
MapReduce: Ein Programmiermodell für große Datensätze
Veröffentlicht: 2023-01-08MapReduce ist ein Programmiermodell und eine zugehörige Implementierung zur Verarbeitung und Generierung großer Datensätze mit einem parallelen, verteilten Algorithmus auf einem Cluster.
Wir verändern die Art und Weise, wie wir mit riesigen Datenmengen arbeiten, mithilfe neuer Technologien. Data Warehouses wie Hadoop, NoSQL und Spark gehören zu den bekanntesten Akteuren auf diesem Gebiet. DBAs und Infrastrukturingenieure/-entwickler gehören zu der neuen Generation von Fachleuten, die sich auf die Verwaltung von Systemen mit einem hohen Maß an Komplexität spezialisiert haben. Anstelle einer Datenbank ist Hadoop ein Software-Ökosystem, das paralleles Rechnen in Form von riesigen Dateien ermöglicht. Diese Technologie hat erhebliche Vorteile in Bezug auf die Unterstützung der massiven Verarbeitungsanforderungen von Big Data gebracht. Bei einer großen Datentransaktion benötigt der durchschnittliche Hadoop-Cluster möglicherweise nur drei Minuten, um eine große Transaktion zu verarbeiten, die in einem zentralisierten relationalen Datenbanksystem normalerweise 20 Stunden dauern würde.
Ein MapReduce-Cluster ist ein Cluster mit einem parallelen Algorithmus und einem Programmiermodell, das große Datenmengen auf die gleiche Weise verarbeitet und generiert wie ein normaler Cluster.
Das Apache Hadoop-Ökosystem wurde entwickelt, um verteiltes Computing zu unterstützen, und bietet eine zuverlässige, skalierbare und einsatzbereite Umgebung. Das MapReduce-Modul dieses Projekts ist ein Programmiermodell, das verwendet wird, um riesige Datensätze zu verarbeiten, die sich auf Hadoop (einem verteilten Dateisystem) befinden.
Dieses Modul ist eine Komponente des Open-Source-Ökosystems Apache Hadoop und dient zum Abfragen und Auswählen von Daten im Hadoop Distributed File System (HDFS). Daten können für eine Vielzahl von Abfragen unter Verwendung eines MapReduce-Algorithmus ausgewählt werden, der zum Zweck der Durchführung solcher Auswahlen verfügbar ist.
Mit MapReduce ist es möglich, große Datenverarbeitungsaufgaben auszuführen. Sie können MapReduce-Programme in jeder Programmiersprache erstellen, einschließlich C, Ruby, Java, Python und anderen. Diese Programme können gleichzeitig verwendet werden, um MapReduce-Programme auszuführen, was sie sehr nützlich für die Analyse umfangreicher Daten macht.
Wofür wird Mapreduce in Mongodb verwendet?
Karten in MongoDB sind ein Programmiermodell für die Datenverarbeitung, das es Benutzern ermöglicht, große Datensätze auszuführen und daraus aggregierte Ergebnisse zu generieren. MapReduce ist die von MongoDB verwendete Methode zum Reduzieren von Karten. Diese Funktion ist in zwei Komponenten unterteilt: eine Abbildungsfunktion und eine Reduktionsfunktion.
Mit dem MapReduce-Tool von MongoDB ist es möglich, große Datensätze zu organisieren und zu aggregieren. Dieser Befehl in MongoDB nutzt die beiden primären Eingaben in MongoDB: Map-Funktion und Reduce-Funktion, um eine große Datenmenge zu verarbeiten. Führen Sie zum Definieren von Beispielen die folgenden Schritte aus. Wir definieren die Map-Funktion, die Reduce-Funktion und die Beispiele.
MapReduce vergleicht Zeichenfolgen, um die Ausgabe mithilfe der Standardsortiermethode zu sortieren, unabhängig davon, ob Sie die Standardmethode verwenden oder nicht. Um die Art und Weise zu ändern, wie Daten sortiert werden, müssen Sie zuerst einen Sortieralgorithmus erstellen und ihn dann mit der Mapper-Klasse implementieren.
