
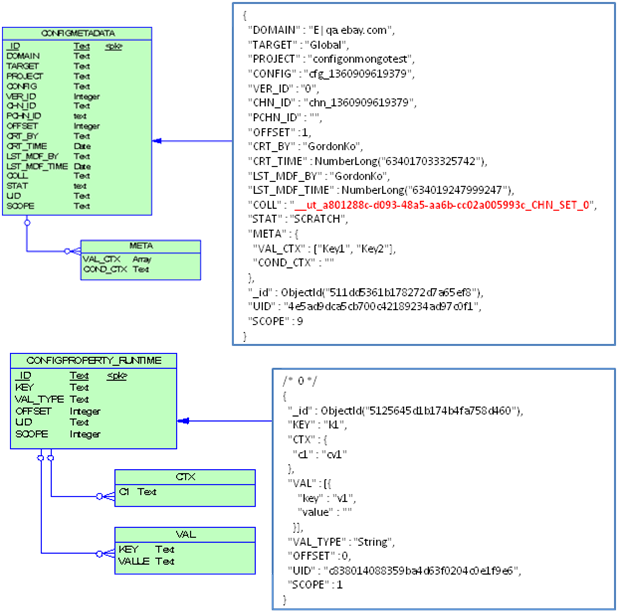
Abflachen von Datenstrukturen für NoSQL-Datenbanken
Veröffentlicht: 2022-11-24Bei der Arbeit mit NoSQL-Datenbanken ist es oft notwendig, Datenstrukturen zu „flachen“, um sie in der Datenbank zu speichern. Dieser Prozess beinhaltet das Konvertieren verschachtelter Datenstrukturen in eine einzelne, flache Struktur. Es gibt verschiedene Möglichkeiten, dies zu tun, und der beste Ansatz hängt von den spezifischen Daten und der verwendeten NoSQL-Datenbank ab. In diesem Artikel untersuchen wir einige verschiedene Methoden zum Vereinfachen von Datenstrukturen und erörtern, wann welche am besten verwendet werden.
Mit Hilfe von Couchbase N1QL können Sie NoSQL-Array-Daten abfragen. Diese Dokumente enthalten eine Vielzahl von Abfragemöglichkeiten in NoSQL. In der obigen Abfrage verwenden wir das Schlüsselwort UNNEST, um den Forum-Bucket eines Couchbase- Buckets zu glätten und auszuwählen. Die WHERE-Bedingung sollte verwendet werden, um die folgende Ergebnismenge anzuwenden.
Können wir Nosql für strukturierte Daten verwenden?
Die überwiegende Mehrheit der NoSQL-Datenbanken eignet sich besser zum Speichern strukturierter, halbstrukturierter und unstrukturierter Daten in einer Datenbank als in mehreren Datenbanken.
Der Begriff „unstrukturierte Daten“ hat zahlreiche Konnotationen, sodass er in einer Vielzahl von Kontexten verwendet werden kann. RDBMS erwartet, dass Sie alles im Voraus definieren (z. B. wird es schwierig sein, diese Datentypen in einem DBMS zu verwalten, insbesondere wenn Sie den Spaltennamen und den Datentyp nicht kennen. Wenn ein Benutzer ein Land zum ersten Mal besucht, ist dies der Fall erforderlich, um seine Bewegungen pro Besuch zu verfolgen. Der Name der Tabelle in einer No. SQL-Datenbank kann als Spalte modelliert werden, wobei das Datum des letzten Besuchs das Datum des letzten Besuchs ist. BLOB kann in einer Vielzahl von Datenbanken sicher gespeichert werden. einschließlich relationaler Datenbanken wie Oracle Database und MySQL. Die CLOB- oder BLOB-Daten können nicht mit einer Abfrage nach einem Schlüsselwert durchsucht werden. Der Hauptvorteil besteht darin, dass sie halbstrukturiert (JSON, XML, und nicht alle Felder sind bekannt) und unstrukturiert verwenden Daten.
Eine Anwendung kann unstrukturierte Daten auf verschiedene Weise verwalten. Es könnte in einem Dateisystem gespeichert werden. Es kann auch eine Datenbank verwendet werden, die kein definiertes Schema hat, um es zu speichern. Datenbankschemata: Eine NoSQL-Datenbank ist ein Datenbanktyp, der kein definiertes Schema hat. Die Daten können auf verschiedene Arten gespeichert werden, was bedeutet, dass auf sie auf verschiedene Arten zugegriffen werden kann. Das Konzept eines Data Lake besteht darin, alle Ihre Daten an einem einzigen Ort zu speichern. Eine Datenumgebung kann groß oder klein sein. Ein Data Warehouse ist eine Art Datenbank, die unstrukturierte Daten in einer Organisation speichert. Aus diesen Daten können Erkenntnisse gewonnen werden.
