
Entwerfen einer Datenbank für Geolokalisierungsdaten: Wichtige Überlegungen
Veröffentlicht: 2022-12-29Geolokalisierungsdaten sind Datentypen, die Informationen über den geografischen Standort eines bestimmten Objekts enthalten. Um Geolokalisierungsdaten effektiv zu speichern und zu verwalten, ist es wichtig zu verstehen, wie eine Datenbank für diese Art von Daten strukturiert wird. Beim Entwerfen einer Datenbank für Geolokalisierungsdaten sind einige wichtige Überlegungen zu beachten. Die erste Überlegung ist die Granularitätsebene, auf der die Daten gespeichert werden. Werden die Daten beispielsweise auf Länderebene, Bundesstaatsebene oder Stadtebene gespeichert? Der Granularitätsgrad wirkt sich auf die Gesamtgröße der Datenbank und die Komplexität der Abfragen aus, die für die Daten ausgeführt werden können. Die zweite Überlegung ist das Format, in dem die Daten gespeichert werden. Es gibt einige verschiedene Optionen zum Speichern von Geolokalisierungsdaten, darunter Breiten-/Längengradpaare, GeoJSON und KML. Jede Option hat ihre eigenen Vor- und Nachteile, daher ist es wichtig, das Format zu wählen, das für die spezifischen Anforderungen der Anwendung am besten geeignet ist. Schließlich ist es wichtig, die Indizierungsstrategie zu berücksichtigen, die für die Daten verwendet wird. Die Indizierung ist aus Leistungsgründen wichtig, kann sich aber auch auf die Gesamtstruktur der Datenbank auswirken. Für Geolokalisierungsdaten besteht eine übliche Indizierungsstrategie darin, einen Quadtree-Index zu verwenden. Unter Berücksichtigung dieser Überlegungen ist es möglich, eine Datenbank zum Speichern von Geolokalisierungsdaten effektiv zu entwerfen.
Eine Reihe von Mainstream-Technologieunternehmen experimentieren mit NoSQL-Datenbanken im Bereich der standortbezogenen Dienste. Eine strukturierte Abfragesprache wie SQL und eine relationale Datenbank wie MySQL funktionieren auf entgegengesetzte Weise. NoSQL-Datenbanken haben keine gemeinsamen Merkmale, und viele von ihnen erfordern keine festen Tabellenschemata oder Verknüpfungsvorgänge. MongoDB (Open Source), BigTable (proprietär von Google) und Google Earth (verfügbar über Google Earth) sind nur einige der NoSQL-Datenbanken, die räumliche Daten verarbeiten können. Cassandra (eine von Facebook entwickelte NoSQL-Datenbank) und CouchDB (eine von Facebook entwickelte NoSQL-Datenbank) sind ebenfalls Open-Source-Softwareplattformen. Amazon SimpleDB, ein Webdienst, kann verwendet werden. Das NoSQL-Framework ist nicht einfach ein Container mit Datenspeichern; es ist eine Sammlung von ihnen.
Viele Entwickler verwenden NoSQL-Technologien, um räumliche Probleme zu lösen, anstatt sich auf eine Datenbank zu verlassen. Stattdessen verwenden sie einen lokalen oder gehosteten Dienst. Erwarten Sie mehr Optionen für Datenbanken, nicht weniger. Dies ist ein Dankeschön an Paul Ramsey und seine Studenten von Geog897g der Penn State University für ihren Beitrag.
Wie sind Nosql-Datenbanken strukturiert?
