in MapReduce über das System definiert werden. Demnach können verteilte Datenspeicher nicht mehr als zwei von drei Dingen garantieren. Konsistenz ist im Allgemeinen entscheidend für die Datenkonsistenz, selbst nachdem eine Operation abgeschlossen wurde. Wenn Server nicht miteinander kommunizieren können, sollte die Partitionstoleranz beibehalten werden.
Nosql-Datenbanken: Die neue Normalität?
Die NoSQL-Datenbankplattform ist flexibler und effizienter als die traditionelle relationale Datenbankplattform . Da sie kein starres Schema erfordern, sind diese Arten von Datenbanken häufig einfacher zu verwenden. Andererseits verfügen sie nicht über alle Fähigkeiten einer relationalen Datenbank.
Nosql-Datenmodellierung
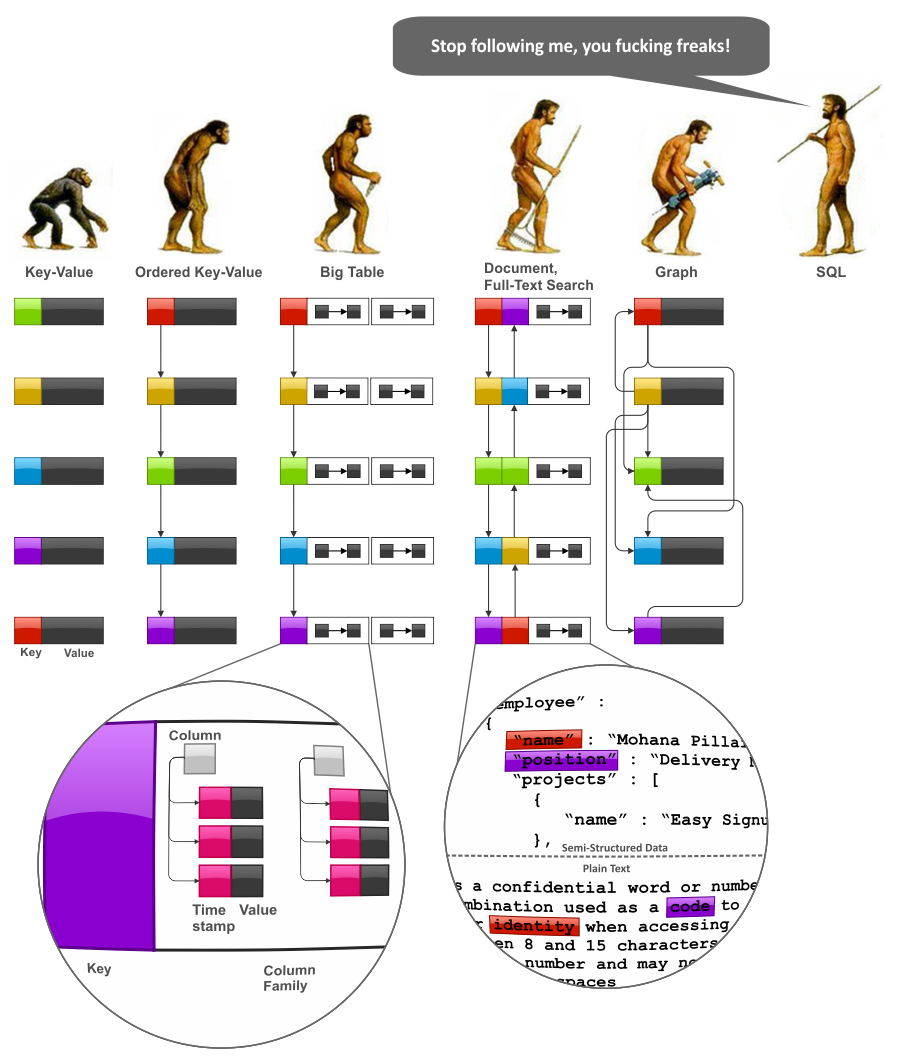
Was ist ein NoSQL-Datenmodell ? Dieses Modell ist nicht auf die Verwendung eines relationalen Datenbankverwaltungssystems (RDBMS) angewiesen. Infolgedessen ist das Modell mehrdeutig darüber, wie Daten miteinander interagieren – wie alles miteinander verbunden ist.
