
Kafka: Eine gute Wahl für Message Broker in Microservices
Veröffentlicht: 2022-11-19Kafka ist eine verteilte Streaming-Plattform. Es wird häufig für die Protokollaggregation, Echtzeit-Stream-Verarbeitung und Ereignisbeschaffung verwendet. In letzter Zeit gewinnt Kafka als Message Broker für Microservices an Popularität. Kafka ist keine herkömmliche Nachrichtenwarteschlange wie ActiveMQ oder RabbitMQ. Es gibt keinen zentralen Server, der alle Nachrichten speichert. Stattdessen wird ein Publish-Subscribe-Modell verwendet. Nachrichten werden in Themen gespeichert, und jedes Thema kann mehrere Partitionen haben. Kafka ist hochverfügbar und skalierbar. Es kann Milliarden von Nachrichten pro Tag verarbeiten. Kafka ist auch sehr schnell. Es kann Nachrichten in Echtzeit verarbeiten. Kafka ist eine großartige Wahl für den Aufbau eines Nachrichtenbrokers für Microservices. Es ist hochverfügbar, skalierbar und schnell.
Kafka, ein Echtzeit-Messaging-System, macht dies möglich. Datenströme sind vor Störungen geschützt und können verteilt oder fehlertolerant sein. Der Kafka Data Integration Bus ist ein Datenaustauschprotokoll, das es einer Vielzahl von Produzenten und Verbrauchern ermöglicht, Daten auszutauschen. Die Fähigkeiten von Kafka ähneln denen von MongoDB und RDS, die als Datenpuffer am Ende Ihrer Anwendung dienen.
KSQL, eine SQL-basierte Skriptsprache, wird verwendet, um Echtzeit-Streaming-Daten in Apache Kafka zu analysieren und zu verarbeiten. KSQL enthält ein interaktives Framework für die Stream-Verarbeitung, das es Ihnen ermöglichen soll, Stream-Verarbeitungsaktivitäten wie Datenaggregation, Filterung, Zusammenführung, Sessionisierung, Windowing usw. durchzuführen.
Es ist mehr als nur ein ausgezeichneter Nachrichtenbroker, wie Apache Kafka demonstriert. Die Framework-Implementierung weist eine Reihe von datenbankähnlichen Merkmalen auf, die sie für die Verwendung in einer Datenbank geeignet machen. Infolgedessen dient es jetzt als Aufzeichnung von Geschäftsereignissen, anstatt sich auf relationale Datenbanken zu verlassen.
Die Kafka-Anwendung spart Zeit und Energie, indem sie Daten aus MongoDB auf einfache und effiziente Weise streamt. MongoDB ist für Unternehmen erforderlich, um große Datenmengen an andere Abonnenten zu veröffentlichen und mehrere Datenströme zu verwalten. Der Kafka MongoDB-Verbindungsdienst ermöglicht Entwicklern das Erstellen mehrerer asynchroner Streams mit MongoDB, einem beliebten Branchentool.
In einer Datenbank dient Apache Kafka als Vorlage. Hunderte von Unternehmen nutzen es, um ACID-Garantien bereitzustellen und unternehmenskritische Aufgaben auszuführen. In den meisten Fällen ist Kafka jedoch nicht so konkurrenzfähig wie andere Datenbanken.
Welche Art von Datenbank ist Kafka?

Kafka ist eine Art Datenbank, die zum Speichern und Abrufen von Nachrichten verwendet wird. Es ist ein verteiltes System, das skalierbar und fehlertolerant ist.
Es ist eine in Scala und Java geschriebene Open-Source-Stream-Verarbeitungsplattform, die Teil des Kafka-Projekts der Apache Software Foundation ist. Ein Stream in der Informatik ist eine Sammlung von Informationselementen, die im Laufe der Zeit verfügbar gemacht werden. Streams können als Artikel auf einem Förderband definiert werden, die einzeln verarbeitet werden. Streams können in ihrer einfachsten Form eine Reihe von scheinbar nicht zusammenhängenden Ereignissen sein. Die Konzepte des Event Sourcing unterscheiden sich von den Konzepten des Data Warehousing und der Datenanalyse, an die Entwickler gewöhnt sind. Wie verwende ich Kafka als Datenbank? Blue ist das Unternehmen, das Ja zum Deal sagt.
Laut Team Red machen Programmierer einen großen Fehler, wenn sie von herkömmlichen Datenbanken auf Kafka umsteigen. Die Botschaft von Team Red, Kafka sei für alle, ist laut Martin Kleppmann herablassend. Das Problem, das Team Red mit Kafka und Streams hat, ist, dass sie ein Problem damit haben, dass Entwickler RDMSs wegwerfen. Wenn ein permanentes Ereignisprotokoll präsentiert wird, hat es immer seinen historischen Kontext, wodurch es leicht zu prüfen ist. Die Datenbankverwaltung hat zahlreiche Vorteile, ist aber auch einer ihrer schwierigsten Aspekte. Die herkömmliche Datenbank arbeitet auf zwei völlig unterschiedliche Arten: Sie führt Lese- und Schreibvorgänge zusammen. Für Programmierer ist es entscheidend, die duplizierten Daten über mehrere Tabellen hinweg zu pflegen und zu synchronisieren.
