
Master-Slave vs. Multi-Master-Replikation in NoSQL-Datenbanken
Veröffentlicht: 2023-01-13Es gibt viele verschiedene Arten der Replikation, die von NoSQL-Datenbanken unterstützt werden. Die gebräuchlichste Art der Replikation ist die Master- Slave-Replikation . Bei dieser Art der Replikation gibt es einen Masterserver, der alle Daten enthält. Die Slave-Server replizieren dann die Daten vom Master-Server. Diese Art der Replikation ist sehr einfach und leicht einzurichten. Es ist auch sehr effizient und bietet eine gute Leistung. Eine weitere Art der Replikation, die von NoSQL-Datenbanken unterstützt wird, ist die Multi-Master-Replikation. Bei dieser Art der Replikation gibt es mehrere Masterserver. Jeder Master-Server hat eine Kopie der Daten. Die Slave-Server replizieren dann die Daten von allen Master-Servern. Diese Art der Replikation ist komplexer einzurichten, bietet jedoch eine bessere Leistung und ist fehlertoleranter.
Zusätzlich zur NoSQL -Datenreplikation bietet es eine robuste Funktion, mit der Sie Ihre strukturierten, unstrukturierten und halbstrukturierten Daten im Falle eines Serverausfalls kopieren und speichern können. Entdecken Sie, wie Sie NoSQL-Datenbanken in einem einfachen Schritt-für-Schritt-Prozess verwenden.
Datenreplikation: Da Daten von einem Server auf einen anderen repliziert werden, kann jedes Datenbit auf mehreren Servern gefunden werden. Ein Replikationsprozess ist in zwei Phasen unterteilt: Master-Slave-Replikation und Slave-bewusste Replikation. Die Master-Slave-Replikation weist einem Knoten die Berechtigung zum Verarbeiten von Schreibvorgängen zu, während die Slave-bewusste Replikation Slaves das Lesen und Synchronisieren mit dem Master ermöglicht.
MySQL beinhaltet die einseitige asynchrone Replikation , bei der ein Server als Quelle fungiert und ein anderer als Replik dient.
Der Replikationsfaktor (RF) ist, wie der Name schon sagt, die Anzahl der Knoten, in denen Daten (Zeilen und Partitionen) repliziert werden. Mehrere Knoten (RF=N) sind verbunden, um Daten zu übertragen. Der RF von Eins zeigt an, dass es nur eine Kopie einer Zeile in einem Cluster gibt und es keine Möglichkeit gibt, die Daten wiederherzustellen, wenn der Knoten abgestürzt oder kompromittiert ist.
Was ist Sharding und Replikation in Nosql?
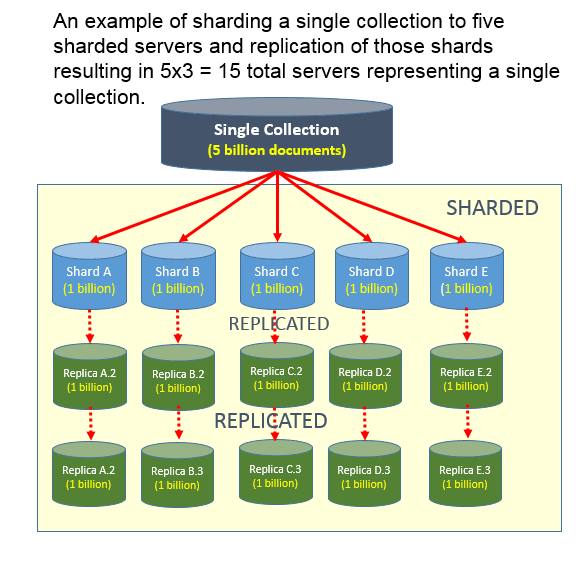
Was ist der Unterschied zwischen Sharding und Replikation? Die Datenreplikation findet statt, wenn ein primärer Serverknoten und ein sekundärer Serverknoten Daten austauschen. Als Backup im Falle eines Ausfalls des Primärservers kann dies helfen, die Datenverfügbarkeit zu erhöhen. Die horizontale Skalierung über mehrere Server hinweg basiert auf der Verwendung eines Shard-Schlüssels.
