
Vorteile der NoSQL-Datenbank
Veröffentlicht: 2022-11-22NoSQL-Datenbanken sind nicht relationale Datenbanken , die eine flexiblere Art der Datenspeicherung ermöglichen. Dies bedeutet, dass Daten auf verschiedene Arten gespeichert werden können, einschließlich als Schlüssel-Wert-Paare, dokumentorientiert oder spaltenorientiert. NoSQL-Datenbanken werden häufig für die groß angelegte Datenspeicherung verwendet, da sie skalierbarer sind und eine größere Datenmenge verarbeiten können als herkömmliche relationale Datenbanken.
Grundsätzlich ermöglicht NoSQL die schnelle Speicherung großer Mengen unabhängiger Daten. Eine NoSQL-Datenbank ist im Wesentlichen nicht in der Lage, relationale Daten zu speichern. In den 1970er Jahren wurde die Verwendung relationaler Datenbanken zum Standard für die Datenspeicherung. Laut Ben Finkel, einem CBT-Ausbilder, schätzt NoSQL Geschwindigkeit und Flexibilität über Konsistenz und Effizienz. Datenbankersteller und Wartungsingenieure müssen hochqualifiziert sein, um relationale Datenbanken zu erstellen und zu warten, die sowohl schnell als auch effizient sind. Eine NoSQL-Datenbank erfordert nicht die Erstellung oder Planung einer Datenbank. Dadurch können Entwickler Anwendungen viel schneller erstellen, prototypisieren und bereitstellen.
Darüber hinaus ähneln sie der heutzutage populäreren agilen Entwicklung. NoSQL-Datenbanken müssen nicht geändert werden und können eine Vielzahl von Datentypen speichern. Die Anzahl der Bytes in einer NoSQL-Datenbank ist höher als die Anzahl in einer relationalen Datenbank . Der Raspberry Pi kann eine NoSQL-Datenbank ausführen, wird es aber deutlich schwerer haben, mit der Last eines Webservers fertig zu werden. Diagramme unterscheiden sich stark von Schlüssel:Wert-Paaren und Dokumenten. Knoten und Kanten sind die beiden Teile eines Graphen. Die Knoten enthalten Informationen über ein Objekt (Person, Ort, Sache, Idee usw.), die von anderen Knoten verwendet werden können. Nächste-Nachbar-Beziehungen werden durch Kantenbeziehungen erklärt. Wir verwenden ein Datenmodell mit breiten Spalten, weil es wie die Zeilen und Spalten aussieht, die wir in einer relationalen Datenbank sehen würden.
Im Gegensatz zu relationalen Datenbanken, die Zeilen und Spalten enthalten, bestehen NoSQL-Datenbanken aus JSON-Dokumenten. Wir melden uns schnell bei Ihnen: NoSQL bedeutet einfach „nicht nur SQL“ und nicht „überhaupt kein SQL“.
Was ist Row in Nosql?
