
Bigtable von Google: Der am weitesten verbreitete spaltenorientierte Datenspeicher
Veröffentlicht: 2022-12-19Bigtable ist ein von Google erstellter spaltenorientierter Datenspeicher. Es ist darauf ausgelegt, große Datenmengen mit einem hohen Maß an Flexibilität zu verarbeiten. Bigtable wird seit über einem Jahrzehnt von Google verwendet und ist die Grundlage für viele seiner Dienste, darunter Gmail, Google Maps und YouTube. Bigtable ist zwar nicht der erste spaltenorientierte Datenspeicher, aber sicherlich der am weitesten verbreitete und bekannteste.
In diesem Artikel untersuchen wir das von Bigtable entwickelte dreidimensionale NoSQL-Speichermodell. Um zu überprüfen, ob es richtig aufgebaut ist, schauen wir uns zunächst an, wie es theoretisch umgesetzt wird, und verwenden dann den Node.js-Client dafür. Das Speichermodell in Bigtable unterscheidet sich von einer ähnlichen Datenbank. Mehrere Zellen in einer Zeilen-/Spaltenkombination können nach einem Zeitstempel pro Zelle geordnet werden. Anstatt Zellen in einer beliebigen Reihenfolge zu speichern, hat jede Zelle den Wert und einen Zeitstempel, um sicherzustellen, dass die Zellen in einer geordneten Reihenfolge gespeichert werden. In diesem Beispiel verwenden wir Node.js und einfaches JavaScript, um Google Cloud Bigtable zu erstellen. In diesem Artikel erfahren Sie, wie Sie mithilfe des Codes eine neue Bigtable-Instanz erstellen.
Wir beginnen damit, eine saubere Umgebung zu schaffen, darauf zu lesen und zu schreiben und sie dann abzureißen. Beim Ausführen von Code mit dem Node.js Bigtable-Client kann der Node.js Bigtable-Client einen Permission Denied-Fehler verursachen und einen Link generieren, um die Cloud Bigtable Admin API zu aktivieren. Außerdem sollten Sie in Ihrem GCP-Projekt ein separates Dienstkonto einrichten, um die Rolle des Bigtable-Administrators zu übernehmen. Um eine Bigtable-Tabelle zu erstellen, müssen wir zuerst eine Instanz der Datenbank und einen Cluster von Tabellen erstellen. Definieren Sie dazu einfach eine Tabellen-ID und eine Spaltenfamilie im Node.js-Client, und schon kann es losgehen. Einfache Zeilen können mithilfe von Bigtable in einer Datenbank erstellt werden. Die einzige Möglichkeit zum Abfragen von Daten besteht darin, den Zeilenschlüssel zum Abfragen einer bestimmten Zeile oder einer Gruppe von Zeilen zu verwenden.
Obwohl Aufnahmezeiten keinen Einfluss auf die Reihenfolge haben, in der Versionen gespeichert werden, wirken sie sich darauf aus, wie sie gespeichert werden. Es ist nicht erforderlich, den gesamten Zeilenschlüssel anzugeben; einfach ein Präfix ist ausreichend. Wenn Sie mehrere Zeilen von Bigtable abfragen müssen, empfehle ich immer die Verwendung von Streaming. Bei der Verwendung von Streaming muss Bigtable keine Daten auf dem Server puffern, bevor Zeilen gesendet werden, was zu einer schnelleren Leistung führt. Filter können verwendet werden, um die Zellversionen einzuschränken und nur die Spalten mit bestimmten Familiennamen oder Spalten mit bestimmten Qualifikationskriterien zurückzugeben. Dies ist besonders nützlich, wenn Sie viele Versionen aufbewahren müssen, für bestimmte Zwecke jedoch nur die neueste Version benötigt wird. Filter werden in erster Linie verwendet, um die Datenmenge zu reduzieren, die abgefragt und gesendet wird, um die Abfrageleistung zu verbessern.
