
5 Möglichkeiten zur Optimierung Ihrer NoSQL-Datenbank
Veröffentlicht: 2023-01-12NoSQL-Datenbanken werden immer beliebter, da sie als skalierbarer und flexibler als traditionelle relationale Datenbanken angesehen werden. Es gibt eine Reihe von Möglichkeiten, eine NoSQL-Datenbank zu optimieren, darunter: 1. Sorgfältiges Entwerfen des Schemas: Dies ist wichtig, da ein gut entworfenes Schema dazu beitragen kann, die Leistung zu verbessern und die Daten besser zu verwalten. 2. Indizieren von Daten: Dies kann zur Verbesserung der Abfrageleistung beitragen. 3. Verwenden von Caching: Caching kann helfen, die Leistung zu verbessern, indem häufig aufgerufene Daten im Arbeitsspeicher gespeichert werden. 4. Partitionieren von Daten: Dies kann zur Verbesserung der Leistung und Skalierbarkeit beitragen, indem Daten auf mehrere Server verteilt werden. 5. Leistungsüberwachung: Dies ist wichtig, um Engpässe zu identifizieren und Korrekturmaßnahmen zu ergreifen.
Jay Patel, ein eBay-Architekt, hat kürzlich einen Artikel über die Datenmodellierung mit dem Cassandra-Datenspeicher veröffentlicht. Er erklärt, wie sie ihr Datenmodell mit Cassandra entworfen haben, wie sie Spalten und Spaltenfamilien verwendet haben und wie sie Abfrageergebnisse mithilfe der Abfrageoptimierung optimiert haben. Eine meiner Lieblingserkenntnisse aus ihrem Ansatz ist, dass er auf jede NoSQL-Datenbank angewendet werden kann. Bevor Sie Ihr Datenmodell optimieren können, müssen Sie zunächst verstehen, wie darauf zugegriffen wird. Wenn Sie bemerken, dass Ihre Abfragen länger dauern, stellen Sie fest, dass Ihre relationale Datenbank Leistungsprobleme hat. Wenn Daten normalisiert werden, ist es weniger wahrscheinlich, dass es zu unnötigen Joins oder n+1-Abfragen kommt. Auch wenn eine Denormalisierung mit NoSQL-Datenspeichern möglich ist, sind damit Kosten verbunden.
Was ist Abfrageoptimierung in Nosql?
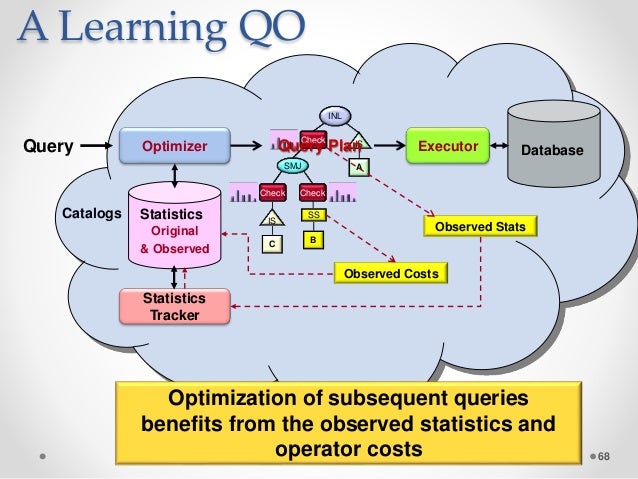
Das Ziel der Abfrageoptimierung ist es, den effizientesten Plan zu finden. Bei der Messung der Effizienz werden Latenz und Durchsatz verwendet. Eine kostenbasierte Optimierung kostet genauso viel wie die Kosten für Arbeitsspeicher, CPU und Speicherplatz. In der NoSQL-Welt bieten die meisten Datenbanken jetzt Unterstützung für SQL-ähnliche Abfragesprachen.