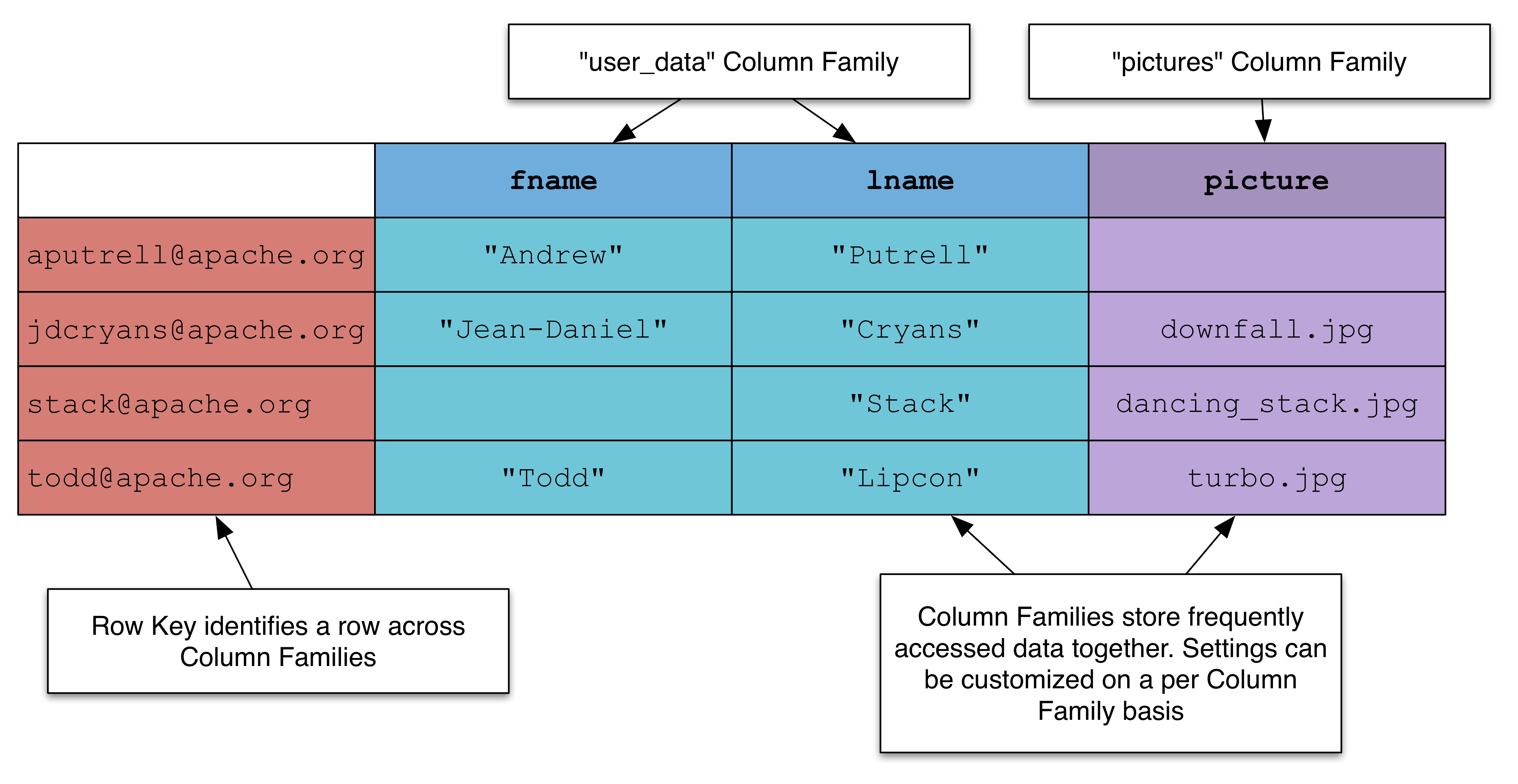
Auf diese Frage gibt es keine endgültige Antwort, da der Begriff „Zeile“ für verschiedene Personen unterschiedliche Bedeutungen haben kann, wenn es um die Arbeit mit NoSQL-Datenbanken geht. Im Allgemeinen ist eine Zeile jedoch einfach ein Datensatz in einer NoSQL-Datenbank, der aus einem oder mehreren Schlüssel-Wert-Paaren besteht. Jeder Schlüssel in einer Zeile entspricht einem bestimmten Attribut der gespeicherten Daten, und der Wert sind die tatsächlichen Daten, die diesem Attribut zugeordnet sind.
