
So speichern Sie strukturierte Daten in einer NoSQL-Datenbank
Veröffentlicht: 2022-11-17NoSQL-Datenbanken werden häufig zum Speichern unstrukturierter Daten verwendet, sie können jedoch auch zum Speichern strukturierter Daten verwendet werden. Es gibt verschiedene Möglichkeiten, strukturierte Daten in einer NoSQL-Datenbank zu speichern, und die am besten geeignete Methode hängt von den spezifischen Daten und dem gewünschten Ergebnis ab. Eine Möglichkeit, strukturierte Daten in einer NoSQL-Datenbank zu speichern, ist die Verwendung eines dokumentenorientierten Ansatzes. Das bedeutet, dass die Daten in Dokumenten gespeichert werden, die dann in Sammlungen organisiert werden. Eine andere Möglichkeit, strukturierte Daten in einer NoSQL-Datenbank zu speichern, ist die Verwendung eines Schlüsselwertansatzes. Das bedeutet, dass die Daten in einem Schlüsselwertspeicher gespeichert werden, wobei jeder Schlüssel einem Wert entspricht. Schließlich kann ein graphenorientierter Ansatz auch verwendet werden, um strukturierte Daten in einer NoSQL-Datenbank zu speichern. Das bedeutet, dass die Daten in einem Diagramm gespeichert werden, wobei die Knoten die Daten darstellen und die Kanten die Beziehungen zwischen den Daten darstellen.
Der Begriff „unstrukturierte Daten“ hat eine Vielzahl von Konnotationen und bedeutet wahrscheinlich für verschiedene Menschen etwas anderes. RDBMS erwartet von Ihnen, dass Sie alles im Voraus definieren, da es von Ihnen erwartet, dass Sie dies im Voraus tun (insbesondere wäre es beispielsweise schwierig, Daten mit einem Spaltennamen und -typ (wie diesem hier) zu verwalten). B. ein bestimmtes Land, möchten Sie wissen, wie oft sie es besucht haben. In einer No. SQL-Datenbank ist es möglich, die Tabelle so zu modellieren, dass der Name der Zelle dem Namen der Tabelle entspricht. BLOB kann sicher in jedem RDBMS gespeichert werden, einschließlich der Oracle-Datenbank und anderen relationalen Datenbanken . Der Schlüsselwert kann im Fall von CLOB und BLOB nicht angegeben werden. Da sie halbstrukturiert sind (JSON, XML, nicht alle Felder sind bekannt), werden sie unterschieden durch ihre unstrukturierte Natur.
NoSQL-Datenbanken werden häufig verwendet, um halbstrukturierte Daten zu verarbeiten. Die IIoT-Geräte generieren strukturierte, unstrukturierte und halbstrukturierte Daten in Echtzeit. Es ist einfach, strukturierte Daten zu verwalten und zu verarbeiten, wenn die Struktur vom Verkäufer definiert wird.
Hadoop kann einem Unternehmen helfen, Muster und Trends zu strukturieren und zu verstehen, die in riesigen Datenmengen verborgen sind, die aus einer Vielzahl von Quellen generiert werden, insbesondere im Zeitalter riesiger Datenmengen. Es ist offensichtlich, dass die überlegenen Fähigkeiten von Hadoop für unstrukturierte Daten nicht genug betont werden können, aber es kann auch verwendet werden, um komplexe Probleme mit strukturierten Daten zu lösen.
Für Unternehmen, die große Mengen unterschiedlicher und unstrukturierter Daten wie Big Data verarbeiten und analysieren, ist NoSQL die bessere Option. NoSQL-Datenbanken haben nicht die gleichen Einschränkungen wie relationale Datenbanken, welche Daten gespeichert werden können.
Kann Mongodb strukturierte Daten speichern?

Ja, MongoDB kann strukturierte Daten speichern. Dies geschieht durch die Verwendung von BSON (Binary JSON), um Daten in einem Binärformat zu speichern. BSON ist eine Obermenge von JSON, sodass jedes JSON-Dokument in einer MongoDB-Datenbank gespeichert werden kann.
MongoDB zum Beispiel hat in den letzten Jahren aufgrund einer Vielzahl von Faktoren an Popularität gewonnen. Eine große Anwendung, in der Daten nicht strukturiert werden können und flexibel gespeichert werden müssen, eignet sich gut für Cloud-Speicher. Da MongoDB als unstrukturierte Datenbank klassifiziert ist, verwendet es einen anderen Ansatz zur Datenspeicherung . Da JSON ein Datentyp ist, der auf verschiedene Weise formatiert werden kann, werden Textdateien und andere unstrukturierte Assets in diesem Format gehalten. MongoDB ist gut geeignet, um große Datenmengen zu verarbeiten, da es für diesen Zweck entwickelt wurde. MongoDB kann problemlos mit großen Datenmengen umgehen, da es physikalisch unmöglich ist, damit umzugehen.