Mit anderen Worten, Cloud Bigtable ist eine NoSQL-Datenbank , die für Analyse- und Betriebsworkloads entwickelt wurde. Dieses Datenbanksystem ist ein plattformübergreifender Hybrid, der Hadoop anstelle von HBase verwendet, das eine spaltenorientierte Datenbank verwendet. Ein Cloud-Bigtable kann verwendet werden, um Anwendungen mit hohem Durchsatz und Skalierbarkeit mit einer Kapazität von weniger als 10 MB zu betreiben.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable und Microsoft Azure CosmosDB sind Beispiele für Wide-Column-Stores.
Tabellen sind in Bezug auf die Speicherung von Schlüsseln/Werten nicht dasselbe wie relationale Datenbanken. Transaktionen können nur einmal durchgeführt werden und Joins werden nicht unterstützt.
Ist Google Bigtable eine Nosql-Datenbank?
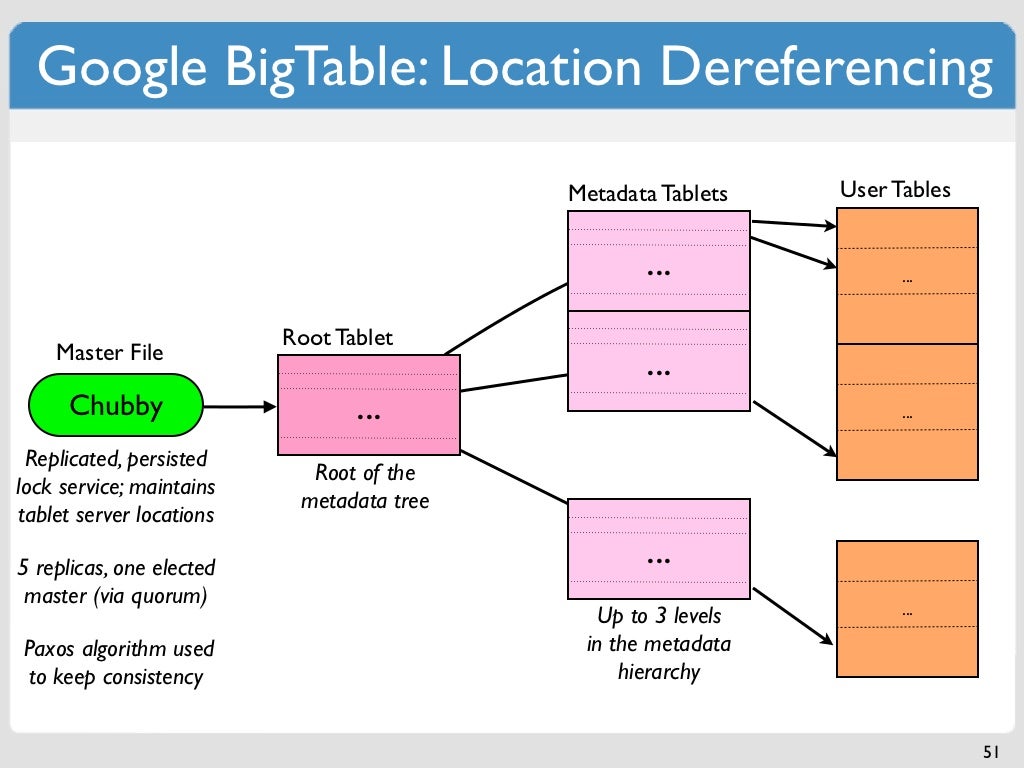
Google Bigtable ist eine NoSQL-Datenbank, die zum Speichern und Verwalten großer Datenmengen entwickelt wurde. Bigtable ist eine spaltenorientierte Datenbank, was bedeutet, dass Daten in Spalten statt in Zeilen organisiert sind. Dadurch eignet es sich gut zum Speichern von Daten, die sich ständig ändern, wie z. B. Webprotokolle oder Social-Media-Daten. Bigtable ist außerdem hochgradig skalierbar, was bedeutet, dass es problemlos mit großen Datenmengen umgehen kann.
