
3 Dinge, die Sie beim Modellieren von Daten für eine NoSQL-Datenbank beachten sollten
Veröffentlicht: 2023-01-25NoSQL-Datenbanken werden immer beliebter, da die Menge der generierten Daten weiterhin exponentiell wächst. Im Gegensatz zu herkömmlichen relationalen Datenbanken , die auf einem festen Schema basieren, sind NoSQL-Datenbanken schemafrei, wodurch sie viel flexibler und einfacher zu skalieren sind. Bei der Modellierung von Daten für eine NoSQL-Datenbank sind einige Dinge zu beachten. Erstens müssen Sie sich keine Gedanken über die Definition von Spalten oder Datentypen machen, da es kein Schema gibt. Das bedeutet, dass Sie Ihre Daten so strukturieren können, wie Sie es für richtig halten. Zweitens müssen Sie sich Gedanken darüber machen, wie Ihre Daten auf mehrere Server verteilt werden, da NoSQL-Datenbanken skalierbar sind. Dies wird als Sharding bezeichnet und muss beim Entwerfen Ihres Datenmodells von Anfang an berücksichtigt werden. Schließlich werden NoSQL-Datenbanken häufig zum Speichern großer Mengen unstrukturierter Daten verwendet. Das bedeutet, dass Ihr Datenmodell wahrscheinlich viel einfacher sein wird als bei einer relationalen Datenbank. Behalten Sie diese Dinge im Hinterkopf und Sie sind auf dem besten Weg, Daten für eine NoSQL-Datenbank zu modellieren.
In SQL-Datenbanken werden Daten immer dann in eine andere Tabelle abgerufen, wenn sie dupliziert werden. Datenmodelle werden mithilfe von REST-API-Antworten erstellt, die gegen eine Zeile in der Datenbank aufgetragen werden. Um mehrere Zeilen zu einer einzigen Tabelle zusammenzufügen, dürfen Sie nicht mehr als einmal zur Festplatte zurückkehren. Eine NoSQL-Datenbank hat eine bessere Leistung, da sie weiter verbreitet ist. In einer NoSQL-Datenbank können Zeilen unterschiedliche Felder enthalten. Sie müssen Daten nicht in mehreren Tabellen speichern, wenn Sie nicht verschiedene Arten von Daten wie Bestelldetails oder Kundeninformationen aufbewahren müssen. NoSQL-Datenbanken, die in mehrere Partitionen aufgeteilt werden können, können auf einer Vielzahl von Servern bereitgestellt werden.
Der Partitionsschlüssel bestimmt, in welche Partition eine Zeile unterteilt wird. Die Sekundärindizes von DynamoDB sind in zwei Varianten verfügbar: lokal und global. Während ein lokaler sekundärer Index einen Sortierschlüssel hat, der sich vom Partitionsschlüssel unterscheidet, muss er identisch sein. Darüber hinaus kann ein globaler Sekundärindex verwendet werden, um eine einheitliche Ansicht aller Artikel in Ihrem Portfolio zu erstellen. Das Lesen von 100 Zeilen von einer Festplatte kann ineffizient sein, wenn Sie sie herausfiltern und nur 2 Zeilen zurückgeben möchten. Denken Sie unbedingt daran, dass Sie bei der Verwendung von NoSQL-Datenbanken Ihre Daten anders modellieren sollten, als wenn Sie sie in relationalen Datenbanken modellieren würden. Da die Daten gemäß der erwarteten Abfrage strukturiert werden müssen, gelten NoSQL-Datenbanken manchmal als weniger flexibel als Datenbanken, die auf relationalen Datenstrukturen basieren.
Die Frage ist, ob Sie Beziehungen explizit in einem RDBMS oder implizit in einer NoDatabase codieren. Der Vorteil von NoSQL ist seine Skalierbarkeit. Die RDS-Instanz kann mit einer maximalen Kapazität von 1 TB Arbeitsspeicher und 128 vCPUs ausgeführt werden, was mehr als der doppelten Kapazität von 99 % der Startups entspricht. DynamoDB hingegen ist nur über Amazon Web Services verfügbar, während Open-Source-Datenbanken Sie nicht an einen Cloud-Anbieter binden.