Scale ändert das Muster während Sie gehen. Streams zeichnen sich durch eine klare Unterscheidung zwischen Leser- und Autorenanliegen aus. Es besteht kein Zusammenhang zwischen der Geschwindigkeit, mit der Kafka in eine Datei schreibt, und der Geschwindigkeit, mit der Elastic Search Aktualisierungen an diese senden kann. Infolgedessen verarbeiten Kafka-Benutzer Protokolle, um verschiedene materialisierte Ansichten zu generieren. Damit materialisierte Ansichten als praktischer Caching-Mechanismus funktionieren, sind einige Vorabkosten erforderlich. Materialisierte Ansichten sind neben der Speicherung ihrer eigenen Daten und der Skalierung wichtige Komponenten der Infrastruktur. Für 99 % der Unternehmen sind DBMS die beste Grundlage.
Ihre Anwendung kann in diese Kategorie fallen, und Sie haben möglicherweise Anspruch auf eine neuartige Architektur, die auf Ihrem Hintergrund basiert. Viele wichtige Funktionen gehen verloren, wenn Sie Datenbanken durch Protokolle ersetzen. Zu den Funktionen gehören Fremdschlüsseleinschränkungen, atomare (Alles-oder-Nichts)-Transaktionen und prozedurale Isolationstechniken, die bei Parallelitätsproblemen helfen. Arjun geht davon aus, dass die Integrität Ihrer Anwendung jederzeit gewahrt bleibt. Grundlegende Funktionen, die die meisten Menschen für selbstverständlich halten, werden zu zusätzlichen Aufgaben, wenn Sie an Streams arbeiten. Es ist wichtig, die Absicht von der schriftlichen Erklärung zu trennen. Eine gängige Konfiguration ist die Verwendung von Kafka zusammen mit einem Change Data Capture-System.
Laut Team Red sind die Datenintegritätsfunktionen von Datenbanken entscheidend, um Datenkontrolle zu erreichen. Transaktionen müssen von herkömmlichen Datenbanken isoliert werden, damit sie berücksichtigt werden können. Infolgedessen kann ein einzelnes Schreiben kostspielig sein. Wenn Ihre Anwendung mit dem Volumen teurer Schreibvorgänge zu kämpfen hat, müssen Sie möglicherweise zu einer konventionelleren Datenbank migrieren. Team Red versäumt es zu erwähnen, dass die Verwendung einer Datenbank vor Kafka die besten Funktionen reduziert.
Die Vorteile dieses Designs sind gegenüber herkömmlichen Messaging-Systemen erheblich. Der erste Vorteil von Kafka ist, dass es eine hohe Anzahl von Anfragen verarbeiten kann. Da Daten nur bei Bedarf auf die Festplatte geschrieben werden, kann Kafka außerdem riesige Datenmengen verarbeiten.
SQL Server ist ein Datenbanktool, das in die Kategorie der Tools fällt. Dieses Handheld-Gerät ist vielseitig und zuverlässig, aber es kann manchmal schwierig sein, es zu verwenden. Kafka und Azure sind beide äußerst leistungsfähige Plattformen, aber Kafka wird hochskaliert, während Azure herunterskaliert wird.
SQL Server ist ein ausgezeichnetes Tool für Unternehmen, die große Mengen an Datenspeicher benötigen, aber es ist möglicherweise nicht die beste Wahl für diejenigen, die eine schnelle Skalierung oder einen hohen Durchsatz benötigen. Für Unternehmen, die große Datenmengen ohne Leistungseinbußen verarbeiten müssen, ist Kafka die bessere Wahl als SQL Server.
Kafka: Ein verteiltes Speichersystem für Zeitreihentelemetrie
Ein Kafka Distributed Storage System, das ein themenbasiertes Modell verwendet, speichert Daten. Daten können in einem themenbasierten Modell einer Kafka-Datenbank statt in einer relationalen Datenbank gespeichert werden. Es verhält sich ähnlich wie eine Warteschlange in einem Kafka-Topic , jedoch nicht auf die gleiche Weise wie eine Warteschlange. Es kann eine große Anzahl von Zeitreihen im Kafka-Framework statt in einer Zeitreihendatenbank speichern.
Was ist der Unterschied zwischen Kafka und Mongodb?

Es ist ein verteilter, partitionierter und replizierter Commit-Protokolldienst, der auf einem verteilten System basiert. Trotz seines einzigartigen Designs ist es ein wichtiger Bestandteil eines Messaging-Systems. MongoDB hingegen wird als „Die Datenbank für riesige Ideen“ bezeichnet.