Eine MongoDB-Datenbank ist eine NoSQL-Datenbank, die auch als Dokumentendatenbank bezeichnet wird. Diese Datenbank wurde so konzipiert, dass sie einfacher zu entwickeln ist als andere relationale Datenbanken. Mithilfe von explain() können wir sehen, wie unsere Abfrage funktioniert. Sie können Explain verwenden, um ein Dokument zu erstellen, das Abfragepläne, Abfragephasen und mehr enthält. Als Ergebnis dieses Artikels können wir verstehen, wie der Index die Scan-Phasen einer bestimmten Sammlung verändern kann. Der Zweck dieses Artikels ist es, die Grundlagen der Optimierung zu erläutern. Die detaillierten Details zur Optimierung der Aggregationsstufe werden in nachfolgenden Artikeln behandelt. Schwarze Menschen zeichnen sich in den Bereichen Technologie aus. Diese Ressourcensammlung hebt einige der Dinge hervor, die wir wissen sollten.
Was macht Nosql schnell?
Nosql-Datenbanken sind auf Schnelligkeit und Skalierbarkeit ausgelegt. Sie verwenden eine Vielzahl von Techniken, um dies zu erreichen, wie z. B. horizontale Skalierung, Sharding und Denormalisierung.
Die überwiegende Mehrheit der noSQL-Systeme sind einfach persistente Schlüssel- oder Wertspeicher (wie Project Voldemort). Wenn Ihre Abfragen von der Art sind, dass Sie einen bestimmten Schlüsselwert nachschlagen müssen, ein System, das dies so schnell tun kann, wie es ein RDBMS tun sollte. Dokumentendatenbanken (wie CouchDB) sind ebenfalls beliebte nosql-Systeme. Denormalisierung wird in diesen Datenbanken stark verwendet, um die Datenstruktur zu strukturieren. Tatsächlich glaube ich, dass die Leistung einer Anwendung an der Anzahl der Teile gemessen werden kann, die erforderlich sind, um eine einzelne Anforderung zu erfüllen. Wenn NoSQL verwendet wird, kann die Leistung einer NoSQL-Datenbank wie djondb zehnmal schneller sein, wenn Sie nur eine einfache Einfügung benötigen. Der Entwickler kann effizienter arbeiten, da NoSQL es ihm ermöglicht, weniger Daten zu verbrauchen.
Das primäre Ziel von NoSQL-DATENBANKEN (keine Grenzen) ist es, ein hohes Maß an Skalierbarkeit aufrechtzuerhalten. Sie müssen berücksichtigen, welche Arten von Abfragen Sie ausführen, welche Spalten Sie in der Tabelle verwenden und welche Implementierung Ihres Servers Sie verwenden. Wenn Sie mehr Knoten mit 1000000 U/min stabil 2 ms erstellen und weniger Code verwenden, erhalten Sie einen schnelleren Knoten mit einer höheren stabilen Rate und Leistung.
Was macht Nosql schneller als SQL?
Dieses Verfahren beinhaltet das Sammeln, Zusammenführen und Aufteilen verschiedener Datenentitäten. Folglich führt eine NoSQL-Datenbank Lese- und Schreibvorgänge schneller aus als eine SQL-Datenbank.
Warum Nosql-Datenbanken die Oberhand gewinnen
Neben einer Vielzahl von Faktoren werden NoSQL-Datenbanken immer beliebter. Sie sind einfach zu bedienen, können große Datenmengen verarbeiten und können an die spezifischen Anforderungen Ihrer Anwendung angepasst werden. Sie haben viele Vorteile, zusätzlich zu ihrer Flexibilität und Anpassbarkeit, die in anderen Datenbanktypen nicht zu finden ist.
Nosql-Leistungsoptimierung

Bei der Leistungsoptimierung von Nosql geht es darum sicherzustellen, dass Ihre Nosql-Datenbank so effizient wie möglich läuft. Es gibt ein paar Schlüsselbereiche, auf die Sie sich beim Optimieren Ihrer nosql-Datenbank konzentrieren sollten: 1. Stellen Sie sicher, dass Ihre Datenbank richtig indiziert ist. 2. Stellen Sie sicher, dass Ihre Abfragen optimiert sind. 3. Stellen Sie sicher, dass Ihre Daten ordnungsgemäß normalisiert sind. 4. Stellen Sie sicher, dass Ihre Datenbank richtig konfiguriert ist. Indem Sie sich auf diese Schlüsselbereiche konzentrieren, können Sie sicherstellen, dass Ihre nosql-Datenbank mit Spitzenleistung läuft.
