
So pflegen Sie Beziehungen zwischen Daten in einer NoSQL-Datenbank
Veröffentlicht: 2022-11-23NoSQL-Datenbanken werden immer beliebter, da die Menge der generierten Daten weiterhin exponentiell wächst. Es herrscht jedoch noch viel Verwirrung darüber, wie diese Datenbanken funktionieren und wie Beziehungen zwischen Daten in einer NoSQL-Umgebung gepflegt werden. In einer herkömmlichen SQL-Datenbank werden Daten in Tabellen gespeichert und Beziehungen werden über Fremdschlüssel aufrechterhalten. In einer NoSQL-Datenbank werden Daten häufig in Dokumenten gespeichert, die Objekten in einer objektorientierten Programmiersprache ähneln. Die Dokumente können geschachtelt werden, was bedeutet, dass Beziehungen ohne die Notwendigkeit von Fremdschlüsseln gepflegt werden können. Es gibt verschiedene Möglichkeiten, Beziehungen zwischen Daten in einer NoSQL-Datenbank aufrechtzuerhalten. Die gebräuchlichste Methode ist die Verwendung von Referenzdokumenten. Ein Referenzdokument ist ein Dokument, das einen Verweis auf ein anderes Dokument enthält. Wenn Sie beispielsweise eine Sammlung von Blogbeiträgen haben, könnte jeder Beitrag einen Verweis auf das Autorendokument enthalten. Eine andere Möglichkeit, Beziehungen zwischen Daten in einer NoSQL-Datenbank aufrechtzuerhalten, ist die Verwendung eingebetteter Dokumente. Ein eingebettetes Dokument ist ein Dokument, das in einem anderen Dokument gespeichert ist. Wenn Sie beispielsweise eine Sammlung von Blogbeiträgen haben, könnte jeder Beitrag ein eingebettetes Dokument haben, das die Autoreninformationen enthält. Der Vorteil der Verwendung von Referenzdokumenten oder eingebetteten Dokumenten besteht darin, dass die Daten in Zukunft einfacher aktualisiert werden können. Wenn Sie beispielsweise den Autor eines Blogbeitrags ändern möchten, müssen Sie nur das Autorendokument aktualisieren. Sie müssen nicht jeden einzelnen Blogbeitrag aktualisieren. Der Nachteil der Verwendung von Referenzdokumenten oder eingebetteten Dokumenten besteht darin, dass die Abfrage der Daten dadurch erschwert werden kann. Wenn Sie beispielsweise alle Blogbeiträge eines bestimmten Autors finden möchten, müssen Sie das Autorendokument für jeden Beitrag abfragen. Dies kann bei einer großen Anzahl von Dokumenten ineffizient sein. Wenn Sie mit einer NoSQL-Datenbank arbeiten, ist es wichtig zu verstehen, wie Beziehungen zwischen Daten gepflegt werden. Referenzdokumente und eingebettete Dokumente sind zwei der gebräuchlichsten Möglichkeiten, dies zu tun.
Die Implementierung von NoSQL in einer dokumentenorientierten Datenbank ist für die Entwicklung von Beziehungen zwischen Objekten unzureichend oder nicht vorhanden. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie die Objekt-/Beziehungsverwaltung an eine Datenbank delegieren. Objektbeziehungen werden mithilfe des REST-API-Aufrufs erstellt. In diesem Beispiel verwenden wir das PUT-Verb, um einen Kunden mit einem Problem zu verbinden. Wenn eine Relation auf diese Weise dargestellt wird, ist immer ein Array von Objekten vorhanden. Nach jeder Referenz auf ein Objekt (zB Relation) können Sie Änderungen am Originaldokument sehen. Da die Datenbank die Verwendung jeder Beziehung aufzeichnet, können wir auch sehen, wo ein bestimmtes Dokument in einer Beziehung verwendet wird. Unter Verwendung der unten gezeigten Beispielabfragen können Sie das Vorhandensein von impliziten Verweisen auf ein Dokument finden, indem Sie eine spezielle Abfrage verwenden: referencedby=true.