Welche Art von Daten speichert Nosql?
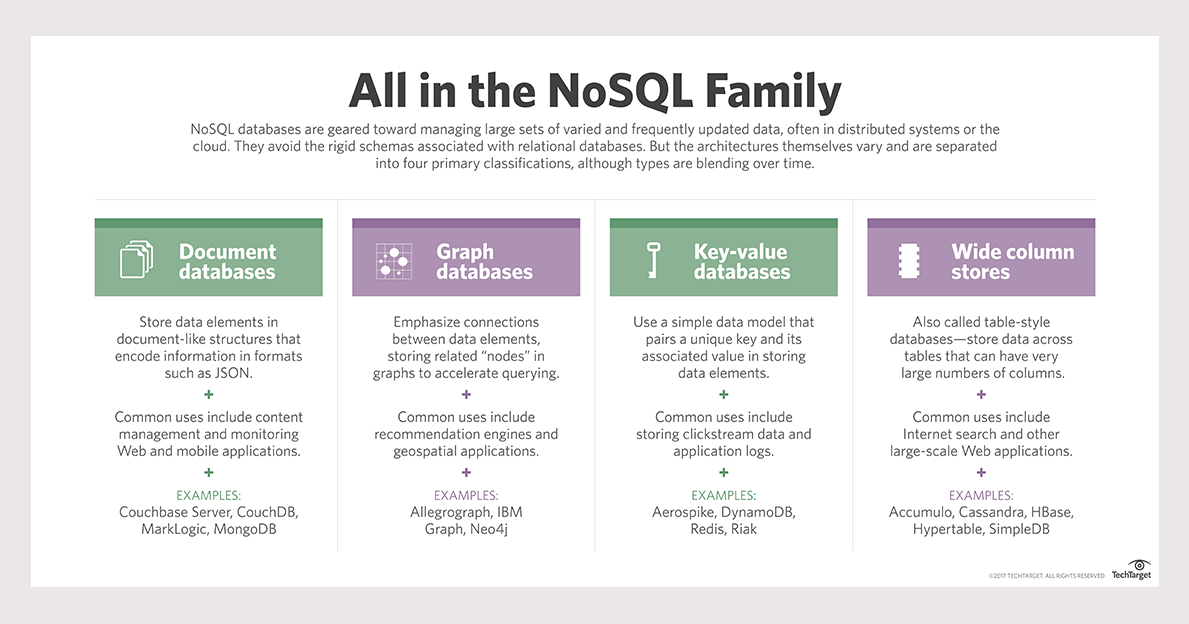
NoSQL-Datenbanken werden verwendet, um Daten zu speichern, die unstrukturiert sind, was bedeutet, dass sie nicht sauber in ein traditionelles Tabellenformat passen. Dies kann Dinge wie Social-Media-Beiträge, Kommentare, Bilder oder alles andere umfassen, das nicht in eine herkömmliche Datenbankstruktur passt . Da NoSQL-Datenbanken flexibler sind, können sie eine gute Wahl für Anwendungen sein, die einen schnellen und einfachen Zugriff auf große Datenmengen erfordern.
Der Begriff „nicht relationale Datenbank“ bezieht sich auf eine Datenbank, die keine feste Struktur hat. Die Key-Value-Store-, spaltenorientierten, dokumentbasierten, Graph- und Graph-Datenbanken sind die gebräuchlichsten Arten von Datenbanken. In der NoSQL-Welt gehören Key-Value-Datenbanken zu den am einfachsten zu verwendenden Datenbanktypen. Die Daten werden mit einer einfachen Reihe von Funktionen gespeichert, gesammelt und entfernt. Eine Key-Value-Store-Datenbank hat keine Abfragesprache, die verwendet werden kann. Die Arten von Daten werden durch die Anforderungen der Anwendungen bestimmt, die sie verarbeiten. Der häufigste Anwendungsfall von Schlüsselwertdatenbanken ist das Aufzeichnen von Sitzungen in Anwendungen, die eine Anmeldung erfordern.
