
Ist Spark für Nosql
Veröffentlicht: 2023-02-05Spark ist ein leistungsstarkes Tool für die Arbeit mit Daten, insbesondere großen Datensätzen. Es ist auf Schnelligkeit und Effizienz ausgelegt und unterstützt eine Vielzahl von Datenformaten, einschließlich NoSQL-Datenbanken . NoSQL-Datenbanken erfreuen sich immer größerer Beliebtheit, da sie sich gut für den Umgang mit großen Datenmengen eignen. Spark kann Ihnen dabei helfen, NoSQL-Daten effizient abzufragen und zu manipulieren.
Um effektiv zu arbeiten, ist es wichtig, die Datenbanken Ihrer Anwendung mit Apache Spark und NoSQL ( Apache Cassandra und MongoDB) zu verwalten. Das Ziel dieses Blogs ist es, Tipps für die Entwicklung von Apache Spark-Anwendungen mit NoSQL-Backends zu geben. Es ist ein Freizeitpark und TCP/IP sPark hat Fahrgeschäfte sowohl im CassandraLand als auch im MongoLand. Als wir versuchten, DOE-Daten abzufragen, begann sich unsere Spark-Anwendung von ihrer Achse zu drehen. Die Lektion hier ist, dass Schlüsselsequenzen wichtig sind, wenn Sie Cassandra abfragen. CassandraLand bietet auch die Achterbahn Partitioner, die eine der beliebtesten Attraktionen ist. Während die Kunden ihre Achterbahnfahrt genießen, können die Betreiber der Fahrten jeden Tag nachverfolgen, wer sie gefahren ist, indem sie ihre Informationen aufbewahren.
In Lektion eins gehen wir auf die Verwaltung von MongoDB-Verbindungen ein. Wenn Sie Informationen über einen Park aktualisieren müssen, z. B. den neuen Mitgliedschaftsstatus des Energieministeriums, können Sie Mongo-Indizes verwenden. MongoDB und Spark sollten verwendet werden, um sicherzustellen, dass Ihre Verbindung ordnungsgemäß verwaltet wird, sowie Indizes in bestimmten Fällen.
Apache Spark ist ein beliebtes verteiltes Verarbeitungssystem, das Open Source ist und für die Verwendung in großen Datenworkloads entwickelt wurde. Diese Funktion ermöglicht neben dem In-Memory-Caching und der optimierten Abfrageausführung schnelle analytische Abfragen für große Datenmengen.
Mit fast demselben Code ist es effizienter und vielseitiger, da es Batch- und Echtzeitdaten gleichzeitig verarbeiten kann. Infolgedessen veralten ältere Big-Data-Tools aufgrund des Fehlens dieser Funktionalität zunehmend.
Welche Art von Datenbank ist Spark?
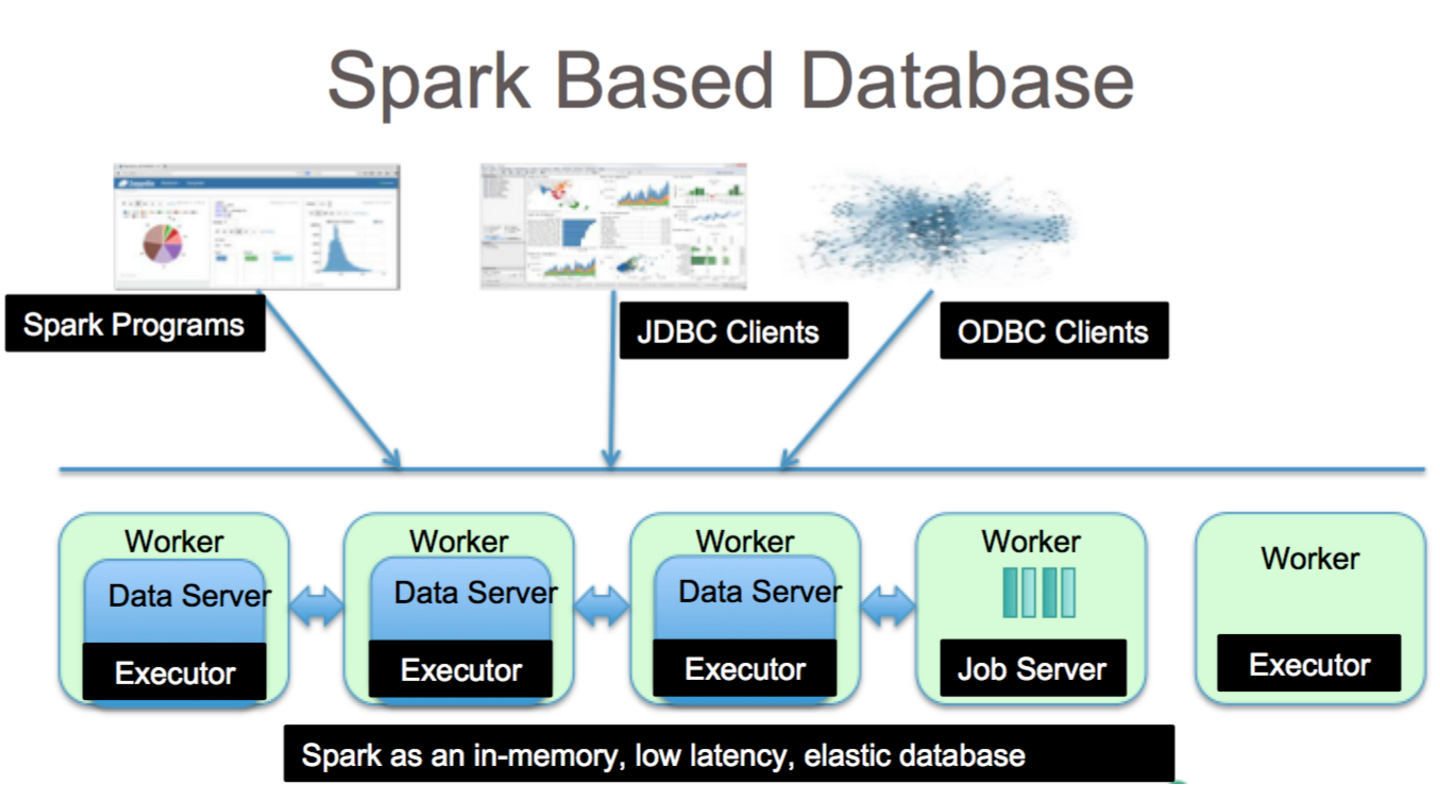
