
Microservices Nosql-Datenbanken und Nachrichtenwarteschlangen
Veröffentlicht: 2022-11-22Microservices sind eine Art von Softwarearchitektur, die es Entwicklern ermöglicht, einzelne Funktionsmodule zu erstellen, die als System zusammenarbeiten. In einem Microservices-System hat jeder Service seine eigene Datenbank. Dadurch kann jeder Dienst unabhängig von anderen Diensten entwickelt und bereitgestellt werden. Nosql-Datenbanken sind ein Datenbanktyp, der nicht die traditionelle tabellenbasierte Struktur relationaler Datenbanken verwendet . Nosql-Datenbanken werden häufig zum Speichern großer Datenmengen verwendet, die für relationale Datenbanken nicht gut geeignet sind. Microservices können mit einer Vielzahl von Methoden mit nosql-Datenbanken kommunizieren. Ein gängiger Ansatz ist die Verwendung einer Nachrichtenwarteschlange. Bei diesem Ansatz hat jeder Dienst eine Nachrichtenwarteschlange, die er verwendet, um mit anderen Diensten zu kommunizieren. Wenn ein Dienst auf Daten in einer nosql-Datenbank zugreifen muss, sendet er eine Nachricht an die Warteschlange. Ein anderer Dienst, der für den Zugriff auf die nosql-Datenbank zuständig ist, ruft die Nachricht aus der Warteschlange ab und ruft die Daten aus der Datenbank ab. Ein weiterer Ansatz ist die Verwendung einer REST-API. Bei diesem Ansatz stellt jeder Dienst eine REST-API bereit, die andere Dienste verwenden können, um auf Daten in der nosql-Datenbank zuzugreifen. Dieser Ansatz wird häufig verwendet, wenn die Daten in der nosql-Datenbank häufig aktualisiert werden. Ein weiterer gängiger Ansatz ist die Verwendung einer Graphdatenbank. Bei diesem Ansatz wird jeder Dienst als Knoten in einem Diagramm dargestellt. Die Kanten im Diagramm stellen die Beziehungen zwischen den Diensten dar. Dieser Ansatz wird häufig verwendet, wenn die Daten in der nosql-Datenbank stark miteinander verbunden sind.
Das Ziel von Microservices ist es, maximale Geschwindigkeit zu erreichen. Die meisten NoSQL-Dienste können in nur 24 Stunden eingerichtet, schnell skaliert und so viele Datenknoten wie möglich erstellt werden, bevor die Persistenzschicht berührt wird. Als Ergebnis all dessen haben Sie einen schnelleren Release-Zyklus.
NoSQL-Datenbanken sind häufig einfacher zu verwenden, wenn sie in großem Umfang auf eine Weise bereitgestellt werden, die Microservices unterstützt. Die Möglichkeit, NoSQL-Datenbanken mit Echtzeit-Streaming-Technologien zu integrieren, ist oft überlegen.
Wie Sie oben gesagt haben, muss jeder Microservice über seine DATEN verfügen, die in einer Datenbank, einem dedizierten Schema oder sogar einer Reihe von dedizierten Tabellen (in einer Datenbank definiert) gespeichert werden können.
Wie interagieren Microservices mit der Datenbank?
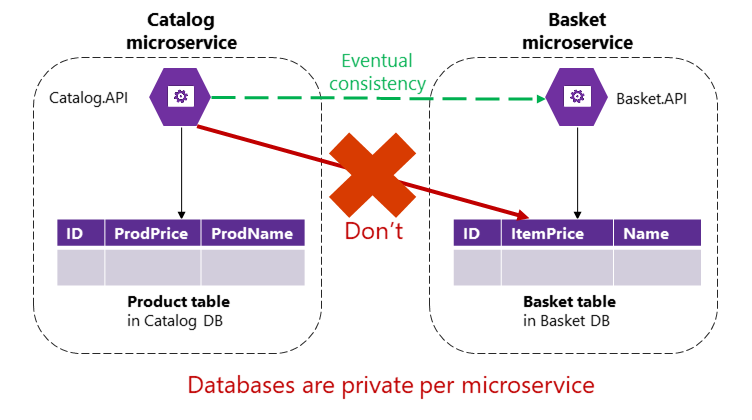
Die Anwendung interagiert monolithisch mit einer Datenbank. Alle Komponenten einer Anwendung nutzen dieselben Daten. Der Datenbesitz ist bei Microservices dezentralisiert, während er bei anderen Arten von Apps direkt erfolgt. Alle Dienste haben im Allgemeinen ihre eigenen privaten Datenspeicher, die auf ihre Funktionen zugeschnitten sind.