Tabellenzeilen haben im Gegensatz zu Tabellenschemadatensätzen zusätzliche Eigenschaften, die sie dazu bringen, Werte aufzuzeichnen. Diese Eigenschaften sollten mit den in diesem Abschnitt aufgeführten Funktionen bewertet werden. Die Funktion modification_time zeigt die letzte Änderungszeit (in UTC) jeder Zeile an. Die Einfügezeit wird zurückgegeben, wenn die Zeile seit ihrer Einfügung nie geändert wurde. Sie können die Partitionsfunktion verwenden, um die Partitions-ID anzuzeigen, in der die Datenzeile(n) gespeichert sind. Wenn diese Funktion verwendet wird, können Sie potenzielle Speicher-Hotspots oder ein Ungleichgewicht in Ihrer Oracle NoSQL-Datenbank identifizieren. Die Funktion row_storage_size gibt die Speicherkapazität (in Bytes) der angegebenen Datenzeile zurück.
Wide-Column-Stores bieten wie relationale Datenbanken einige deutliche Vorteile. Wide-Column-Stores haben zusätzlich zu ihrer horizontalen Skalierbarkeit Vorteile, was bedeutet, dass sie eine große Anzahl von Dokumenten verarbeiten können, ohne dass es zu Leistungsproblemen kommt, die durch hohe Gleichzeitigkeitsniveaus verursacht werden. Auch Wide Column Stores sind anpassungsfähig. Diese Technologien können in einer Vielzahl von Anwendungen eingesetzt werden, darunter Webanwendungen, Data Warehouses und Suchmaschinen. Wide-Column-Speicher sind möglicherweise nicht für Anwendungen geeignet, die eine außergewöhnliche Leistung erfordern.
Zeilen in MySQL gegen Mongodb
In MySQL erstellen Sie eine Tabellenzeile, indem Sie einer Spalte in der Tabelle einen Wert zuweisen. Ein Array enthält einen Datensatz aller Zeilen in der Tabelle, der Tabelleneigenschaften wie Spaltenwerte enthält.
Eine Zeile ist ein Datensatz in einer Tabelle, die eine Art Datenbank ist. Die in einer Zeile enthaltenen Daten sind auf die gleiche Weise organisiert, sodass es sich um eine vollständige Aufzeichnung spezifischer Artikelinformationen handelt. Eine Zeile wird manchmal als Tupel bezeichnet, aber nicht immer.
In MongoDB müssen Zeilen vor der Anzeige nicht schemasigniert werden. Sie können einfach Felder eingeben, wann immer Sie möchten. MongoDB enthält ein Datenmodell, mit dem Sie hierarchische Beziehungen darstellen, Arrays speichern und komplexere Strukturen handhaben können.
Eine Reihe von Spalten wird in MongoDB erstellt, wenn Sie einem Feld in der Tabelle einen Wert hinzufügen. Im Allgemeinen ist eine Zeile ein Datensatz aller Daten in der Tabelle, einschließlich der Feldwerte der Tabelle und aller anderen definierten Eigenschaften.
Ist eine Nosql-Datenbank, in der Daten nach Spalten und nicht nach Zeilen gespeichert werden?
Dies ist die Art der Beschreibung, die ich verwenden möchte. Das Ziel solcher NoSQL-Datenbanken ist es, Benutzern zu ermöglichen, komplexe Abfragen durchzuführen und Daten auf hocheffiziente Weise zu analysieren. Spaltenbasierte Datenbanken verwenden im Gegensatz zu relationalen Datenbanken Spalten zum Speichern von Daten. Diese Spalten werden verwendet, um eine Untergruppe von Spalten zu bilden.
Die Open-Source-Datenbank MongoDB ist bekannt für ihre Geschwindigkeit, Skalierbarkeit und Benutzerfreundlichkeit und ist eine der beliebtesten Datenbanken. Da es sich nicht um ein Paketprodukt handelt, müssen Sie es selbst installieren und verwalten, anstatt es von einem Anbieter wie Oracle oder Microsoft SQL Server zu kaufen.
Eines der Hauptmerkmale von MongoDB ist die Fähigkeit zur Integration mit anderer Software.
Die MongoDB-Datenbank enthält alle ihre Datensätze als Dokumente, sodass Sie sich keine Gedanken über Zeilen- oder Spaltenstrukturen machen müssen.