Mit SQL-Datenbanken können Sie einen Datensatz in Tabellen aufteilen und dann eine Partition für jede Tabelle erstellen. Eine NoSQL-Datenbank wie MongoDB hat keine Tabellen, sondern eine Sammlung von Dokumenten. Der Mongo-Shard-Befehl wird verwendet, um MongoDB-Sammlungen zu fragmentieren. Sie können die Last auf mehrere Server in einer einzigen Sharding-Umgebung verteilen, was zu einer verbesserten Leistung führt. Dies gilt insbesondere für große Datensätze. Darüber hinaus kann Sharding helfen, große Datensätze zu verwalten und zu sichern, indem Datenintegrität bereitgestellt wird. Neben der Skalierung Ihrer Daten ist Sharding ein fantastisches Werkzeug, um sie effektiv zu verwalten. Dieses Muster wird aufgrund seiner einfachen Implementierung und breiten Unterstützung häufig in NoSQL-Datenbanken verwendet.
Warum Sharding besser für Datenschreibvorgänge ist
Im Allgemeinen ermöglicht die Replikation eine horizontale Skalierung von Lesevorgängen, aber nicht die Skalierung von Daten über mehrere Server mit einem einzigen Schlüssel, während Sharding dies tut.
Welche Art von Daten wird von Nosql unterstützt?
NoSQL-Datenbanken werden immer beliebter, da sie eine Vielzahl von Datentypen unterstützen. Dies umfasst sowohl traditionelle Datentypen wie Zahlen und Zeichenfolgen als auch neuere Datentypen wie JSON und XML. NoSQL-Datenbanken unterstützen auch eine Vielzahl von Programmiersprachen, was sie zu einer guten Wahl für Unternehmen macht, die mehrere Sprachen verwenden.
In einer NoSQL-Datenbank gibt es vier Typen: Schlüssel-Wert-Paare, Spalten, Diagramme und Dokumente. Jede Kategorie hat ihre eigenen Eigenschaften und Einschränkungen. Die MongoDB-Datenbank ist eine beliebte NoSQL-Datenbank . Dies ist eine Schlüssel-Wert-Paar-Datenbank, die beide Paare speichert. Diese Anwendung ist einfach zu bedienen, skalierbar und schnell. Dokumentenorientierte Datenbanken stehen im Mittelpunkt von CouchDB. Diese Anwendung ist einfach zu bedienen und flexibel genug, um mehreren Benutzern gerecht zu werden. Die Datenbank CouchBase ist spaltenorientiert und fokussiert auf Transaktionen. Die Datenbank von Cassandra basiert auf einer stark spaltenorientierten Architektur. Das HBase-Speichersystem ist eine skalierbare, verteilte Speicherlösung im Petabyte-Bereich für große Datensätze. Es ist eine verteilte Speicherdatenbank, die auf Redis läuft. Mit Riak als Datenspeicher können Sie ein Open-Source-Hochleistungssystem aufbauen. Neo4J ist als Graphdatenbank auf einer Java-Plattform aufgebaut.
Warum Nosql die beste Wahl für Unternehmen ist, die schnell skalieren müssen
Für Unternehmen, die schnell skalieren müssen, ist NoSQL eine gute Wahl, da es eine flexiblere Architektur hat und horizontal skaliert werden kann. Darüber hinaus reagieren NoSQL-Datenbanken nicht so empfindlich auf Schemaänderungen wie traditionelle relationale Datenbanken.
Nosql-Datenreplikation ist
Die Nosql-Datenreplikation ist ein Vorgang zum Kopieren von Daten aus einer Nosql-Datenbank in eine andere Nosql-Datenbank. Dies geschieht, um die Daten sicher aufzubewahren und sicherzustellen, dass sie im Falle eines Ausfalls immer verfügbar sind.
Nosql vs. Rdbms: Was ist besser für die Leistung?
Es gibt eine wachsende Zahl von Forschungsergebnissen, die zeigen, dass NoSQL-Datenbanken wie MongoDB herkömmliche RDBMSs übertreffen. Die Technologie ermöglicht das Sharding und die Replikation von Daten, wodurch sie sich ideal für Anwendungen eignet, die einen hohen Durchsatz und schnellen Zugriff auf Daten erfordern. Obwohl Daten manchmal repliziert werden können, ist dies nicht immer möglich.
Master-Slave-Replikation in Nosql
Die Master-Slave-Replikation ist eine Art der Replikation, bei der Daten von einem primären („Master“) Server auf einen oder mehrere sekundäre („Slave“) Server kopiert werden. Die Slave-Server können für Leseoperationen verwendet werden, aber alle Schreiboperationen müssen an den Master gesendet werden. Diese Art der Replikation wird häufig in Nosql-Datenbanken verwendet, da sie eine hohe Verfügbarkeit und Skalierbarkeit bieten kann. Wenn beispielsweise der Master-Server ausfällt, können die Slaves immer noch verwendet werden, um Leseanforderungen zu bedienen. Und wenn mehr Lesekapazität benötigt wird, können zusätzliche Slave-Server hinzugefügt werden.