Diese NoSQL-Datenbank kann eine Vielzahl von Datentypen speichern und ist äußerst stabil. Es verarbeitet auch Sharding und Replikation und stellt sicher, dass die Datenbank hochverfügbar und zuverlässig ist. Viele Google-Anwendungen verwenden es, einschließlich Google Analytics, Webindizierung, MapReduce und Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting und Google For-Anwendungen, die eine große Datenbank benötigen Anzahl von Datenelementen ist Datastore eine gute Wahl.
In welchen Auftragsdaten werden Bigtable gespeichert?
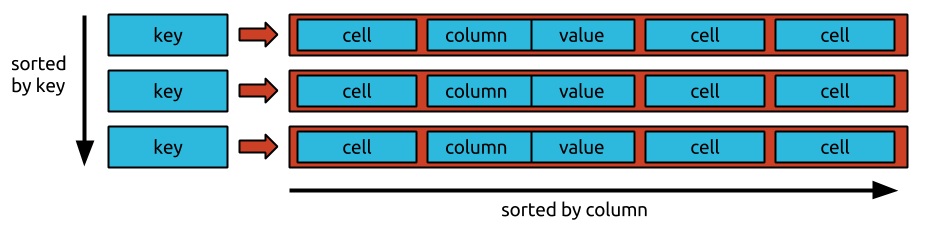
Es gibt keine bestimmte Reihenfolge, in der Daten in Bigtable gespeichert werden. Daten werden in zufälliger Reihenfolge gespeichert, was den Zugriff auf bestimmte Daten erschwert.
Googles Bigtable: Nicht nur zum Speichern von Daten
Daten können innerhalb der igtable nicht in einer bestimmten Reihenfolge platziert werden. Da Bigtable eine zeilenorientierte Datenbank ist, sind alle Daten innerhalb einer Zeile in Spalten organisiert, gefolgt von einer Spalte. Da die Daten in umgekehrter chronologischer Reihenfolge gespeichert werden, ist es einfach und schnell, den neuesten Wert anzufordern, aber es ist schwierig und zeitaufwändig, den ältesten Wert anzufordern.
Aufgrund der Nutzung von Colossus durch Bigtable werden Ihre Daten auf Colossus gespeichert, dem internen, langlebigen Dateisystem von Google, das in den Rechenzentren von Google untergebracht ist. Bigtable kann kostenlos verwendet werden, und Sie müssen keinen HDFS-Cluster oder ein anderes Dateisystem verwenden.
Eine Abfrage an eine externe Datenquelle kann durchgeführt werden, ohne dass eine permanente Tabelle mit dem Befehl Combine erstellt wird: Eine Tabellendefinitionsdatei mit einer Abfrage. Es gibt eine Inline-Schemadefinition sowie eine Abfrage. Eine JSON-Schemadefinitionsdatei mit einer Abfrage.
Bigtable vs. Datenspeicher
Es gibt einige wichtige Unterschiede zwischen Bigtable und Datastore. Erstens ist Bigtable ein spaltenorientierter Datenspeicher, während Datastore zeilenorientiert ist. Das bedeutet, dass Daten in Bigtable in Spalten organisiert sind, während sie in Datastore in Zeilen organisiert sind. Zweitens hat Bigtable im Gegensatz zu Datastore kein Transaktionskonzept. Das bedeutet, dass Sie in Bigtable Änderungen nicht auf einen früheren Zustand zurücksetzen können, während Sie dies in Datastore können. Schließlich ist Bigtable auf hohen Durchsatz und geringe Latenz ausgelegt, während Datastore auf hohe Verfügbarkeit und Skalierbarkeit ausgelegt ist.