SpiderMonkey ist eine weit verbreitete JavaScript-Engine. Es ist gut für kleine Anwendungen, hat aber einige Einschränkungen. SpiderMonkey hat zum Beispiel keinen Sortieralgorithmus. Wenn Sie also Mapmapper zum Sortieren der Daten verwenden möchten, müssen Sie zunächst Ihren eigenen Sortieralgorithmus erstellen und ihn in der Reduce-Klasse implementieren.
Trotz seiner Popularität verwendet SpiderMonkey keinen Sortieralgorithmus. Es gibt andere Einschränkungen für SpiderMonkey, aber diese ist bemerkenswert. SpiderMonkey hat zum Beispiel keinen guten Garbage Collector. Wenn Ihr Programm also langsamer wird, müssen Sie möglicherweise einige Maßnahmen ergreifen, um es schneller zu machen.
Warum eine MapReduce-Funktion verwenden?
Eine MapReduce-Funktion kann in einer Vielzahl von Situationen nützlich sein. Diese Methode kann in einigen Fällen für die Batch-Datenverarbeitung verwendet werden. Es ist auch nützlich, wenn Sie eine große Datenmenge benötigen, die von einer einzelnen Anwendung oder einem einzelnen Prozess verarbeitet werden soll. Eine MapReduce-Funktion kann auch verwendet werden, um Daten zu verarbeiten, die über mehrere Knoten in einem verteilten System verteilt sind. Durch die Verwendung der MapReduce-Funktion können Daten von den Knoten in einer einzigen Ausgabe kombiniert werden. Eine MapReduce-Anwendung wird normalerweise verwendet, um große Datenmengen zu verarbeiten, obwohl es erforderlich sein kann, sehr große Mengen zu verarbeiten.
Warum heißt es Mapreduce?
Es gibt einige Theorien darüber, warum es MapReduce heißt. Einer davon ist, dass es sich um ein Wortspiel handelt, da Map-Reduce-Algorithmen darin bestehen, ein Problem in kleinere Teile zu zerlegen (Mapping), diese Teile dann zu lösen und sie wieder zusammenzusetzen (Reduzieren). Eine andere Theorie besagt, dass es sich um einen Verweis auf ein Papier handelt, das 2004 von Google-Mitarbeitern mit dem Titel „MapReduce: Simplified Data Processing on Large Clusters“ geschrieben wurde. In der Veröffentlichung verwenden die Autoren die Begriffe „Map“ und „Reduce“, um die beiden Hauptphasen ihres vorgeschlagenen Verarbeitungsmodells zu beschreiben.
Es ist jedoch wichtig zu beachten, dass das MapReduce-Modell nur begrenzt verwendet wird. Es ist nicht für große Datenmengen geeignet und muss parallelisiert werden, um ordnungsgemäß zu funktionieren. Wenn es darum geht, diese Probleme anzugehen, bietet Apache Spark eine leistungsstarke Alternative zu MapReduce. Das Spark-Cluster-Computing-System basiert auf Hadoop und arbeitet als Allzweck-Computing-Plattform. Dieses Tool kann verwendet werden, um traditionelle Datenanalyseaufgaben wie Data Mining und maschinelles Lernen sowie komplexere Datenverarbeitungsaufgaben wie Data Warehousing und Big Data-Analyse zu beschleunigen. Diese Software wurde mit Erlang erstellt, einer Programmiersprache, die sowohl skalierbar als auch fehlertolerant ist. Es kann große Datenmengen verarbeiten und auf mehreren Computern gleichzeitig ausgeführt werden. Darüber hinaus verwendet Spark Parallelität, sodass mehrere Knoten dieselbe Aufgabe gleichzeitig ausführen können. Insgesamt hat es das Potenzial, umfangreiche Datenanalyseaufgaben zu automatisieren und skalierbarer zu machen. Wenn Sie Ihre Verarbeitung parallelisieren und große Datenmengen verarbeiten müssen, ist es eine hervorragende Alternative zu MapReduce.