Die Herausforderungen der Master-Slave-Replikation
Es kann schwierig sein, Daten auf allen Slave-Knoten im Master-Slave-Replikationsmodell zu verwalten. Wenn einer der Slave-Knoten ausfällt, gehen die Daten auf diesem Slave-Knoten verloren.
Welches Replikationsmodell unterstützt Datenbank-Lese- und -Schreibvorgänge in allen Knoten?
Das Replikationsmodell, das Lese- und Schreibvorgänge in der Datenbank auf allen Knoten unterstützt, ist das Master- Master-Replikationsmodell . Dieses Modell ermöglicht es jedem Knoten, als Master zu fungieren, was bedeutet, dass jeder Knoten in der Datenbank lesen und schreiben kann. Dies ist vorteilhaft für Organisationen, die hohe Verfügbarkeit und Redundanz benötigen, da alle Knoten weiter betrieben werden können, selbst wenn ein Knoten ausfällt.

Welches Anwendungsmodell unterstützt Datenbank-Lese- und Schreibvorgänge in allen Notes?
RDBMS verwenden typischerweise ein Schema-on-Write-Modell, bei dem eine Datenstruktur im Voraus definiert wird und alle Lese- und Schreibvorgänge von dieser Struktur abhängig sind.
Datenbankänderungen und -aktualisierungen können im Lese-/Schreibmodus auftreten
Änderungen und Aktualisierungen können im Lese-/Schreibmodus erfolgen, wenn die Datenbank im Lese-/Schreibmodus geöffnet wird, der von OpenReadWrite() oder OpenWrite gesteuert wird. DatabaseReader ist eine Klasse, die zum Lesen und Schreiben von Daten in eine Datenbank verwendet werden kann. Daten können mithilfe des DatabaseWriter-Objekts in eine Datenbank geschrieben werden.
Welche Art von Datenbank unterstützt Knoten, die durch Beziehungen verbunden sind?
Beziehungen können in Graphdatenbanken unter Verwendung von strukturierten Beziehungen gespeichert und abgerufen werden. Beziehungen sind die wertvollsten Aspekte von Graphdatenbanken, weil sie zu den wertvollsten Bürgern gehören. Die Knoten werden in Graphdatenbanken verwendet, um Datenentitäten zu speichern, und die Kanten werden verwendet, um Entitäten zu verbinden.
Mongodb und Node.js: Die perfekte Paarung für die Arbeit mit Graphen in Javascript
Wenn Sie Diagramme in JavaScript verwenden möchten, sollten Sie MongoDB verwenden. MongoDB ist die beliebteste NoSQL-Datenbank, während Node.js auch eine beliebte JavaScript-Programmiersprache ist.
Wie funktioniert die nicht relationale Datenbankreplikation?
In einer Peer-to- Peer-NoSQL-Datenreplikationsinstanz werden Daten von einer Datenbank in eine andere repliziert, basierend auf dem Konzept, dass jede Kopie ihre eigene Kopie aktualisieren muss. Dies kann nur funktionieren, wenn jede Kopie des Schemas denselben Datentyp im selben Format speichert. Der andere kritische Aspekt dieser Methode der Datenreplikation ist die Wiederherstellung der Datenbank.
Die verschiedenen Arten der Replikation
*br *Speicherreplikation *br Dies ist eine Art der Replikation, die Datenänderungen auf konsistente Weise speichert. Ein Quellreplikatserver erstellt einen Snapshot der Datenbank mit aktuellen Statusinformationen, nachdem er einen erstellt hat. Anschließend wird der Snapshot an den Zielreplikatserver gesendet. Nach dem Snapshot erstellt der Zielreplikatserver eine neue Kopie der Datenbank. Referenzieren der Transaktionsreplikation in Daten Transaktionen werden in Daten gespeichert, die sich häufig ändern und mithilfe der Transaktionsreplikation repliziert werden können. Eine Transaktion wird gestapelt und in einem einzigen Stapel repliziert. Die Änderungen an den Daten werden durch einen als Replikation bezeichneten Prozess repliziert. Peer-to-Peer-Replikation kann durch die Verwendung von Servern erreicht werden. Die Peer-to-Peer-Datenreplikation ist eine Art der Datenreplikation, mit der Daten repliziert werden, die nicht häufig geändert werden. Bei der Peer-to-Peer-Datenreplikation repliziert ein Cluster von Knoten Daten. Jeder Knoten in einem Cluster hat sein eigenes Datenmodell. Die Cluster-Knoten wissen nichts voneinander.