Der Begriff NoSQL bezieht sich auf vier Arten von Datenbanken: Schlüsselwertspeicher, dokumentbasierte Speicher, spaltenbasierte Speicher und graphbasierte Speicher. Die drei Haupttypen der NoSQL-Datenmodellierung sind konzeptionell, allgemein und hierarchisch.
Was ist ein NoSQL-Datenmodell? Das Modell stützt sich nicht auf ein relationales Datenbankverwaltungssystem (RDBMS). Infolgedessen gibt das Modell nicht an, wie sich die Daten beziehen oder wie alles miteinander verbunden ist.
Die Fähigkeit, große Datenmengen abzufragen, ist eine der wichtigsten Eigenschaften von NoSQL-Systemen . Dokumentendatenbanken können eine Vielzahl von Anwendungen unterstützen, da sie die meisten Funktionen bieten. Auf die Daten kann auf verschiedene Arten zugegriffen werden, einschließlich der Verwendung von Primärschlüsseln in Schlüsselwertspeichern und Wide-Column-Speichern.
Das Ziel von NoSQL-Datenbanken ist es, sich von den Zeilen und Spalten einer relationalen Datenbank zu lösen. Die meisten Leute verwechseln NoSQL-Datenbanken mit dem Fehlen eines Datenmodells, was ein weit verbreitetes Missverständnis ist. Der vorangegangene Abschnitt beschreibt, wie Daten in einem Schema organisiert werden.
Nosql-Datenmodellierungsbeispiel
Es gibt viele verschiedene Möglichkeiten, Daten in einer Nosql-Datenbank zu modellieren, und der beste Ansatz hängt von der spezifischen Anwendung und den Datenanforderungen ab. Eine gängige Methode zum Modellieren von Daten in einem Schlüsselwertspeicher ist beispielsweise die Verwendung einer Hash-Map, die eine schnelle Suche nach Datensätzen nach Schlüssel ermöglicht. Eine weitere beliebte Möglichkeit, Daten in einer dokumentenorientierten Datenbank zu modellieren, ist die Verwendung verschachtelter Dokumente, die komplexe Datenstrukturen effizienter darstellen können als eine traditionelle relationale Datenbank .
Nosql-Datenbankmodellierungstools
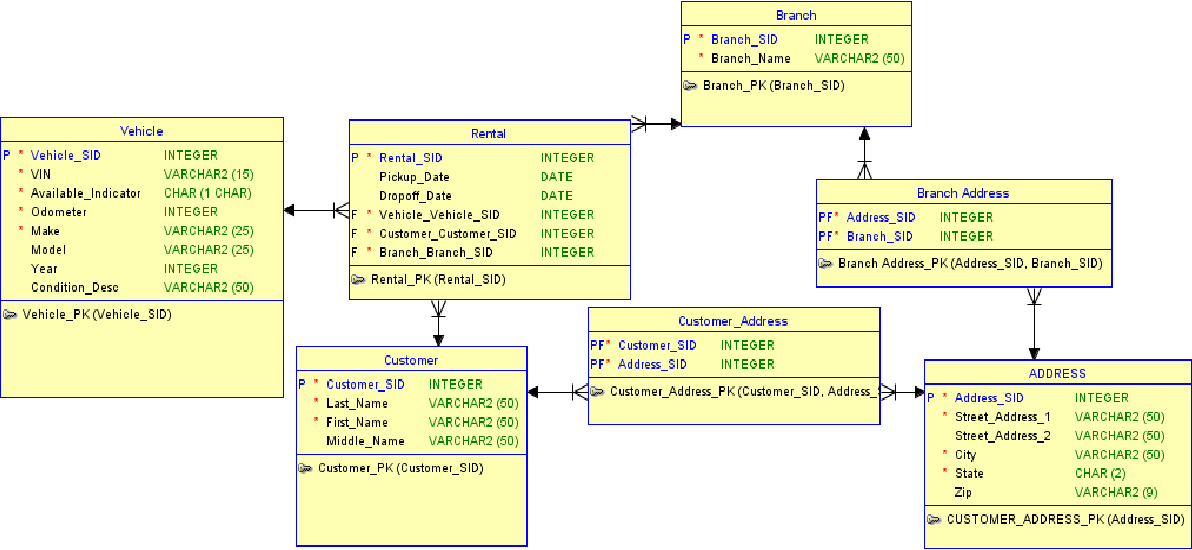
Wenn es um Nosql-Datenbankmodellierungstools geht, stehen einige verschiedene Optionen zur Auswahl. Beispielsweise gibt es Tools, die sich darauf konzentrieren, Ihnen beim Entwerfen und Visualisieren Ihres Datenmodells zu helfen, sowie andere, die sich darauf konzentrieren, Ihnen bei der Verwaltung und Optimierung Ihrer nosql-Datenbank zu helfen. Unabhängig von Ihren spezifischen Anforderungen gibt es wahrscheinlich ein nosql-Datenbankmodellierungstool, das Ihnen helfen kann.