Es gibt Beziehungen zwischen verschiedenen Dokumenten in MongoDB, was ihre logische Beziehung bezeichnet. Mit referenzierten und eingebetteten Ansätzen können Beziehungen modelliert werden. Sehen wir uns im folgenden Beispiel den Fall an, in dem Adressen für Benutzer mit N:N-Beziehungen gespeichert werden.
Many-to-Many (N:M)-Beziehungen sind schwieriger zu implementieren als One-to-Many-Beziehungen, da es in einer relationalen Datenbank keinen einzigen Befehl dafür gibt. Wenn sie in MongoDB implementiert werden, sind sie auf die gleiche Weise. MongoDB erlaubt Ihnen standardmäßig nicht, irgendeine Art von Beziehung zu erstellen.
Nicht relationale Datenbanken , auch als „NoSQL“ bekannt, sind typischerweise reine SQL-Datenbanken. Ihre Fähigkeit, Informationen zu behalten, ist sehr unterschiedlich. Eine nicht relationale Datenbank speichert Daten normalerweise in einem nicht tabellarischen Format, wodurch sie besser an die Anforderungen moderner Datenstrukturen wie SQL- und NoSQL-Datenbanken angepasst werden kann.
Kann eine Nosql-Datenbank relational sein?
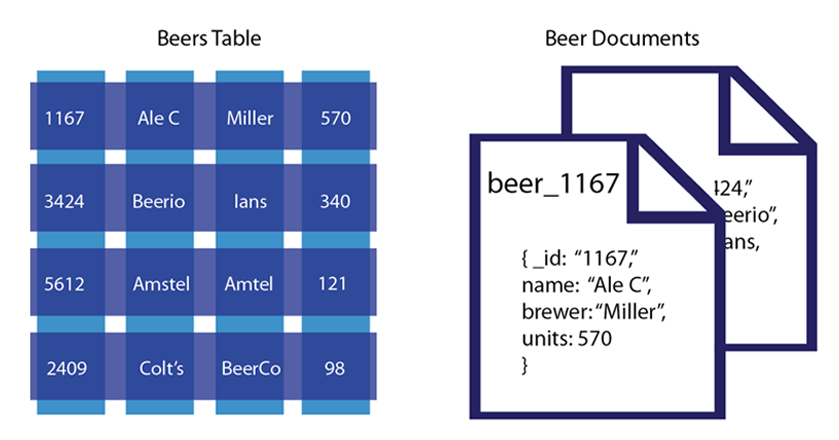
NoSQL-Datenbanken sind keine relationalen Datenbanken, das heißt, sie können andere Strukturen als SQL-Datenbanken haben (z. B. Zeilen und Spalten) und leichter an die Bedürfnisse des Benutzers angepasst werden.
Datenbanksysteme wie relational und NoSQL werden häufig in Cloud-nativen Apps implementiert. Ihre Architektur und Datenspeicherungspraktiken unterscheiden sich ebenso wie ihr Zugriff auf Informationen und Daten. Eine No-SQL-Datenbank speichert unstrukturierte oder halbstrukturierte Daten paarweise oder Dokumente ohne Formatierung. NoSQL-Datenspeicher werden bevorzugt, wenn hochvolumige Dienste Reaktionszeiten von weniger als einer Sekunde erfordern. Wenn Sie nach einem konsistenten System für ein Element suchen, das gerade aktualisiert wird, warten Sie auf diese Antwort, bis alle Repliken erfolgreich aktualisiert wurden. Selbst wenn die Antwort nicht die neueste ist, wird jeder Knoten eine sofortige Antwort zurücksenden. Wenn ein replizierter Datenknoten ausfällt, stellt die Partitionstoleranz sicher, dass das System weiterläuft.