Wenn Mango stark ausgelastet ist, führt das MangoNoSql-Skript Hintergrundschreibvorgänge im Hintergrund aus. Mit der Batch Write Behind-Funktion können Sie hinter den Kulissen schreiben. Jede Aufgabe wird parallel zu den anderen ausgeführt, wodurch Punktwerte aus einem Pool in den Fokus gerückt werden. Wenn Sie NoSQL Data Lost Events in Ihrem System bemerkt haben, ist es eine gute Idee, Ihre Leistungseinstellungen zu ändern. Wenn Sie auf die Schaltfläche Jetzt sichern klicken, wird eine Warteschlange mit Jobs erstellt, um das System jetzt zu sichern. Alle Punktwerte, die als Teil von NoSQL-Modulen in eine Speicherliste geschrieben werden können, werden in mango gespeichert. Danach wählt es bis zu 'Batch-Schreiben hinter Einfügungen pro Task' aus der Liste aus und startet einen Thread zum Einfügen der Einfügungen.
Die Vor- und Nachteile von Nosql
Bei der Entwicklung von NoSQL-Datenbanken ist es entscheidend, sie flexibel und schnell zu halten. Es hat weniger Overhead, weil es weniger Einschränkungen als SQL hat. Flacher NoSQL-Speicher ist flexibel und kann über eine Vielzahl von Objekten (Dokumente oder Schlüssel-Wert-Paare) verteilt werden. Eine NoSQL-Datenbank wird allgemein als wenig schwierig in Bezug auf Entwicklung, Funktionalität und Leistung angesehen. Es ist einfach zu erlernen und wird von Personen verwendet , die es vorziehen , Daten zu speichern , die nicht den traditionellen Datenbankmodellen entsprechen .
Mongodb-Leistungsoptimierung
MongoDB ist ein leistungsstarkes dokumentenorientiertes Open-Source- Datenbanksystem . Es verfügt über eine indexbasierte Suchfunktion, die das Abrufen von Daten schnell und einfach macht. Wie bei jedem anderen Datenbanksystem kann die Leistung von MongoDB jedoch optimiert werden, um sicherzustellen, dass es reibungslos und effizient läuft. Es gibt ein paar grundlegende Dinge, die getan werden können, um die Leistung von MongoDB zu optimieren. Zunächst ist es wichtig sicherzustellen, dass die richtigen Indizes vorhanden sind. Dadurch wird sichergestellt, dass die Daten schnell und einfach abgerufen werden können. Zweitens ist es wichtig, die Datenbank gut organisiert zu halten. Dies trägt dazu bei, die Datengröße gering zu halten und die Abfrage zu vereinfachen. Schließlich ist es wichtig, die Datenbank regelmäßig zu überwachen, um sicherzustellen, dass sie reibungslos läuft. Wenn Sie diese einfachen Tipps befolgen, ist es möglich, dass MongoDB reibungslos und effizient läuft.

Guy Harrison erklärt in diesem Blogbeitrag, wie Sie die neue Windowing-Aggregation und Aggregationspipeline in MongoDB 5.0 verwenden. Data Lake entstand als Ergebnis des explosionsartigen Interesses an Big Data und Hadoop. Mit dem Data Lake wurde eine moderne und effizientere Alternative zum Enterprise Data Warehouse (EDW) entwickelt. Der Blog dieser Woche konzentriert sich auf MongoDB B -Tree-Indizes und wie man verkettete Indizes erstellt, um Multi-Key-Lookups zu optimieren. Darüber hinaus berücksichtigen wir bei der Erwägung – oder Verwendung – von Indizes einige Kompromisse.
Was ist die Leistungsverbesserung in Mongodb?
Wenn Sie Ihre MongoDB-Abfragemuster kennen, können Sie Ihre MongoDB-Leistung verbessern, indem Sie: die Ergebnisse häufiger Unterabfragen speichern, um die Leselast zu reduzieren; und Erkennen Ihrer MongoDB-Abfragemuster. Stellen Sie sicher, dass Sie Indizes für jedes Feld haben, das Sie regelmäßig abfragen. Wenn Sie langsame Abfragen bemerken, können Sie diese anhand Ihrer Protokolle identifizieren.
Braucht Mongodb viel Ram?
MongoDB benötigt 1 GB RAM, um auf einem einzelnen Asset ausgeführt zu werden. Wenn das System mit dem Auslagern von Speicher auf Festplatte beginnen muss, hat dies schwerwiegende Auswirkungen auf die Leistung und sollte vermieden werden.