NoSQL-Datenbanken sind flexibler als relationale Datenbanken, indem sie in kleinere Teile zerlegt werden. Die meisten Menschen verwechseln NoSQL-Datenbanken damit, dass sie überhaupt kein Datenmodell haben. Das Verständnis, wie Daten organisiert werden, ist ein wichtiger Schritt bei der Erstellung eines Schemas. Diese Unterschiede spiegeln sich in Datenmodellen für jeden der vier Haupttypen von NoSQL-Datenbanken wider. Infolgedessen wird das Schemadesign im Laufe der Zeit iterativ sein, um die Anforderungen der Anwendung zu erfüllen. Um die richtige NoSQL-Datenbank für Sie auszuwählen, müssen Sie zunächst bestimmen, welches Datenmodell für Ihren Anwendungsfall am besten geeignet ist. Es stehen zahlreiche Arten von Datentypen und Datenstrukturen zur Auswahl, wenn es darum geht, Werte und Felder in jedem Dokument zu speichern.
Es wurden mehrere leistungsstarke Abfragesprachen entwickelt, um eine breite Palette von Feldwerttypen zu verarbeiten, und Felder werden mithilfe von Abfragen abgerufen. Eine Zeile in einer NoSQL-Datenbank besteht aus einem Schlüssel und einer zugehörigen Spalte, die als Spaltenfamilie bezeichnet wird. NoSQL-Datenbanken bestehen aus vier Arten von zugrunde liegenden Strukturen, die Daten speichern. Obwohl die Art und Weise, wie die Daten organisiert sind, sehr anpassungsfähig ist, kann sie gelegentlich als XML-los bezeichnet werden. Dokumentdatenbanken, Datenbanken mit breiten Spalten und Diagrammdatenbanken sind normalerweise so konfiguriert, dass sie eine bestimmte Abfragesprache verwenden.
NoSQL-Datenbanken werden immer beliebter, da sie eine flexiblere und dynamischere Art der Datenspeicherung bieten. Da diese Datenbanken für die Cloud konzipiert sind, können sie horizontal skaliert werden, was sie ideal für Unternehmen macht, die mit schnellem Wachstum Schritt halten möchten.
Was ist ein Datenbankmodellierungstool?
Ein Datenmodellierungstool ist eine Softwareanwendung, mit der Sie Datenbankstrukturen basierend auf Diagrammen erstellen können, wodurch es einfacher wird, eine auf Ihre Bedürfnisse zugeschnittene Datenstruktur zu erstellen. Benutzer können Infografiken, Diagramme, Datenvisualisierungen und Flussdiagramme erstellen, die auf ihre spezifische Branche zugeschnitten sind.