Aufgrund der BSON-Darstellung von Daten ist MongoDB eine schnelle Datenbank.
MongoDB unterstützt große Datensätze sowie Stapelverarbeitung.
Installation und Verwaltung von MongoDB: Die Benutzerfreundlichkeit von MongoDB macht es zu einer beliebten Wahl für Entwickler.
Sind alle Nosql-Datenbanken spaltenorientiert?
Einige NoSQL-Datenbanken sind spaltenorientierte Datenbanken, während andere SQL-orientierte Datenbanken sind. Sowohl Zeilen als auch Spalten können Details zur physischen Speicherimplementierung für eine relationale oder nicht relationale Datenbank enthalten.
Wie speichert die Nosql-Schlüsselwertdatenbank Daten?
NoSQL-Datenbanken haben einen der am wenigsten komplexen Schlüsselwertspeicher. Genau das macht den Reiz dieses Modells aus. Das Programm verfügt über sehr einfache Funktionen zum Speichern, Abrufen und Entfernen von Daten. Es ist wichtig zu beachten, dass Key -Value-Store-Datenbanken keine Abfragesprache haben.
Das Ziel dieses Artikels ist es, mehr über den Schlüsselwertspeicher von NoSQL zu erfahren. Eine NoSQL-Datenbank ist eine Nicht-SQL- oder nicht relationale Datenbank, die als Mechanismus zum Speichern und Abrufen von Daten dient. Datenbankdesign, horizontale Skalierung und Benutzerkontrolle über die Verfügbarkeit sind wichtige Funktionen in einer NoSQL-Datenbank. Eine Key-Value-Datenbank ist eine Art von NoSQL-Datenbank, die die Key-Value-Methode verwendet. Die Schlüssel, die eine Vielzahl von Objekten wie Zeichenfolgen oder sogar einen bestimmten Werttyp darstellen können, werden als eindeutige Bezeichner bezeichnet. Die Schlüsselnamen können beispielsweise so einfach wie Zahlen oder so komplex wie Beschreibungen der Werte sein.
Wenn Geschwindigkeit, Skalierbarkeit und Benutzerfreundlichkeit entscheidende Aspekte einer Anwendung sind, ist eine Schlüsselwertdatenbank ideal. Eine Schlüssel-Wert-Datenbank eignet sich zum Speichern kleiner Datenmengen, z. B. einer Kundenliste, oder zum Speichern von Daten, die keine Bearbeitung oder Abfrage erfordern. Eine Key-Value-Datenbank wird in mehrere Kategorien eingeteilt, darunter Berkeley DB, HBase, MongoDB und Redis. Jedes hat seine eigenen Funktionen und kann auf vielfältige Weise verwendet werden. Es ist wichtig, jeden von ihnen gründlich zu prüfen, um festzustellen, welcher für Ihr Projekt am besten geeignet ist. Eine Schlüsselwertdatenbank kann zum Speichern von Daten verwendet werden, die nicht auf herkömmliche Weise abgefragt oder bearbeitet werden müssen. Eine Key-Value-Datenbank kann beispielsweise verwendet werden, um kleine Datenmengen zu speichern, wie z. B. eine Kundenliste, oder um Daten zu speichern, die keine Bearbeitung oder Abfrage auf herkömmliche Weise erfordern. Die Key-Value-Datenbank bietet außerdem ein hohes Maß an Skalierbarkeit und Geschwindigkeit. Die Hauptfunktion einer Schlüsselwertdatenbank ist ein assoziatives Array, das es ihr ermöglicht, eine große Anzahl von Daten in kurzer Zeit zu verarbeiten. Da Werte nur Schlüsseln zugeordnet sind, verlassen sich Schlüssel-Wert-Datenbanken außerdem nicht so stark auf Indizes wie traditionelle relationale Datenbanken. Es ist ihnen möglich, große Datenmengen schneller als bisher zu verarbeiten. Ein Nachteil von Key-Value-Datenbanken ist, dass sie mit komplexen Daten nicht sehr gut umgehen können. Das assoziative Array ist eine grundlegende Datenbankstruktur und nicht so ausgefeilt wie eine traditionellere relationale Datenbank . Infolgedessen sind Schlüsselwertdatenbanken nicht in der Lage, große Datenmengen zu verarbeiten, die auf komplexere Weise organisiert werden müssen. Um die Anforderungen von Anwendungen mit hoher Geschwindigkeit, Skalierbarkeit und einfacher Wartung zu erfüllen, sind Schlüsselwertdatenbanken eine ausgezeichnete Wahl. Sie sind ideal zum Speichern kleiner Datenmengen, zum Handhaben von Daten, die nicht auf herkömmliche Weise manipuliert oder abgefragt werden müssen, und zum schnellen und effizienten Verarbeiten großer Datenmengen.