8 Datenmodellierungsmuster in Redis ist ein ausgezeichnetes Buch zum Erlernen der Datenmodellierung in Redis. Es werden acht Datenmodelle erörtert, die zum Erstellen moderner Anwendungen ohne die Einschränkungen einer traditionellen relationalen Datenbank verwendet werden können, die unerschwinglich teuer sein kann. Die NoSQL-Plattform ermöglicht die Integration von zwei separaten Tabellen oder Sammlungen mit einer Tabelle. Dadurch können sie ihre Beziehung besser verstehen und alle relevanten Daten leichter finden. Jede Tabelle ist eine eigene Ansicht in NoSQL-Anwendungen, was bedeutet, dass ihre Leistung unabhängig von der Anwendung ist. Eine begrenzte Liste (z. B. Listen bekannter Größe) wird als unbegrenzte Liste eingebettet, während eine unbegrenzte Liste separat als unbegrenzte Liste eingebettet wird. In diesem Fall ist es derjenige, also werden folgende Variablen benötigt: das Produkt, der Autor, das Erscheinungsdatum, die Bewertung und der Kommentar.
Das erste Muster hat Viele-zu-Viele-Beziehungen mit unbegrenzten Seiten. In einer relationalen Datenbank müssen Sie verschiedene Arten von Produkten verfolgen, indem Sie sie in Tabellen unterteilen. Durch die Verwendung von Redis Stack ist es möglich, zwischen Typfeldern für Sammlungen zu unterscheiden. Während Sie das Bucket-Muster durchlaufen, reduzieren Sie den Overhead, indem Sie Zeitreihendaten speichern und verwalten. Viele Anwendungsfälle können durch die Verwendung des Revisionsmusters in Verbindung mit Echtzeitdaten verbessert werden. Mit NoSQL können Sie diese Muster auf vielfältige Weise verwenden, um die Komplexität von JOIN-Vorgängen zu reduzieren. Umfangreiche JOIN-Operationen wie HR-Systeme, CMS, Produktkataloge und soziale Netzwerke erfordern die Verwendung des Baum- und Diagrammmusters.
Es ist nicht auf die Verwendung eines relationalen Datenbankverwaltungssystems (RDBMS) zur Verstärkung angewiesen. Daten können auf einer Festplatte, einem In-Memory-Laufwerk oder beidem gespeichert werden. Die Verwendung von Redis und NoSQL zum Erstellen von Anwendungen wird in einer Reihe von Beispielen auf Redis Launchpad demonstriert.
Nosql-Datenbanken: Der beste Weg, nicht relationale Daten zu speichern
Somenosql-Datenbanken hingegen können auf relationalen Datenbanken ausgeführt werden. MongoDB und Cassandra verwenden beispielsweise den B-Tree-Index, der in einer Vielzahl von Datenbanken zu finden ist. Das in Neo4j verwendete Graphenmodell ist nicht mit relationalen Datenbanken kompatibel. NoSQL-Datenbanken werden immer beliebter, weil sie flexibler und effizienter sind als herkömmliche Datenbanken . Es ist keine Überraschung, dass eine nosql-Datenbank eine ausgezeichnete Wahl ist, wenn Sie ein Datenmodell benötigen, das nicht auf dem relationalen Modell basiert.
