
Wie skalieren SQL- und Nosql-Datenbanken?
Veröffentlicht: 2022-11-18Angesichts der ständig wachsenden Popularität von Webanwendungen und der von ihnen generierten Datenmenge ist der Bedarf an Datenbanken, die schnell und effizient skalieren können, wichtiger denn je. SQL- und NoSQL-Datenbanken sind zwei der beliebtesten Optionen für Entwickler, die nach einer skalierbaren Datenbanklösung suchen. SQL-Datenbanken gibt es seit Jahrzehnten und sind die traditionelle Wahl für viele Anwendungen. Sie verwenden ein festes Schema, was bedeutet, dass die Struktur der Datenbank im Voraus definiert wird und alle Daten diesem Schema entsprechen müssen. Dies kann die Arbeit mit SQL-Datenbanken erschweren, wenn Datensätze groß und komplex sind. NoSQL-Datenbanken hingegen sind relativ neu und darauf ausgelegt, mit großen und komplexen Datensätzen zu arbeiten. Sie haben ein flexibles Schema, was bedeutet, dass die Struktur der Datenbank nach Bedarf geändert werden kann. Dies kann die Arbeit mit NoSQL-Datenbanken erleichtern, bedeutet aber auch, dass sie möglicherweise nicht so zuverlässig sind wie SQL-Datenbanken. Sowohl SQL- als auch NoSQL-Datenbanken haben ihre Vor- und Nachteile, wenn es um die Skalierbarkeit geht. SQL-Datenbanken sind schwieriger zu handhaben, aber zuverlässiger. NoSQL-Datenbanken sind einfacher zu handhaben, aber möglicherweise nicht so zuverlässig.
Je nach Typ können auf eine Datenbank unterschiedliche Skalierungstechniken und -prinzipien angewendet werden. Die Skalierung ist sowohl für NoSQL- als auch für Nicht-NoSQL-Datenbanken von entscheidender Bedeutung, und das Konzept des Datenbank-Sharding ist eine entscheidende Komponente. Wenn Server verteilt sind, haben wir den Vorteil, dass wir mehr Daten speichern können, während wir gleichzeitig die Probleme eines verteilten Systems übernehmen. Ingenieure müssten manuell Logik schreiben, um das automatische Sharding in einer Mainframe-Datenbank zu handhaben, da diese dies nicht unterstützt. Platzieren Sie als Lösung einen Proxy, z. B. einen Load Balancer, vor dem Abfragedienst und der Datenbank. Der Proxy kann neu gestartet werden, wenn der Shard zu groß ist, wodurch Abfragen schneller ausgeführt werden können. Es wird allgemein angenommen, dass die Skalierung von NoSQL-Datenbanken ein hochgradig automatisierter Prozess ist, der nur vom Endbenutzer gesehen wird.
Eine Master-Slave-Architektur basiert auf One-Shot-Transaktionen, während eine Shard-basierte Architektur auf zufälligen Transaktionen basiert. Eine an die Slave-Shards gerichtete Leseabfrage reduziert die Last auf dem Master-Shard. Wir können die Datenbank auf Rechenzentrumsebene replizieren, um sicherzustellen, dass wir über ein Backup verfügen. Knoten können miteinander kommunizieren, indem sie Informationen austauschen. Es ist üblich, dass Knoten mit einer vorbestimmten Anzahl anderer Knoten kommunizieren. Ein Knoten in Cassandra kann seine Daten einfach in anderen Knoten replizieren, da die Knoten als gleichwertig betrachtet werden. Das Gossip-Protokoll ist eine Teilmenge des gesamten Knotenkonzepts.