Database as a Service (DBaaS) wird gegenüber anderen Arten von Datendiensten für Cloud-native Anwendungen bevorzugt. Diese Dienste können verwendet werden, um Sicherheit, Skalierbarkeit und Überwachung bereitzustellen. Sie könnten eine virtuelle Azure-Maschine konfigurieren und für jeden Dienst eine Datenbank Ihrer Wahl darauf installieren. Ein Cloud-nativer Microservice kann basierend auf den Anforderungen des Benutzers entweder relationale oder NoSQL-Datenbanken nutzen. Die Plattform Azure Database as a Service (DBaaS) umfasst vier verwaltete relationale Datenbanken. Bei Just-in-time- und Pay-as-you-go-Modellen müssen Sie sich nicht zurückhalten. Die Flaggschiff-Datenbank von Microsoft, SQL Server, ist ebenso verfügbar wie eine Reihe von Open-Source-Alternativen.
Durch Auswahl der erforderlichen Menge an Verarbeitungskernen, Arbeitsspeicher und Speicherplatz können Sie eine Azure-Datenbank in weniger als einer Minute bereitstellen. Microsoft ist bestrebt, Azure als offene Plattform zu halten, daher bietet das Unternehmen verwaltete Versionen beliebter Open-Source-Datenbanken an. Die serverlose Compute-Ebene hält Datenbanken während inaktiver Zeiträume automatisch an, sodass nur Speichergebühren abgezogen werden können. Oracle erwarb Sun Microsystems, und die verwaltete Version von MariaDB wurde als Fork von MySQL erstellt. Die Azure-Datenbank für MariaDB ist ein vollständig verwalteter Datenbankdienst, der als Teil der Azure-Cloud bereitgestellt wird. Der Dienst basiert auf der Server-Engine MariaDB Community Edition. Es kann geschäftskritische Workloads bewältigen, indem es vorhersehbare Leistung und dynamische Skalierung bietet.
Das Befehlszeilenschnittstellentool oder der Azure Data Migration Service sind beide hervorragende Möglichkeiten, Postgres-Datenbanken dorthin zu migrieren. Zusätzlich zur Unterstützung für Aktiv/Aktiv-Clustering auf globaler Ebene unterstützt CosmosDB sowohl Schreib- als auch Lesevorgänge, sodass Sie jede Ihrer Datenbankregionen dafür konfigurieren können. Das CosmosDB-Datenbanksystem kann verwendet werden, um vorhandene Mongo-, Gremlin- oder Cassandra-Datenbanken mit minimalen Code- oder Datenänderungen zu migrieren. Azure-Tabellenspeicher kann für Dienste, die ihn nutzen, problemlos an die CosmosDB-Tabellen-API übertragen werden. Abbildung 5-13 enthält fünf gut definierte Konsistenzmodelle für Azure Cosmos DB. Diese Optionen machen es einfach, die Kompromisse zwischen Konsistenz, Verfügbarkeit und Leistung zu verwalten. Die folgende Tabelle zeigt die Konsistenzstufen für jeden.
Jeremy Likness, Microsoft Program Manager, lieferte eine hervorragende Erläuterung der fünf Modelle. Eine neue Datenbanktechnologie namens NewSQL kombiniert verteilte Skalierbarkeit mit ACID-Garantien, um eine objektorientierte Datenbank zu erstellen. Wenn Cloud-Umgebungen kurzlebig sind, ist es sinnvoll, dass newSQL-Datenbanken aufgrund des Vorhandenseins zugrunde liegender virtueller Maschinen gedeihen, die jederzeit neu gestartet oder neu geplant werden können. Die vorherige Abbildung enthält Open-Source-Projekte, die von der Cloud Native Computing Foundation erstellt wurden. Im Gegensatz zu anderen Workloads, die ein Service-Konstrukt verwenden, kann ein Client eine einzelne DNS-Anfrage an eine Gruppe identischer NewSQL-Datenbankprozesse senden. Wir können skalieren, ohne die Verfügbarkeit bestehender Anwendungsinstanzen zu beeinträchtigen, wenn wir Datenbankinstanzen von den Adressen der ihnen zugeordneten Dienste entkoppeln. Eine bestimmte Anfrage an einen Dienst führt immer zum gleichen Ergebnis, unabhängig davon, wie viele Anfragen gleichzeitig gesendet werden.