Da Kafka standardmäßig keine Warteschlangen unterstützt, müssen Sie es in eine Verbraucherversion des Systems hacken. Wenn eine relationale Datenbank erforderlich ist, kann ein anderes Tool von größerem Nutzen sein. MongoDB ist aus verschiedenen Gründen eine ausgezeichnete Wahl, einschließlich seiner Benutzerfreundlichkeit und Flexibilität. Die Benutzerunterstützung von Apache ist verfügbar. Confluent hat ein Kafka (wenn bereit zu zahlen), das bei Linkedin zur gleichen Zeit wie das Kafka-Projekt erstellt wurde. Einen Anbieter zu haben, der automatische Sicherungen durchführt und den Cluster automatisch skaliert, ist äußerst praktisch. Wenn Sie keinen Systemadministrator oder DBA haben, der sich mit MongoDB auskennt, empfiehlt es sich, einen Drittanbieter zu beauftragen, der auf MongoDB-Hosting spezialisiert ist.
Kafka soll uns in seiner einfachsten Form das Einreihen von Nachrichten in eine Warteschlange ermöglichen. Die Speicher-Engine von Cassandra gewährleistet ein konstantes Schreiben in Ihre Daten, egal wie groß sie werden. MongoDB bietet eine benutzerdefinierte Map/Reduce-Implementierung sowie native Hadoop-Unterstützung für Analysen, Cassandra hingegen nicht. Dabei spielt es keine Rolle, ob es bei Ihnen oder einem anderen Anbieter gehostet wird, da die Kosten in der Regel angemessen sind.
Kafka vs. Traditionelle Datenbanksysteme
Es ist wichtig zu beachten, dass es einige Unterschiede zwischen Kafka und einem traditionellen Datenbanksystem gibt.
Da Kafka eine Streaming-Plattform ist, kann es eine hohe Datenaufnahme verarbeiten, ohne dass eine erhebliche vorherige Verarbeitung erforderlich ist.
Beim Ausführen von Kafka werden Daten eher von Tail-Lesevorgängen als von Datenträgerlesevorgängen verbraucht.
Die Verwendung von Seiten-Caching reduziert die Notwendigkeit von Round-Trip-Datenbankbesuchen für Kafka.
Um Daten nachgelagert an nachgelagerte Kunden zu senden, verwendet Kafka Pub/Sub-Messaging.
Was ist die Kafka-Datenbank?
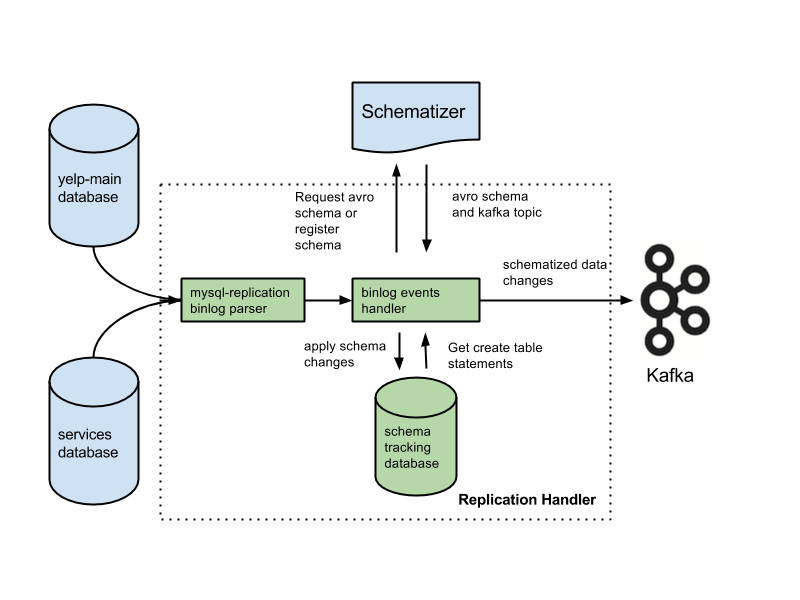
Kafka ist eine Datenbank, die häufig zum Speichern von Streaming-Daten verwendet wird. Es ist ein verteiltes System, das skalierbar und fehlertolerant ist. Kafka wird häufig verwendet, um Echtzeit-Datenpipelines und Streaming-Apps zu erstellen. Es kann einen hohen Durchsatz und eine niedrige Latenz verarbeiten.
Ein Message Broker wie Kafka hat in den letzten Jahren an Popularität gewonnen. Laut Befürwortern ist Kafka ein Paradigmenwechsel in der Datenverwaltung. Es ist wichtig, sich daran zu erinnern, dass die Verwendung von Kafka als primärer Datenspeicher Sie nicht isoliert. Jedes Problem, auf das Datenbanksysteme stoßen, wird in Zukunft gelöst. Hacker können Daten stehlen, indem sie Fehler in autonomen Architekturen ausnutzen. Wenn zwei Benutzer gleichzeitig versuchen, denselben Artikel zu kaufen, werden beide erfolgreich sein, und wir werden für beide keinen Bestand mehr haben. Diese Architekturen, die beim Betrieb von Gaslight-Appliances Zeitreisefunktionen verwenden, stützen sich auf ereignisgesteuerte Architekturen.