So entwerfen Sie eine Nosql-Datenbank
Auf diese Frage gibt es keine endgültige Antwort, da die beste Art und Weise, eine NoSQL-Datenbank zu entwerfen, von den spezifischen Anforderungen der Anwendung abhängt. Es gibt jedoch einige allgemeine Tipps, die befolgt werden können, um sicherzustellen, dass die Datenbank optimal gestaltet ist. Zunächst ist es wichtig, die Daten zu verstehen, die in der Datenbank gespeichert werden, und die Beziehungen zwischen den Daten. Dies hilft bei der Bestimmung des besten Schemas für die Daten. Als nächstes ist es wichtig, die richtige NoSQL-Datenbanktechnologie für die Anwendung auszuwählen. Es gibt eine Reihe verschiedener Technologien, jede mit ihren eigenen Stärken und Schwächen. Schließlich ist es wichtig, die Datenbank auf Leistung zu entwerfen. Dies bedeutet, Dinge wie Indizierung und Sharding zu berücksichtigen.

Mit normalisiertem RDBMS können Sie die inhärenten Stärken des relationalen Paradigmas nutzen. Der Hauptvorteil von NoSQL-Datenbanken besteht darin, dass sie halbstrukturierte Aggregate und dynamische Entitäten modellieren können. Anstelle von Entitäten und Beziehungen sollten Sie überlegen, wie Sie NoSql in Bezug auf Hierarchie und Aggregate modellieren. Denormalisierung, wie sie in RDBMS definiert ist, fährt Ihre DB effektiv zu einer NoSQL-Datenbank herunter. Wenn Sie nur eine Teilmenge eines Aggregats benötigen, müssen Sie Code hinzufügen, oder wenn Sie ein Aggregat von Aggregaten benötigen, müssen Sie es parsen. Es ist wichtig, Ihre Beziehungen so früh wie möglich zu identifizieren.
Nosql-Design
Ein NoSQL-Datenmodell konzentriert sich im Gegensatz zu einem anwendungsorientierten Ansatz darauf, wie die Anwendung die Daten abfragt, und nicht auf die Beziehungen innerhalb der Daten. Anstelle eines starren relationalen Schemas betonen die Konstruktionsprinzipien von NoSQL-Datenbanken die Flexibilität der Daten.
NoSQL-Datenbanken sollten daher mit einer entsprechenden Änderung der Anwendungsarchitektur einhergehen. Die Serverkomplexität wird im Rahmen des NoSQL-Ansatzes von SQL-basierten Datenbanken wegverlagert. In diesem Artikel werden wir uns mit den verschiedenen Aspekten der Datenverwaltung befassen und eine Architektur empfehlen, die eine Datenverwaltungsebene anstelle von NoSQL-Datenbanken verwendet. Objektorientierte NoSQL-Datenbanken haben typischerweise verschachtelte Strukturen für Datenentitäten. Wenn die Kinder/Unterstrukturen eines übergeordneten Dokuments immer innerhalb des Dokuments zugänglich sind, funktionieren verschachtelte Datenstrukturen gut. Bidirektionale Beziehungen können in einigen Fällen durch die Verwendung von verschachtelten Strukturen vermieden werden. In einigen kritischen Anwendungen sind immer noch Beziehungen erforderlich.
Es ist sehr gut verstanden, wie man Beziehungen zu traditionellen RDBMS verwaltet. Wie können wir Beziehungen mit NoSQL-Datenbanken modellieren? Sie könnten eine von zwei Strategien ausprobieren. Eine Möglichkeit, die Datenduplizierung auf ein Minimum zu beschränken, ist der Einsatz von Normalisierungsstrategien. Eine Option besteht darin, Daten zu denormalisieren, was die Abfrageleistung verbessern kann. Der NoSQL-Ansatz zur Datenverwaltung läuft Gefahr, falsch interpretiert zu werden, wenn er versucht, Edgar Codds historische Säulen der Datenverwaltung zu untergraben. Daher sollte der Datenbankzugriff eher als interne Komponente der Implementierung denn als wiederverwendbare API betrachtet werden.