Das Erstellen einer separaten Datenbank für jeden Dienst kann helfen, Domänengrenzen durchzusetzen und unbeabsichtigte Dateninteraktionen zu verhindern, aber es ist nicht die einzige Lösung. Die Möglichkeit, eine Datenbank mit allen Ihren Diensten zu teilen, ist ebenfalls eine Option. Solange sich Ihre Dienste verhalten und Sie nicht mit unerwarteten Daten von anderen Diensten überraschen, wird es Ihnen gut gehen. Datenbankbasierte Microservice-Architekturen sind schwer zu skalieren. Datenbankabstürze treten in der gesamten Datenbank auf, nicht nur in einem einzelnen Cluster. Änderungen in der Datenbank können sich auf eine Reihe von Diensten auswirken. Da Microservices auf derselben Datenbank aufbauen und sich mit ihr verbinden, sind sie außerdem nicht unabhängig voneinander. In einer Microservices-Architektur kann die Verwendung einer gemeinsam genutzten Datenbank eine Reihe von Vorteilen bieten. Das System kann auch beim Hochskalieren und Anpassen der Architektur helfen. Es kann auch die Entwicklung und Bereitstellung der Dienste erleichtern. Schließlich wird es einfacher, das System zu verwalten und Fehler zu beheben. Stellen Sie daher sicher, dass Ihre Architektur anpassungsfähig und skalierbar ist, unabhängig davon, ob Sie eine einzelne Datenbank für Ihre Microservices oder eine separate Datenbank für jeden Service verwenden.
Die Vor- und Nachteile von Microservices
Organisationen sind in den letzten Jahren immer abhängiger von Microservices geworden. Sie reduzieren die Notwendigkeit teamübergreifender Abhängigkeiten zwischen Entwicklern, haben aber auch Mängel. Eines der Probleme mit Microservices ist, dass sie auf eine einzige Datenbank angewiesen sind. Die gemeinsame Nutzung von Daten ist erforderlich, wenn zwei verschiedene Microservices dieselben Informationen benötigen. Wenn einer der Microservices die Daten für längere Zeit sperrt, sind die Daten möglicherweise nicht mehr verfügbar. Ein weiteres Problem bei Microservices ist die Schwierigkeit, auf Daten von anderen Microservices zuzugreifen. Für jeden Microservice ist ein Kommunikationsprotokoll erforderlich, um eine Verbindung zu den Daten des anderen herzustellen. Diese Art der Implementierung kann schwierig zu implementieren sein und zu Fehlern führen. Eine Möglichkeit, diese Probleme zu lösen, besteht darin, mehrere Datenbanken zu verwenden. Microservice-Websites können mit dieser Methode die Datenbank nutzen, die ihren spezifischen Anforderungen am besten entspricht. Es ermöglicht uns auch, verschiedene Datenbanktechnologien zu verwenden, wenn wir verschiedene Microservices entwickeln. Dadurch ist der Zugriff auf Daten zwischen Microservices jetzt einfacher.
Gemeinsam genutzte Microservices-Datenbank
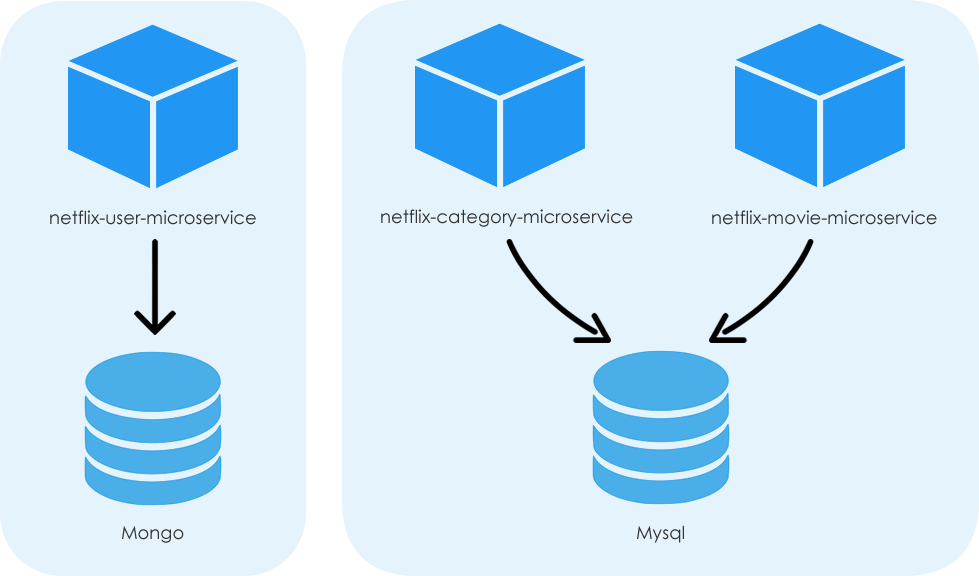
Eine gemeinsam genutzte Microservices-Datenbank ist eine Datenbank, die von Microservices gemeinsam genutzt wird. Diese Datenbank kann verwendet werden, um Daten zu speichern, die von mehreren Microservices benötigt werden. Dies kann hilfreich sein, wenn Daten zwischen Microservices geteilt werden müssen, aber nicht jeder Microservice über eine eigene Kopie der Daten verfügen muss.