Die Verwaltung großer Datenmengen ist eine hervorragende Anwendung von Kafka. Transaktionen sollten weiterhin mit einem herkömmlichen DBMS isoliert werden. Verwenden Sie OLTP-Datenbanken für die Zugangskontrolle, CDC für die Ereignisgenerierung und modellieren Sie nachgelagerte Kopien, wenn Ansichten erscheinen, um Ihre Datenbank auf den Kopf zu stellen.
Kafka kann auch verwendet werden, um große Datenmengen zu speichern und täglich zu verarbeiten. Die Möglichkeit, Big Data im Batch- oder Streaming-Modus zu verarbeiten, ist ein Vorteil gegenüber anderen Methoden. Mit dem Kafka-Prozess können Protokolldateien von mehreren Servern abgerufen und beispielsweise in einer Datenbank oder einem Suchindex gespeichert werden. Außerdem ist eine Streaming-API verfügbar, mit der Daten in Echtzeit verarbeitet werden können.
Kafka vs. SQL
Im Allgemeinen werden Kafka und MySQL in zwei Typen eingeteilt: Nachrichtenwarteschlangen und Datenbankanwendungen. Die meisten Entwickler betrachten Kafka als eine verteilte und skalierbare Lösung mit hohem Durchsatz, während MySQL aufgrund seiner Einfachheit, Leistung und Benutzerfreundlichkeit als am beliebtesten angesehen wird.
Pub-Sub-Messaging auf Kafka ist ein verteiltes, fehlertolerantes System mit hohem Durchsatz, das große Datenmengen verarbeiten kann. MySQL ist die weltweit beliebteste Open-Source-Datenbank, die für den Einsatz in unternehmenskritischen und stark ausgelasteten Produktionssystemen vorgesehen ist. Entwicklungen betrachten Kafka aufgrund seines hohen Durchsatzes, seiner verteilten Architektur und Skalierbarkeit als leistungsfähiger als MySQL; wohingegen SQL, Free und Easy die Hauptgründe sind, warum MySQL-Benutzer es bevorzugen. Ich empfehle PostgreSQL, wenn Sie praktische Erfahrungen mit Datenbankverwaltungssystemen (DBMSs) sammeln möchten. Bei Vital Beats verwenden wir hauptsächlich Postgres, weil es uns ermöglicht, das gewünschte Gleichgewicht zwischen effektiver Datenverwaltung und Sicherung zu erreichen und gleichzeitig die Befehlszeile zu unterstützen. Wenn Sie vorhaben, Ihre Datenbank lokal oder in der Cloud zu hosten, sind PaaS-Datenbanken (Platform as a Service) die erste Anlaufstelle. Da MongoDB Daten auf derselben Ebene wie ein Dokument schreibt, ist die Konsistenz ohne Transaktionen schwierig.
Dokumentspeicher, wie sie in Amazon DynamoDB und AWS RedShift zu finden sind, unterscheiden sich stark von Schlüssel-Wert-Paaren (oder Spaltenspeichern) in MongoDB. Abfragen mit der #Nosql-Datenbank sind schneller und einfacher, da die Entwicklungszeit verkürzt wird. Als Berufsanfänger in der Immobilienbranche möchte ich eine Datenbank auswählen, die auf Dauer hochproduktiv sein wird. Wenn Sie Aurora Postgres auf AWS mit einer Bereitstellung in einer einzigen Region ausführen, ist dies eine der besten Plattformen, die ich empfehle. Wenn Sie PostgreSQL in drei Cloud-Umgebungen verwenden, werden Sie eine bessere multiregionale Replikation erleben. Wenn Sie sie richtig konfigurieren, wird jede dieser drei Datenbanken langfristig effizient, skalierbar und zuverlässig arbeiten. Uber wechselte aus verschiedenen Gründen von Postgres zu MySql, einschließlich der Notwendigkeit eines agileren und zuverlässigeren Datenübertragungssystems.
Der Chief Technology Officer von OPS Platform erklärte, dass Postgres aufgrund seiner Geschwindigkeit und Benutzerfreundlichkeit die langfristig effektivste Wahl für sein Produkt sei. Im Vergleich zu MySQL 7.x werden Transaktionen in MySQL 8.0 schneller verarbeitet. Ist eine Datenbank sicherer? Ist es möglich, den Verschlüsselungsschlüssel willkürlich zu ändern? MySQL und MongoDB sind die beiden beliebtesten Open-Source-Datenbanken. Neben der Leichtigkeit, mit der Daten gespeichert werden können, kann MongoDB auch zum Speichern großer Mengen eingehender Daten über das Content Distribution Network (CDN) verwendet werden. Der Hauptvorteil von Postgres gegenüber anderen objektrelationalen Datenbanken ist die Betonung auf Erweiterbarkeit und Einhaltung von Standards.