Verfügt Mongodb über einen Abfrageoptimierer?
Wenn ein Index in MongoDB verfügbar ist, bestimmt der Abfrageoptimierer, welcher Abfrageplan am effizientesten ist, und speichert ihn zwischen. Die Anzahl der vom Abfrageausführungsplan ausgeführten „Arbeitseinheiten“ (Arbeiten) wird verwendet, um den effizientesten Abfrageplan zu bestimmen, wenn der Abfrageplaner Kandidatenpläne untersucht.
Mongodb-Abfrageoptimierungstool
Mongodb bietet ein Abfrageoptimierungstool, mit dem Benutzer die Leistung ihrer Abfragen verbessern können. Dieses Tool bietet eine Möglichkeit, den Abfrageausführungsplan zu visualisieren und die Abfrage basierend auf den Ergebnissen zu optimieren. Das Tool ermöglicht es Benutzern auch, den Abfrageausführungsplan in einer Vielzahl von Formaten anzuzeigen, darunter JSON, BSON und CSV.
MongoDB stellt Statistiken zur Abfrageausführung als Teil eines Inspektionssystems bereit. Diese Informationen können von einem Entwickler verwendet werden, um eine Abfrage zu optimieren. Auf der Registerkarte „Explain Plan“ können Benutzer beispielsweise die Statistik des Plans grafisch darstellen. Zusätzlich zu queryPlanner, executeStats und allExecutionPlans können Ausführlichkeitsmodi zur Erläuterung verwendet werden. Unique, Partial, Sparse (keine Dokumente ohne das Indexfeld indizieren), Hidden (Ergebnisse des Abfrageplaners nicht anzeigen) und Multikey-Indizes werden alle von MongoDB unterstützt. Anstatt Indexpräfixschlüssel oder unterschiedliche Sortierreihenfolgen zu verwenden, wird ein zusammengesetzter Index für Indizes verwendet. MongoDB optimiert die Abfrageleistung, indem zwei separate Indizes oder Präfixe verwendet werden, wenn zwei Indizes oder ihre Präfixe verbunden werden.
Die Pipeline von Mongod enthält eine Phase, die mit einem nicht indizierten Feld übereinstimmt. Es ist eine einfache Lösung, die Matching-Stufe neu zu schreiben, um ein bereits vorhandenes und indiziertes Feld zu verwenden. Der Optimierer sucht nach Arbeitseinheiten, die ausgeführt werden müssen, wenn jeder Kandidatenplan ausgeführt wird. Beim Ausführen leseintensiver Anwendungen sollte die Größe der Replikatsätze erhöht und Sharding durchgeführt werden. Der Status und die Dauer der Replikation sollten überwacht werden. Richtig: Aktualisieren Sie alle übereinstimmenden Dokumente so effizient wie möglich, wenn Sie Multi verwenden. Untersuchen Sie Sperrmetriken in einer bestimmten Reihenfolge.
Eine lange Sperrzeit kann darauf hindeuten, dass die Abfragestruktur oder Systemarchitektur nicht ordnungsgemäß funktioniert. Batching verbessert die Ressourceneffizienz. Ereignisse in Kafka können beispielsweise in Stapeln statt in Blöcken konsumiert werden. Es ist unmöglich, eine Abfrage für eine fragmentierte Sammlung zu indizieren, wenn der Index den Schlüssel für die Sammlung nicht enthält. Durch die Verwendung von $planCacheStats können Sie die Cache-Informationen in der Aggregationsphase besser verstehen. Dies bedeutet auch, dass der Plan-Cache nur eine Größenbeschränkung von 0,5 GB hat, was der gleichen Größenbeschränkung wie die frühere Version entspricht.
Nosql-Datenspeicher
Anstatt Daten in Tabellen zu speichern, speichern NoSQL-Datenbanken Daten in Dokumenten. Daher bezeichnen wir sie als „nicht nur SQL“ und können daher mit einer Vielzahl unterschiedlicher Methoden als flexible Datenmodelle klassifiziert werden. NoSQL-Datenbanken werden in vier Typen unterteilt: reine Dokumentendatenbanken, Key-Value-Stores, Wide-Column-Datenbanken und Graph-Datenbanken.
