
InfluxDB: Eine Zeitreihendatenbank
Veröffentlicht: 2022-11-18InfluxDB ist eine in Go geschriebene und von InfluxData entwickelte Zeitreihendatenbank. Es ist auf Skalierbarkeit ausgelegt, wobei der Schwerpunkt auf hoher Schreibleistung und schnellen Abfragen liegt. Es ist auch Open Source, mit einer Community-Version und einer Enterprise-Version. InfluxDB wird häufig in Verbindung mit Grafana, einem Open-Source-Datenvisualisierungstool, verwendet. InfluxDB ist aufgrund seiner hohen Schreibleistung und schnellen Abfrage eine beliebte Wahl für Zeitreihendaten. Es ist auch Open Source, was es für viele Entwickler attraktiv macht.
Um einen Vergleich durchzuführen, haben wir echte PeerSpot-Benutzerbewertungen verwendet, um InfluxDB mit Oracle NoSQL zu vergleichen. In diesem Artikel vergleichen wir die Funktionen, Preise, Service und Support, die einfache Bereitstellung und den ROI von NoSQL-Datenbanken, um herauszufinden, welche für Ihr Unternehmen besser geeignet ist. Seit 2012 wurde unsere Forschung von 648.701 Fachleuten genutzt. InfluxDB, ein Cloud-basiertes Angebot, hat die beste Funktion, nämlich seine Zeitreihen-DB, schnelle Zeitmassenabfragen und Fensteroperationen. Es gibt einige Probleme mit der Bulk-API für InfluxDB, die mit Daten mit hoher Kardinalität nicht kompatibel ist. Verwenden Sie unsere kostenlose Empfehlungs-Engine, um festzustellen, welche NoSQL-Datenbank Ihren Anforderungen am besten entspricht. InluxDB ist ein kostenloses Open-Source-Softwareprogramm, mit dem Entwickler und Unternehmen Zeitreihendaten verwalten können.
Mit InfluxDB können Sie Internet of Things (IoT), Anwendungen, Systeme, Container und Infrastruktur überwachen und analysieren. Ein Rezensent nannte die Datenaggregation und Integration mit Grafana als die wichtigsten Funktionen. Die Oracle NoSQL Database soll ein sehr großes und hochverfügbares Datenbanksystem sein. Vollständige Erstellungs-, Lese-, Aktualisierungs- und Löschvorgänge (CRUD) sowie eine Vielzahl von Haltbarkeits- und Konsistenzgarantien sind verfügbar. Mit vier Bewertungen belegt InfluxDB den fünften Platz im NoSQL-Datenbankmarkt und liegt nur hinter Oracle No SQL, das mit einer Bewertung den siebten Platz belegt. Als die am meisten empfohlene Datenbank hat sie eine sehr einfache Benutzeroberfläche und ist leicht und leistungsstark.
InfluxDB ist keine relationale Datenbank, da sie keine Primär- oder Fremdschlüssel, keine Verknüpfungen von Messungen usw. enthält. Tags als Lösung: Tags werden theoretisch als Workaround verwendet, sind aber nur für Daten mit niedriger Kardinalität geeignet. Sie benötigen viel Speicherplatz, wenn Sie viele Datensätze mit einem eindeutigen ID-Tag haben.
Die influxDB-Datenbank ähnelt einer SQL-Datenbank, es gibt jedoch einige Unterschiede. Diese Datenbank wurde speziell für die Verarbeitung von Zeitreihendaten entwickelt. Obwohl relationale Datenbanken Zeitreihendaten verarbeiten können, sind sie nicht für allgemeine Zeitreihen-Workloads optimiert.
InfluxDB Cloud ist eine vollständig verwaltete, elastische Zeitreihendatenplattform , die es Benutzern ermöglicht, schnell zu starten und schnell zu skalieren, um ihre Anforderungen zu erfüllen.
Eine von InfluxData erstellte Zeitreihendatenbank (TSDB) ist eine Open-Source-Datenbank. Zeitreihendaten wie Vorgänge, Anwendungsmetriken, Internet-of- Things-Sensordaten und Echtzeitanalysen können mithilfe dieser Bibliothek in Go gespeichert und abgerufen werden.
Ist Graphql ein SQL oder Nosql?
In GraphQL verwenden wir ein Typsystem, um Daten effizient in dynamischen Abfragen zurückzugeben, die eine typbasierte Abfragesprache sind. SQL (Structured Query Language) ist ein älterer, weiter verbreiteter Standard für den Entwurf, die Implementierung und die Verwaltung von Datenstrukturen in tabellarischen und hierarchischen Datenbanken. Wenn Sie eine NoSQL-Datenbank für Ihre API verwenden möchten, entscheiden Sie sich für GraphQL.