Welcher Cloud-Datenspeicher kann zum Erstellen von Google Cloud-Datenbanken verwendet werden? Da Bigtable große Workloads mit komplexen Back-End-Workloads unterstützt, ist es für größere Organisationen und Unternehmen gedacht. Im Gegensatz zu SQL, das die restriktivere Abfragesprache GQL verwendet, führen Datenspeicher ACID-Transaktionen für Teilmengen von Daten durch, die als Entitätsgruppen bekannt sind (obwohl die Abfragesprache GQL viel offener ist). Google Cloud Datastore und Google Cloud Bigtable sind zwei unterschiedliche Dienste mit einer Reihe unterschiedlicher Funktionen. Darüber hinaus können Ihnen die Informationen im Bild unten helfen, den für Sie geeigneten Dienstleister auszuwählen. Die obigen Antworten sowie die im Lehrbuch Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals behandelten Punkte dienen als Leitfaden für diesen Artikel.
Was ist der Unterschied zwischen Bigtable und Datastore?
Was ist der Unterschied zwischen Datenspeicher und Datenbank? Der Bigtable und der Datenspeicher sind beide für die Verarbeitung und Analyse großer Datenmengen ausgelegt, während der Datenspeicher für hochwertige Transaktionsdaten ausgelegt ist. Der Datenspeicher wird auch als NoSQL-Datenbank bezeichnet, da er sich nicht an den traditionellen SQL-Standard hält und Daten flexibler und skalierbarer aufbewahren kann. Was für ein Datenspeicher ist Google Bigtable? Das Bigtable-Speichermodell speichert Daten in massiv skalierbaren Tabellen, die nach Schlüssel- und Wertzuordnungen sortiert sind. Eine Tabelle besteht aus Zeilen, von denen jede eine einzelne Entität beschreibt, und Spalten, von denen jede ihren eigenen Wert hat. Ist der Datenspeicher veraltet? Da die Cloud Datastore API v1beta3 veröffentlicht wurde, ist sie nicht mehr verfügbar. Dennoch ist das Cloud Datastore-Produkt voll funktionsfähig und wird unterstützt.
Bigtable-Datenbank
Ein Bigtable ist ein verteiltes Speichersystem zur Verwaltung strukturierter Daten, das auf eine sehr große Skalierung ausgelegt ist: Petabytes an Daten auf Tausenden von Standardservern. Bigtable ist eine spaltenorientierte Datenbank, was bedeutet, dass Daten spaltenweise und nicht zeilenweise gespeichert werden.
Die Tabelle ist eine spärliche, dicht besiedelte Struktur mit Zeilen und Spalten, die Milliarden von Zeilen erreichen können. Eine Bigtable ist eine ausgezeichnete Wahl zum Speichern großer Datenmengen mit geringer Latenz. Da es einen hohen Lese- und Schreibdurchsatz bei geringer Latenz unterstützt, ist es eine geeignete Datenquelle für MapReduce-Operationen. Wenn Sie eine Bigtable-Tabelle verwenden, wird sie in Blöcke zusammenhängender Zeilen unterteilt, die als Tablets bezeichnet werden, um Abfragen zu vereinfachen. In einem Dateisystem namens Colossus, das Google verwendet, werden Tablets im SSTable-Format gespeichert. Ein Bigtable-Knoten ist eine Teilmenge jedes Tablets, das Teil der Bigtable-Instanz ist. Das Hinzufügen von Knoten zu einem Cluster kann die Anzahl gleichzeitiger Anforderungen erhöhen, die es verarbeiten kann.