Aufgrund ihrer vielen Vorteile werden NoSQL-Datenbanken immer beliebter. Die Fähigkeit, horizontal zu skalieren, mehr Daten zu verarbeiten, Daten flexibler zu speichern und in andere Systeme zu integrieren, sind alles Vorteile von Cloud Computing. NoSQL-Datenbanken haben gegenüber herkömmlichen relationalen Datenbanken eine Reihe von Vorteilen.
Kann Mongodb relational sein?
MongoDB ist nicht nur ein etabliertes, nicht relationales Datenbanksystem mit verbesserter Flexibilität und horizontaler Skalierbarkeit, sondern hat auch einige Vorteile gegenüber relationalen Datenbanken, wie z. B. referenzielle Integrität und Parallelität.
Ist Snowflake eine relationale Datenbank?
Es überrascht nicht, dass Snowflake eine leistungsstarke relationale Datenbank ist. Sie können es mit allen wichtigen relationalen Datenmodellen verwenden, einschließlich der drei Standardmodelle (Tabellen, Relation und Join) und dem ungewöhnlicheren Schneeflockenmodell. Die Datenbank unterstützt auch Echtzeit-Streaming, Objektindizierung und Abfragebeschleunigung sowie alle modernen relationalen Datenbankfunktionen, die in modernen Datenbanken zu finden sind. Ist es relational oder nicht? Diese Datenbank ist eine relationale Datenbank.
Welche Nosql-Datenbank unterstützt keine Beziehungen oder Joins?

Es gibt einige nosql-Datenbanken, die keine Beziehungen oder Verknüpfungen unterstützen, darunter MongoDB, Cassandra und Hbase. Obwohl diese Datenbanken nicht so beliebt sind wie einige der anderen, werden sie immer noch von vielen Organisationen verwendet.
Oracle NoSQL Database unterstützt nicht den allgemeinen Join-Operator, der in herkömmlichen relationalen Datenbanken verwendet wird. Es bietet jedoch einen speziellen Join-Typ für Tabellen mit derselben Hierarchie. Infolgedessen ist die Ausführung von Joins sehr einfach, da nur kolokalisierte Zeilen übereinstimmen können.
Entitätsbeziehung in Nosql
Eine Entitätsbeziehung in nosql ist eine Beziehung zwischen zwei oder mehr Entitäten in einer nosql-Datenbank. Diese Beziehung kann eine Eins-zu-eins-, eine Eins-zu-viele- oder eine Viele-zu-viele-Beziehung sein.
Er-Diagramme für Dokumentendatenbanken
Sie können jedoch die ER-Modellierungsprinzipien verwenden, um auf ähnliche Weise ein ER-Diagramm für eine dokumentorientierte Datenbank zu erstellen. Erstellen Sie ein Datenmodell, das zum Speichern Ihrer Dokumente verwendet werden kann. Die Dokumenttypen, die Sie speichern möchten, die Felder und Eigenschaften für jedes Dokument und das Modell als Ganzes sollten alle in diesem Datenmodell enthalten sein. Zum Erstellen Ihres Datenmodells ist ein Entitätsdiagramm erforderlich. Das folgende Diagramm zeigt die Datenstruktur in Ihrem Dokumentenspeicher. Erstellen Sie dann mithilfe des Beziehungsdiagramms ein Datenmodell. Das folgende Diagramm zeigt die Beziehung zwischen den Entitäten in Ihrem Datenmodell.