Sowohl die Type Mismatch- als auch die GraphQL-Datenbank wurden von Cochrane und Herman Camarena erstellt. Ein Typsystem kann mit GraphQL anstelle eines NoSQL-Systems eingeführt werden, da wir immer noch die Vorteile von NoSQL nutzen können. Die Dokumentstruktur in einer GraphQL-Sammlung variiert leicht von einem Dokument zum nächsten, mit einigen Ausnahmen. Aufgrund der GraphQL-APIs kann ein Entwickler auswählen, welche Datentypen er haben möchte, die ungefähr den Typen von Backends entsprechen. Um das volle Potenzial von GraphQL auszuschöpfen, muss das Problem der Typkonflikte angegangen werden. Als Sprache hat es viele Vorteile, die das Mismatch-Problem weniger ernst machen. Mit Tools wie JSON2SDL von StepZen können Sie den Job noch weiter automatisieren.
Graphql ist unabhängig von Datenquellen
Es ist nicht unabhängig von Datenquellen, für die Änderungen gespeichert oder abgerufen werden. Auf Daten kann zugegriffen und sie manipuliert werden, indem willkürliche Funktionen verwendet werden, die als Resolver bekannt sind.
Ist Influx Sql oder Nosql?
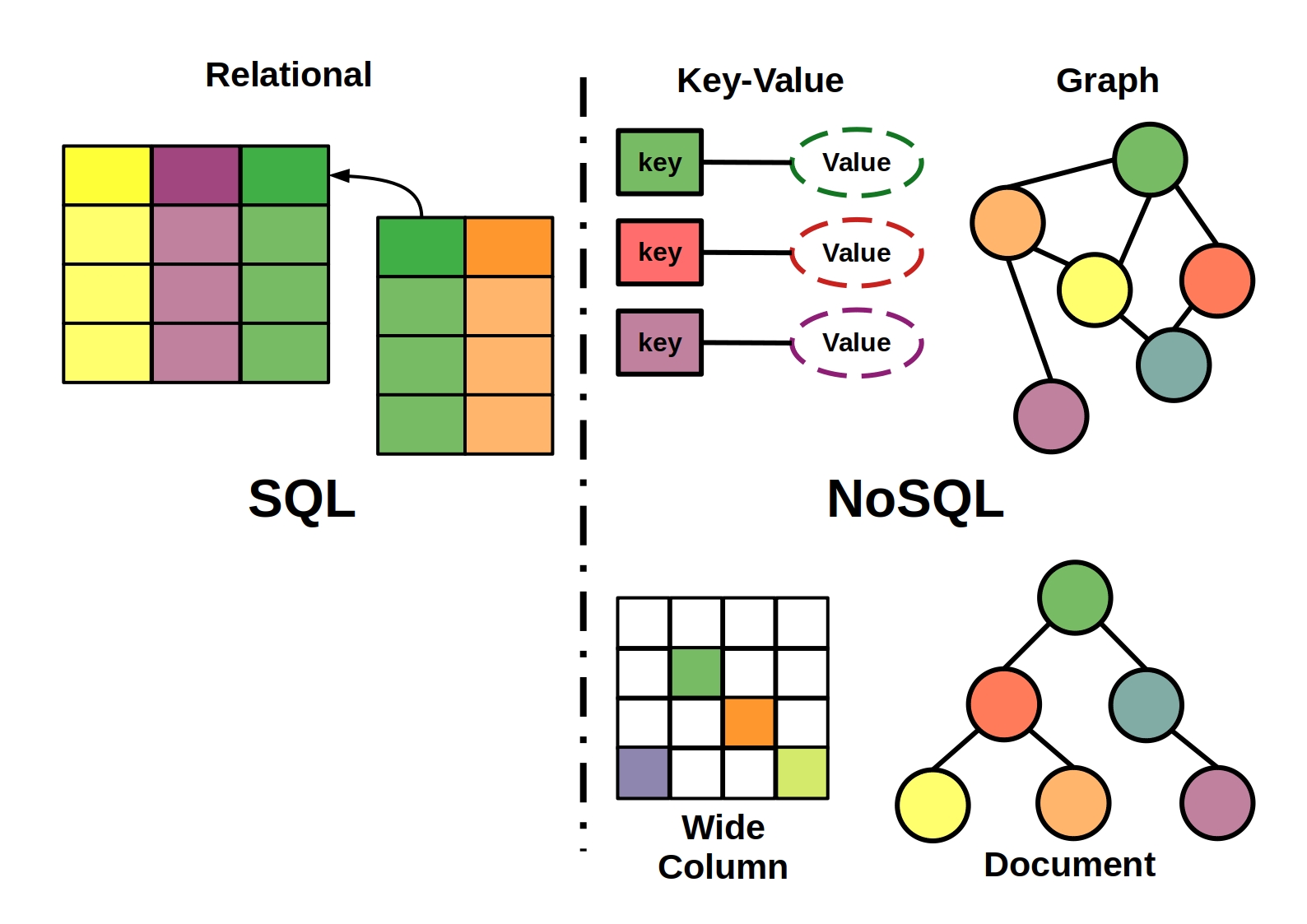
InfluxDB ist eine relationale Datenbank, die von InfluxData entwickelt wurde. ist eine kostenlose Open-Source-Datenbank, die Big Data , NoSQL und Skalierbarkeit kombiniert. Es verfügt über eine hohe Verfügbarkeit, eine hohe Schreibgeschwindigkeit und ist bei Bedarf verfügbar. InfluxDB, eine NoSQL-Datenbank, speichert eine Reihe von Datenpunkten im Laufe der Zeit basierend auf einer Reihe von Zeitreihen-Datenpunkten.
Sein Zweck besteht darin, für Zeitreihendaten verwendet zu werden. Jede Datenreihe hat einen Zeitstempel, der einen einzelnen Punkt darin identifiziert. Bei einer Datenbanktabelle wird der Primärschlüssel in diesem Fall immer vom System gesetzt, genau wie bei SQL-Datenbanken. In den meisten Fällen kann ein neues Feld