Eine Zeile enthält eine Reihe von Schlüssel- oder Werteinträgen, die eine Kombination aus Spaltenfamilie, Spaltenzeitstempel und Schlüssel sind. Bigtable behandelt alle Daten auf die gleiche Weise: als rohe Byte-Strings. Da Bigtable Mutationen sequentiell speichert und regelmäßig komprimiert, erfordert die Anzahl der Mutationen, die zu einem bestimmten Zeitpunkt gespeichert werden können, mehr Speicherplatz. Bigtable komprimiert Ihre Daten mithilfe eines ausgeklügelten automatisierten Algorithmus. Da Deletionen eigentlich neuartige Mutationen sind, benötigen sie kurzfristig mehr Speicherplatz. Die proprietären Speichermethoden von Google ermöglichen es, eine Datenhaltbarkeit zu erreichen, die die durch die standardmäßige HDFS-Drei-Wege-Replikation erreichte übertrifft. Zusätzlich zum Verwalten des Zugriffs auf die Bigtable-Tabellen können Sie den Zugriff auf andere Google Cloud-Dienste verwalten, indem Sie Benutzern im Abschnitt Identity and Access Management (IAM) Ihres Google Cloud-Projekts Rollen zuweisen. Gemäß der Standardverschlüsselungsrichtlinie von Google Cloud werden alle Daten in der Cloud im Ruhezustand mit denselben gehärteten Schlüsselverwaltungssystemen verschlüsselt, die wir für unsere verschlüsselten Daten verwenden. Mithilfe einer Sicherung können Sie eine Kopie des Schemas und der Daten einer Tabelle speichern und diese Kopie der Daten später in einer neuen Tabelle wiederherstellen.
Bigtable gegen Kassandra
Cassandra und Bigtable verwenden unterschiedliche Methoden, um zu bestimmen, welcher Verarbeitungsknoten Lese- und Schreibvorgänge ausführen soll. In Cassandra wird der Partitionsschlüssel als Schlüssel bezeichnet, während in Bigtable der Zeilenschlüssel als Schlüssel bezeichnet wird. Die Load-Balancing-Richtlinie für Cassandra muss vom Client als Teil des Prozesses überprüft werden.
Eine verteilte Datenbank ist eine Datenbank, die von mehreren Personen gemeinsam genutzt wird. Dieses Unternehmen integriert mehrdimensionale Schlüsselwertspeicher in sein System, wodurch es Zehntausende von Abfragen pro Sekunde (QPS) verarbeiten kann. Das Ziel dieses Dokuments ist es, die beiden Datenbanksysteme zu vergleichen und gegenüberzustellen. Zu den Hauptmerkmalen von Bigtable gehören: Ein Papier zu einem verteilten Speichersystem für strukturierte Daten wurde erstellt. Wenn Bigtable feststellt, dass für einen Datensatz ein Bereichsausgleich erforderlich ist, kann ein Verarbeitungsknoten die Datenbereiche einfach ändern, da die Speicherebene von der Verarbeitungsebene getrennt ist. Bigtable kann auch verwendet werden, um die asynchrone Replikation über geografisch verteilte Cluster mit bis zu vier Clustern in Topologien zu unterstützen. Die Fehlertoleranz von Cassandra ist mit seinem Grad an einstellbarer Konsistenz verbunden.
Durch Konfigurieren einer Topologiestrategie für die Datenreplikation können Sie die geografische Replikation definieren. Im Allgemeinen wird eine QUORUM-Einstellung (oder LOCAL_QUORUM in einigen Rechenzentren) verwendet. Um als erfolgreich angesehen zu werden, muss die Einstellung des Konsistenzniveaus einer Operation mit einer Replikatknotenmehrheit erfüllt werden, die dem Koordinatorknoten antwortet. Durch die Verwendung von Rechenzentrums- und Rack-Konfigurationen sind die Replikate von Cassandra im Vergleich zu herkömmlichen Replikaten in der Lage, mehr Belastungen standzuhalten. Beim Durchführen von Lese- und Schreibvorgängen bestimmt die Topologie, welche Knoten benötigt werden, um Konsistenz zu gewährleisten. Eine Bigtable-Instanz kann einen einzelnen Cluster oder eine Gruppe von bis zu vier großen Replikaten enthalten. Bigtable und Cassandra sind NoSQL-Datenspeicher , bei denen es sich um breite Spaltenspeicher handelt.