Viele-zu-viele-Beziehung in Nosql
Eine Zahl-zu-viele-Beziehung ist eine Beziehung, bei der zwei Entitäten durch mehrere Instanzen derselben Entität verknüpft werden können. Es gibt einige Beispiele aus dem wirklichen Leben: Ärzte können viele Patienten behandeln und gleichzeitig viele Ärzte haben.
Ich möchte eine Taxonomiestruktur (Geobegriffe) für meine node.js-Anwendung mit einer NoSQL-Datenbank implementieren. Die Idee hinter Geo-Tags war es, Personen, die in bestimmten Städten oder Gemeinden geboren wurden, mit diesen Begriffen zu identifizieren, sie später herauszufiltern und sie zu markieren. John Doe wurde 1957 in Blackburn (Lancashire) geboren, Paul Brown 1960 in Liverpool und Georgia Doe 1982 in Wirral. Wenn es im Land nur wenige Strukturelemente gibt, die modernen folgen, werden sie auf diese Weise gefiltert sind nicht möglich. Ich bin ein Neuling in der NoSQL-Welt (ich habe keine NoSQL-Datenbanken entworfen, also habe ich eine ernsthafte Design-Herausforderung vor mir). Ich glaube, es gibt mehrere Lösungsmöglichkeiten.

Krähenfußnotation: Die Viele-zu-Viele-Beziehung
Sie werden die Crow's Foot Notation normalerweise in einer Datenbank sehen, wenn Sie eine Reihe von zu vielen Beziehungen grafisch darstellen. Die Beziehungen zwischen Tabellen werden gemäß dieser Notation durch eine Reihe von Linien dargestellt. Die Ursprünge eines Diagramms (obere linke Ecke) beginnen normalerweise mit einer Linie, die zur Tabelle führt, die als „fremd“ bezeichnet wird (weil dort der Ursprung liegt). Danach gehen die Zeilen zur zugehörigen Tabelle, gefolgt von der untergeordneten Tabelle.
Nosql-Dokumentation
Die Nosql-Dokumentation ist ein Prozess oder eine Reihe von Regeln, die zum Schreiben von Nosql-Code verwendet werden. Es ist ein Codierungsstil, der darauf ausgelegt ist, den Nosql-Code lesbarer und leichter verständlich zu machen.
NoSQL-Datenbanken speichern Daten im Gegensatz zu herkömmlichen relationalen Datenbanken nicht in einem festen Format. Die häufigsten Typen sind Dokumente, Schlüsselwerte, breite Spalten und Diagramme. In den späten 2000er Jahren führte ein deutlicher Rückgang der Speicherkosten zur Entwicklung von NoSQL-Datenbanken. Entwickler können diese Tools verwenden, um riesige Mengen unstrukturierter Daten zu speichern, sodass sie an einer Vielzahl von Projekten arbeiten können. Dokumentdatenbanken, Key-Value-Datenbanken, Wide-Column-Stores und Graph-Datenbanken sind einige der gängigsten NoSQL-Datenbanken. Da keine Verknüpfungen erforderlich sind, sind Abfragen schneller. Zu den häufigsten Anwendungsfällen gehören kritische (z. B. Finanzdaten) und amüsantere (z. B. Speichern von IoT-Messwerten aus einer intelligenten Katzentoilette) Anwendungen.
In diesem Tutorial werden wir uns ansehen, wie eine NoSQL-Datenbank funktioniert und warum sie für eine Vielzahl von Anwendungen von Vorteil ist. Darüber hinaus werden wir einige häufige Missverständnisse über NoSQL-Datenbanken und ihre Anwendungen untersuchen. Laut DB-Engines ist MongoDB die weltweit am weitesten verbreitete nicht-relationale Datenbank. Sie benötigen keine Software auf Ihrem Computer, um in diesem Tutorial eine MongoDB-Datenbank abzufragen. Ein Cluster ist eine Sammlung von Datenbanken, in denen MongoDB-Datenbanken gespeichert sind. Auf den Atlas-Datenspeicher kann zugegriffen werden, wenn Sie über einen Cluster verfügen. Es gibt drei Arten von Datenbanken, die Sie erstellen können: manuell in Atlas Data Explorer, in MongoDB Shell oder in MongoDB Compass, je nach Ihrer bevorzugten Programmiersprache.