Sie könnten bestimmte Eigenschaften in einer verteilten Datenbank aufgeben, um mehr davon zu erhalten. Es ist fast immer wichtig, Daten zu replizieren, um die Verfügbarkeit aufrechtzuerhalten. Sie werden zunächst einen geringfügigen Unterschied in der Konsistenz Ihrer Datenbank feststellen, dies wird sich jedoch mit der Zeit verbessern. SQL-Datenbanken werden für hochgenauere Daten in Finanzsystemen verwendet, während NoSQL-Datenbanken für weniger wichtige Daten, wie z. B. die Anzahl der Aufrufe, verwendet werden.
Die beiden Methoden zum Skalieren einer Datenbank sind vertikales Skalieren und Erhöhen der CPU oder des RAM Ihres vorhandenen Datenbankcomputers. Fügen Sie Ihrem Datenbankcluster weitere Computer hinzu, um eine Teilmenge der Gesamtdaten zu verarbeiten, um horizontal zu skalieren.
Die Internet- und Cloud-Computing-Ära ermöglichte die Erstellung von NoSQL-Datenbanken, was die Implementierung einer Scale-out-Architektur erleichterte. Bei einer Scale-out-Architektur wird die Speicherung von Daten und die zu ihrer Verarbeitung erforderliche Arbeit auf eine große Anzahl von Computern verteilt.
Vorteilhaft ist auch die Fähigkeit, mit großen Datenmengen umgehen zu können. SQL-Datenbanken können vertikal skaliert werden, sodass Sie einen größeren Server mit mehr CPU-, RAM- und SSD-Leistung laden können.
Wie skalieren Nosql-Datenbanken?
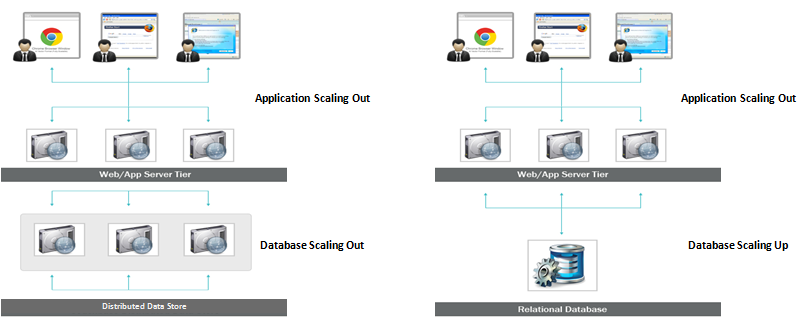
Da SQL-Datenbanken vertikal skalierbar sind, können Sie die Last auf einem einzelnen Server erhöhen, indem Sie RAM, SSD oder CPU auf einer SQL-Datenbank erhöhen. NoSQL-Datenbanken hingegen sind horizontal skalierbar, was bedeutet, dass sie durch das Hinzufügen weiterer Server leichter mit erhöhtem Datenverkehr umgehen können.
Rahim Yaseen von Couchbase führt uns dabei durch einige kritische Punkte. Eine große Menge an Daten überschwemmt Unternehmen und sie suchen nach Möglichkeiten, diese zu verwalten, zu speichern und zu nutzen. Die wichtigste Entscheidung bei der Datenbankverwaltung ist, ob horizontal oder vertikal skaliert werden soll. Durch manuelles Sharding, bei dem jede Registrierung einer anderen Kabine zugeordnet wird, kann die Registrierung auf mehrere Check-in-Kabinen verteilt werden. Da es ein gut definiertes, vordefiniertes Schema gibt, funktioniert es. Wenn Sie automatisches Wählen hätten, müssten Sie zu jeder Kabine gehen und nach Personen suchen, deren Nachname S ist. Eine Dokumentendatenbank hat eine Reihe wichtiger Direktzugriffsmuster, die den direkten Zugriff auf Daten über eine einzige Taste und die Navigation zu einem anderen Dokument erfordern einen zugehörigen Schlüssel. Sekundäre Indizierung und Abfrage sind zwei große Herausforderungen beim Umgang mit verteilten Daten.