Die Vor- und Nachteile von Nosql-Datenbanken
NoSQL-Datenbanken wie MongoDB können mehr strukturierte und unstrukturierte Daten speichern, was ideal für Daten sein kann, die nicht immer strukturiert sind. Trotzdem sind relationale Datenbanken aufgrund ihrer Fähigkeit, Daten effektiver und effizienter zu speichern, um analytische Anforderungen besser zu erfüllen, immer noch beliebter.
Was ist eine abgeflachte Datenstruktur?
Im Allgemeinen wird die Datenglättung als der Vorgang definiert, bei dem halbstrukturierte Daten, z. B. Name-Wert-Paare in JSON, in separate Spalten zusammengefasst werden, wobei der Name zum Spaltennamen wird, der die Werte enthält. Das Hinzufügen von verschachtelten Strukturen zu Daten ist eine Alternative zum Unflatten.
Flache Datenbanken stellen im Gegensatz zu relationalen Datenbanken keine komplexen Beziehungen zwischen Entitäten dar. Es gibt auch Einschränkungen bei Datenbeschränkungen. Flache Datenbanken hingegen sind nicht mit relationalen Datenbanken zu vergleichen. Einer relationalen Datenbank fehlen im Gegensatz zu einer nicht relationalen Datenbank Abfrage- und Indizierungsfunktionen. Da eine flache Datenbank normalerweise nur von der Software gelesen und genutzt werden kann, die sie hostet, sind Daten in der Datenbank normalerweise nur für die Anwendung verfügbar, die sie hostet.
Wenn ein XML-Schema aktiv ist, ist der Befehl „Schema reduzieren“ aktiviert. Eine neue flache XSD wird generiert, indem (i) die Komponente(n) jedes enthaltenen Schemas als globale Komponenten des aktiven Schemas hinzugefügt und (ii) die Komponente(n) des aktiven Schemas gelöscht werden.
Die Verwendung des Befehls "Schema abflachen" ist eine großartige Möglichkeit, den Speicherbedarf eines Modells zu reduzieren. Es ist möglich, die Anzahl der Speicheranforderungen für Ihr Modell zu reduzieren, indem Sie Ihre Datensätze glätten. Darüber hinaus erleichtert das Vereinfachen Ihres Schemas das Trainieren Ihres Modells.

Kann Nosql ein festes Schema haben?
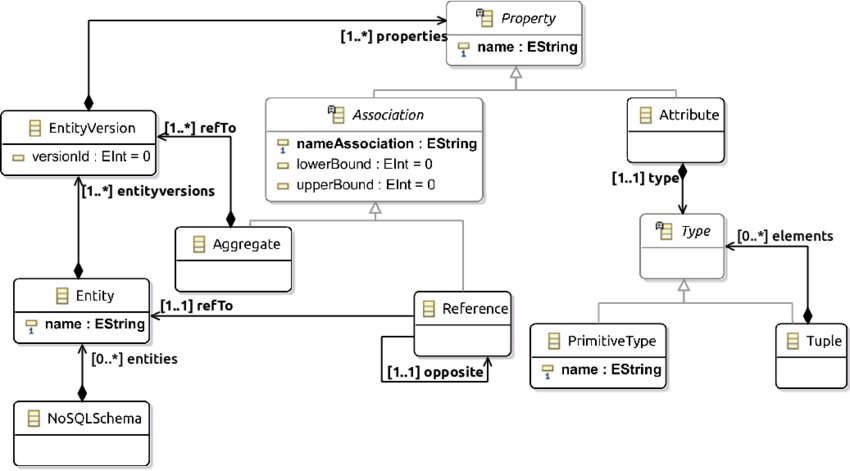
Kann NoSQL ein festes Schema haben? NoSQL-Datenbanken sind so konzipiert, dass sie flexibel und skalierbar sind, daher haben sie kein festes Schema. Das bedeutet, dass Sie Felder nach Bedarf hinzufügen oder entfernen können, ohne die gesamte Datenbank neu gestalten zu müssen.