Dieses Beispiel zeigt, wie der Beispieldatensatz von Atlas importiert wird. Eine NoSQL-Datenbank kann Entwicklern eine Reihe von Vorteilen bieten, z. B. flexible Datenmodelle, horizontale Skalierung, blitzschnelle Abfragen und Benutzerfreundlichkeit. Sie können neue Dokumente einfügen, vorhandene bearbeiten und Dokumente im Daten-Explorer löschen. Mit dem Aggregations-Framework können Sie Ihre Daten auf sehr leistungsfähige Weise analysieren. Sie können Atlas- und Atlas Data Lake-Daten ganz einfach in Diagrammen anzeigen.
Nosql-Abfrage
NoSQL-Datenbanken werden häufig verwendet, wenn Skalierbarkeit wichtiger ist als Datenkonsistenz. NoSQL-Datenbanken werden manchmal auch als „nicht nur SQL“ bezeichnet, um zu betonen, dass sie möglicherweise SQL-ähnliche Abfragesprachen unterstützen.
Früher waren Datenmodelle und Abfragesysteme eng integriert. Wir können jetzt Datenbanksysteme erstellen, die die Entwicklerproduktivität priorisieren, und damit beginnen, die Abfragemethode vom Datenmodell zu abstrahieren, um die Entwicklerproduktivität zu priorisieren. SABRE, die weltweit erste kommerzielle Datenbank, wurde 1994 von IBM und American Airlines gegründet, um die Effizienz von Flugtickets zu verbessern. NoSQL-Datenbanken wurden in den letzten Jahren auf Skalierbarkeit, Betriebszeit, Redundanz, Flexibilität und Flexibilität optimiert. Zusätzlich zum Hinzufügen von Map-Reduce als Option in Riak und MongoDB haben sie es auch zu CouchDB und Riak hinzugefügt. Wir hatten eine einfache deklarative Ad-hoc-Abfrage von SQL erwartet, aber es stellte sich heraus, dass es sich eher um einen Skripttrick handelte. Wenn Sie ein Datenbanksystem erstellen, das sich leicht skalieren lässt, stehen Abfragen nicht im Vordergrund.
XQuery und Jsoniq sind Versuche, eine Standardabfragesprache zu erstellen, die verwendet werden kann, um hierarchische Dokumente in Dokumentendatenbanken abzurufen. MarkLogic, eine XML-Dokumentendatenbank, verwendet XQuery zusätzlich zu XQuery, während ArrangoDB seine eigene Obermenge verwendet, die auf die Datenmodellierung abgestimmt ist. Beide Sprachen haben eine starke Verbindung zum Format der auf der Festplatte gespeicherten Daten, und beide wurden kommerziell verwendet. Eine oder beide der in einer Dokumentendatenbank verwendeten Abfragesprachen beziehen sich auf die in der Datenbank verwendeten Abfragesprachen. N1QL (oder Non-First-Form-Query-Sprache) ist im Gegensatz zu SQL von Natur aus äußerst SQL-ähnlich. Obwohl Beziehungen nicht erzwungen werden, arbeiten wir gemeinsam an Dokumenten, unabhängig davon, ob sie formell oder informell sind. Sowohl Couchbase als auch Cassandra haben viel Zeit und Mühe in ihre Indizes und Abfrage-Parses gesteckt, damit sie Daten auf diese Weise abfragen können, ohne dass eine relationale Suche erforderlich ist.
Können Sie in Nosql abfragen?
Der Name NoSQL bezieht sich nicht auf SQL. SQL ist nicht die bevorzugte Methode zum Schreiben von Abfragen in No SQL. Die Software speichert Daten nicht im relationalen Format, sondern organisiert.