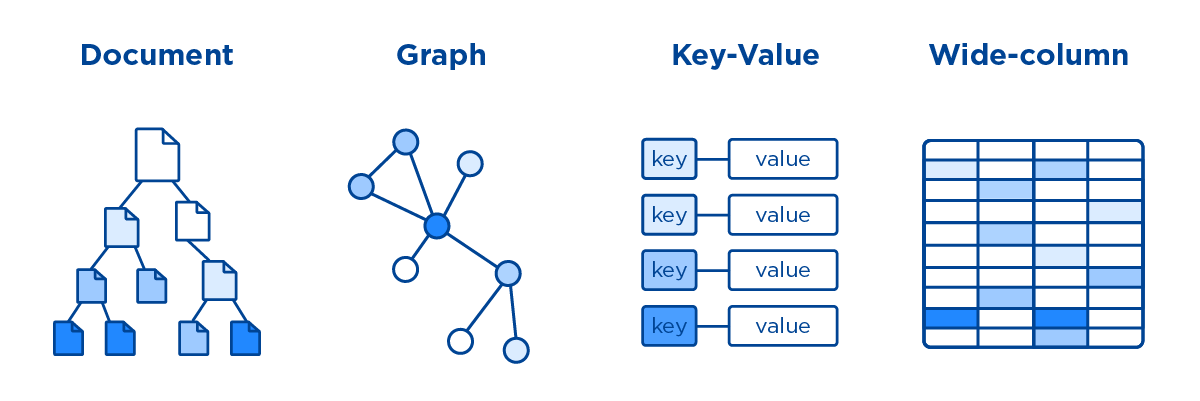
SQL-Datenbanken (auch bekannt als NoSQL-Datenbanken) speichern Daten aufgrund ihrer nicht tabellarischen Natur anders als herkömmliche Datenbanken . Eine NoSQL-Datenbank besteht basierend auf ihrem Datenmodell aus mehreren Typen. Zu den Dokumenttypen gehören Diagramme, Grafiken und breite Spalten sowie Schlüsselwerttypen.
Im Gegensatz zu herkömmlichen relationalen Datenbanken speichern NoSQL-Datenbanken Daten in einem für sie einzigartigen Format. Dokument-, Schlüsselwert-, Breitspalten- und Diagrammtypen sind die häufigsten. Die Kosten für die Speicherung von Daten sind in den letzten zehn Jahren dramatisch gesunken, was das Aufkommen von NoSQL-Datenbanken ermöglicht hat. Entwickler können große Mengen unstrukturierter Daten speichern, da sie diese Systeme für eine Vielzahl von Zwecken verwenden können. Dokumentdatenbanken, Schlüsselwertdatenbanken, Wide-Column-Stores und Graphdatenbanken sind alles Beispiele für NoSQL-Datenbanken. Wenn kein Beitritt erforderlich ist, verbessern sich die Abfragezeiten. Die Vielfalt der Anwendungsfälle für IoT-Lösungen reicht von kritischen (z. B. Finanzdaten) bis hin zu verspielteren und absurderen (z. B. das Speichern von IoT-Messwerten aus einer intelligenten Katzentoilette).
In diesem Tutorial erfahren Sie, wie Sie eine NoSQL-Datenbank auswählen und verwenden. Darüber hinaus werden wir uns eingehend mit einigen häufigen Missverständnissen über NoSQL-Datenbanken befassen. Laut DB-Engines ist MongoDB die beliebteste nicht-relationale Datenbank der Welt. Das Ziel dieses Tutorials ist es, Ihnen beizubringen, wie Sie eine MongoDB-Datenbank abfragen, ohne etwas auf Ihrem Computer zu installieren. Ein MongoDB-Cluster ist ein Ort, an dem Sie Ihre Datenbanken speichern. Die Speicherkapazität von Atlas kann erhöht werden, sobald sie für einen Cluster konfiguriert wurde. Der Atlas Data Explorer, die MongoDB Shell oder der MongoDB Compass sind mögliche Methoden zum manuellen Erstellen einer Datenbank.
Als Ergebnis werden die Beispieldaten von Atlas in dieses Skript importiert. NoSQL-Datenbanken haben eine Vielzahl von Vorteilen für Entwickler, einschließlich der Möglichkeit, Daten parallel zu modellieren und zu skalieren, Daten schnell abzufragen und blitzschnelle Abfragen zu verwenden. Der Daten-Explorer ist die bequemste Art, neue Dokumente einzufügen, vorhandene Dokumente zu bearbeiten und Dokumente zu löschen. Sie können Ihre Daten mit dem Aggregation Framework analysieren, das eines der leistungsstärksten verfügbaren Tools ist. Diagramme sind eine der einfachsten Möglichkeiten, Daten in Atlas und Atlas Data Lake zu visualisieren.