Was ist der Unterschied zwischen Mapreduce und Aggregation?
Bei der Arbeit mit Big Data ist mapreduce eine wichtige Methode, um Daten aus einer großen Datenmenge zu extrahieren. MongoDB 2.2 enthält ab sofort das neue Aggregation Framework. In Bezug auf die Funktionalität ist Aggregation ähnlich wie mapreduce, aber auf dem Papier scheint es schneller zu sein.
In diesem Szenario werden MongoDB Aggregation und MapReduce auf Docker-Containern in einem Sharded-Setup ausgeführt. Die Leistung der Aggregator-Pipeline ist der von mapreduce überlegen, da sie eine schnellere und einfachere Navigation ermöglicht. So funktioniert das Problem: Tweet zählt schwedische Pronomen wie „den“, „denne“, „denna“, „det“, „han“, „hon“ und „hen“ (Groß-/Kleinschreibung beachten) in einem Twitter-Hashtag. Wie viele Twitter-Handles hat ein Benutzer? Über 4 Millionen Tweets wurden verschickt. In diesem Experiment erstellen wir zunächst eine MongoDB-Datenbank und aktivieren Sharding. Die Twitter-Streams wurden in die Datenbank importiert und Abfragen mit MapReduce und Aggregation Pipeline ausgeführt.
Mapreduce: Das ultimative Datenaggregationstool
Ein mapReduce-Programm liest eine Liste von Dokumenten aus einer Sammlung und verarbeitet sie mithilfe einer Reihe vordefinierter Funktionen. Die mapReduce-Operation generiert einen Strom von verarbeitungsbereiten Dokumenten, die in der Reduzierungsphase verarbeitet werden. Es ist möglich, MapsReduce und Aggregation in einer Vielzahl von Situationen zu kombinieren. Der Aggregationsoperator $group ist ein Tool, mit dem Dokumente in einem einzelnen Feld gruppiert werden können. Wenn mehrere Dokumente mit dem Aggregationsoperator $merge zusammengeführt werden, kann ein neues Dokument erstellt werden. Der Aggregationsoperator $accumulator kann verwendet werden, um die Ergebnisse mehrerer Map-Reduce-Operationen in einem einzigen Dokument darzustellen.
Mapreduzierung in Mongodb
Mongodb mapreduce ist eine Datenverarbeitungstechnologie für große Datensätze. Es ist ein leistungsstarkes Tool zur Analyse von Daten und bietet eine Möglichkeit, Daten parallel und verteilt zu verarbeiten und zu aggregieren. MapReduce wurde ausgiebig für die Datenanalyse in einer Vielzahl von Bereichen verwendet, einschließlich Web-Traffic-Analyse, Protokollanalyse und Analyse sozialer Netzwerke.
Wenn Sie den Befehl mapReduce verwenden , können Sie Map-Reduce-Aggregationsvorgänge für eine Sammlung ausführen. Die Kartenfunktion kann jedes Dokument in Null oder viele andere konvertieren. In MongoDB-Versionen von 4.2 bis früher kann jede Ausgabe nur die Hälfte der maximalen BSON-Dokumentgröße enthalten. Der veraltete JavaScript-Code vom Typ BSON, der in MapReduce verwendet wird, wird nicht mehr unterstützt, und der Code kann nicht mehr für seine Funktionen verwendet werden. MongoDB 4.4 enthält jetzt nicht mehr den veralteten JavaScript-Code vom Typ BSON mit Gültigkeitsbereich (BSON-Typ 15). Der Bereichsparameter gibt an, auf welche Variablen von der Reduce-Funktion zugegriffen werden darf. Um die Eingaben zu reduzieren, begrenzt MongoDB die BSON-Dokumentgröße auf die Hälfte der maximalen Größe.