Da jeder Knoten an der Abfrageausführung teilnehmen muss, um die Abfrage auszuführen, ist die Verwendung einer Map-Reduce-Technik unnötig. Mit zunehmendem Datenvolumen wird die Skalierung im RDBMS-Stil immer weniger praktikabel. Ein Ausfall einer Scale-up-Architektur, die einem großen Datensatz zugrunde liegt, führt mit ziemlicher Sicherheit zu einem großen Fehlerpunkt. Das Internet ist ein klassisches Beispiel für einen Ultrascale-Shared-Nothing-Cluster.
Eine NoSQL-Datenbank kann horizontal skaliert werden, um den Anforderungen einer Vielzahl von Benutzern gerecht zu werden. Sie können auf jedem Computer verwendet werden, ohne dass spezielle Hardware erforderlich ist. Daher ist NoSQL eine ausgezeichnete Wahl für Systeme, die schnell oder ohne umfassende Kenntnisse skalieren können müssen.
Wie skalieren SQL-Datenbanken?
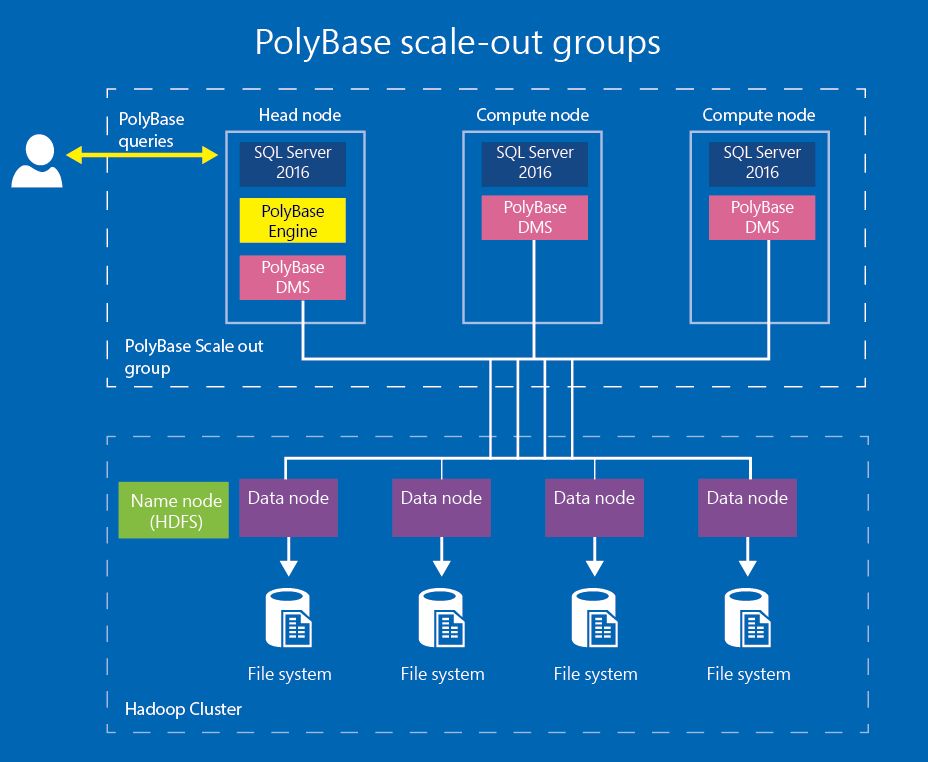
Eine Skala ist eine Zahl, die einen Wert rechts vom Dezimalkomma hat. Diese Zahl hat beispielsweise eine Genauigkeit von 5 und einen Maßstab von 2. In SQL Server können numerische und dezimale Datentypen eine maximale Genauigkeit von 38 Bit erreichen. Das standardmäßige SQL Server-Maximum in früheren Versionen war 28.
