
Horizontale Skalierbarkeit mit NoSQL-Datenbanken
Veröffentlicht: 2022-11-20NoSQL-Datenbanken sind horizontal skalierbar, was bedeutet, dass sie durch Hinzufügen weiterer Knoten zu einem System skaliert werden können, im Gegensatz zur vertikalen Skalierung, die sich auf das Hinzufügen weiterer Ressourcen zu einem einzelnen Knoten bezieht. Das bedeutet, dass eine NoSQL-Datenbank fragmentiert oder in mehrere Teile geteilt werden kann und jeder Teil auf einem separaten Server gespeichert werden kann. Dies ermöglicht eine horizontale Skalierung der Datenbank, die viel effizienter und skalierbarer ist als eine vertikale Skalierung.
Skalierung ist für SQL- und NoSQL-Datenbanken von entscheidender Bedeutung, und das Konzept des Datenbank-Shardings ist ein wesentlicher Bestandteil davon. Wie der Name schon sagt, teilen wir die Datenbank in Chunks (Shards) auf.
Darüber hinaus fehlt es in NoSQL an dynamischen Operationen. Es gibt keine Garantie dafür, dass die Verbindung SÄURE-Eigenschaften hat. In solchen Fällen bieten sich SQL-Datenbanken an. Wenn Ihre Anwendung außerdem Laufzeitflexibilität erfordert, vermeiden Sie NoSQL.
Welche Nachteile haben NoSQL-Datenbanken? Einer der Nachteile von NoSQL-Datenbanken besteht darin, dass ihnen die ACID-Transaktionsunterstützung (Atomicity, Consistency, Isolation, Durability) fehlt, die für ACID-Transaktionen über mehrere Dokumente hinweg erforderlich ist. Viele Anwendungen können mit dem richtigen Schemaentwurf Einzeldatensatz-Atomizität verwenden.
Kann Mongodb geteilt werden?
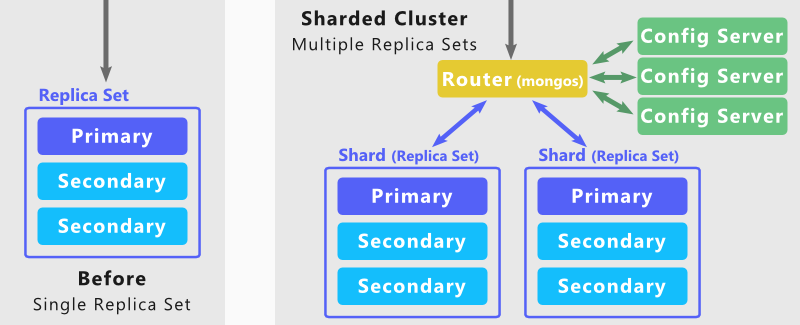
Das MongoDB-Backend basiert auf einer Sharding-Architektur, um extrem große Datensätze und Operationen mit hohem Durchsatz zu unterstützen. Große Datenbanken mit großen Datenmengen oder das Ausführen von Hochgeschwindigkeitsanwendungen können dazu führen, dass die Serverkapazität beeinträchtigt wird.
Mit MongoDB Sharding können Sie Ihre Datenbank so skalieren, dass sie eine unbegrenzte Anzahl gleichzeitiger Benutzer verarbeiten kann. Dies wird erreicht, indem der Durchsatz von Lese- und Schreibvorgängen sowie die Speicherkapazität des Systems erhöht werden. Es gibt zahlreiche Kollektionen, aus denen Sie wählen können. Wählen Sie den Shard-Schlüssel sorgfältig aus, um die Clusterleistung zu maximieren. Die MongoDB NoSQL-Datenbank unterstützt zwei Arten der Datenverteilung über Cluster mit Sharding-Funktionen. Daten können mithilfe des Bereichsschlüsselwerts eines Shards in Bereiche unterteilt werden. Mithilfe von Hash-Hashing kann der Wert eines gehashten Shards berechnet werden.