Es ist wichtig, die Datenkonsistenz über NoSQL-Speicher und -Datenbanken hinweg aufrechtzuerhalten. Schlüsselwert-Dokumentdatenbanken wurden mithilfe einer Index-API ähnlich der DB-API von Berkeley indiziert. Das W3C ist zu dem Schluss gekommen, dass NoSQL-Datenbanken laut Berichten einen programmgesteuerten Zugriff auf Indizes und keinen abfragebasierten Zugriff haben sollten. Infolgedessen müssen Datengültigkeits- und Integritätseinschränkungen weiterhin durchgesetzt werden. Indem wir die Validierung aus der Speicherschicht verlagern, können wir sie in unserer Datenverwaltungsschicht zentralisieren. Konsistenzbasierte Replikationssysteme können im Allgemeinen basierend auf einer strengeren Transaktionssemantik auf individuellen Datenbankspeichersystemen implementiert werden. Benutzerdefinierte Replikation und Konsistenzerzwingung sind äußerst nützlich für Anwendungen, die eine höhere Integrität oder eine größere Skalierbarkeit von entspannter Konsistenz erfordern.
Die Auflösung von Konflikten in CouchDB mithilfe der Konfliktlösung im Stil von Multi-Version Concurency Control (MVCC) ist manchmal naiv. In Persevere 2.0 kann ein Datenmodell definiert und Produkte mit ihren Herstellern verknüpft werden. Als Ergebnis unserer Bemühungen wurde das MVC-Architekturmodell effektiv implementiert. Die Rekapitalisierung dieser Art von Benutzerschnittstellenebene als mVC weist auf eine Verlagerung des Schwerpunkts weg von Datenmodellierungsbelangen in der Benutzerschnittstellenlogik hin.
Was ist Nosql und Beispiel?
Eine NoSQL-Datenbank (auch als SQL bezeichnet) ist ein Datenbanktyp, der Daten auf andere Weise speichert als eine relationale Datenbank. Der Begriff NoSQL bezeichnet ein Datenmodell, das die Gestaltung einer Vielzahl von Datenbanken ermöglicht. Dokumenttypen, Schlüsselwerttypen, Breitspaltentypen und Diagramme sind die häufigsten.
Was ist die Architektur von Nosql?
Mit dem NoSQL-Datenbankansatz müssen Server, auf denen SQL-basierte Datenbanken ausgeführt werden, keine großen Datenmengen mehr verarbeiten. Validierung, Zugriffskontrolle, Datenzuordnung, Korrelationsaktivitäten, Konfliktlösung, Aufrechterhaltung von Integritätsbeschränkungen und ausgelöste Prozeduren werden alle aus der Datenbankschicht entfernt.
Die Vorteile von Nosql Cloud-Datenbanken
Die Verwendung einer Nosql-Cloud-Datenbank bietet gegenüber einer herkömmlichen relationalen Datenbank mehrere Vorteile. Sie sind flexibler in der Skalierung. Sie sind in Bezug auf Lese- und Schreibvorgänge leistungsfähiger als andere Arten von Software. Der dritte Vorteil ist, dass sie besser mit Datenänderungen umgehen können.
Welches Tool wird für das Nosql-Datenbankdesign verwendet?
Hackolade, DbSchema und Cassandra Data Modeler sind einige der Entwurfstools für NoSQL-Datenbankschemas. Das visuelle Schemadesign von Hackolade ist ideal für NoSQL-Datenbanken jeglicher Art. DbSchema extrahiert Schemata aus bestehenden NoSQL-Datenbanken und konvertiert sie in XML.
SQL oder Nosql?