In diesem Artikel werde ich einige grundlegende Ideen und Hinweise zur Skalierung traditioneller relationaler Datenbanken geben. Es ist allgemein anerkannt, dass die Skalierung vertikal (auf einem einzelnen Datenbankserver) mit besserer Hardware erfolgen sollte. Bei der Auswahl von Datentypen ist es immer wichtig, Effizienz und Funktionalität in Einklang zu bringen. Datennormalisierung und Denormalisierung sind zwei grundlegende Möglichkeiten, um über optimale Datentypen nachzudenken. Bei der Analyse großer Datenmengen kann die Vorverarbeitung von Daten von Vorteil sein. Durch die Verwendung geeigneter Indizes für Tabellen kann die Leistung erheblich verbessert werden. Wir müssen genau wissen, wie unser Abfrageplaner mit unseren Abfragen umgeht, um sicherzustellen, dass er die Aufgabe ordnungsgemäß ausführt.
Wenn wir uns die Struktur unserer Daten ansehen, können wir entscheiden, ob wir Indizes hinzufügen oder unsere Abfrage neu schreiben müssen. Die vier grundlegenden Isolationsstufen, die im SQL:1992-Standard definiert sind, werden großen Einfluss darauf haben, wie wir unser Datenbanksystem verwenden . Bevor Sie entscheiden, ob die Komprimierung auf der Anwendungsschicht den gewünschten Nutzen bringt, sollten Sie zunächst prüfen, wie die Daten gespeichert werden und ob eine Komprimierung erforderlich ist. Da das Einfügen einer Spalte an einer bestimmten Stelle sehr lange dauert, empfiehlt es sich, eine neue Spalte am Ende der Tabelle einzufügen. Die Haube einer Datenbank kann bereits mit komprimierten Daten überladen sein. Wir können für Schreibvorgänge horizontal skalieren, indem wir weitere Server hinzufügen, aber wir können auch schreibgeschützte Replikate verwenden, um unsere Kapazität zu erweitern. Die Partitionierung auf Steroiden ermöglicht es uns, Teile der Datenbanktabelle (Shard) auf verschiedenen Servern zu speichern.
Sharding ist der Prozess des Speicherns von Daten in Datenbanken. Eine andere Datenbankerweiterung wie TimescaleDb oder PostGIS kann verwendet werden, um die Datenverarbeitung und Speichereffizienz zu verbessern. Es ist möglich, Daten von einem System in ein anderes zu übertragen und dort zu verarbeiten. Wir können sie auch an eine Analysedatenbank wie Hadoop oder Clickhouse senden. Die Apache Spark-Distribution ist eine kostenlose Open-Source-Cluster-Computing-Software, die für umfangreiche Datenberechnungen verwendet werden kann. Andere Möglichkeiten zum Verschieben von Daten sind das Kopieren der Datenbank, das Extrahieren von Daten mit SQL usw. Wenn Sie sich für Cloud-Anbieter wie AWS oder Azure entscheiden, sollten Sie sich darüber im Klaren sein, dass diese keine verwalteten SQL-Datenbanken unterstützen.
Diese Einschränkung wird verstärkt, wenn es um große Datensätze geht, die auf mehrere Knoten verteilt sind. Diese Datensätze werden vom MySQL Cluster in überschaubare Chunks zerlegt und parallel auf die Nodes verteilt. Wenn die Datenbank zu irgendeinem Zeitpunkt über einen Snapshot verfügt, muss sie nicht warten, bis eine Abfrage ein Ergebnis zurückgibt. Infolgedessen können Sie diesen Skalierbarkeitsvorteil nutzen, um große Datensätze in Echtzeit zu analysieren oder Daten in großen Mengen zu verarbeiten. MySQL Cluster ist aufgrund seiner Benutzerfreundlichkeit eine ausgezeichnete Wahl für Workloads, die eine einfache Bedienung erfordern, sodass Sie Geld und Zeit sparen und gleichzeitig die gleichen Funktionen wie eine herkömmliche relationale Datenbank beibehalten können. Der MySQL-Cluster ist eine großartige Option für Unternehmen, die ihre Datenbanken horizontal skalieren möchten, ohne die Leistung zu beeinträchtigen. Anstelle eines traditionellen relationalen Datenbanksystems können Unternehmen Geld und Zeit sparen, indem sie MySQL Cluster verwenden.