Aufgrund der Flexibilität von NoSQL-Datenbanken können sie mit unstrukturierten und halbstrukturierten Daten umgehen. Dies ermöglicht eine schnellere und iterativere Entwicklung, da die Daten nicht in der Datenbank neu erstellt werden müssen. NoSQL-Datenbanken können auch skaliert werden, um große Datenmengen zu verarbeiten, da sie skalierbar sind. Schließlich ermöglicht die Datenstruktur von NoSQL-Datenbanken ihnen, Daten auf eine völlig neue Art und Weise zu handhaben, die für sie einzigartig ist. NoSQL-Datenbanken sind ideal für große Datensätze, da sie an individuelle Anforderungen angepasst werden können.
Welche Art von Nosql-Datenbank wird verwendet, um Entitätsbeziehungen zu verfolgen?
Auf diese Frage gibt es keine endgültige Antwort, da dies von den spezifischen Anforderungen der Anwendung abhängt. Zu den beliebtesten Nosql-Datenbanken , die zum Verfolgen von Entitätsbeziehungen verwendet werden, gehören jedoch MongoDB, Couchbase und Cassandra.
Jedes System, das mit alternativen SQL-Datenbanken arbeitet, wird als NoSQL bezeichnet. Im Gegensatz zu herkömmlichen Zeilen- und Spaltentabellen, die in relationalen Datenbankverwaltungssystemen verwendet werden, bestehen die in dieser Anwendung verwendeten Datenmodelle aus unterschiedlichen Strukturen. NoSQL-Datenbanken unterscheiden sich stark voneinander. Dokumentdatenbanken mit einer Scale-out-Architektur werden üblicherweise verwendet, um die am weitesten verbreiteten Dokumentdatenbanken zu implementieren. E-Commerce-Plattformen, Handelsplattformen und die Entwicklung mobiler Apps sind nur einige Beispiele für Anwendungsfälle. Wir nehmen MongoDB und PostgreSQL im Detail unter die Lupe und vergleichen sie miteinander. Diese Daten können mithilfe einer spaltenorientierten Datenbank in Sekunden gesammelt werden.
Sie sind aufgrund ihrer Methode zum Schreiben von Daten nicht in der Lage, Daten konsistent zu schreiben. Graphdatenbanken sind optimiert, um Verbindungen zwischen Datenelementen als Teil ihrer Such- und Erfassungsfähigkeiten zu erfassen und zu suchen. Mit diesen Methoden können mehrere Tabellen in SQL effizienter verknüpft werden.
Welcher Nosql-Datenbanktyp eignet sich am besten zum Speichern von Daten mit komplexen Beziehungen?
Eine Dokumentendatenbank ist eine schemafreie Datenbank, die es Ihnen ermöglicht, ein Schema zu definieren, ohne ihm im Voraus folgen zu müssen. Mit diesem System können wir komplexe Daten in Dokumentenformaten wie XML und JSON speichern.
Welche Art von Nosql-Datenbank verwendet Kanten und Beziehungen in ihrer Struktur?
Eine gerichtete Graphstruktur wird verwendet, um Daten in einer Graph Base NoSQL-Datenbank darzustellen. Ein Graph besteht aus Knoten und Kanten. Ein Graph ist eine Darstellung einer Menge von Objekten, mit denen einige Paare der Objekte durch eine Art Verknüpfung verknüpft sind.
Nosql Geospatial
Geodaten sind Daten, die eine geografische Komponente wie Längen- und Breitengrad enthalten. Nosql-Datenbanken eignen sich gut zum Speichern und Abfragen von Geodaten. Viele nosql-Datenbanken verfügen über eine integrierte Unterstützung für Geodatentypen und -operationen.