Es können reguläre B-Baum- und Hash-Indizes sowie Ausdrucks- und Teilindizes (die nur einen Teil der Tabelle betreffen) erstellt werden. Der grundlegendste Unterschied zwischen Redis und Kafka ist die Verwendung von Enterprise-Messaging-Frameworks. Ich suche nach einer Technologie, die Cloud-nativ ist, wenn ich mich für eine entscheide. Zusätzlich zur Diensterkennung kann NATS verwendet werden, um Lastenausgleich, globale Multicluster und andere Operationen zu ersetzen. Das einzige, was Redis nicht tut, ist, als reiner Nachrichtenbroker zu dienen (zum Zeitpunkt des Schreibens). Infolgedessen handelt es sich eher um einen allgemeinen In-Memory-Key-Value-Store. Obwohl ich über eine umfangreiche Musikbibliothek verfüge, sind meine Songs häufig länger als zwei Stunden.

Das Problem beim mehrstündigen Speichern von Audiodateien in einer Datenbankzeile besteht darin, dass sie nicht leicht durchsuchbar sind. Wenn Sie es vorziehen, sollten Sie Audiodateien in einem Cloud-Speicherdienst wie Backblaze b2 oder AWS S3 speichern. Gibt es eine Lösung, die MQTT Broker auf IoT World verwendet? Es ist in einem der Rechenzentren untergebracht. Wir verarbeiten sie derzeit für Warn- und Alarmzwecke. Unser Hauptziel ist es, leichtere Produkte zu verwenden, die die Betriebskomplexität und Wartungskosten reduzieren. Es wäre ideal, wenn wir Apache Kafka mit diesen zusätzlichen API-Aufrufen von Drittanbietern integrieren könnten.
Die RabbitMQ-App ist eine ausgezeichnete Wahl für Wiederholungsversuche und Warteschlangen. Wenn nicht jede Nachricht von mehr als einem Benutzer verarbeitet werden muss, können Sie RabbitMQ verwenden. Es ist nicht sinnvoll, Kafka zu verwenden, um das System mit Bestätigungen auszuliefern. Der Kafka-Event-State-Manager ermöglicht es Ihnen, wie ein persistenter Event-State-Manager, verschiedene Datenquellen mithilfe einer Stream-API zu transformieren und abzufragen. Das RabbitMQ-Framework ist ideal für einen Eins-zu-Eins-Publisher oder -Abonnenten (oder -Verbraucher), und ich glaube, dass ein Fanout-Austausch so konfiguriert werden kann, dass mehrere Verbraucher aktiviert werden. Das Pushnami-Projekt demonstriert, wie Live-Daten von einer Datenbank in eine andere migriert werden. Da jedes Frontend (Angular), Backend (Node.js) und Frontend (MongoDB) nativ ist, war der Datenaustausch viel einfacher.
Um die Übersetzungsebene zu vermeiden, habe ich den relationalen zu hierarchischen Teil übersprungen. Es ist wichtig, eine endliche Größe in MongoDB-Objekten beizubehalten und korrekte Indizes zu verwenden. Bereits in den 1960er Jahren verwendeten einige der frühesten elektronischen Krankenakten (EMRs) MUMPS, eine dokumentenorientierte Datenbank. MongoDB, das bis zu 40 % aller Krankenhausakten speichert, gilt als robuste medizinische Datenbank. Es gibt jedoch einige sehr clevere Methoden, um nicht nativ unterstützte Geo-Abfragen durchzuführen, die auf lange Sicht extrem langsam sind. Amazon Kinesis verarbeitet Hunderttausende von Datendateien pro Sekunde aus Hunderttausenden von Quellen. RabbitMQ macht es Ihnen einfach, Nachrichten von jeder App zu senden und zu empfangen. Apache ActiveMQ ist schnell, unterstützt eine breite Palette sprachübergreifender Clients und ist eine robuste Skriptsprache. Hadoop-Daten werden mit einer schnellen und universellen Verarbeitungs-Engine namens Spark verarbeitet.
Kafka gegen Mongodb
Mongodb ist eine leistungsstarke dokumentenorientierte Datenbank mit vielen Funktionen, die sie zu einer guten Wahl für eine Vielzahl von Anwendungen machen. Kafka ist eine leistungsstarke Streaming-Plattform, mit der Echtzeit-Datenpipelines und Streaming-Anwendungen erstellt werden können.