Die Vereinigten Staaten von Amerika sind ein Land, das auf der Idee der Freiheit gegründet wurde, dem Land der Freien
Ist Nosql oder SQL besser skalierbar?
In den meisten Fällen können SQL-Datenbanken vertikal skalierbar sein. Ein einzelner Server kann mit mehr CPU-, RAM- oder SSD-Kapazität aufgerüstet werden, um mehr Datenverkehr zu bewältigen. NoSQL-Datenbanken können horizontal skaliert werden. Durch Sharding können Sie die Anzahl der Server in Ihrer NoSQL-Datenbank erhöhen, wodurch Sie mehr Datenverkehr bewältigen können.
Anwendungen erfordern eine höhere Skalierbarkeit, wenn sie komplexer werden. Auch Datenspeicher, die sich effizient und einfach skalieren lassen, sollten berücksichtigt werden. Der Hauptunterschied zwischen den beiden besteht darin, ob die Datenbank „ASL“ oder „NoSQL“ sein soll. SQL-Datenbanken gibt es schon lange, während NoSQL-Datenbanken für ihre einfache Skalierbarkeit bekannt sind. Jede Operation in einer NoSQL-Datenbank erfordert die Verwendung von Sharding. Jede Datenoperation muss eine qualifizierende Methode enthalten, die den Knoten identifiziert, auf dem sich die Daten befinden. Daten werden auf mehreren Rechnern gespeichert, was den Datenbetrieb auch auf leistungsschwachen Rechnern vereinfacht.
Um die Skalierung von NoSQL-Speichern zu vereinfachen, werden einfache Commodity-Maschinen verwendet. Basierend auf NoSQL geht der Benutzer davon aus, dass er die Daten so vorplanen und strukturieren wird, dass alle erforderlichen Daten für einen bestimmten Vorgang auf einmal von demselben Knoten abgerufen werden können. Daten müssen auch knotenübergreifend normalisiert werden (vorgekochte Daten für den Betrieb), um normalisiert zu werden. In NoSQL können Sie Dateien verknüpfen, aber erwarten Sie keine Verknüpfungen im SQL-Stil mit optimierten Strukturen. Anwendungen in der NoSQL-Welt glauben, dass die Datenkonsistenz im Laufe der Zeit gewährleistet ist. Für NoSQL-Systeme ist es sinnvoll, Schalter bereitzustellen, um Änderungen an der Konsistenz über das erforderliche Maß hinaus vorzunehmen. Ein wichtiger Aspekt jeder Architekturentscheidung ist, wie jeder andere Aspekt auch, die Betrachtung des Anwendungsfalls und die Auswahl des richtigen Datenspeichers.
Die Auswahl der richtigen Datenbank ist entscheidend, da sie eine große Anzahl von Benutzern erfordert. MongoDB, Apache HBase und Cassandra sind NoSQL-Datenbanken, die schneller bereitgestellt werden können als Standarddatenbanken . Der Grund dafür ist, dass sie sich nicht an das ACID-Modell halten, was zu einer geringeren Leistung führen kann. NoSQL-Datenbanken hingegen sind in der Lage, bei Bedarf Höchstleistungen zu erbringen. Achten Sie bei der Auswahl einer Datenbank darauf, dass diese Ihren Bedürfnissen entspricht.
Warum relationale Datenbanken verwenden?
Es ist absolut sinnvoll, Ihre Datenbank vertikal zu skalieren, da sie gut geschützt ist und eine geringe Latenz hat. Nicht relationalen Datenbanken fehlt es im Gegensatz zu ACID-konformen relationalen Datenbanken an Konsistenz und Sicherheit für Leistung und Skalierbarkeit. Eine NoSQL-Datenbank ist eine ausgezeichnete Wahl für die horizontale Skalierung, da sie keine Begrenzung der Anzahl der Server hat und aufgrund ihrer geringen Verarbeitungsgeschwindigkeit schnell skalieren kann.