Große Dokumente, die an den Server zurückgegeben werden, können zurückgegeben und dann in nachfolgenden Reduzierungen zusammengeführt werden, was möglicherweise gegen die Anforderung verstößt. MongoDB 4.2 ist die neueste Version. Diese Option kann verwendet werden, um eine neue Sharding-Sammlung zu erstellen, sowie Map-Reduce, um eine neue Sammlung mit demselben Sammlungsnamen zu erstellen. Die Finalize-Funktion erhält als Argumente einen Schlüsselwert und den reduzierten Wert von der Reduce-Funktion. Es gibt drei Optionen zum Konfigurieren des out-Parameters. Diese Option funktioniert zusätzlich zum Erstellen einer neuen Sammlung nicht für sekundäre Mitglieder von Replikatgruppen. NonAtomic: Die Option false kann nur angegeben werden, wenn die zu übergebende Sammlung bereits vorhanden ist und die explizite Spezifikation hat.
Die Verwendung der Reduzierungsfunktion sowohl für das neue als auch für das vorhandene Dokument führt dazu, dass der Schlüssel des neuen Dokuments derselbe ist wie der Schlüssel des vorhandenen Dokuments. Eine Zuordnungsreduzierung funktioniert nicht, wenn der Sammlungsname eine vorhandene ungehärtete Sammlung ist, die eingerichtet wurde. In diesem Fall wird MongoDB daran gehindert, seine Datenbank zu sperren, wenn nonAtomic wahr ist. Nur sekundäre Mitglieder von Replikatgruppen, die diese Option verwenden, können aus der Gruppe entfernt werden. Es sind keine benutzerdefinierten Funktionen erforderlich, um die Map-Reduce-Operation neu zu schreiben. Die cust_id wird verwendet, um das Wertfeld der $group-Stufengruppe durch die cust_id-Methode zu berechnen. Die $merge-Phase kombiniert die Ergebnisse der $merge-Phase mithilfe der verfügbaren Aggregationspipeline-Operatoren in der Ausgabesammlung.
Beispielsweise kann die $out-Stage verwendet werden, um die Ausgabe der Sammlung agg_alternative_1 zu schreiben. Jedes Eingabedokument kann mit der Kartenfunktion verarbeitet werden. Jedem Artikel in der Bestellung wird ein neuer Objektwert zugeordnet, der sowohl die Anzahl von 1 als auch die Artikelmenge in der Bestellung enthält. In ReducedVal stellt das Zählfeld die Summe der Zählfelder dar, die von den Array-Elementen generiert werden. Wenn die Finalize-Funktion das ReducedVal-Objekt so modifiziert, dass es ein berechnetes Feld namens avg enthält, wird das modifizierte Objekt an den Benutzer zurückgegeben. Die $unwind-Stufe zerlegt das Dokument mithilfe des Array-Felds items in ein Dokument für jedes Array-Element. Die Phase $project formt das Ausgabedokument um, um die Ausgabe von mapreduce zu spiegeln, indem zwei Felder -id und value eingefügt werden.
Es wird das vorhandene Dokument überschrieben, wenn es kein vorhandenes Dokument mit demselben Schlüssel wie das neue Ergebnis gibt. Wenn Sie den out-Parameter angeben, gibt mapReduce ein Dokument als Ausgabe im folgenden Format zurück, wenn Sie Ergebnisse in eine Sammlung schreiben möchten. Ein Array der resultierenden Dokumente wird zurückgegeben, wenn die Ausgabe inline geschrieben wird. Jedes Dokument enthält zwei Felder: den Namen des Quelldokuments und den Namen des Empfängerdokuments. Wenn der Schlüsselwert in das Feld -id eingegeben wird, wird ein Wertfeld zum Reduzieren oder Fertigstellen von Werten für den Schlüssel erstellt.
Was ist Emit in Mongodb?