Einige Shard-Schlüssel sind möglicherweise geschlossen, aber ihre gehashten Werte befinden sich wahrscheinlich nicht im selben Chunk. Durch Konfigurieren und Aktivieren der Sharding-Einstellung kann auf die Datenbank zugegriffen werden. Stellen Sie sicher, dass Ihre Mongos verbunden sind. Ihre Shards werden ebenfalls dem Cluster hinzugefügt. Jedes Mal, wenn Sie dieses Verfahren durchführen, haben Sie eine Transaktion für jeden Shard abgeschlossen. Es ist notwendig, eine Sharding-Einstellung in Ihrer Datenbank zu aktivieren. Verwenden Sie dann die Methode sh.shardCollection(), um Ihre Sammlung zu fragmentieren. Sie haben jetzt Ihren ersten Sharding-Cluster erstellt. Bisher wurden Router (Mongos-Instanzen) für Anwendungsinteraktionen verwendet.
MongoDB ist eine hervorragende NoSQL-Datenbank für kleine und mittlere Unternehmen, die Skalierbarkeit und Leistung benötigen. Darüber hinaus enthält es Funktionen wie Sharding, das die Verteilung von Dokumenten über Shards hinweg ermöglicht, um die Leistung zu verbessern. Wenn Ihre Datenbank 200 GB oder mehr erreicht, können Sicherungs- und Wiederherstellungsprozesse verlangsamt werden. Wenn Ihre MongoDB-Datenbank eine bestimmte Größe überschreitet, sollten Sie sich daher immer an Ihren MongoDB-Anbieter wenden.
Welche Datenbanken unterstützen Sharding?

Datenbanken, die Sharding unterstützen, sind in der Regel so konzipiert, dass sie auf mehreren Servern ausgeführt werden, wobei jeder Server einen Teil der Datenbank hostet. Dadurch kann die Datenbank auf mehrere Server verteilt werden, was die Leistung und Skalierbarkeit verbessern kann.
Sharding in Nosql

Auf NoSQL-Technologien basierende Partitionierungsmuster umfassen Hashing. Beim Partitionieren wird jede Partition auf einem potenziell separaten Server platziert – möglicherweise auf der ganzen Welt. Benutzer aus der ganzen Welt können von dieser Skalierung profitieren, die es ihnen ermöglicht, gleichzeitig auf verschiedene Teile des Datensatzes zuzugreifen.
Ein Datensatz wird verteilt, indem er in mehreren Datenbanken gespeichert wird, um das gewünschte Ergebnis zu erzielen. Da dieser Ansatz die Aufteilung größerer Datensätze in kleinere Blöcke ermöglicht, können mehrere Datenknoten verwendet werden, um sie zu speichern. Da die Daten auf mehrere Computer verteilt sind, kann eine fragmentierte Datenbank mehr Anforderungen verarbeiten als ein einzelner Computer. Mit Sharding zur unbegrenzten Bewältigung erhöhter Last können Sie den Durchsatz, die Speicherkapazität und die Verfügbarkeit Ihrer Datenbank erhöhen. Wenn Ihre Workload hauptsächlich zum Lesen geschrieben wird, bietet Ihnen die Replikation von Daten erhebliche Leistungssteigerungen, und Sie müssen möglicherweise überhaupt kein Sharding verwenden. Eine andere Architektur ist für eine Arbeitslast erforderlich, die hauptsächlich auf Schreiben basiert oder mit Lese-/Schreibzugriff gemischt ist. Es gibt viele verschiedene Arten und Architekturen von Sharding.

Die Verwendung von bereichsbasiertem Sharding ist eine einfache und unkomplizierte Methode zur horizontalen Partitionierung. seine Wirksamkeit wird jedoch durch die Verfügbarkeit geeigneter Schlüssel und die Wahl geeigneter Bereiche bestimmt. Ein gehashter oder algorithmischer Sharding-Datensatz wird als Eingabe angewendet, wobei die Hash-Funktion oder der Algorithmus verwendet wird, um eine Ausgabe oder einen Hash-Wert zu generieren. Daten können in einem einzigen physischen Raum aufbewahrt werden, indem Hash-basiertes Sharding verwendet wird. In einer relationalen Datenbank können Daten, die einer bestimmten Tabelle zugeordnet sind, auf andere Tabellen verteilt werden. Selbst wenn kein geeigneter Schlüssel beschafft werden kann, ermöglicht das Hashing der Eingaben eine gleichmäßige Verteilung der Daten auf die Shards. Es kann bei reduziertem Sendebetrieb helfen und die Leistung steigern. Ein geografiebasierter Sharding-Dienst hält auch zugehörige Daten an einem Ort auf einem einzigen Server. Ein Ranged Shard ist ein geografisch verteilter Shard, bei dem der Schlüssel für den Schlüssel ein geolokalisierter Schlüssel für die Shards ist. Es gibt eine Reihe weiterer Optionen für die Zuweisung von Geoshards, die in diesem Artikel nicht behandelt werden.