Replikation der Nosql-Dokumentendatenbank
Nosql-Dokumentendatenbanken sind darauf ausgelegt, hohe Verfügbarkeit und Skalierbarkeit zu bieten, indem Daten über mehrere Server repliziert werden. Dadurch kann die Datenbank auch dann weiter betrieben werden, wenn ein oder mehrere Server ausfallen.
Große Nosql-Datenbank
Auf diese Frage gibt es keine endgültige Antwort, da sie von den spezifischen Bedürfnissen des Benutzers abhängt. Einige der beliebtesten großen Nosql-Datenbanken sind jedoch MongoDB, Cassandra und Hadoop. Diese Datenbanken sind alle auf Skalierbarkeit und hohe Leistung ausgelegt, wodurch sie sich ideal für die Verarbeitung großer Datenmengen eignen.
Eine NoSQL-Datenbank wie zum Beispiel MongoDB ist ideal für Big Data, da sie große Datenmengen schnell und einfach verarbeiten kann. Da MongoDB eine dokumentenorientierte MongoDB ist, kann sie enorme Datenmengen verarbeiten. Mit anderen Worten, MongoDB kann Daten in einer Vielzahl von Formaten verarbeiten, einschließlich JSON, BSON und JavaScript Object Notation (JSON). Es erleichtert auch den Zugriff und die Speicherung von Daten. Darüber hinaus ist MongoDB skalierbar, was bedeutet, dass es große Datenmengen verarbeiten kann.
Welche Nosql-Datenbank eignet sich am besten für Big Data?
Sie erstellen die Formate, die Analysetools verwenden können, um unstrukturierte und halbstrukturierte Daten in Formate umzuwandeln, die in ihren Anwendungen verwendet werden können. Die einzigartigen Anforderungen zum Speichern von Big Data machen NoSQL (nicht relationale) Datenbanken wie MongoDB zu einer ausgezeichneten Wahl.
Warum Mongodb die beste Wahl für die Speicherung von Big Data ist
MongoDB ist eine ausgezeichnete Wahl zum Speichern und Verwalten großer Datenmengen. Die CRUD-Operationen (Erstellen, Lesen, Aktualisieren, Löschen), das Aggregations-Framework, die Textsuche und die Map-Reduce-Funktion machen es Benutzern einfach, auf die Daten zuzugreifen, sie zu bearbeiten und zu analysieren.
Ist Big Data Nosql?
Wenn sich Ihre Datenworkloads mehr auf die schnelle Verarbeitung und Analyse großer Mengen unterschiedlicher und unstrukturierter Daten wie Big Data konzentrieren, ist NoSQL die bessere Wahl. NoSQL-Datenbanken haben nicht die gleichen Beschränkungen für Datentypen wie relationale Datenbanken.
Warum Nosql-Datenbanken die Zukunft des Datenmanagements sind
Datenbank NoSQL wird aufgrund ihrer erheblichen Leistungsvorteile gegenüber herkömmlichen relationalen Datenbanken immer beliebter. Es handelt sich um einen NoSQL-Datenbank-Enabler, der bestimmte Arten von NoSQL-Datenbanken wie HBase aktiviert und es ermöglicht, Daten über Tausende von Servern zu verteilen, ohne die Leistung zu beeinträchtigen. Die Cloud-Plattform von Google (GCP) bietet eine Vielzahl von Datenbankdiensten, die in ihrer Fähigkeit, sehr große, dynamische Datensätze ohne die Notwendigkeit eines Schemas zu verarbeiten, einzigartig sind.
Verwenden große Unternehmen Nosql?
Datenbanktechnologie, die auf Cloud Computing, dem Web, Big Data und den Big Users basiert. Durch das Angebot von NoSQL als Alternative zum herkömmlichen RDBMS ist NoSQL zu einer praktikablen Option für viele beliebte Internetunternehmen wie LinkedIn, Google, Amazon und Facebook geworden.
Ist Nosql die Zukunft für die Backend-Datenbanken von Instagram?
An diesem Punkt scheint Instagram PostgreSQL als primäre Datenbank als primäres Backend zu bevorzugen, obwohl sich dies ändern kann. Cassandra, eine beliebte NoSQL-Datenbank, ist möglicherweise nicht die beste Lösung für Instagram. Cassandra ist ein ausgezeichnetes Tool zum Speichern großer Datenmengen, hat aber eine schlechte Erfolgsbilanz in Bezug auf die Leistung.
Im Moment ist es schwierig vorherzusagen, ob Instagram NoSQL-Datenbanken als primäre Backend-Datenbank verwenden wird oder nicht. PostgreSQL und Cassandra sind eine ausgezeichnete Wahl, aber sie können in Bezug auf die Leistung nicht mit SQL mithalten.