Der Zeilenschlüssel von Bigtable wird verwendet, um die globalen Daten in einer Tabelle nach Reihenfolge zu sortieren. Die Nodes von Bigtable gleichen automatisch die Node-Verantwortung für Schlüsselbereiche aus, die auch als Tablets bezeichnet werden, als Teil der Nodes-Funktion von Bigtable. Der Bigtable-Dienst eines Clients erzwingt keine von ihm gesendeten Spaltendatentypen. In Bigtable wird jeder Spalte in einer Tabelle ein Familienname zugewiesen. Obwohl Tabellen häufig mehrere Spaltenfamilien haben (maximal 100 Spalten pro Tabelle), benötigt jede Tabelle mindestens eine Spaltenfamilie. Eine Zeilenschlüsselkreuzung besteht aus zwei Zellen (einer Spaltenfamilie kombiniert mit einem Spaltenqualifizierer). In Cassandra und Bigtable gibt es eine Methode zur Auswahl des Verarbeitungsknotens für Lese- und Schreibvorgänge.
In Cassandra wird der Partitionsschlüssel identifiziert, während in Bigtable der Zeilenschlüssel verwendet wird. Eine Load-Balancing-Richtlinie, die Rechenzentren kennt, wie z. B. eine Multi-Cluster-Richtlinie, bietet das Potenzial für ein Failover. Beide Datenbanken verwenden eine ähnliche Methode zum Beenden eines Schreibvorgangs und wurden auf Geschwindigkeit optimiert. Die Daten werden in den beiden Datenbanken über unveränderliche SSTable-Dateien gespeichert. In Cassandra muss der Koordinator den Client benachrichtigen, dass der Schreibvorgang abgeschlossen ist, bevor mehrere Reproduktionen antworten. Ein erfolgreicher Schreibvorgang in Bigtable kann nur durch eine Antwort von einem Knoten bestätigt werden, da jeder Zeilenschlüssel nur einem Knoten zugeordnet ist. Zellen in beiden Datenbanken dürfen nicht in die zusammengeführte SSTable aufgenommen werden.
Aufgrund der WHERE-Klausel in einer CQL-Abfrage ist es nicht möglich, mehr als eine Zeile in Cassandra zurückzugeben. Nur der Knoten, der für den Schlüsselbereich verantwortlich ist, muss in Bigtable konsultiert werden. Am Verarbeitungsknoten ist es möglich, die Menge der zu lesenden Daten zu begrenzen. Während einer Komprimierungsphase werden SSTables regelmäßig zusammengeführt, und in Bigtable und Cassandra gespeicherte Daten werden darin gespeichert. Es gibt keine Regeln für die Anzahl der Zeitstempelversionen für jede Zelle, aber es können andere Zeilengrößenbeschränkungen gelten. Datenhaltbarkeitsgarantien werden durch das Replikationssystem von Colossus bereitgestellt. Bigtable verfügt wie Cassandra über eine Befehlszeilenschnittstelle und Client-Bibliotheken für viele gängige Programmiersprachen.
Jedem Knoten wird in Bigtable eine SSTable zugewiesen, und die darin gespeicherten Daten werden von diesem Knoten bereitgestellt. Bei der Dimensionierung eines Cassandra-Clusters müssen Sie keine Speicherreplikate berücksichtigen, wie dies bei Bigtable der Fall ist. Solid-State-Laufwerke (SSD) oder Festplattenlaufwerke (HDD) sind die am häufigsten verwendeten Speichertypen für Bigtable-Instanzen . Wie von Cassandra demonstriert, gibt es keinen Verlust an Speicherdichte zum Erreichen von Fehlertoleranz. Es ist möglich, eine Bigtable-Instanz mit minimalem Aufwand und minimaler Ausfallzeit so zu skalieren, dass sie die Workload-Anforderungen erfüllt. Obwohl es nur vier Cluster gibt, kann jeder Cluster in jeder unterstützten Cloud-Region auf der ganzen Welt erstellt werden. Google empfiehlt, die Leistung von Bigtable mit repräsentativen Daten und Abfragen zu testen, um eine QPS-Metrik pro Knoten zu generieren.