Übertragungen von MongoDB als Quelle zu anderen MongoDB-Quellen oder anderen MongoDB-Quellen können mit der Kafka-zu-MongoDB-Anwendung nahtlos erfolgen. Mit Hilfe von MongoDB Kafka Connector lernen Sie, wie Sie Daten effizient übertragen. Mit dieser Funktion können Sie eine völlig neue ETL-Pipeline für Ihr Unternehmen erstellen. Confluent bietet eine Vielzahl von Konnektoren, die als Quelle und Senke fungieren und es Benutzern ermöglichen, Daten zwischen beiden zu übertragen. Die Debezium MongoDB-Konnektoren sind ein solcher Konnektivitätsmechanismus, mit dem Benutzer von Kafka MongoDB eine Verbindung zur MongoDB-Datenbank herstellen können. Bevor Sie Confluent Kafka starten können, müssen Sie zunächst sicherstellen, dass es auf Ihrem System läuft. Durch die Verwendung von Funktionalitäten wie KStream, KSQL oder anderen Tools wie Spark Streaming können Sie Daten in Kafka analysieren.
Die Dateneingabe in das Warehouse erfordert manuelle Skripte sowie benutzerdefinierten Code. Mit der No-Code-Datenpipeline-Plattform von Hevo können Sie einfache Datenpipeline-Systeme ohne Codierung erstellen. Die transparente Preisplattform von Hevo ermöglicht es Ihnen, jedes Detail Ihrer ELT-Ausgaben in Echtzeit zu sehen. Die Testphase dauert 14 Tage und beinhaltet einen 24×7-Support. Die Ende-zu-Ende-Verschlüsselung erfolgt unter Verwendung der strengsten Sicherheitszertifizierungen. Mit Hevo können Sie Ihre Kafka- und MongoDB-Daten sicher an 150 verschiedene Datenquellen (darunter 40 kostenlose Quellen) übertragen.
Was ist Kafka und Mongodb?
Der MongoDB-Kafka-Konnektor ist ein von Confluent verifizierter Konnektor, der Daten aus Kafka-Themen als Datensenke in MongoDB speichert und Änderungen an diesen Themen als Datenquelle veröffentlicht.
Die Vor- und Nachteile der Verwendung von Kafka als Datenbank
Welche Datenbank ist gut für Kafka? Prinzipiell kann Kafka zum Erstellen einer Datenbank verwendet werden. Das Ergebnis wird eine Untersuchung aller größeren Probleme sein, die Datenbankverwaltungssysteme seit Jahrzehnten plagen. Ein Datenbankmanagementsystem (DBMS) ist eine Art von Software, die Daten organisiert und abfragt. Sie werden für umfangreiche Anwendungen und zum Speichern von Daten benötigt, auf die mehrere Benutzer zugreifen müssen. Ein DBMS wird in zwei Typen eingeteilt: relational und nicht-relational. Das relationale Modell ist eine Standardmethode zur Darstellung von Informationen in einem relationalen DBMS. Sie sind beliebt, weil sie einfach zu verwenden sind und zum Speichern von Daten verwendet werden können, die in Tabellen organisiert sind. Ein DBMS, das keine benutzerbezogenen Modelle verwendet, ist nicht so leistungsfähig wie eines, das andere Modelle verwendet. Die Daten werden auch in anderen Formaten als Tabellen gespeichert, um sie effizienter zu organisieren, z. B. als Datenströme. Das Kafka-Modell wird verwendet, um eine Datenbank zu erstellen, die für eine Vielzahl von Zwecken verwendet werden kann. Die Stream-Verarbeitung ist das Herzstück von Kafka, einem neuen Datendarstellungsmodell. Datenmanagementsysteme (DMS) sind ein wesentlicher Bestandteil des Datenmanagements. Die Verwendung von Kafka als Datenbank kann jedoch manchmal schwierig sein. Einige der häufigsten Probleme, auf die DBMS stoßen, sind Leistung, Skalierbarkeit und Zuverlässigkeit. George Fraser, CEO von Fivetran, und Arjun Narayan, CEO von Materialise, haben den Beitrag gemeinsam verfasst.
Kafka-Persistenzdatenbank
Kafka-Persistenzdatenbanken bieten eine Möglichkeit, Daten hochverfügbar und skalierbar in einem Kafka-Cluster zu speichern. Standardmäßig verwendet Kafka zum Speichern von Daten eine In-Memory-Datenbank, die jedoch nicht für Produktionsbereitstellungen geeignet ist. Eine Kafka-Persistenzdatenbank kann verwendet werden, um eine zuverlässigere Speicheroption für Kafka-Daten bereitzustellen.
LinkedIn hat 2011 das Open-Source-Apache kaffef entwickelt. Diese Plattform ermöglicht die Einspeisung von Echtzeitdaten mit extrem geringer Latenz und Durchsatz. In den meisten Fällen können Daten über Kafka Connect aus externen Systemen importiert und exportiert werden. Neue Lösungen können bei Problemen wie ineffizienter Speicherleistung und Unterauslastung von Laufwerken helfen. Trotz der Herausforderungen der Architektur ist lokaler Flash eine ausgezeichnete Wahl für Kafka-Systeme. Da auf jedes Thema in Kakfa nur auf einem Laufwerk zugegriffen werden kann, wird die Unterauslastung zunehmen. Die Synchronisierung kann auch schwierig sein, was zu Kosten- und Effizienzproblemen führt.