Räumliche Daten (Dateien, Datenbanken, Webdienste) sind Datentypen, die geografische Informationen speichern und in ortsbezogenen Anwendungen verwendet werden können. Daten aus einer räumlichen Ebene können verwendet werden, um eine grafische Ebene auf einer Karte darzustellen, aber sie können auch zur Analyse geografischer Merkmale und Standorte verwendet werden. Es war ein spezieller Typ von Datenbankverwaltungssystem, das nur räumliche Objekte unterstützte und hauptsächlich von räumlichen Analytikern verwendet wurde. Wir beziehen uns auf räumliche Daten als Punkte, Linien und Bereiche kartografischer Informationen, da sie für deren Speicherung und Verarbeitung ausgelegt sind. Im Allgemeinen verwendeten Grafikprofis die Desktop-Mapping-Software von ESRI, um (statische) Karten zu erstellen. Zusätzlich zum Importieren der Daten könnten Webentwickler sie mit einer ortsbezogenen Web-Mapping-Anwendungsschicht abfragen, indem sie eine räumliche Datenbank verwenden. Beim Zugriff auf räumliche Daten erstellen Entwickler am häufigsten eine Karte, sei es online, in einer mobilen App oder auf einem Desktop-Computer.
Wenn Sie beginnen, räumliche Daten einfach als ein weiteres Objekt mit Koordinaten zu verwenden, werden Sie feststellen, wie gut es mit NoSQL-Datenbanken funktioniert. Durch die Verwendung von Cluster-basiertem Computing können räumliche Daten im Laufe der Zeit wachsen, wobei Abfrageressourcen leicht verfügbar sind. Diese Anwendungen machen es einfach, komplexere räumliche Abfragen zu verbergen, die häufig hinter den Kulissen verwendet werden. Es ist üblich, dass räumliche Datenbanken einfach ein Rechteck um jedes der Features in einem Dataset berechnen und dieses als groben Index für die Abfrage verwenden. Sie verwenden den MBR, um zu bestimmen, wie nahe die Features sind, damit sie Features ignorieren können, die zu weit voneinander entfernt sind, um wichtig zu sein. Dokumentenanfragen mit N1QL/SQL-basierter NoSQL-Software, wie z. B. Couchbase, können durchgeführt werden. Mit Hilfe der Geoobjekte können nachgelagerte Anwendungen direkt angebunden werden.
Das Ziel dieses Blogs ist es, zu demonstrieren, wie die Programmiersprache R sowie das Leaflet-Mapping-Paket auf einfache Weise Daten anfordern und Ergebnisse zeichnen können. Der wirkliche Kampf wird draußen mit Anfragen ausgetragen. Auch vollwertige GIS-Anwendungen und räumliche Datenbanken sind in der Lage, große Datenmengen zu generieren. Die Spezifikation umfasst viele verschiedene Typen und Funktionen für räumliche Merkmale. Eine weitere beliebte Form der räumlichen Verbindung ist das Verbinden von Punkten, insbesondere das Gruppieren von Punkten zu Polygonen. Der schwierigste Aspekt ist das Entwerfen eines Systems auf der Grundlage von Computergeometrie, was das Erstellen neuer Merkmale erfordert. Die Bedeutung des Ressourcenmanagements kann nicht genug betont werden, da dies schwierig ist.

Was ist die Beziehung zwischen Nosql und räumlichen Daten?
Da NoSQL für die Bewältigung großer Arbeitslasten entwickelt wurde, bietet es aufgrund seiner verteilten Computernatur immer eine zusätzliche Luxusschicht, sich darauf für GIS-Anwendungen zu verlassen. Wenn Cluster verwendet werden, wachsen räumliche Daten im Laufe der Zeit, und Abfrageressourcen können einfach erweitert werden.