Apache Spark ist ein Datenverarbeitungs-Framework, das Daten aus einer Vielzahl von Datenrepositorys verarbeiten kann, einschließlich (HDFS), NoSQL-Datenbanken und relationalen Datenbanken.
Obwohl es zahlreiche Hype-Zyklen für relationale Datenbanken gegeben hat, werden sie unabhängig von den neuesten Fortschritten und dem Aufstieg von NoSQL-Datenbanken weiterhin beliebt sein. Im Laufe der Zeit ist es immer schwieriger geworden, Daten in relationalen Datenbanken zu speichern. In diesem Artikel werden wir uns einige der bedeutenden Fortschritte bei der Nutzung der Leistungsfähigkeit relationaler Datenbanken auf globaler Ebene ansehen. Als es zum ersten Mal veröffentlicht wurde, war die Schnittstelle zwischen Spark und Big Data Analysis minimal. Viele Leute haben eine Menge Code geschrieben, um dieses Programm auszuführen, das zwar leistungsstark, aber relativ langsam war. Benutzer können diese beiden Modelle problemlos in der Spark-SQL- Datenbank kombinieren. Es akzeptiert auch eine Vielzahl von Datenformaten aus einer Vielzahl von Quellen.
Das Open-Source-Projekt Apache Spark ist das aktivste, an dem Hunderte von Mitwirkenden mitwirken. Abgesehen davon, dass es sich um ein kostenloses Open-Source-Projekt handelt, hat Spark SQL begonnen, in der Mainstream-Branche an Popularität zu gewinnen. Neben Spark SQL verwenden etwa zwei Drittel der Databricks Cloud-Kunden (der gehostete Dienst, auf dem Spark ausgeführt wird) andere Programmiersprachen. Nach Abschluss unserer ersten Fallstudie zeigen wir in dieser praktischen Fallstudie, wie Databricks auf den Fall angewendet werden. Ein Spark DataFrame ist ein Satz von Zeilen (Zeilentypen), die mit demselben Schema verteilt werden. Jede Spalte im Datensatz ist mit einem Namen gekennzeichnet. Die API von DataFrame ermöglicht es Entwicklern, prozeduralen und relationalen Code zu integrieren.
Spark kann auch erweiterte Funktionen wie UDFs verarbeiten. Eine Tabelle in einer relationalen Datenbank ist analog zu einem Datenrahmen in einer Datenrahmendatenbank, es sind jedoch weitere Optimierungen erforderlich. Sie können auf die gleiche Weise manipuliert werden wie die nativen verteilten Sammlungen (RDDs) von Spark. Im Allgemeinen ist die Spark-SQL-Abfrage schneller als die Shark-Abfrage und konkurrenzfähiger mit Impulsa. In Abfrage 3a, wo die Abfrageselektivität dazu führt, dass eine der Tabellen sehr klein wird, gibt es einen signifikanten Unterschied zwischen Impala und Impala.