Best Practices für Microservice-Datenbanken
Auf diese Frage gibt es keine allgemeingültige Antwort, da die Best Practices für Microservice-Datenbanken je nach den spezifischen Anforderungen Ihrer Anwendung variieren. Einige allgemeine Tipps, die hilfreich sein können, umfassen jedoch das Entwerfen Ihres Datenbankschemas als modular und lose gekoppelt, das Verwenden einer Nachrichtenwarteschlange zum Entkoppeln von Microservices und das Verwenden einer Datenbankreplikationslösung zum Sicherstellen einer hohen Verfügbarkeit.
Datenbankmuster für Microservices
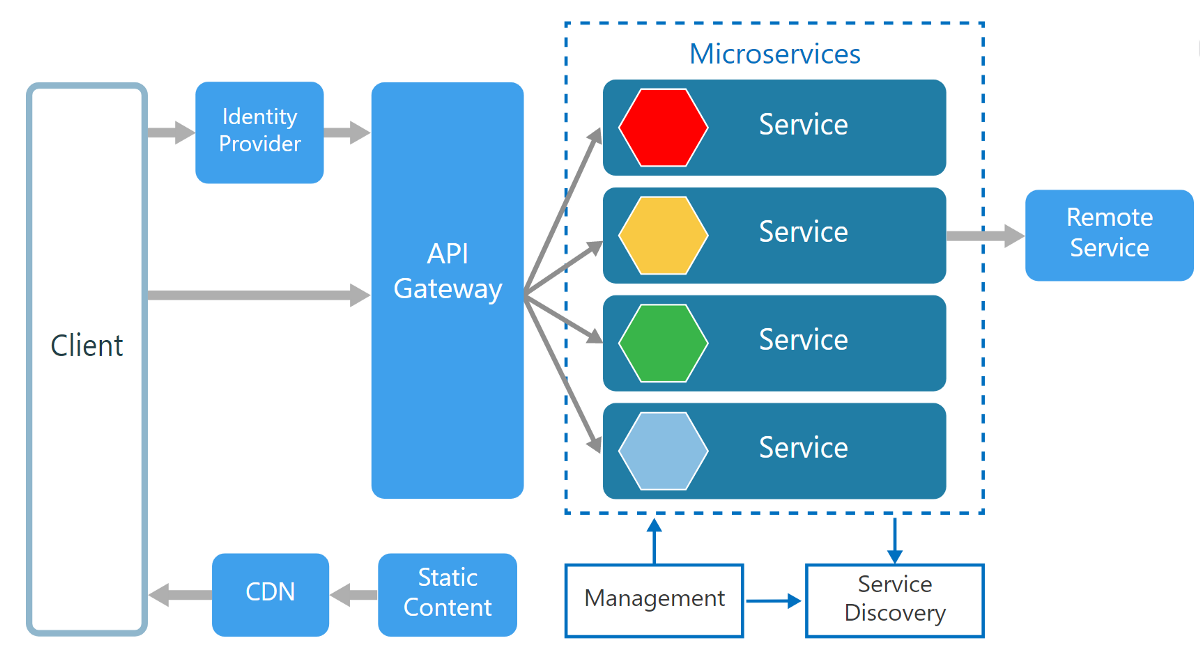
Es gibt einige verschiedene Datenbankmuster, die für Microservices verwendet werden können. Am gebräuchlichsten ist das Shared-Database-Muster, bei dem jeder Microservice über eine eigene Datenbank verfügt, die zur Datenspeicherung verwendet wird. Dies kann entweder eine relationale Datenbank wie MySQL oder eine NoSQL-Datenbank wie MongoDB sein. Ein weiteres häufiges Muster ist das Event-Sourcing-Muster, bei dem jeder Microservice über ein eigenes Ereignisprotokoll verfügt, das zur Datenspeicherung verwendet wird. Dieses Ereignisprotokoll kann verwendet werden, um Ereignisse wiederzugeben, die in der Vergangenheit aufgetreten sind, was für Debugging- oder Überwachungszwecke nützlich sein kann.