Die Vor- und Nachteile der Verwendung einer Key-Value-Datenbank
Die Sammlungsfunktion von MongoDB ist eine Sammlung von Dokumenten, die den gleichen Feldwerttyp haben. Eine Sammlung kann eine Vielzahl von Dokumenten enthalten, und jedes Dokument darin hat eine eigene Sammlungs-ID. Die Dokumentversionierung ist auch für MongoDB verfügbar, mit der Sie Änderungen an einzelnen Dokumenten innerhalb einer MongoDB-Sammlung nachverfolgen können. MongoDB aktualisiert die Feldwerte einer Sammlung und aktualisiert auch die Versionsnummer des Dokuments und speichert dabei einen Zeitstempel. Wie ist die Nutzung von Key-Value-Datenbanken? Was sind die Vorteile? Eine Key-Value-Datenbank ist einfach einzurichten, was einer ihrer Vorteile ist. Sie müssen keine Tabellen oder Indizes in MongoDB erstellen, nur um loszulegen. Darüber hinaus kann die Verwendung einer Key-Value-Datenbank äußerst effizient sein. Da MongoDB Daten in einer Reihe von Schlüssel-Wert-Paaren speichert , können Sie einen Wert abrufen, indem Sie den Schlüssel in das Suchfeld eingeben. Welche Nachteile hat die Verwendung einer Key-Value-Datenbank? Daten sind mit einer Key-Value-Datenbank schwierig zu pflegen. Wenn Sie einem Dokument in der Sammlung ein neues Feld hinzufügen möchten, müssen Sie jedes Dokument in der Liste manuell aktualisieren. Darüber hinaus ist eine Schlüssel-Wert-Datenbank anfällig für Skalierungsprobleme, da sie schwierig horizontal zu skalieren ist. Da MongoDB Daten in einer Reihe von Schlüssel-Wert-Paaren speichert, müssen weitere Server hinzugefügt werden, wenn Sie mehr Benutzer unterstützen möchten.
Was ist Nosql und wie werden die Dokumente gespeichert?
Dokumentendatenbanken gelten im Allgemeinen als NoSQL-Datenbanken und werden nicht als solche klassifiziert. Anstelle von festen Zeilen und Spalten werden flexible Dokumente verwendet, um Daten in Dokumentendatenbanken zu speichern. Dokumentendatenbanken sind beliebter als tabellarische, relationale Datenbanken.
Dokumentorientierte Datenbanken (auch bekannt als aggregierte Datenbanken, Dokumentdatenbanken oder Dokumentspeicher) speichern einzelne Datensätze sowie die zugehörigen Informationen in einzelnen Dokumenten. Dokumentspeicher sind eine Teilmenge des NoSQL-Schirms und beliebte Datenbankverwaltungssysteme, die „nicht relationale“ Modelle verwenden. DocumentDB ist neben MongoDB, CouchDB, OrientDB und DocumentDB eines der beliebtesten Dokumentenspeichersysteme. Dokumentendatenbanken sind in keiner Weise von Tabellenschemata abhängig. Jede Entität ist in einem einzelnen Dokument untergebracht, und assoziative Daten können innerhalb dieses Dokuments gefunden werden. Mit dieser Methode können Daten variiert, die Integration und Modellierung verbessert und akute Beziehungen zwischen Entitäten effektiver durchgesetzt werden. Dokumentspeicher sind stark auf Schlüsselwertspeicher angewiesen, die diese Durchsetzungsregeln mehr als selbst erstellen können. Dokumentendatenbanken benötigen mehr Dokumentation, bevor sie aus Nischengemeinschaften und Foren entfernt werden können.