Bei der Entwicklung von NoSQL-Technologien ist es wichtig, das Design im Auge zu behalten, da diese Technologien keine Lösung aus einer Hand für alle Anwendungsfälle bieten, wie z. B. RDBMS. Es ist entscheidend, einen standardisierten und dennoch benutzerdefinierten Ansatz zum Entwerfen von NoSQL-Datenbanken zu entwickeln. Mit diesem Artikel kann ein NoSQL -Datenmodell erstellt werden, und ich versuche, einen allgemeinen Rahmen dafür zu geben. Da NoSQL ein abfragegesteuertes System ist, können sich Abfragen basierend auf den Anforderungen ändern, und daher muss das Design iterativ geändert werden. Durch die Verwendung von Abfragemustern können wir Container im ersten Schritt identifizieren. Wir können diese Funktion verwenden, um Abfrageanforderungen von Entitäten zu verankern und später bei der Datenverwaltung zu helfen. Dies wird durch den Einsatz agiler Praktiken wie Anforderungserhebung und User-Story-Analyse erreicht.
Die Denormalisierung kann unter Verwendung einer Vielzahl von Techniken implementiert werden, einschließlich Embedding/Flatting und Referenzierung. Als Ergebnis einer solchen Denormalisierung können Spalten in spaltenorientiertem NoSQL als flache Liste von Spalten (optional gruppiert nach Spaltenfamilien) entworfen werden. Die Erfassung und Zuordnung von Multikardinalitätsattributen erfolgt über spezielle Datentypen wie Listen, Mengen, Karten und eingebettete Strukturen. Das Design des Dokumentschlüssels basiert auf einer Hash-Map, die durch Multiplizieren einer Zeichenfolge aus Typ- und Geschäftsschlüsselfeldern zu einer Zeichenfolge erstellt wird. HBase, eine NoSQL-Datenbank mit sekundärem Index, ist eine Ausnahme. Damit Indizes ordnungsgemäß funktionieren, müssen sie so konzipiert sein, dass sie unkritische/Data-Mining-Abfragen ausführen.
Welche Datenbank hat ein festes oder statisches Schema?
Das Schema von SQL-Datenbanken ist fest, statisch oder vordefiniert, je nachdem, ob sie fest oder dynamisch sind. Ein dynamisches Schema ist eines der Merkmale von NoSQL-Datenbanken. SQL-Datenbanken zeigen Daten in einem Tabellenformat an, daher der Begriff „tabellenbasierte Datenbank“.
Was sind die Einschränkungen von Nosql?
Welche Vor- und Nachteile haben NoSQL-Datenbanken? NoSQL-Datenbanken gibt es in vielen Varianten, aber einer ihrer größten Nachteile ist ihre fehlende Unterstützung für ACID-Transaktionen (atomare, konsistente, isolierte und dauerhafte) Transaktionen über mehrere Dokumente hinweg. Es ist akzeptabel, Einzeldatensatz-Atomizität in einer Vielzahl von Anwendungen zu verwenden, wenn Ihr Schema richtig entworfen ist.
Was ist Schema in Nosql?
Schlüssel, Indizes, Denormalisierungen und andere Funktionen von NoSQL-Datenbanken sind so konzipiert, dass sie von den Ergebnissen der Abfrage und des Workflows abhängig sind. Die folgenden Spezifikationen müssen zu Beginn der Erhebung der Abfrageanforderungen angegeben werden: Geschäftsdatenentitäten.
Was ist das Abflachen von Daten in SQL?
Datenglättung in SQL bezieht sich auf den Prozess der Konvertierung von Daten aus einem hierarchischen Format in ein flaches Format. In einem flachen Format werden alle Daten in einer einzigen Tabelle gespeichert, und es gibt keine Verschachtelung von Daten. Dies erleichtert die Abfrage und Verarbeitung der Daten, da nicht mehrere Tabellen verknüpft werden müssen.
Einer meiner Lieblings-T-SQL-Hacks besteht darin, einen Wert aus mehreren Zeilen zu nehmen und ihn in eine einzelne Zeichenfolge umzuwandeln. Scot Becker hat mir diesen Trick vor anderthalb Jahren beigebracht, und ich hatte ihn schon eine Weile gehört. Sie könnten dazu die Northwind-Datenbank verwenden. Um die Produkte nach Belieben zu verwenden, geben Sie eine durch Kommas getrennte Zeichenfolge von Produkten ein. Es wurden keine Cursor oder Schleifen verwendet. Wenn Sie mit vielen Daten arbeiten müssen, ist dies nicht der geeignetste Weg. Dies wird bei einer großen Anzahl von Datensätzen lange dauern.