Microservices-Datenbankverknüpfungen
Microservices sind ein neuerer Ansatz zum Erstellen von Softwareanwendungen, die sich auf kleine, unabhängige Dienste konzentrieren, die zusammenarbeiten. Dieser Ansatz hat viele Vorteile, aber ein potenzieller Nachteil besteht darin, dass er Datenbankverknüpfungen erschweren kann.
Eine Möglichkeit, diese Herausforderung zu meistern, besteht darin, ein Tool wie Apache Kafka zu verwenden, das als zentraler Knotenpunkt für Daten aus all Ihren Microservices fungieren kann. Kafka kann dann verwendet werden, um Verknüpfungen mit diesen Daten durchzuführen, was die Arbeit mit Daten aus mehreren Microservices erheblich vereinfacht.
Microservices-Datenbankverwaltungsmuster
Es gibt keine allgemeingültige Antwort auf das Datenbankmanagement für Microservices, aber es gibt einige gängige Muster, die befolgt werden können, um Datenkonsistenz und Leistung sicherzustellen. Ein gängiges Muster ist eine zentrale Datenbank , auf die alle Microservices zugreifen können, was zur Gewährleistung der Datenkonsistenz beitragen kann. Ein weiteres gängiges Muster besteht darin, dass jeder Microservice seine eigene Datenbank verwaltet, was zur Verbesserung der Leistung beitragen kann, indem jedem Microservice ermöglicht wird, seine eigene Datenbank unabhängig zu skalieren.
Welche Muster werden in Microservices verwendet?
Die Client-Side Discovery- und Server-Side Discovery-Muster werden verwendet, um Anfragen für Clients an eine verfügbare Dienstinstanz in Microservice-Architekturen weiterzuleiten. Die Messaging- und Fernprozeduraufrufmuster von Diensten können auf unterschiedliche Weise verwendet werden.
Wie wird die Datenbank in Microservices verwaltet?
Das Hauptmerkmal der Microservices-Architektur ist, dass Services ohne Servicekopplung bereitgestellt werden. Um dies zu erreichen, muss jeder Dienst über einen eigenen privaten Datenspeicher verfügen. Daher erfordert die Entwicklung einer Datenbankarchitektur für Microservices in der Regel die Einhaltung eines servicebasierten Musters.
Wie verwalte ich mehrere Datenbanken in Microservices?
Wenn Sie eine einzelne Datenbank für verschiedene Microservices erstellen, ist dies ein Anti-Pattern; Die Lösung besteht darin, für jeden Microservice eine Datenbank zu erstellen.
Microservices-Architektur
Eine Microservices-Architektur ist eine Art von Softwarearchitektur, die Software als Sammlung kleiner, unabhängiger Dienste organisiert. Jeder Dienst ist für eine bestimmte Funktion verantwortlich und kommuniziert mit anderen Diensten, um Aufgaben auszuführen. Diese Art von Architektur wurde entwickelt, um die Flexibilität, Skalierbarkeit und Wartbarkeit von Softwareanwendungen zu verbessern.
Die drei verschiedenen Arten von Microservice-Topologien
Die REST-basierte API-Topologie finden Sie im folgenden Diagramm. Der Zugriff auf Microservices erfolgt über RESTful-APIs basierend auf der Topologie der Microservices. Microservices werden auf verschiedenen Knoten in der Infrastruktur implementiert und verwenden Standard-HTTP, um miteinander zu kommunizieren. Eine REST-basierte Topologie wird verwendet, um eine Anwendung zu erstellen. Die Microservices werden mithilfe derselben RESTful-APIs über die Topologie verteilt. Eine Microservices-Bereitstellung hingegen basiert auf einer API-nachrichtenbasierten Kommunikation zwischen den Microservices. Die Topologie des Messaging wird zentral verteilt. Eine Microservices-Topologie basiert auf einer zentralisierten Messaging-Plattform, in der die Microservices miteinander kommunizieren. Es wird hauptsächlich für die Kommunikation von Microservices verwendet, wobei Nachrichten, die zwischen Microservices und ihren Orchestrierungsschichten ausgetauscht werden, über diese Plattform abgewickelt werden.