zu einer Messung hinzugefügt werden, indem einfach ein Punkt dafür geschrieben wird. Ausführlichere Beschreibungen der in diesem Abschnitt erwähnten influxDB-Begriffe finden Sie in unserem Glossar. Wenn Sie InfluxDB 1.8 mit Flux verwenden, können Sie ein grundlegendes Verständnis der Syntax und Konzepte erlangen. InfluxQL, eine SQL-ähnliche Abfragesprache, wird verwendet, um mit influxDB zu interagieren.
Die SQL-Umgebung wurde so konzipiert, dass Benutzer, die aus anderen Umgebungen kommen, damit vertraut sind. Das Programm unterstützt keine erweiterten Operationen wie UNION, JOIN oder HAVING. Der aktuelle Zeitstempel des Servers kann mit relativer Zeit und now() verwendet werden, um die relative Zeit zu berechnen. Diese Abfrage generiert eine Liste mit Foodships-Daten. Eine CR-ud-Datenbank ist keine vollständige CRUD-Datenbank, sondern eher eine afluxDB. Es wurde entwickelt, um die Datengenerierung und das Lesen zu priorisieren, anstatt Daten zu aktualisieren und zu zerstören.
InfluxDB und MySQL sind zwei der am häufigsten verwendeten Zeitreihendatenbanken. Beide Open-Source-Tools sind einfach zu bedienen und können individuell angepasst werden. InfluxDB ist eine ausgezeichnete Wahl für die Analyse von Zeitreihendaten, da es einfacher als alle anderen ist. InfluxDB bietet gegenüber MySQL eine Reihe von Vorteilen. MySQL ist speichereffizienter und schneller zu entwickeln als InfluxDB. Der zweite Grund, warum InfluxDB ein besseres Tool als MySQL ist, ist, dass es stabiler ist. Darüber hinaus bietet InfluxDB eine bessere Unterstützung für Zeitreihenanalysen als MySQL. Für die Zeitreihenanalyse ist InfluxDB eine gute Wahl, da es einfach zu bedienen, speichereffizient und zuverlässig ist. Eine Reihe von Unternehmen, darunter Cisco, Power Home Remodeling, AT&T und Windstream Communications, verwenden bereits InfluxDB.