Datenbankorientierte Speicher: In der Datenbank enthält jede Tabelle eine Reihe von Spalten. Jede Spalte kann eine Vielzahl von Informationen enthalten. MongoDB, Cloudant und HBase sind nur einige der spaltenorientierten Stores auf dem Markt. Diese Gruppe besteht aus Open-Source-Anwendungen, die auf Googles MapReduce-Papier basieren. Dokumentenspeicher sind Datenbanken, die alle Daten zu einem Dokument speichern. Ein Dokument enthält im Wesentlichen nur Schlüsselwertsätze. Dokumentenspeicher sind eine Art Speicher für Dokumente, wie Nimble und CouchDB. Beide Programme sind Open Source und basieren auf dem Apache CouchDB-Paper. Graphdatenbanken sind Datenbanken, die Graphen zum Speichern von Daten verwenden. Ein Graph besteht aus Knoten und Kanten, die miteinander verbunden sind. Es gibt Kanten in beiden Knoten und Kanten, die die Beziehungen zwischen ihnen darstellen. Graphdatenbanken wie Redis und Neo4j sind Beispiele dafür, wie man eine solche erstellt. Diese Apps sind beide Open Source und wurden mit Facebook Millimeterpapier erstellt.
Nosql-Datenbanken: Die neue Welle der Datenverwaltung
Eine Vielzahl von Faktoren führt dazu, dass NoSQL-Datenbanken immer beliebter werden. Sie sind weniger kompliziert in der Anwendung und flexibler als herkömmliche Datenbanken . Darüber hinaus können sie mit einem breiteren Datenspektrum umgehen als relationale Datenbanken.
Liste der Nosql-Datenbanken
Es gibt viele Arten von NoSQL-Datenbanken, jede mit ihren eigenen Stärken und Schwächen. Die beliebtesten NoSQL-Datenbanken sind MongoDB, Apache Cassandra, Redis und Amazon DynamoDB.
Eine NoSQL-Datenbank ist eine Datenbank, die große Datenmengen erfassen und verarbeiten kann, im Gegensatz zu einer herkömmlichen Datenbank, die kein SQL enthält. Eine NoSQL-Datenbank kann mehrere Typen haben, von denen jeder einen einzigartigen Ansatz zur Datenmodellierung verwendet und im selben Kontext verwendet werden kann oder nicht. Zu den am häufigsten verwendeten Datenbanktypen gehören Schlüsselwert-, dokumentbasierte, grafikbasierte und breite Spaltendatenbanken. Das Datengrid, ein Netzwerk von Systemen, die Daten in der Cloud speichern, ist das, woraus Datenbanken und Grids bestehen. Datenbankmodelle sind eine Sammlung von Funktionen, die von zwei oder mehr Datenbankmodellen gemeinsam genutzt werden. Für NoSQL-Datenbanken im Jahr 2021 ist die folgende Tabelle basierend auf dem Typ in Abschnitte unterteilt. Die Open-Source-Graphdatenbank Neo4J basiert auf Java und verfügt über zusätzliche Funktionen, die als Teil der Graph Data Platform verfügbar sind.