Cassandra führt eine große Anzahl von Verwaltungsfunktionen mit von Bigtable verwalteten Komponenten aus. Die Largetable-Sicherungen erstellen wiederherstellbare Kopien der Tabelle, die als Objekte im Cluster gespeichert werden. Backups verbrauchen weniger Knotenressourcen und sind kostengünstiger als Cloud-Speicher. Eine andere Methode zum Sichern von Bigtable ist die Verwendung eines verwalteten Datenexports in Cloud Storage. Interne Wartungsaufgaben wie Betriebssystem-Patching, Knotenwiederherstellung, Knotenreparatur, Überwachung der Speicherkomprimierung und Rotation von SSL-Zertifikaten werden alle nahtlos vom Bigtable-Dienst ausgeführt. Dashboards sind für die Überwachung von Durchsatz- und Nutzungsmetriken auf Instanz-, Cluster- und Tabellenebene auf der Seite der Google Cloud-Konsole von Bigtable verfügbar. Sie können das Überwachungs-Dashboard verwenden, um eine erweiterte Leistungsoptimierung durchzuführen.
Das Bigtable-Papier beschreibt ein Datenspeichersystem, das massives Scale-out unterstützt. Jede Tabelle in den Daten ist in eine Reihe von Partitionen unterteilt. Sie können die Tabelle mithilfe eines Zeilenschlüssels oder eines Bereichs von Zeilenschlüsseln abfragen. Das Bigtable-Papier beschreibt auch eine Methode zum Verteilen der Arbeit der Tabelle über einen Cluster von Knoten. Apache Cassandra, eine Open-Source-Datenbank, basiert auf einigen Konzepten aus dem Bigtable-Papier. Rechenzentren verwenden eine verteilte Knotenarchitektur, in der der Speicher von den Servern geteilt wird, die die Daten bereitstellen. Der Zugriff auf das Datenspeichersystem von Bigtable erfolgt über die cbt-Befehlszeilenschnittstelle und die Client-Bibliotheken. Bigtable enthält neben Python eine Reihe von Programmiersprachen, was die Integration in Anwendungen vereinfacht.
Datastax Astra Cassandra von Google als Service: Einfach bereitzustellen und zu skalieren
Googles DataStax Astra Cassandra as a Service ist eine ausgezeichnete Wahl, um mehr über Cassandra zu erfahren. Die Benutzeroberfläche von Kubernetes Operator vereinfacht die Konfiguration, Verwaltung und Skalierung Ihrer Cassandra-Bereitstellung.
Bigtable-Dokumentation
Die Bigtable-Dokumentation ist eine großartige Ressource, um mehr über dieses leistungsstarke Tool zu erfahren. Es bietet einen Überblick über die Funktionen und Möglichkeiten von Bigtable sowie detaillierte Informationen zur Verwendung. Die Dokumentation ist gut organisiert und leicht verständlich, was sie zu einer wertvollen Ressource für alle macht, die daran interessiert sind, mehr über dieses leistungsstarke Tool zu erfahren.
Die Google Cloud Platform ist für das Hosting der Bigtable-Datenbank von Google verantwortlich. Es ist einfach, OpenTSDB 2.1 und höher zu verwenden, wenn es in Verbindung mit Googles Backend verwendet wird. Sie müssen lediglich eine Bigtable-Instanz erstellen, Ihre TSDB-Tabellen mit der Bigtable HBase-Shell einrichten und die TSDs starten. Die Kunden von Bigtable befinden sich derzeit in der Beta-Phase und durchlaufen eine Reihe von Änderungen.
Das effiziente Datenlayout von Bigtable
Bigtable eignet sich auch gut für MapReduce-Operationen. Aufgrund seines effizienten Datenlayouts kann MapReduce große Datenmengen in kurzer Zeit verarbeiten.