NoSQL-Datenmodelle erfreuen sich wachsender Beliebtheit, da sie einfach zu verwenden sind und keine produktübergreifende Konsistenz aufweisen. SQL-Datenbanken erleichtern die Durchführung komplexer Abfragen für strukturierte Daten, indem Abfragen verarbeitet und Daten tabellenübergreifend verknüpft werden. Der Mangel an Konsistenz zwischen NoSQL-Datenbanken sowie die Notwendigkeit, Daten häufiger abzufragen, kann zu einer längeren Abfragezeit führen. Wenn Sie Daten zu analytischen Zwecken schnell abfragen müssen, ist eine SQL-Datenbank die wahrscheinlichste Lösung. Wenn Sie Daten jedoch in einem flexibleren und weniger strukturierten Format speichern müssen, ist ein NoSQL-Datenmodell möglicherweise besser für Sie geeignet.
Nosql-Dokument
Nosql-Dokumentendatenbanken werden immer beliebter, da der Bedarf an schnelleren und flexibleren Datenverwaltungslösungen wächst. Diese Datenbanken sind auf hohe Leistung, Skalierbarkeit und Flexibilität ausgelegt und eignen sich daher ideal für eine Vielzahl von Anwendungen.
Dokumentorientierte Datenbanken sind ein moderner Ansatz, der JSON anstelle von Spalten und Zeilen als Datenspeicher verwendet. Wenn Sie mit halbstrukturierten Daten arbeiten, können Sie Probleme lösen, die mit RDBMSs schwieriger zu erfassen sind. Dokumentenspeicher sind eine natürliche und flexible Lösung für agile Entwickler, die mit ihnen schneller arbeiten können. Die ausdrucksstarke Abfragesprache und die vielseitige Indizierung bieten Ihnen vielfältige Abfragemöglichkeiten. Sie können weiterhin von der Garantie für relationale Datenbanken profitieren, indem Sie ACID-Transaktionen durchführen. Sie können mehr darüber erfahren, wie verteilte Systeme die Skalierbarkeit und Widerstandsfähigkeit Ihrer Daten erhöhen können, indem Sie „distributedsystems.com“ besuchen. Die einzelnen Dokumente sind eigenständige Einheiten, was eine serverübergreifende Verteilung erleichtert, ohne dass die Datenlokalität darunter leidet.
Die Verwendung intuitiver, praktischer Modellierung in Dokumentendatenbanken ermöglicht ein schnelleres Lesen von Modellen als in relationalen Datenbanken. Es wird eine geringere Datenqualität erwartet, und es besteht die Gefahr einer Datenverschlechterung aufgrund starrer Tabellen. Es gibt kein natives Scale-out in der relationalen Datenbank. Wenn Sie also Ihre vorhandene Datenbank partitionieren (sharden) möchten, müssen Sie für ein kostspieliges Scale-up-System bezahlen. Dokumentorientierte Datenbanken können verschiedene Arten von Dokumenten speichern und müssen normalerweise keine Felder eingeben. Trotz der Tatsache, dass jedes Feld unterschiedlich ist, gibt es eine gemeinsame strukturelle Zusammensetzung. Jedes Dokument enthält eine eindeutige ID, mit der Informationen hinzugefügt, geändert, gelöscht oder abgefragt werden können. Das Einkapseln von eingekapselten Daten (oder Informationen) erfolgt normalerweise in einem Standardformat oder einer Dekodierung.
Dokumentorientierte Datenbanken haben eine viel flexiblere Struktur als eine traditionelle Datenbank . Daten werden direkt aus dem Dokument und nicht aus Spalten innerhalb der Datenbank gespeichert, wenn sie abgefragt werden. Die einzigen Datenfelder, die hinzugefügt werden müssen, sind diejenigen, die für den Datensatz in der Dokumentenablage relevant sind.
Warum Dokumente zum Speichern von Dateien besser sind als relationale Tabellen
Dokumente werden häufig zum Speichern von Dateien verwendet, da sie für die Speicherung großer Dateien effizienter sind als relationale Datenbanken. Dokumentdokumente haben auch den Vorteil, dass sie bequem zu durchsuchen und zu manipulieren sind.