Es ist ein fantastisches Tool für die Datenanalyse mit Spark SQL. Auf HiveQL-Syntax, Hive-SerDes und HiveDFs kann über die HiveQL-Syntax sowie auf Hive-SerDes und HiveDFs zugegriffen werden. Hive-Metastores , SerDes und UDFs wurden bereits implementiert. Trotz der Tatsache, dass Spark eine Datenbank ist, ist es auch eine NoSQL-Datenbank. Wenn Sie also eine verwaltete Tabelle in Spark erstellen, können Sie eine Vielzahl von SQL-kompatiblen Tools zum Speichern Ihrer Daten verwenden. SQL-Ausdrücke können für den Zugriff auf Tabellen in Spark verwendet werden, indem eine Verbindung zu JDBC über Konnektoren von jdbc.org hergestellt wird. Dadurch können Sie auch Tools von Drittanbietern wie Tableau, Talend und Power BI verwenden. Die Möglichkeit, Spark zu verwenden, ist ideal für die Datenanalyse und ein nützliches Tool für eine Vielzahl von Branchen.
Spark Sql: Das Beste aus beiden Welten
Es schließt die Lücke zwischen den beiden zuvor erwähnten Modellen, dem prozeduralen und dem relationalen Modell, indem es zwei Hauptkomponenten enthält. Infolgedessen können Sie mithilfe einer DataFrame-API umfangreiche relationale Vorgänge für externe Datenquellen und die integrierten verteilten Sammlungen von Spark ausführen.
Was ist Spark in der Datenbank? Es ist ein Open-Source-Framework, das maschinelles Lernen, interaktive Abfrageverarbeitung und Echtzeit-Workloads verwendet. Dieses Unternehmen hat kein eigenes Speichersystem; Vielmehr nutzt es zusätzlich zu seinen eigenen Analysen auf anderen Speichersystemen wie HDFS, Amazon Redshift, Amazon S3, Couchbase und anderen. Wenn es um strukturierte Datenverarbeitung geht, ist Spark SQL nicht nur eine Datenbank; es ist auch ein Modul. Die überwiegende Mehrheit davon ist in DataFrames geschrieben, bei denen es sich um Programmierabstraktionen handelt, die in Verbindung mit SQL-Abfragen arbeiten.
Was ist der SQL-SQL-Typ für „sparksql“? Hive SQL unterstützt die HiveQL-Syntax sowie Hive-SerDes und -UDFs, sodass Sie auf zuvor erstellte Hive-Warehouses zugreifen können. Die Verwendung vorhandener Hive-Metastores, SerDes und UDFs in Spark SQL ist nicht schwierig.
Kann Mongodb Spark ausführen?
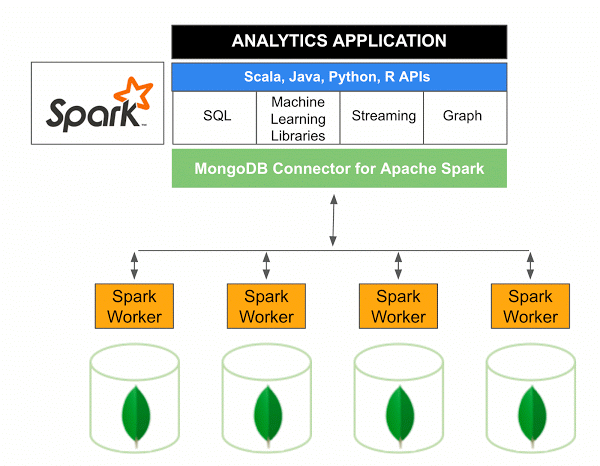
Version 10.0 des MongoDB-Konnektors für Apache Spark enthält Unterstützung für strukturiertes Spark-Streaming über die neue Spark-Datenquellen-API V2 sowie die Implementierung der neuen Spark-Datenquellen-API V2.
Der MongoDB-Konnektor für Spark ist ein Open-Source-Projekt, mit dem Sie Daten aus MongoDB schreiben und mit Scala aus MongoDB lesen können. Aufgrund der Dienstprogrammmethoden der Konnektoren werden die Interaktionen zwischen Spark und MongoDB vereinfacht, was es zu einer leistungsstarken Kombination für die Erstellung anspruchsvoller analytischer Anwendungen macht. Mithilfe der integrierten Replikations- und Sharding-Funktionen kann Spark in einer Vielzahl von Workloads implementiert werden, die MongoDB-Datenbanken verwenden.
Spark: Der schnelle Weg zum Erstellen datenintensiver Anwendungen
Mit Hilfe von Spark, einem leistungsstarken Tool, können Sie schnell funktionalere Anwendungen entwickeln. Durch die Integration von MongoDB können Entwickler den Entwicklungsprozess beschleunigen, indem sie eine einzige Datenbanktechnologie verwenden. Darüber hinaus ist Spark Cloud-nativ und bietet Unterstützung für NoSQL-Datenspeicher , wodurch es sich ideal für datenintensive Anwendungen eignet.