Wenn eine SSD ausfällt, müssen die Daten von ihr vollständig neu erstellt werden. Dieses zeitaufwändige Verfahren verringert die Clusterleistung. Kafka eignet sich am besten für NVMe/TCP-basierte Speicher, da es den Kompromiss zwischen Zuverlässigkeit und Leistung glättet.
Kafka ist ein fantastisches Messaging-System, aber keine perfekte Lösung zum Speichern von Daten
Kafka ist ein ausgezeichnetes Nachrichtensystem, das zum Speichern von Daten verwendet werden kann. Eine der Aufbewahrungsoptionen von Kafka ist eine Aufbewahrungszeit von -1, was sich auf eine lebenslange Aufbewahrung bezieht. Die Zuverlässigkeit von Kafka bleibt jedoch weit hinter der einer traditionellen Datenbank zurück. Es ist wichtig zu beachten, dass Kafka Daten auf Festplatte, Prüfsumme und Replikation für Fehlertoleranz speichert, sodass das Ansammeln von mehr gespeicherten Daten es nicht verlangsamt. Kafka kann zum Senden und Empfangen von Nachrichten verwendet werden, ist jedoch nicht die beste Wahl zum Speichern von Daten.
Was ist Kafka
Kafka ist ein schnelles, skalierbares, dauerhaftes und fehlertolerantes Publish-Subscribe-Messaging-System. Kafka wird in der Produktion von Unternehmen wie LinkedIn, Twitter, Netflix und Airbnb verwendet.
Kafka hat ein einfaches und geradliniges Design. Es ist ein verteiltes System, das auf einem Cluster von Maschinen läuft und horizontal skaliert werden kann. Kafka ist für hohen Durchsatz und geringe Latenz ausgelegt.
Kafka wird zum Erstellen von Echtzeit-Streaming-Datenpipelines und -anwendungen verwendet. Es kann verwendet werden, um Daten in Echtzeit zu verarbeiten und zu aggregieren. Kafka kann auch für die Ereignisverarbeitung, Protokollierung und Prüfung verwendet werden.
LinkedIn hat Kafka im Jahr 2011 eingeführt, um Daten-Feeds in Echtzeit zu verarbeiten. Kafka wird heute von über 80 % der Fortune 100 verwendet. Eine Kafka-Streams-API ist eine leistungsstarke, leichtgewichtige Bibliothek, die für die On-the-Fly-Verarbeitung ausgelegt ist. Zusätzlich zu den beliebten verteilten Datenbanken enthält Kafka eine Abstraktion eines verteilten Commit-Protokolls. Im Gegensatz zu Messaging-Warteschlangen ist Kafka ein äußerst anpassungsfähiges, fehlertolerantes verteiltes System mit hoher Skalierbarkeit. Beispielsweise könnte es zur Verwaltung der Fahrgast- und Fahrerzuordnung bei Uber oder zur Bereitstellung von Echtzeitanalysen bei British Gas verwendet werden. Viele Microservices setzen auf Kafka. Der Cloud-native, vollständige und vollständig verwaltete Service von Confluent ist dem von Kafka überlegen. Confluent macht es einfach, eine völlig neue Kategorie moderner, ereignisgesteuerter Anwendungen aufzubauen, indem historische und Echtzeitdaten zu einer einheitlichen Quelle der Wahrheit kombiniert werden.
Mit Hilfe von Kinesis können Sie eine Vielzahl von Datenströmen verarbeiten, was es zu einer leistungsstarken und vielseitigen Stream-Verarbeitungsplattform macht. Es ist aufgrund seiner Geschwindigkeit, Einfachheit und Kompatibilität mit einer Vielzahl von Geräten eine beliebte Plattform. Aufgrund seiner Zuverlässigkeit ist es eine der beliebtesten Streaming-Plattformen. Aufgrund seiner Langlebigkeit kann es ein hohes Datenvolumen ohne Probleme verarbeiten. Da es sich um eine bekannte Plattform handelt, die weit verbreitet ist und unterstützt wird, ist es außerdem einfach, einen Partner oder Integrator zu finden, der Ihnen beim Einstieg hilft. Wenn Sie nach einer leistungsstarken und zuverlässigen Streaming-Plattform suchen, ist Kinesis eine ausgezeichnete Wahl.
Kafka: Das Messaging-System, das Datenbanken ersetzt
Echtzeit-Datenflüsse können mithilfe von Kafka, einem Messaging-System zum Erstellen von Echtzeit-Streaming-Datenpipelines und -anwendungen, an die sich ändernde Datenumgebung angepasst werden. Big Data wird durch Echtzeit-Ereignisströme mithilfe von Kafka verarbeitet, das in Scala und Java geschrieben ist. Eine Kafka-Verbindung kann von einem Punkt zum anderen erweitert und auch zum Senden von Daten zwischen Quellen verwendet werden. Die Event-Streaming-Plattform soll Live-Streaming von Events ermöglichen. Es ist unfair, Datenbanken mit Messaging-Lösungen wie Kafka zu vergleichen. Aufgrund der Funktionen in Kafka sind keine Datenbanken mehr erforderlich.