Was ist ein Nosql-Beispiel?
Spaltenbasierte NoSQL-Datenbanken wie Cassandra, HBase und Hypertable sind weit verbreitet.
Ist Nosql einfacher als SQL?
SQL-Datenbanken haben den Vorteil, Abfragen zu verarbeiten und Daten tabellenübergreifend zu verknüpfen, was komplexere Abfragen für strukturierte Daten, wie z. B. Ad-hoc-Anforderungen, ermöglicht. Die produktübergreifende Konsistenz einer NoSQL-Datenbank, insbesondere beim Umgang mit großen Datenmengen, ist ein gemeinsames Merkmal dieser Art von Datenbanken.
Nosql-Datenmodell
Was ist ein NoSQL-Datenmodell? Was sind die Vor- und Nachteile? Es gibt kein relationales Datenbankmanagementsystem (RDBMS), und dieses Modell ist unmöglich zu replizieren. Infolgedessen gibt es für das Modell keinen expliziten Weg, um zu verstehen, wie die Daten zusammenhängen – wie alles zusammenkommt.
8 Datenmodellierungsmuster in Redis behandelt die Grundlagen der Datenmodellierung in NoSQL sowie die Best Practices für den Einstieg. Das Buch untersucht acht Datenmodelle, die Entwickler verwenden können, um moderne Anwendungen ohne die Schwierigkeiten zu erstellen, die herkömmliche Datenbanken mit sich bringen können. Mit NoSQL können Sie zwei separate Tabellen oder Sammlungen kombinieren, um eine einzige Tabelle oder Sammlung zu erstellen. Dadurch ist es einfacher, alle relevanten Daten zu finden und deren Zusammenhang zu verstehen. Jede Tabelle in NoSQL kann einzeln angezeigt werden. Wenn Sie 1:n-Beziehungen modellieren möchten, betten Sie begrenzte Listen (z. B. Listen mit bekannter Größe) und unbegrenzte Listen separat ein. Das Produkt ist in diesem Fall das Eine, und die vielen Rezensionen, Autorennamen, Erscheinungsdaten, Bewertungen und Kommentare sind die „vielen“ Variablen.
Das erste Muster ist eine Anzahl-zu-Viele-Beziehung mit unbeschränkten Seiten. Das Ziel einer relationalen Datenbank ist es, Produkte in separaten Tabellen zu speichern. Da die Schemas so flexibel sind und es Ihnen ermöglichen, Typfelder basierend auf dem Typ der Sammlungen zu trennen, können alle Redis Stack-Schemata mit dieser Funktion eingerichtet werden. Wenn Sie Zeitreihendaten akkumulieren und aggregieren, reduziert das Bucket-Muster den Overhead. Ein Revisionsmuster kann in einer Vielzahl von Kontexten verwendet werden, in denen Echtzeitdaten erforderlich sind. Diese Muster können verwendet werden, um die mit JOIN-Operationen in NoSQL verbundenen Komplikationen zu umgehen. Das Baum- und Diagrammmuster ist besonders nützlich für eine Vielzahl von umfangreichen JOIN-basierten Operationen, wie z. B. Personalwesen, CMS, Produktkataloge und soziale Netzwerke.
Dieses Modell wird von einem relationalen Datenbankverwaltungssystem (RDBMS) nicht unterstützt, da es auf einem Modell basiert, das von keinem unterstützt wird. Die Speicherung von Daten kann auf verschiedene Arten erfolgen, einschließlich der Verwendung von Festplatten, In-Memory oder beidem. Redis Launchpad verfügt über eine Reihe von Anwendungen, die mit NoSQL und Redis geschrieben wurden.