Best Practices für das Design von Nosql-Datenbanken
Beim Entwerfen einer NoSQL-Datenbank ist es wichtig, die folgenden Best Practices zu berücksichtigen:
1. Halten Sie es einfach: NoSQL-Datenbanken sind so konzipiert, dass sie einfach und benutzerfreundlich sind. Daher ist es wichtig, das Design so einfach wie möglich zu halten.
2. Joins vermeiden: Joins werden in NoSQL-Datenbanken nicht unterstützt. Daher ist es wichtig, sie beim Entwerfen der Datenbank zu vermeiden.
3. Daten denormalisieren: Das Denormalisieren von Daten ist eine gängige Praxis in NoSQL-Datenbanken. Das bedeutet, dass Daten dupliziert werden, um die Performance zu verbessern.
4. Verwenden Sie ein Schema: Ein Schema ist in einer NoSQL-Datenbank nicht erforderlich, kann aber beim Organisieren von Daten hilfreich sein.
5. Verwenden Sie geeignete Datentypen: NoSQL-Datenbanken unterstützen eine Vielzahl von Datentypen. Es ist wichtig, für jedes Feld in der Datenbank den geeigneten Datentyp auszuwählen.

Es ist möglich, die Stärken des relationalen Paradigmas bei der RDBMS-Denormalisierung zu nutzen. NoSQL-Datenbanken sind ein fantastisches Werkzeug zum Erstellen dynamischer Entitäten und halbstrukturierter Aggregate. Anstatt über Entitäten und Beziehungen nachzudenken, modellieren Sie NoSql mit einem hierarchischen und aggregierten Ansatz. Durch die Denormalisierung in RDBMS wird Ihre Datenbank effektiv auf eine NoSQL-Datenbank heruntergefahren. Wenn Sie ein großes Aggregat von Aggregaten benötigen, müssen Sie den Code beitreten, oder wenn Sie ein kleines Aggregat benötigen, müssen Sie es parsen. Sie sollten so schnell wie möglich mehr über Ihre Beziehungen erfahren.
Nosql-Datenbankdiagramm
Das Nosql-Datenbankdiagramm ist ein Datenbanktyp, der Daten in einem Format speichert, das sich von der herkömmlichen relationalen Datenbank unterscheidet. Nosql-Datenbanken werden häufig für Anwendungen verwendet, die ein hohes Maß an Skalierbarkeit und Leistung erfordern.
Der Name und die Struktur von Datenmodellierungsdiagrammen unterscheiden sich von denen der ER- und Klassendiagramme. Die vom Entwickler vereinfachten NoSQL-Beziehungsregeln sollen Entwicklern den Einstieg in NoSQL erleichtern. Beim Modellieren ist es immer vorzuziehen, Lese- und Schreibvorgänge im Voraus zu planen. Es ist nie eine gute Idee, Dokumente mit einer zunehmenden Anzahl von Referenzen oder Nummern in einem anderen Dokument abzulegen. Infolgedessen gibt es viele Artikel auf dem Markt, die weiter wachsen werden, daher können wir ihre IDs nicht als Referenzen in Produkte einbetten oder hinzufügen. Eine weitere Sammlung kann erstellt werden, um mehrere Transaktionen zu speichern, oder Sie können einfach ein eindeutiges Identifikationsfeld (z. B. ID-Transaktion) in alle Transaktionen einfügen, die in einer Gruppe durchgeführt werden. Der Name und die Designprinzipien der NoSQL-Datenmodellierung sind nicht so stark wie die von SQL.
Um das Lesen zu erleichtern, ist es immer vorzuziehen, die Symbole einzubeziehen, aus denen das Diagramm besteht. Das Produkt verfügt über zahlreiche Transaktionen, die völlig optional sind, aber Anforderungen erfüllt werden müssen. Während der Entwicklung der Anwendung muss das Diagramm unten möglicherweise verbessert werden.