Die Vorteile der Verwendung eines Geodatenindex
Sie müssen einen räumlichen Index in MongoDB erstellen, um räumliche Daten in MongoDB verwenden zu können. Mit diesem Index können Sie eine Sammlung räumlicher Formen und Punkte effizienter abfragen, indem Sie ihn als räumlichen Abfrageindex verwenden. Ein georäumlicher Index, der eine Vielzahl von Kriterien wie Längen- und Breitengrad verwendet, kann verwendet werden, um alle Orte in einem Dokument zu lokalisieren. Welche Vorteile hat die Verwendung eines Mapping-Index? Ein Kartenindex kann das Auffinden von Objekten in Dokumenten beschleunigen, da er einen geografischen Index verwenden kann, um sie zu lokalisieren. Das folgende Beispiel wäre ein Ort, an dem Sie alle Restaurants in Ihrer Stadt finden können. Da ein Geoindex auf Breiten- und Längengrad basiert, ist es einfach, Dokumente zu finden, die Ihren Kriterien entsprechen. In ähnlicher Weise kann Ihnen die Verwendung eines Geodatenindex beim Auffinden von Objekten helfen, die sich nicht unbedingt im selben Gebiet befinden. Möglicherweise möchten Sie alle Dokumente mit Längen- und Breitengraden innerhalb eines bestimmten geografischen Gebiets nachschlagen. Alle benötigten Dokumente mit Längen- und Breitengrad nach Ihren Kriterien finden Sie ganz einfach über einen Geodatenindex. Wie erstellt man einen Geoindex? Um einen Geodatenindex zu erstellen, müssen Sie zunächst eine Datensammlung erstellen, die die Daten enthält, die Sie indizieren möchten. Ein räumlicher Index, gefolgt von der Sammlung, ist erforderlich. Als letzten Schritt müssen Sie eine Abfrage generieren, die den Geoindex verwendet, um Objekte zu lokalisieren. Was sind die wichtigsten Dinge, die bei der Arbeit mit psy GIS zu beachten sind? Bei der Arbeit mit räumlichen Daten sollten die folgenden Hinweise beachtet werden. Bei der Suche nach Objekten in einem Dokument ist es immer vorzuziehen, einen Geoindex zu verwenden. Stellen Sie bei der Arbeit mit GIS sicher, dass Ihre Dokumente das richtige Format haben. Bei der Abfrage von Objekten müssen immer Bezugskoordinaten angegeben werden. Es ist nie eine gute Idee anzunehmen, dass ein Dokument geografische Informationen enthält. Bevor Sie den Index verwenden, ist es immer eine gute Idee, das Format der Daten zu überprüfen.
Geodatenspeicherung
Geodatenspeicherung bezieht sich auf den Prozess der Speicherung digitaler Daten, die einem physischen Standort zugeordnet sind. Diese Art von Daten kann verwendet werden, um Karten und andere Visualisierungen zu erstellen, die den Menschen helfen, die Welt um sie herum zu verstehen. Es gibt eine Vielzahl von Möglichkeiten, Geodaten zu speichern, einschließlich der Verwendung von Datenbanken, Dateien und Webdiensten.
Open-Source-Geodaten wie das Internet der Dinge (IoT), Voluntary Geoinformation (VGI) und Open Geospatial Data erfreuen sich wachsender Beliebtheit. Der Importprozess von PostgreSQL/PostGIS-Datenbanken wird mit HOGS, einem Befehlszeilendienstprogramm, vereinfacht. Es wurde mit dem Ziel entwickelt, die Leistung eines herkömmlichen Speicherlayouts und eines NoSQL-Dokumentenspeichers zu demonstrieren. Obwohl das Geschwindigkeitsversprechen von NoSQL verlockend erscheinen mag, gibt es auch Nachteile. Um zu verstehen, ob wir die Prinzipien relationaler Datenbankmanagementsysteme (RDBMS) wirklich aufgeben können, müssen wir dies daher zunächst berücksichtigen. HOGS ist ein Open-Source-Befehlszeilendienstprogramm, das die Open-Source-GDAL/OGR-Bibliothek verwendet, um den Import von heterogenen Geodaten in a/postGIS-Datenbanken zu automatisieren. Dokumentspeicher, Diagrammdatenbanken, objektorientierte Datenbanken und Schlüsselwertspeicher sind alles Beispiele für NoSQL-Datenspeicher.