Die Vor- und Nachteile von Nosql- und SQL-Datenbanken
SQL-Datenbanken bieten eine bessere mehrzeilige Transaktionsverarbeitung als NoSQL-Datenbanken für unstrukturierte Daten wie Dokumente und JSON. SQL-Datenbanken werden auch in Legacy-Systemen verwendet, die in einem relationalen Format geschrieben wurden. Die Daten von InfluxDB werden in einer Shard-Gruppe gespeichert. Daten werden in einer Shard-Gruppe gespeichert und mit Zeitstempeln gespeichert, die im Verlauf als Shard-Dauer definiert und nach Aufbewahrungsrichtlinie (RP) angeordnet sind. Außerdem kann je nach RP die Dauer der Shard-Gruppe angepasst werden. Sie können die Dauer der Shard-Gruppe ändern, indem Sie zur Aufbewahrungsrichtlinienverwaltung wechseln. InfluxDB unterscheidet sich in Aufbau und Bedienung in vielen Punkten von SQL-Datenbanken. Der Zweck von InfluxDB besteht darin, historische Daten zu speichern. Zeitreihendaten können in relationalen Datenbanken gespeichert werden, aber diese Datenbanken sind nicht für routinemäßige Zeitreihen-Workloads optimiert. Der InfluxDBQL-Client ermöglicht SQL-Abfragen von Datenbankdaten.

Welche Art von Datenbank ist Influxdb?
InfluxDB ist eine Open-Source-Zeitreihendatenbank ohne externe Abhängigkeiten. Es ist nützlich zum Überwachen von Metriken, Ereignissen und Analysieren von Analysen.
Die Open-Source-Datenbank InfluxDB ist in einem Zeitreihenformat geschrieben und wird von InfluxData gepflegt. Diese Plattform, die zum Speichern und Abrufen von Zeitreihendaten entwickelt wurde, wird zur Überwachung und Aufzeichnung von Leistungsmetriken und Analysen verwendet. Die Datenbankarchitektur von InfluxDB besteht aus zwei Datenbanken: einem Time Series Index (TSI) für Seriendaten und einem invertierten Index für Mess-, Tag- und Feldmetadaten. InfluxDB, eine Open-Source-Datenbank, speichert Daten in einem Spaltenformat. Darüber hinaus können Spalten in der Datenspeicherung gängige Zeitreihenabfragen wie Scans im Laufe der Zeit unterstützen. Der Time-Structured Merge Tree (TSM) ist die von InfluxDB verwendete Organisationsstruktur. Ein FileStore wird auch verwendet, um den Dateizugriff auf alle TSM-Dateien auf einem Computer zu verwalten.
InfluxDB ist eine leistungsstarke, schnelle und kostengünstige Datenspeicherlösung, die für die Zeitreihenanalyse und -überwachung verwendet werden kann. Es verwendet eine spaltenweise Datenbereitstellung, bei der alle Daten auf einmal bereitgestellt werden, wodurch die Notwendigkeit entfällt, ganze Zeilen zu lesen, um bestimmte Datenwerte zu extrahieren. Daher ist InfluxDB ein nützliches Werkzeug für Daten, die häufig umfangreich und dicht sind, wie z. B. Sensor- und Systemdaten. InfluxDB bietet, wie die meisten Datenbanken, einen hohen Lese- und Schreibdurchsatz sowie spaltenorientierte Funktionalität aufgrund der Verwendung von Sharding und Indexierung. Dies ist eine nützliche Funktion, da Daten von Sensoren oder Systemprotokollen, die regelmäßig aufbewahrt und abgerufen werden müssen, gespeichert und abgerufen werden können. InfluxDB ist eine leistungsstarke und flexible Datenspeicherlösung, die sich gut für die Zeitreihenanalyse und -überwachung eignet. Das Format umfasst ein spaltenweises Array, das Daten spaltenweise liefert, doppelt so schnelle Lese- und Schreibdurchsätze und Indexfunktionen, die eine schnellere Suche und Skalierung ermöglichen. InfluxDB ist eine ausgezeichnete Wahl für eine Vielzahl von Speicheranforderungen, einschließlich umfangreicher Zeitreihendaten sowie solcher, die eine schnelle und effiziente Datenspeicherlösung erfordern.
Influxdb gegen Mongodb
Die Ergebnisse von InfluxDB zeigten, dass es MongoDB in Bezug auf Datenaufnahme und Festplattenspeicherleistung weit überlegen war. In Bezug auf die Datenaufnahme übertrifft InfluxDB MongoDB um den Faktor vier. InfluxDB bot im Gegensatz zu MongoDB die 20-fache Komprimierung.