Die Vor- und Nachteile von Nosql-Datenbanken
Nosql-Datenbanken sind für halbstrukturierte Daten ausgelegt. Das relationale Modell ist dafür nicht geeignet. Ein Schlüsselwertspeicher ist eine ausgezeichnete Wahl, da er Daten in einer Vielzahl von Schlüsselwertpaaren speichert.
Beispiel für ein Nosql-Datenbankschema
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das traditionelle tabellenbasierte Schema einer relationalen Datenbank verwendet. NoSQL-Datenbanken werden häufig für Big Data und Echtzeit-Webanwendungen verwendet.
Datenbank NoSQL benötigt im Gegensatz zu relationalen Datenbanken kein festes Schema zum Speichern von Daten. Der Hauptzweck von NoSQL-Datenbanken besteht darin, eine groß angelegte Datenspeicherung in verteilten Systemen zu ermöglichen. Unternehmen wie Twitter, Facebook und Google verwenden NoSQL, um riesige Datenmengen zu analysieren und Echtzeit-Webanwendungen zu erstellen. Daten werden in einer Datenbank gespeichert und als Schlüsselpaar mit dem Schlüsselwert abgerufen. Diese Art von NoSQL-Datenbank kann verwendet werden, um Informationen in einer Sammlung, einem Wörterbuch oder einem assoziativen Array zu speichern. Dokumenttypen werden häufig in Content-Management-Systemen, Blogging-Plattformen, Echtzeitanalysen und E-Commerce verwendet. Meistens werden graphbasierte Datenbanken verwendet, um Daten in sozialen Netzwerken, Logistik- oder räumlichen Datenbanken zu speichern.
Mit dem MapReduce-Tool können Sie Ansichten in CouchDB definieren. Nach diesem Prinzip kann ein verteilter Datenspeicher nicht mehr als zwei von drei Dingen garantieren. Datenkonsistenz ist ein Muss: Die Daten dürfen auch nach Ausführung einer Operation nicht verändert werden. Es ist wichtig, dass die Partitionstoleranz des Systems beibehalten wird, selbst wenn die Kommunikation zwischen Servern nicht stabil ist.
Haben Nosql-Datenbanken ein Schema?
Hat NoSQL ein Schema? Im Gegensatz zu relationalen Datenbanken, die eine Funktionshierarchie haben, ist dies bei NoSQL-Datenbanken nicht der Fall. Die zugrunde liegende Struktur jeder der vier Haupttypen von NoSQL-Datenbanken wird zum Speichern der Daten verwendet.
Daten so, wie es am besten zu Ihrer Anwendung passt. Die drei Arten von Schemas in Mongodb
MongoDB hat viele Vorteile, einschließlich seiner Benutzerfreundlichkeit und Wartungsfreundlichkeit. Die einfachste Version dieses Systems ist einfacher, da sie nicht die Verwendung eines komplizierten Schemas erfordert. Aufgrund seines flexiblen Schemas können Sie Ihre Daten optimal für Ihre Anwendung modellieren. In diesem Artikel gehen wir auf die Datenmodellierung in MongoDB ein. Die Daten von MongoDB können sich standardmäßig ändern. Dokumentstrukturen werden nicht automatisch durch Sammlungen erzwungen. Dadurch haben Sie die Möglichkeit, Datenmodelle zu entwerfen, die die Anforderungen Ihrer Anwendung am besten erfüllen und gleichzeitig deren Leistungsanforderungen erfüllen. MongoDB verwendet die drei Arten von Schemas: logisch, physisch und Ansicht. Das logische Schema einer Datenbank beschreibt die Art und Weise, wie sie geschrieben ist. Mithilfe eines logischen Schemas können Sie die Struktur einer Datenbank namens Produkte definieren und eine Liste von Produkten erstellen. Das logische Schema wird verwendet, um Beziehungen zwischen Daten in einer Datenbank zu definieren und zu bestimmen, wie sie gespeichert werden. Das physische Schema wird durch die physische Datenbank definiert. Sie