Dokumentspeicher speichern Daten als Dokumente und nicht als Tabellen in einer relationalen Datenbank, da sie kein explizites Schema haben. Aufgrund ihrer einfachen Handhabung werden sie häufig in Verbindung mit Open-Source-Datensätzen verwendet. Der GeoJSON-Standard, der sowohl von MongoDB als auch von CouchDB verwendet wird, wird verwendet, um räumliche Fähigkeiten bereitzustellen. Amirianet al. Studieren Sie dokumentorientierte Modelle 19 % schneller als relationale Modelle für räumliche Daten mit großen Polygonen. Amirian und Kollegen testeten drei verschiedene Speicherstrategien für „ Big Data mit Geodaten “ unter Verwendung von Microsoft SQL Server 2012, mit Input von Benutzern. Das Layout des XML-Dokuments (NoSQL-Dokumentenspeicher) bot während der Einrichtung die beste Leistung und Skalierbarkeit.
Mehrere Ergebnisse ihrer Forschung zeigen, dass dokumentbasierte Modelle in einer Vielzahl von Workflow-Szenarien berücksichtigt werden sollten. Die Verwendung von MongoDB zum Abfragen von Punkten und zusammengesetzten Daten ergibt die dreifache Leistung von PostGIS bei sechsfacher Geschwindigkeit. Trotzdem übertrifft PostgIS MongoDB um mehr als das Dreifache bei Radiusabfragen, wenn der Radius der Abfrage zunimmt. Trotzdem erkennen die Autoren an, dass NoSQL-Datenbanken einige ähnliche Fähigkeiten wie RDBMS fehlen, geben jedoch an, dass sich dies in Zukunft ändern wird. Python wurde aufgrund seiner plattformübergreifenden Verfügbarkeit und Integration mit Open-Source-Bibliotheken wie GDAL/OGR und GEOS sowie seiner plattformübergreifenden Integration als Sprache zur Implementierung des HOGS-Systems ausgewählt. Die Datenbank wird auf zwei verschiedene Arten gespeichert: Feature- und Datensatzspeicherung. Eine Feature-Tabelle hat Zeilen für jedes Attribut, eine Geometriespalte und eine Feature-ID-Spalte; Jede Zeile enthält ein Feature mit einem Datensatz.
Eine Spalte enthält die ID. Sowohl die Geometrie- als auch die ID-Spalten sind separate Spalten, die zusätzlich zur Tabelle in Spalten organisiert sind. Der Hauptunterschied besteht darin, dass alle Attribute in einer einzigen Spalte vom Typ jsonb gespeichert werden. HOGS kann verwendet werden, um die Versionierung von Datensätzen zu unterstützen, indem inkrementelle Versionsnummern und zugehörige Zeitstempel verwendet werden. HOGS verwendet sowohl ein NoSQL- als auch ein traditionelles tabellenbasiertes Speicherlayout. Während der Importphase werden die Dateien jedes Datensatzes gelesen und analysiert, bevor sie mithilfe einer COPY-Anweisung in eine Datenbank geschrieben werden. Da jede Datei in einem Import eine eigene Datei ist, kann diese Phase gleichzeitig mit anderen Dateien ausgeführt werden. Importgeschwindigkeit, Abfragegeschwindigkeit und Datenbankgröße wurden für jedes Datenspeicherlayout gemessen.