Als Zuordnungsfunktion kann die Zuordnungsfunktion jederzeit Emits (Schlüssel, Wert) aufrufen, um ein Ausgabedokument zu generieren, das den Schlüssel und den Wert enthält. Eine einzelne Ausgabe in MongoDB 4.2 und früher kann nur die Hälfte der maximalen Größe der BSON-Dateien von MongoDB aufnehmen. Ab Version 4.4 von MongoDB wird die Einschränkung aufgehoben.
Warum Mongodb die beste Wahl für flexible und skalierbare Daten ist
Aufgrund des Fehlens eines starren Schemas wird MongoDB häufig mit NoSQL in Verbindung gebracht. Aufgrund des Fehlens eines starren Schemas können Daten in jedem für die Anwendung geeigneten Format gespeichert werden. Die Flexibilität der Datenbank bietet einen wichtigen Vorteil beim Hoch- oder Herunterskalieren, da Daten so gespeichert werden können, dass sie auf die Bedürfnisse der Anwendung zugeschnitten sind.
Ein Datendiagramm mit ER-Diagrammen kann verwendet werden, um die Beziehungen zwischen verschiedenen Daten zu visualisieren. Das ER-Diagramm stellt eine Reihe von Knoten dar, die eine Sammlung von Daten darstellen, und die Verbindungen zwischen ihnen dienen als Identifikator.
Beziehungen werden in MongoDB nicht erzwungen, da es sich nicht um eine relationale Datenbank handelt. Das ER-Diagramm stellt Beziehungen dar, die innerhalb von Daten bestehen, und hilft auch, sie zu visualisieren.
MongoDB ist eine ausgezeichnete Wahl für Daten, die flexibel und skalierbar sind. Seine Flexibilität ermöglicht es ihm, Daten auf eine für eine Anwendung sinnvolle Weise zu speichern, und seine Skalierbarkeit ermöglicht es ihm, große Datenmengen schnell und einfach zu handhaben.
Map-Reduce Mongodb-Beispiel
In MongoDB ist Map-Reduce ein Datenverarbeitungsparadigma zum Aggregieren von Daten aus Sammlungen. Es ähnelt den Map- und Reduce-Funktionen in der funktionalen Programmierung.
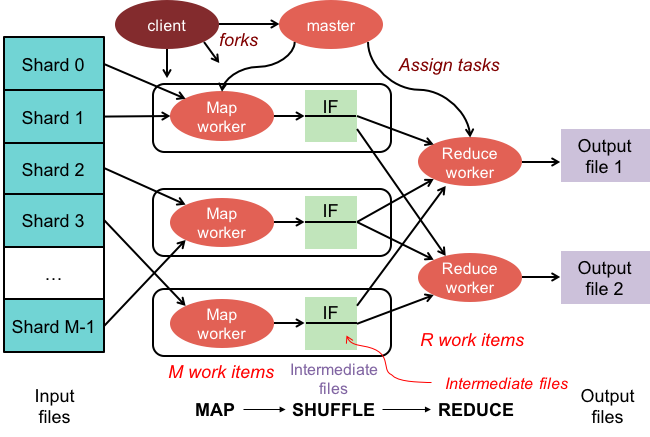
Map-Reduce-Operationen bestehen aus zwei Phasen:
1. Die Zuordnungsphase wendet eine Zuordnungsfunktion auf jedes Dokument in der Sammlung an. Die Zuordnungsfunktion gibt für jedes Eingabedokument ein oder mehrere Objekte aus.
2. Die Reduzierphase wendet eine Reduzierfunktion auf die von der Abbildungsphase ausgegebenen Dokumente an. Die Reduce-Funktion aggregiert die Objekte und erzeugt ein einzelnes Objekt als Ausgabe.
Stellen Sie sich beispielsweise eine Sammlung von Artikeln vor. Wir können map-reduce verwenden, um die Anzahl der Wörter in jedem Artikel zu berechnen.