Der Redis-Datenspeicher ist ein von IBM entwickelter Open-Source-In-Memory-Speicher für Schlüssel-Wert-Paare. Es kann verwendet werden, um Sitzungsdaten für einen schnelleren Zugriff zu speichern, zusätzlich zu Caching, Queueing und Queueing, und es ist weniger teuer als herkömmliche Datenbanken . Eine NoSQL-Datenbank wird häufig als Ergänzung und nicht als Ersatz für eine relationale Datenbank verwendet. Ein zugrunde liegender Persistenztyp hat andere Merkmale als einer, der in einer relationalen Datenbank gespeichert ist. PyMongo, das mit Python-Code erstellt wurde, ermöglicht Ihnen die Interaktion mit einer oder mehreren MongoDB-Instanzen über eine gemeinsame Schnittstelle. Das um PyMongoEngine herum aufgebaute Python-ORM wurde speziell für MongoDB entwickelt. Das Ziel von Graph Databases ist es, einen umfassenden Überblick über NoSQL-Datenspeicher zu geben und sie mit anderen Arten von Datenspeichern zu vergleichen. Im Folgenden finden Sie eine kurze Beschreibung von NoSQL und seiner Verwendung sowie eine Beschreibung des Consistency, Availability, and Partition-Tolerance (CAP) Theorems. Sitzungsdaten können schneller im Arbeitsspeicher gespeichert werden als in einer herkömmlichen Datenbank mit persistentem Speicher.
NoSQL-Datenbanken profitieren von folgenden Eigenschaften: einfache Skalierung, hohe Verfügbarkeit und geringe Latenz beim Datenzugriff. Datenbankanwendungen sind darauf ausgelegt, mehr Datentypen zu verarbeiten als herkömmliche Datenbanken. Es vereinfacht die Datenspeicherung mit einem vereinfachten Modell und ermöglicht eine schnellere und effizientere Verarbeitung. Darüber hinaus eignen sie sich für umfangreiche Datenanalysen. NoSQL-Datenbanken haben gegenüber herkömmlichen Datenbanken eine Reihe von Vorteilen. Die Vorteile davon sind, dass sie skalierbar sind, ein hohes Maß an Verfügbarkeit bieten und eine geringe Latenz für den Datenzugriff bieten.
Warum Nosql-Datenbanken die Führung übernehmen
Die Verwendung von NoSQL-Datenbanken bietet gegenüber herkömmlichen relationalen Datenbanken zahlreiche Vorteile, und sie werden immer beliebter. Das ObjectStore-Design, das eine effizientere Nutzung objektorientierter Programmiertechniken ermöglicht, ist einer der Hauptgründe dafür. NoSQL-Datenbanken bieten neben ihrer Skalierbarkeit noch eine Vielzahl weiterer Vorteile. Daten können einfach gehandhabt werden, da sie groß sind und in kurzer Zeit verarbeitet werden können. Für jedes Unternehmen, das nach einer zuverlässigen und skalierbaren Dokumentendatenbank sucht, ist MongoDB eine ausgezeichnete Wahl. Darüber hinaus ist die Nutzung kostenlos und eine beliebte Wahl für Unternehmen jeder Größe.
Mongodb-Textindex
Die Textindizes von MongoDB unterstützen die sprachspezifische Textverarbeitung, einschließlich Tokenisierung, Wortstammbildung und sprachspezifischen Stoppwörtern. Sie können mit jedem Feld verwendet werden, das sprachbasierten Text enthält.
Das Erstellen von Textindizes in MongoDB ist so einfach wie die Verwendung der Methode createIndex(). Die Hauptfunktion eines Textindex besteht darin, jedes Element in einer Zeichenfolge oder einem Array von Elementen in einem Text zu identifizieren. Zusammengesetzte Indizes enthalten zusätzlich zum Textindexschlüssel sowohl aufsteigende als auch absteigende Indexschlüssel. Lassen Sie uns in diesem Fall in der Post-Sammlung von students suchen, indem Sie einen Textindex im Titelfeld erstellen. MongoDB fasst die Ergebnisse jedes Indexfelds im Dokument zusammen, indem es seine Gewichtung mit der Gesamtzahl der Übereinstimmungen multipliziert. Die Standardgewichtung eines Indexfelds ist eins, Sie können sie also mit der Methode createIndex() ändern. Sie können mehrere Textindizes mit dem Platzhalterbezeichner ($**) erstellen.