Zusätzlich zu dem allgemeineren Anwendungsfall ermöglicht ein Warenkorb E-Commerce-Websites, Daten über die Einkaufssitzung jedes Benutzers zu speichern. Wenn Feiertagsverkäufe und Sonderaktionen laufen, ist die Skalierbarkeit von Schlüsselwertspeichern nützlich. Darüber hinaus verfügt das System über eine integrierte Redundanz, sodass kein Artikel aus einem Einkaufswagen verloren geht. Schlüssel-Wert-Datenbanken dienen einem bestimmten Zweck und enthalten Funktionen, die einigen einen Mehrwert verleihen, während sie anderen Einschränkungen auferlegen.
Die Programmiersprache MongoDB ist nicht nur beliebt, sondern auch äußerst flexibel. Infolgedessen können Sie die Anzahl der Server erweitern, um die zusätzliche Last zu bewältigen. Darüber hinaus stellt die Replikationsfunktion von MongoDB sicher, dass die Daten immer auf dem neuesten Stand und an mehreren Standorten sind. Daher ist MongoDB eine sehr attraktive Option für große Organisationen, die Daten sowohl zuverlässig als auch konsistent halten möchten.
Sind Nosql unstrukturierte Daten oder halbstrukturierte Daten?
Nicht relationale Datenbanken werden verwendet, um strukturierte und unstrukturierte Daten in NoSQL zu speichern (und nicht nur in strukturierten Abfragesprachen). Aufgrund der hohen Skalierbarkeit und einfachen Suche ist NoSQL ideal für unstrukturierte Daten.

Daten können in einer Vielzahl von Formaten gespeichert werden, z. B. Tabellenkalkulationen, Text- und Video- oder sogar Audiodateien. Es handelt sich um eine Art von Daten, die im Speicher gespeichert werden und von denen erwartet wird, dass sie vor der Speicherung eine vordefinierte Struktur aufweisen. Ein unstrukturierter Datensatz kann nicht in einer relationalen Datenbank gespeichert werden, da ihm ein vordefiniertes Datenmodell fehlt. Unstrukturierte Daten ist ein Begriff, der sich auf unstrukturierte Daten bezieht, die unstrukturiert sind, aber eine Form von Metadaten enthalten, die verwendet werden können, um die Struktur der Daten oder die Hierarchie der Daten zu finden. Ingenieure und Wissenschaftler in maschinellem Lernen und künstlicher Intelligenz analysieren diese Art von Daten mit Techniken wie maschinellem Lernen und KI, um Bedeutung (oder sogar eine übergeordnete Struktur) zu extrahieren. Es umfasst E-Mails und andere Dokumente in einem ähnlichen Format, die jedoch Metadaten enthalten, die es Benutzern ermöglichen, unabhängig vom Format auf bestimmte Informationen auf einer bestimmten Ebene zuzugreifen. Wir haben in diesem Artikel einige reale Beispiele für jeden der verschiedenen Datentypen behandelt und uns auch angesehen, wie sie in modernen Organisationen verwendet werden.
Strukturierte Daten werden typischerweise in Datenbanken gespeichert (die später für Data Warehousing verwendet werden). Unstrukturierte Daten werden in nicht relationalen Datenbanken oder Data Lakes gespeichert, da es kein vordefiniertes Schema gibt, das befolgt werden muss, damit Daten klassifiziert werden können. Für halbstrukturierte und hierarchiebasierte Daten ist MongoDB eine gute Option.
Datenbank-NoSQL-Systeme erfreuen sich aufgrund ihrer Skalierbarkeit und Flexibilität wachsender Beliebtheit. Diese Methode zum Speichern von Daten ist ideal für unstrukturierte und halbstrukturierte Daten sowie für halbstrukturierte und unstrukturierte Daten. Da es einfacher ist, agiler mit Daten zu arbeiten, eignen sie sich ideal für die iterative Entwicklung.
Unstrukturierte Datenspeicherung
Ein unstrukturiertes Datenspeichersystem ist ein Dateisystem, das den gespeicherten Daten keine Struktur auferlegt. Die Daten werden einfach als flache Datei gespeichert, ohne dass das Dateisystem eine Struktur auferlegt. Diese Art von Speichersystem wird typischerweise zum Speichern von Text- oder Binärdaten wie Bildern verwendet, die nicht auf eine bestimmte Weise organisiert werden müssen.