können ein physisches Schema verwenden, um beispielsweise die Struktur der Daten in einer Datenbank namens Produkte zu definieren. Es bestimmt auch, wie Daten indexiert und durchsucht werden; das physische Schema kann in einem Verzeichnis oder auf einer Platte gefunden werden. In einer Datenbank auf Ansichtsebene beschreibt das Ansichtsschema das Datenbankdesign. Ein Ansichtsschema kann beispielsweise verwendet werden, um die Struktur einer Datenbank namens Produkte zu definieren. Während das Ansichtsschema die Struktur eines Datensatzes definiert, bestimmt es nicht, wie er gespeichert wird. Sie können damit jedoch jede Speichertechnologie verwenden, die Dokumente unterstützen kann. MongoDB unterstützt Schemas basierend auf drei verschiedenen Typen. Ein logisches Schema ist eine Methode zum Definieren der Struktur Ihrer Daten, während ein physisches Schema eine Methode zum Definieren des Formats der Speicherung Ihrer Daten ist und ein Ansichtsschema eine Methode zum Definieren der Struktur Ihrer Daten, aber nicht zum Bestimmen, wie sie ist strukturiert. Mit dem Datenmodell von MongoDB können Sie aufgrund seiner Flexibilität wählen, welche Anforderungen Sie erfüllen möchten. Wenn Sie beispielsweise über große Datenmengen verfügen, möchten Sie möglicherweise ein physisches Schema anstelle eines Webschemas verwenden. Wenn Sie sehr wenig Daten haben und Ihre Struktur vereinfachen möchten, können Sie ein Ansichtsschema verwenden. Das deklarative Schema von MongoDB sowie seine einfache und leistungsstarke Benutzeroberfläche machen es zu einer ausgezeichneten Wahl für die Entwicklung benutzerdefinierter Modelle.
Welche Art von Schema wird für die Nosql-Datenbank verwendet?
Skalierung: NoSQL-Datenbanken stellen normalerweise Schemata bereit, die einfach nach oben und unten skaliert werden können, um die Anforderungen eines Entwicklers zu erfüllen. Aufgrund ihres flexiblen Datenmodells eignen sich NoSQL-Datenbanken ideal zum Speichern von halbstrukturierten und unstrukturierten Daten.
Json: Die Zukunft der Datenbankverwaltung?
Daten mit halbstrukturierten Daten, die keine strenge Zeilen-Spalten-Struktur in einer Standard-SQL-Datenbank erfordern, sind ideal für JSON. Es kann verwendet werden, um Inhalte schneller und effizienter zu erstellen und zu aktualisieren sowie die Schemaflexibilität zu verbessern. Es eignet sich beispielsweise ideal zum Speichern von Benutzerprofilen oder Produktbeschreibungen.
Was ist ein Beispiel für ein Nosql?
Eine NoSQL-Datenbank kann verwendet werden, um eine Vielzahl von Aufgaben in einer Vielzahl von Branchen zu erfüllen. Eine NoSQL-Datenbank wird anhand ihres Typs klassifiziert. Dokumentendatenbanken werden beispielsweise als Allzweckdatenbanken klassifiziert. In Schlüsselwertdatenbanken können einfache Suchabfragen für große Datenmengen durchgeführt werden.
Warum Mongodb die beste Nosql-Datenbank ist
Millionen von Benutzern, darunter Uber, Airbnb und Pinterest, verwenden MongoDB. Dies ist auch die beliebteste NoSQL-Datenbank auf GitHub. Es gibt zahlreiche Gründe, MongoDB zu verwenden. Darüber hinaus ist seine Indexgröße von nur 2 GB beeindruckend. Es kann eine große Datenmenge in kurzer Zeit verarbeiten. Darüber hinaus verfügt MongoDB über eine Reihe nützlicher Funktionen wie Sharding und Replikation. Sie können Ihre Daten auch dann sicher aufbewahren, wenn die Größe Ihrer Daten wächst. Wenn es um NoSQL-Datenbanken geht, ist MongoDB zweifellos der König.