Kafka ist keine Datenbank
Kafka ist keine Datenbank, wird aber oft in Verbindung mit einer verwendet. Es ist ein Nachrichtenbroker, der verwendet werden kann, um Nachrichten zwischen verschiedenen Komponenten eines Systems zu senden. Es wird häufig verwendet, um verschiedene Teile eines Systems zu entkoppeln, damit sie unabhängig voneinander skaliert werden können.
Es ist möglich, Apache Kafka durch eine Datenbank zu ersetzen, aber tun Sie dies der Einfachheit halber nicht. Die Top-Gear-Folge, in der die Protagonisten jeweils 10.000 Dollar für den Kauf eines gebrauchten italienischen Supersportwagens mit Mittelmotor erhielten, erinnerte mich an eine alte Top-Gear-Folge, in der die Protagonisten jeweils 10.000 Dollar bekamen. Im Jahr 2011 veröffentlichte LinkedIn Kafka, und diese Folge wurde im selben Jahr ausgestrahlt. Es ermöglicht Ihnen, das Nötigste an dauerhaftem Messaging zu tun, ohne in eine Messaging-Plattform mit vollem Funktionsumfang zu investieren. Die grundlegende Prämisse ist, dass es eine Grundregel gibt. Erstellen Sie eine Tabelle (oder Bucket, Collection, Index, was auch immer) für jedes Ereignis, das während des Producer-Prozesses aufgezeichnet wurde. Rufen Sie die Datenbank regelmäßig von einer Verbraucherinstanz ab und aktualisieren Sie den Status des Verbrauchers, während er verarbeitet wird.
Damit das Modell richtig funktioniert, sollten Produzenten und Konsumenten gleichzeitig arbeiten können. Erwägen Sie, Kafkas Buch als Leitfaden zu verwenden und Aufzeichnungen auf unbestimmte Zeit zu speichern, anstatt sie einfach zu lesen. Auf der anderen Seite könnten disjunkte Verbrauchergruppen implementiert werden, indem Datensätze beim Einfügen dupliziert und dann Datensätze nach dem Verbrauch gelöscht werden. Kafka verwendet persistente Offsets, um sein benutzerdefiniertes Datenauffächern zu ermöglichen und mehrere disjunkte Verbraucher zu unterstützen. Um diese Funktionalität einzustellen, müssen Sie einen Dienst von Grund auf neu entwickeln. Es ist nicht schwierig, das Konzept der zeitbasierten Bereinigung zu implementieren, aber es ist notwendig, die Logik der Scavenger zu hosten. Auf Kafka gibt es feinkörnige Kontrollen über alle Akteure (Konsumenten, Produzenten und Administratoren).
Es kann problemlos Millionen von Datensätzen pro Sekunde auf Commodity- und Cloud-Servern verarbeiten. Kafka ist für hohen Durchsatz sowohl auf Produzenten- als auch auf Verbraucherseite im nichtfunktionalen Sinne optimiert. Bei Verwendung von Kafka handelt es sich um ein verteiltes Nur-Anhänge-Protokoll, das auf diesem Gebiet konkurrenzlos ist. Im Gegensatz zu herkömmlichen Message Brokern, die Nachrichten in der Konsumphase entfernen, löscht Kafka Nachrichten nicht, nachdem sie konsumiert wurden. Der Durchsatz und die Latenz einer Datenbank müssen mit ziemlicher Sicherheit durch den Einsatz spezialisierter Hardware und hochgradig gezielter Leistungsoptimierung erheblich verbessert werden. Der Verzicht auf einen Makler mag auf den ersten Blick reizvoll sein. Wenn Sie eine Streaming-Event-Plattform wie Kafka nutzen, profitieren Sie von dem enormen technischen Aufwand, der in deren Aufbau geflossen ist.
Um sicherzustellen, dass die Lösung, für die Sie sich heute entscheiden, gewartet werden kann, müssen Sie sicher sein, dass sie auf einem hohen Standard gewartet werden kann. Die meisten Funktionen in einem Ereignisspeicher können nur durch die Verwendung einer Datenbank implementiert werden. Es gibt keinen One-Size-Fits-All-Event-Store; jeder nichttriviale Ereignisspeicher ist in den meisten Fällen mit ziemlicher Sicherheit eine maßgeschneiderte Implementierung, die von einer oder mehreren Standarddatenbanken unterstützt wird. Sie können Datenbanken im Bereich der Datenorganisation für einen effizienten Abruf verwenden, aber Sie sollten sie nicht verwenden, um Daten in (nahezu) Echtzeit zu verteilen.