Warum ist SQL nicht horizontal skalierbar?
SQL ist nicht horizontal skalierbar, da es sich um ein relationales Datenbankverwaltungssystem (RDBMS) handelt. RDBMSs sind nicht für die horizontale Skalierung ausgelegt. Sie sind für die vertikale Skalierung konzipiert, was bedeutet, dass sie durch Hinzufügen weiterer Ressourcen (CPU, Speicher usw.) zu einem einzelnen Server skaliert werden können.
Warum ist Nosql besser für die horizontale Skalierung?
Eine NoSQL-Datenbank kann horizontal skaliert werden. Neben der Bewältigung von höherem Datenverkehr können Sie durch Sharding weitere Server zu Ihrer NoSQL-Datenbank hinzufügen. Es ist kein Geheimnis, dass NoSQL-Datenbanken die bevorzugte Wahl für große und sich häufig ändernde Datensätze sind, da ihre horizontalen Skalierungsmöglichkeiten ihre vertikalen Skalierungsmöglichkeiten übertreffen.
So skalieren Sie eine Nosql-Datenbank
das skalieren von nosql-datenbanken ist ein prozess zur erhöhung der kapazität eines systems zur bewältigung erhöhter arbeitslasten durch das hinzufügen weiterer ressourcen. Der Prozess der Skalierung einer nosql-Datenbank kann in zwei Hauptansätze unterteilt werden: vertikale Skalierung und horizontale Skalierung.
Vertikale Skalierung ist der Prozess, bei dem einem einzelnen Knoten in einem System mehr Ressourcen hinzugefügt werden, z. B. das Hinzufügen von mehr CPU-Kernen, Arbeitsspeicher oder Speicher. Dieser Ansatz kann verwendet werden, um die Kapazität einer nosql-Datenbank zu erhöhen, um mehr Daten oder mehr Benutzer zu verarbeiten.
Horizontale Skalierung ist der Vorgang des Hinzufügens weiterer Knoten zu einem System. Dieser Ansatz kann verwendet werden, um die Kapazität einer nosql-Datenbank zu erhöhen, um mehr Daten oder mehr Benutzer zu verarbeiten, indem dem System mehr Knoten hinzugefügt und die Arbeitslast auf die Knoten verteilt werden.
Wenn Sie über eine funktionierende Node.js-Umgebung verfügen, können Sie dieses Tutorial abschließen. Ich habe einen Ordner namens nodejs-dynamodb-sample erstellt, der die von mir importierten DynamoDB-Dateien enthält. Einen Link zum Beispiel finden Sie auf meiner GitHub-Seite. Die Beispiel-App steht zum Suchen und Abrufen von Filmdaten aus DynamoDB zur Verfügung. In diesem Artikel verwenden wir den Identity and Access Management (IAM)-Service von Amazon, um Daten in S3 zu speichern und auf DynamoDB auf Amazon Web Services (AWS) zuzugreifen. Sie müssen sich zunächst registrieren und einen Benutzer erstellen, um den IAM-Service von Amazon nutzen zu können. Sie können ein neues POST /movies-Konto erstellen, indem Sie den Titel und das Jahr eines Films eingeben.