Nachdem wir Couchbase mehr als 4 Jahre lang genutzt haben, sind wir zu MongoDB gewechselt und könnten nicht zufriedener sein. Wir haben Unternehmensunterstützung erhalten, aber die Erfahrung war schrecklich, obwohl wir als Couchbase-Partner aufgeführt waren. Um es ordnungsgemäß auszuführen, benötigen Sie mindestens sechs Server mit ihren Mindestanforderungen. In der Produktion werden sechs Server benötigt. Eine kleinere Memcached-Instanz wird mit der Couchbase-Instanz ausgeliefert, um den In-Memory-Cache zu verarbeiten. Dieses Programm verfügt über 8 GB RAM und kann 5000 Dokumente unterstützen. Ich bin hier nicht scherzhaft. Auf einer Couchbase-Instanz gab es weniger als 5000 Dokumente, weniger als 20 Indizes und mehr als 8 GB RAM.
Die InfluxDB-Datenbank ist eine sehr gute Wahl für Zeitreihendaten. Daher ist es eine ausgezeichnete Wahl zum Speichern sensibler Daten, da es dem Entwickler die vollständige Kontrolle über seine Datensicherheit ermöglicht. Darüber hinaus ist die Community-Unterstützung von InfluxDB ausgezeichnet, sodass Sie die Organisation bei Bedarf einfach kontaktieren können.
Warum Orientdb die beste Graphdatenbank ist
OrientDB bietet im Gegensatz zu MongoDB eine Reihe von Vorteilen.
Da OrientDB schemafrei ist, können Sie Ihr Datenmodell problemlos modellieren.
Da OrientDB ACID-konform ist, sind Ihre Daten konsistent und dauerhaft.
Die Leistung von OrientDB ist der von MongoDB überlegen, was es zu einer ausgezeichneten Wahl für die Speicherung von Zeitreihendaten macht.
OrientDB könnte die beste Option für Sie sein, wenn Sie nach einer Graphdatenbank suchen. Wenn Sie die True Graph Engine beherrschen, müssen Sie sich nicht mit anderen Datentypen befassen oder andere Systeme implementieren.
Influxdb-Profis
Es gibt viele Gründe, InfluxDB zu lieben. Hier sind nur einige: – Erstens ist InfluxDB unglaublich einfach zu installieren und in Betrieb zu nehmen. Tatsächlich können Sie eine Instanz mit sehr wenig Konfiguration in nur wenigen Minuten zum Laufen bringen. – Zweitens hat InfluxDB eine hervorragende Schreibleistung. Es kann problemlos Millionen von Datenpunkten pro Sekunde verarbeiten, ohne ins Schwitzen zu geraten. – Drittens hat InfluxDB ein sehr flexibles Datenmodell, das leicht an Ihre Bedürfnisse angepasst werden kann. – Viertens verfügt InfluxDB über eine reichhaltige Abfragesprache, die viele verschiedene Arten von Abfragen unterstützt. – Fünftens lässt sich InfluxDB gut in viele verschiedene Arten von Datenquellen und Anwendungen integrieren. Insgesamt ist InfluxDB eine ausgezeichnete Wahl für Zeitreihendaten. Es ist einfach zu bedienen, hat eine großartige Leistung und ist sehr flexibel.
InfluxDB ist eine Zeitreihendatenbank. Um die Leistung für diesen Anwendungsfall zu maximieren, ist es wichtig, Kompromisse einzugehen, hauptsächlich in Bezug auf die Funktionalität. Daten mit sehr aktuellen Zeitstempeln machen die überwiegende Mehrheit der Schreibvorgänge aus und werden in aufsteigender Reihenfolge hinzugefügt. Die fraglichen Daten werden selten aktualisiert, und umstrittene Aktualisierungen sind selten. Für Designer war es schwierig, die Leistung durch den Umgang mit kurzlebigen und nicht aufeinander folgenden Daten zu steigern. Eine Datenbank mit einer großen Anzahl von Lese- und Schreibvorgängen muss groß genug sein, um damit umgehen zu können.
Die leistungsstärkste Zeitreihendatenbank ist ein Dienst, der InfluxDB Cloud und eine Zeitreihendatenbank kombiniert. Dieses kostenlose Tool ist einfach zu bedienen, schnell, serverlos und flexibel und unterstützt beliebte Tools wie Docker und Prometheus. Aufgrund der Popularität von Open Source InfluxDB hat sich das Unternehmen zu einem der erfolgreichsten Unternehmen der Branche entwickelt. In diesem Jahr hat sich die Reichweite von InfluxData dramatisch ausgeweitet, mit über 450.000 aktiven Instanzen von InfluxDB, die weltweit ausgeführt werden. Data Scientists und Ingenieure, die eine leistungsstarke Zeitreihendatenbank benötigen, die sowohl einfach als auch schnell bereitzustellen ist, sind ideale Kandidaten für InfluxDB Cloud.