Diese Kategorie umfasst etwa 80 % der unstrukturierten Daten. Das Volumen, die Vielfalt und die Geschwindigkeit unstrukturierter Daten erschweren die Speicherung. Speichersysteme, die traditionell für die Verarbeitung großer Mengen unstrukturierter Daten ausgelegt sind, werden dies in Zukunft möglicherweise nicht mehr können. Daher muss Ihre Datenspeicherinfrastruktur in der Lage sein, eine große Anzahl von Transaktionen zu verarbeiten und zu skalieren. Bei der Entwicklung eines Big-Data-Projekts ist es entscheidend, dass Unternehmen im Voraus planen, unstrukturierte Daten zu speichern. Es ist entscheidend, eine Speicherinfrastruktur auszuwählen, die agil, kostengünstig, skalierbar und auf eine Vielzahl von Anwendungsfällen zugeschnitten ist. Eine Nosql-Datenbank (Norelational) ist eine hervorragende Möglichkeit, diese Informationen zu speichern.
MongoDB Atlas oder andere Cloud-Datenbanken wie MongoDB as a Service (DaaS) sind hervorragende Optionen. Eine MongoDB-Datenbank speichert Daten in einem BSON-Format (json-like) basierend auf Dokumenten. Die Attribute eines Dokuments variieren je nach Datentyp. Da die Daten gesichert werden und repliziert werden können, sind Dokumentenspeicher hochgradig skalierbar und für die Gestaltung verfügbar. Die Database-as-a-Service-Plattform von MongoDB Atlas verwendet große Cloud-Plattformen wie AWS, Azure und Google Cloud zum Speichern von Datenbanken. Bevor auf ein Data Warehouse zugegriffen werden kann, sollte ein Extraktions-, Transformations- und Ladeschritt (ETL) für unstrukturierte Daten durchgeführt werden. Data Warehouses verarbeiten und speichern Daten aus einer Vielzahl von Quellen, um sicherzustellen, dass sie für die Analyse bereit sind. Data Lakes speichern alle Daten in ihrem nativen Format, das eine Mischung aus Rohdaten und verarbeiteten Daten ist.
Aufgrund seiner Einfachheit, seines geringen Gewichts und seiner einfachen Verarbeitung ist JSON ideal zum Speichern unstrukturierter Daten. Es kann einfach in eine Vielzahl von Formaten konvertiert werden, darunter HDFS, Cassandra und MongoDB, die alle von dieser Anwendung unterstützt werden. Da die Daten nicht zusammengeführt werden mussten, war unsere Lösung einfach zu implementieren. Durch die Verwendung der json_archive-Funktion könnten wir separate Dateien für jedes JSON-Objekt erstellen. Eine relationale Datenbank kann unstrukturierte Daten auf verschiedene Arten speichern. Zunächst einmal sind relationale Datenbanken die effizienteste Methode zum Speichern und Abfragen großer Mengen unstrukturierter Daten. Sie ermöglichen eine hocheffiziente Komprimierung großer Datenmengen, und in vielen Fällen sind Abfragesprachen, Semantik und andere Mechanismen enthalten, die bestimmte Datentypen bedienen. Zweitens erleichtert die Struktur der relationalen Datenbank die Datenabfrage. Jeder Datensatz wird als einzelnes JSON-Objekt in einer relationalen Datenbank gespeichert, und alle seine Daten werden als eins gespeichert. Egal, ob Sie nach einem bestimmten Datensatz oder einem vollständigen Satz von Datensätzen suchen, Sie werden die Informationen finden, die Sie benötigen. Der dritte Vorteil einer relationalen Datenbank besteht darin, dass sie große Datenmengen verarbeiten kann. Sie können nicht nur zig Millionen Datensätze speichern, sondern auch komplexe Abfragen verarbeiten.
Unstrukturierte Daten: Was, wo und wie werden sie gespeichert?
Obwohl unstrukturierte Daten in jedem Format gespeichert werden können, werden sie typischerweise in einem Text- oder Nicht-Text-Format gespeichert. Unstrukturierte Daten erfordern im Allgemeinen eine größere Speicherkapazität, da sie nicht in eine vordefinierte Struktur passen. Cloud-Speicher bietet Sicherheit und die Möglichkeit, von jedem Ort aus auf Daten zuzugreifen, was ihn zu einer hervorragenden Option für unstrukturierte Daten macht. Die Verwendung von Dateispeicher ist eine gute Möglichkeit, große Datenmengen zu speichern, um sie zu organisieren. Diese Software basiert auf pfadbasierter Speicherung, was bedeutet, dass Ordner und Verzeichnisse zum Speichern von Daten verwendet werden. Es ist wichtig zu wissen, wo sich Daten in einem Dateispeichersystem befinden, wenn sie gefunden werden sollen.