Was ist Sharding in SQL?
Ein Datenspeicher kann über das Hashing-Verfahren auf mehrere Datenbanken verteilt und dann auf mehreren Maschinen gespeichert werden. Dadurch können größere Datensätze in kleinere Blöcke aufgeteilt und in mehreren Datenknoten gespeichert werden, wodurch die Gesamtkapazität des Systems erhöht wird.
Dieser Algorithmus garantiert keine gleichmäßig partitionierten Daten
Dieser Algorithmus garantiert gemäß diesem Algorithmus, dass Daten gleichmäßig über Shards verteilt werden, aber er garantiert nicht, dass sie gleichmäßig über Shards verteilt werden. Eine Zeile in der Partitionsspalte mit dem Datennamen user_id wird gleichmäßig auf die fünf Shards verteilt; Die Datenwerte für die fünf Shards werden jedoch nicht gleichmäßig aufgeteilt.
Verwendet Mongodb Sharding?
Unter Verwendung einer Kombination von Techniken können mehrere Maschinen Daten durch eine Sharding-Methode gemeinsam nutzen. Bei der Bereitstellung großer Datensätze und der Durchführung von Vorgängen mit hohem Volumen setzt MongoDB Sharding ein. Datenbanksysteme mit einer großen Datenmenge oder Anwendungen, die einen hohen Durchsatz erfordern, können eine erhebliche Menge an Speicherkapazität beanspruchen.
Die Zukunft des Shardings: Postgresql
Machen Sie einen Plan für die Zukunft. Die Bereitstellung einer Sharding-Lösung ist nicht nur möglich, sondern auch ein erforderlicher Schritt. Als Teil des Prozesses sind regelmäßige Abstimmungen und Optimierungen erforderlich. Sie sollten sich bewusst sein, dass sich die heutigen Sharding-Lösungen schnell weiterentwickeln, und Sie sollten auf dem Laufenden bleiben. PostgreSQL hat in den letzten Jahren erhebliche Fortschritte im Sharding-Bereich gemacht. Wenn Sie also eine Lösung suchen, die auf mehreren Plattformen verwendet werden kann, sollten Sie ernsthaft darüber nachdenken, sie zu verwenden.
Nosql-Sharding vs. Partitionierung
Partitionierung und Algorithmen zum Sortieren einer großen Menge von Daten in kleinere Abschnitte sind analog. Daten werden so partitioniert, dass sie auf viele Computer verteilt werden können, während Sharding es ermöglicht, sie auf mehrere Computer zu verteilen. Im Allgemeinen werden partitionierte Daten basierend auf einer einzelnen Datenbankinstanz in Teilmengen unterteilt.
Die Partitionierung durch Subtraktion ist zusätzlich zur horizontalen Partitionierung eine Art der Partitionierung. Eine andere Methode ist die vertikale Partition, bei der Sie eine Tabelle in kleinere Teile unterteilen. Wenn Sie eine vertikale Partition replizieren, wird dies als vertikale Partitionierung bezeichnet. Um Daten aufzuteilen, kopieren Sie das Schema und verwenden Sie dann einen Shard-Schlüssel. Hier sind einige Beispiele dafür, wann es angebracht ist, einen Tisch zu teilen. Wenn Daten partitioniert sind, ist es oft einfacher, Abfragen durchzuführen. Angenommen, eine Anwendung enthält eine Bestelltabelle mit einem Verlaufsdatensatz von Bestellungen, und diese Tabelle wird jede Woche partitioniert. Wenn Sie Bestellungen für eine einzelne Woche anfordern, können Sie nur auf eine Partition der Tabelle „Bestellungen“ zugreifen. Ein Partitionsbereinigungsverfahren für diese Abfrage könnte theoretisch eine 100-mal schnellere Ausführung ermöglichen.