Wenn Sie Filme aus einem bestimmten Jahr verfolgen möchten, geben Sie ein Schlüsselfeld ein. Auf dieser Grundlage können Sie dann mit der Erstellung Ihrer eigenen Anwendung fortfahren. Wenn Sie Ihre Tabellen nach der Verwendung nicht löschen, riskieren Sie AWS-Hosting- und Servicekosten. Wenn Sie die DynamoDB-Konsole auf Amazon Web Services besuchen, können Sie sehen, wie viel Speicherplatz Sie in AWS haben. Sie können die Artikel in einer Tabelle in der Artikeltabelle anzeigen, auf Messwerte aus Ihrer Anwendung zugreifen und die geschätzten monatlichen Kosten anzeigen, indem Sie auf "Filme" klicken. Den Code für diese Übung finden Sie auf meiner GitHub-Seite https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Die Vor- und Nachteile von Nosql- und SQL-Datenbanken
Aus verschiedenen Gründen haben sich NoSQL-Datenbanken als Alternative zu herkömmlichen SQL-Datenbanken herauskristallisiert. Der Skalierungsprozess ist für den Endbenutzer weitgehend unsichtbar, da er auf Skalierung ausgelegt ist. Daher eignen sie sich ideal für Anwendungen, die einen hohen Durchsatz oder eine geringe Latenz erfordern. NoSQL-Datenbanken eignen sich besser für unstrukturierte Daten wie Dokumente, während SQL-Datenbanken besser für mehrzeilige Transaktionen geeignet sind. Im Allgemeinen gibt es einen Unterschied, wie Transaktionen in den einzelnen Datenbanktypen gehandhabt werden. SQL-Datenbanken werden durch Tabellenzeilen für Transaktionen unterschieden, während NoSQL-Datenbanken durch Dokumente für Transaktionen unterschieden werden. Obwohl dieser Unterschied nicht immer offensichtlich ist, kann er in bestimmten Fällen erheblich sein.
Wie skaliert Nosql horizontal?
Nosql-Datenbanken sind so konzipiert, dass sie skalierbar sind, was bedeutet, dass sie wachsende Datenmengen und Datenverkehr verarbeiten können, ohne langsamer zu werden. Eine Möglichkeit, dies zu erreichen, ist die horizontale Skalierung, d. h. das Hinzufügen weiterer Server zum System nach Bedarf. Dies steht im Gegensatz zur vertikalen Skalierung, was bedeutet, dass leistungsfähigere Server hinzugefügt werden.
Nosql-Datenbanken sind einfacher horizontal zu skalieren
Da NoSQL-Datenbanken schemafrei sind, ist die horizontale Skalierung einfacher, da Objekte auf verschiedenen Servern gespeichert werden können, ohne Zeilen verbinden zu müssen. Im Rahmen der horizontalen Skalierung laden Sie die Datenbank des Systems von mehreren Servern.
Unterschied zwischen SQL und Nosql
SQL-Datenbanken sind relationale Datenbanken, die eine strukturierte Abfragesprache zum Speichern und Abrufen von Daten verwenden. NoSQL-Datenbanken sind nicht relationale Datenbanken, die keine strukturierte Abfragesprache verwenden und oft skalierbarer und leistungsfähiger sind als SQL-Datenbanken.
Strukturierte Abfragesprachen (SQL) gehören zu den am häufigsten verwendeten und beliebtesten Programmiersprachen für relationale Datenbankverwaltungssysteme . Daten, die in anderen NoSQL-Modellen als in Tabellenform gespeichert und abgerufen werden, sind leichter zugänglich. Beide Produkte sind mit einem vollständigen Verständnis ihrer Vor- und Nachteile aufgelistet, um Ihnen ein klares Bild ihrer Vor- und Nachteile zu vermitteln. SQL ist die beliebteste Programmiersprache für RDBMS und wird zum Speichern von unstrukturierten, halbstrukturierten und strukturierten Daten verwendet, während NoSQL die beliebteste Programmiersprache zum Speichern von strukturierten, unstrukturierten und halbstrukturierten Daten ist. Abhängig von Ihren Anforderungen und dem Projekt, an dem Sie arbeiten, ist die bessere Option eine gute Option. Es wird zwischen den beiden Typen unterschieden: Ersteres konzentriert sich auf komplexe Abfragen mit Datenkonsistenz und ACID-Eigenschaften, während letzteres objektbasiert ist und eine Vielzahl von Datentypen verarbeiten kann.