Zuerst definieren wir eine Zuordnungsfunktion, die ein Schlüssel-Wert-Paar für jedes Dokument ausgibt, wobei der Schlüssel die Artikel-ID und der Wert die Anzahl der Wörter im Artikel ist.
Als nächstes definieren wir eine Reduce-Funktion, die die Werte für jeden Schlüssel summiert.
Schließlich führen wir die Map-Reduce-Operation für die Sammlung aus. Das Ergebnis ist ein Dokument, das die aggregierten Daten enthält.
In Mongosh gibt es eine Datenbank. Die Methode mapReduce() ist ein Wrapper um den Befehl mapReduce. In diesem Abschnitt werden mehrere Beispiele bereitgestellt, z. B. eine Aggregations-Pipeline-Alternative ohne einen benutzerdefinierten Aggregationsausdruck. Karten können mit benutzerdefinierten Ausdrücken übersetzt werden, indem Beispiele für Map-Reduce-to-Aggregation-Pipeline-Übersetzungen verwendet werden. Die Map-Reduce-Operation kann geändert werden, ohne benutzerdefinierte Funktionen mit den verfügbaren Aggregations-Pipeline-Operatoren definieren zu müssen. Die Kartenfunktion kann verwendet werden, um jedes Dokument in der Eingabe zu verarbeiten. Jeder Artikel hat seinen eigenen Objektwert, der einem neuen Wert zugeordnet ist, der die Zahl 1, die Mengennummer für die Bestellung und eine Liste von Artikeln enthält.
Wenn der Schlüssel im aktuellen Dokument mit dem Schlüssel im neuen Dokument übereinstimmt, überschreibt die Operation dieses Dokument. Sie können den Map-Reduce-Vorgang mithilfe von Aggregations-Pipeline-Operatoren neu schreiben, anstatt benutzerdefinierte Funktionen zu definieren. Die $unwind-Stufe zerlegt das Dokument nach dem Array-Feld items, was zu einem Dokument für jedes Array-Element führt. Wenn die $project-Phase das Ausgabedokument umgestaltet, wird die Map-Reduce-Ausgabe gespiegelt. Eine Operation überschreibt ein vorhandenes Dokument, das denselben Schlüssel wie das neue Ergebnis hat.
Was ist die Mapper-Funktion in Hadoop?
Als Reducer müssen Sie die Daten der Mapper kombinieren, um eine einheitliche Antwort zu generieren. Ausgabe reduzieren wird erzeugt, wenn eine Reihe von Map-Ausgaben als Eingabe akzeptiert wird, von denen jede eine Teilmenge des generierten Ergebnisses darstellt.
Mapper werden verwendet, um Daten in überschaubare Chunks zu unterteilen und dann jeden Chunk basierend auf seiner Größe einer Aufgabe zuzuweisen. Die Eingabedaten werden von der Mapper-Funktion empfangen, wo es Parameter gibt, die die auszuführende Aufgabe angeben.
Eine Reihe von Elementen entspricht den Datenblöcken, die vom Mapper in der Ausgabe zugeordnet wurden. Als Ergebnis wird die Map-Ausgabe an den Reducer weitergeleitet, der sie in eine Reduce-Ausgabe umwandelt.
Fehler werden auch von der Mapper-Funktion behandelt. Ein Mapper gibt in diesem Fall eine Fehlerausgabe zurück, die keine Map-Ausgabe ist. Da der Reducer diese Daten nicht verarbeiten kann, gibt der Mapper eine Fehlermeldung zurück.
Hadoop-Ökosystem
Das Hadoop-Ökosystem ist eine Plattform zur Verarbeitung und Speicherung von Big Data. Es besteht aus einer Reihe von Komponenten, die jeweils eine bestimmte Rolle bei der Verarbeitung und Speicherung von Daten spielen. Die wichtigsten Komponenten des Ökosystems sind das Hadoop Distributed File System (HDFS), das MapReduce-Framework und die Hadoop Common-Bibliothek .