Die norwegische Kartierungsbehörde, bekannt als N50, stellte einen offenen Datensatz für jeden Benchmark zur Verfügung. Ein Datensatz des norwegischen Festlandes im Maßstab 1:50.000 enthält acht Teildatensätze (Merkmalssammlungen) mit mehreren topologischen Schichten. Nach dem Extrahieren der Daten im vollständigen Datensatz gibt es 3415 Dateien mit einer Gesamtgröße von 7,9 GB. Die tabellenbasierte Importmethode ist 44 % schneller als die jsonb-Importmethode. Der Import des Tabellenlayouts dauert ungefähr eine Stunde und 19 Minuten, während das jstrelb-Layout ungefähr drei Stunden dauert. Wir haben 840 Abfragegeometrien aus den Abfrageprotokollen dieses Systems unter Verwendung der Tabellenlayout-Importgeschwindigkeit erhalten. Diese Polygone bedecken das norwegische Festland in einem Bereich von 1 bis 100 Metern.
Alle Metriken zeigen, dass das tabellenbasierte Layout besser abschneidet als das NoSQL-Layout im jsonb-Stil. Aufgrund der Art und Weise, wie Attribute gespeichert werden, und der Anzahl der verwendeten Tabellen könnte dies ein Problem darstellen. PostgreSQL/PostGIS wird von beiden Datenbanken verwendet, und beide Datenbanken verwenden PostGIS-Geometrietypen. Der Hauptunterschied zwischen Datenabfragen und jsonb-Dateien ist die Tabellengröße; Die gemeinsame Tabelle in jsonb-Dateien ist größer als die gemeinsame Tabelle in Datenabfragen. Viele Datasets können basierend auf den Feature-Typen, die sie enthalten, in separate Datasets unterteilt werden. Im Vergleich zu einem kombinierten NoSQL-Dokumentenspeicher-Tabellenlayout haben wir festgestellt, dass ein traditionelles Layout mit einer Tabelle pro Datensatz ein kombiniertes NoSQL-Dokumentenspeicher-Tabellenlayout für homogene Datensätze übertrifft. HOGS kann automatisiert werden und bringt keine zusätzliche Komplexität durch die Nutzung von GDAL/OGR in einem GDAL/OGR-System.
Eine einzelne Tabelle mit verschiedenen Datensätzen mit einer heterogenen Mischung von Features scheint einfacher zu handhaben, aber diese Art von Layout funktioniert nicht mit anderen GIS-Paketen. Der nächste Schritt besteht darin, ein gründlicheres Benchmark-Setup zu erstellen, das einen größeren Satz von Datensätzen umfasst. Es wird nicht empfohlen, den jsonb-Datentyp in Postgres zu verwenden, um homogene Datensätze im Kontext von Metadaten für geosynchrone Daten zu speichern. Wenn der Speicherplatzbedarf einer einzelnen Datenbankinstanz den einer anderen Datenbankinstanz nicht übersteigt, bleibt die Anweisung bestehen. Herkömmliche RDBMS-Technologien können verwendet werden, um große Mengen an Geodaten effizient zu speichern und abzufragen. Das Handbuch für MongoDB 2018. Der JSONB-Datentyp in PostgresQL beschleunigt laut Del Alba den Betrieb.
Glauben Sie, dass Nosql Landnutzungs- und Landbedeckungsdaten verarbeiten kann? Nat Ecodyn. Dieses Buch wurde in 11:438 bis 4426 veröffentlicht. Sie dürfen diesen Artikel in jedem beliebigen Medium veröffentlichen, solange Sie die Creative Commons-Lizenz (https://creativecommons.org/licenses/by/4.0/) befolgen. Es bestehen laut Autor keine Interessenskonflikte. Trotz der Tatsache, dass veröffentlichte Karten und institutionelle Zugehörigkeiten Zuständigkeitsansprüche enthalten, ist Springer Nature immer noch neutral.
Die vielen Einsatzmöglichkeiten von Gis
Geografische Informationssysteme (GIS) können für eine Vielzahl von Zwecken verwendet werden, darunter Tatortkartierung, Erforschung des Klimawandels und Landmanagement. Es gibt verschiedene Arten von GIS-Software, die jeweils mehr auf eine bestimmte Aufgabe zugeschnitten sind. ESRI, MapInfo und TopoGIS sind Beispiele für beliebte GIS-Softwarepakete.