Nosql-Daten der Dokumentanwendung
Es gibt viele Gründe, eine Dokumentenanwendung zum Speichern Ihrer Daten zu verwenden. Erstens sind Dokumentendatenbanken sehr flexibel und können Daten problemlos in einer Vielzahl von Formaten speichern. Das bedeutet, dass Sie Daten in JSON-, XML- oder sogar Binärformaten speichern können, wenn Sie dies wünschen. Zweitens sind Dokumentendatenbanken oft einfacher zu skalieren als traditionelle relationale Datenbanken. Dies liegt daran, dass sie sehr einfach über mehrere Server verteilt werden können. Schließlich bieten Dokumentdatenbanken für bestimmte Arten von Abfragen häufig eine bessere Leistung als relationale Datenbanken.
Daten in dokumentenorientierten Datenbanken werden im JSON-Format gespeichert und nicht in Spalten/Zeilen, wie in anderen modernen Datenbanken. Diese Art von Daten ermöglicht es Ihnen, Herausforderungen zu bewältigen, die mit RDBMSs weitaus schwieriger zu meistern sind. Dokumentenspeicher ermöglichen Entwicklern eine schnellere Zusammenarbeit mit agiler Software, indem sie sie zu einer natürlichen und anpassungsfähigen Lösung machen. Die ausdrucksstarke Abfragesprache und die vielseitige Indexfunktion erleichtern die Abfrage auf vielfältige Weise. Durch die Verwendung von ACID-Transaktionen können Sie alle Garantien beibehalten, die Sie von einer relationalen Datenbank gewohnt sind. Ihre Daten werden durch verteilte Systeme unendlich skalierbar und belastbar. Jedes Dokument ist separat untergebracht und lässt sich leichter auf Server verteilen, um sicherzustellen, dass die Datenlokalität nicht leidet.
Dokumentendatenbanken verwenden im Gegensatz zu relationalen Datenbanken eine intuitive, praktische Modellierung, die schneller gelesen werden kann. Da die Datenqualität geringer sein wird, wird es weniger starre Tabellen geben. Da es keine native Skalierung gibt, müssen Sie für teure Scale-up-Systeme bezahlen, wenn Sie Ihre herkömmliche relationale Datenbank partitionieren möchten. Jeder Dokumentenspeicher in einer dokumentenorientierten Datenbank enthält Felder für verschiedene Arten von Dokumenten, und sie sind optional. Während jedes Dokument denselben strukturellen Aufbau hat, gibt es in jedem Dokument unterschiedliche Felder. Jedes Dokument hat seine eigene eindeutige ID, die zum Hinzufügen, Ändern, Löschen und Abfragen von Informationen verwendet werden kann. Es wird allgemein angenommen, dass die Dokumentcodierung ein Standardformat oder eine Komprimierung von eingekapselten Daten (oder Informationen) umfasst.
Dokumentorientierte Datenbanken unterscheiden sich von herkömmlichen Datenbanken dadurch, dass sie viel flexibler sind und keine Konsistenz erfordern. Anstatt Daten an Spalten innerhalb der Datenbank zu senden, werden Daten direkt aus dem Dokument abgerufen. Es müssen nicht jedem Datensatz neue Informationsfelder hinzugefügt werden, sondern nur die relevanten im Dokumentenspeicher.
Der Unterschied zwischen Mongodb und Sql
Es ist wichtig zu beachten, dass Dokumente unterschiedlich sind. Die Anzahl der Felder, die in einem Dokument enthalten sein können, ist unbegrenzt. Dokumenttypen können auch zugehörige Felder enthalten. Ein Dokument könnte beispielsweise einen Kunden in einer Datenbank darstellen. Das Dokument würde den vollständigen Namen, die Adresse und die Telefonnummer des Kunden enthalten. Die Bestellhistorie und der Kontostand des Kunden können ebenfalls in die Felder aufgenommen werden.
Der Unterschied zwischen MongoDB und SQL besteht darin, dass Datenbanken keine Tabellen sind und Dokumente ebenfalls keine Tabellen sind. MongoDB hat keine Sammlung von Feldern wie SQL. Dokumentensammlungen hingegen bestehen aus Feldern, die miteinander in Beziehung stehen.