RedisGraph, ein Graph-Datenbankmodul für Redis, wandelt Abfragen mithilfe der Cypher-Abfragesprache in lineare Algebra-Ausdrücke um. Eine weitere Hadoop-basierte Lösung ist Accumulo, die auf Googles Bigtable basiert. ObjectDB, Infinispan, Hazelcast und ArangoDB sind nur einige der auf dem Markt verfügbaren NoSQL-Datenbanken. Obwohl dies eine Liste ist, stehen Ihnen zahlreiche andere Optionen zur Verfügung. Ihre Datenbanklösung wird höchstwahrscheinlich Ihren Anforderungen am besten entsprechen, wenn Sie diese Listen verwenden.
Warum Mongodb die beliebteste Nosql-Datenbank ist
Laut der Website database-engines.com ist MongoDB die am weitesten verbreitete NoSQL-Datenbank. Neben MySQL, Cassandra und DynamoDB haben sich NoSQL-Datenbanken zu einer beliebten Alternative zu relationalen Datenbanken entwickelt.
Beispiele für Nosql-Datenbanken
Heutzutage sind viele NoSQL-Datenbanken verfügbar, jede mit ihren eigenen Vor- und Nachteilen. Einige der beliebtesten NoSQL-Datenbanken sind MongoDB, Cassandra und Redis. MongoDB ist eine leistungsstarke dokumentenorientierte Datenbank, die sich perfekt für Anwendungen eignet, die eine hohe Leistung und Skalierbarkeit erfordern. Cassandra ist eine hochgradig skalierbare, spaltenorientierte Datenbank, die sich perfekt für Anwendungen eignet, die eine hohe Verfügbarkeit erfordern. Redis ist ein In-Memory-Schlüsselwertspeicher, der sich perfekt für Anwendungen eignet, die einen extrem schnellen Datenzugriff erfordern.
Nicht relationale Datenbanken wie NoSQL-Datenbanken speichern Daten in einem anderen Format als dem, das von relationalen Datenbanken verwendet wird. Es muss kein festes Schema verwendet werden, Join-Funktionen werden vermieden und NoSQL lässt sich einfach skalieren. Der Hauptzweck von NoSQL-Datenbanken besteht darin, verteilte Datenspeicher mit enormen Speicheranforderungen zu bedienen. Unternehmen wie Twitter, Facebook und Google sammeln täglich Terabytes an Benutzerinformationen. NoSQL-Datenbanken sind verteilt, was bedeutet, dass es in ihnen keine einzelne Steuereinheit oder Speicher gibt. Dadurch entfällt die Bereitstellung oder Verwaltung unterschiedlicher Datenbanken für dieselben Daten. Der Vorteil der Verwendung einer verteilten Datenbank besteht darin, dass sie Daten in einem kontinuierlichen Zustand speichert und so sicherstellt, dass sie ständig verfügbar sind.
Alles in einem Schlüsselwertspeicher ist sowohl ein Schlüssel als auch ein Wert. Column Family Stores sind der ideale Ort, um große Datenmengen zu speichern und zu verarbeiten, die auf eine Vielzahl von Maschinen verteilt sind. Dokumentdatenbanken enthalten im Allgemeinen Versionen von zuvor verwendeten Schlüsselwertsammlungen. Die Dokumente in einem halbstrukturierten Format werden in JSON-Dateien gespeichert. SQL und andere deklarative Abfragesprachen werden in Graphdatenbanken nicht verwendet. Auf diese Datenbanken kann nur über Datenmodelle, nicht über Datenbanken zugegriffen werden. RESTful-Schnittstellen sind in einer Reihe von NoSQL-Plattformen möglich.
Da es sich um eine multirelationale Datenbank handelt, ähnelt sie eher einer relationalen Datenbank als einer Graphdatenbank. Graphdatenbanken können mehrere Datentypen in derselben Datenbank verarbeiten und dabei ein einziges Backend verwenden. Multi-Modell-Datenbanken sind eine neue Art von NoSQL-Datenbanken, die in Zukunft an Popularität gewinnen werden. Rankings der beliebtesten Datenbanken und deren Fortschritt finden Sie unter http://db-engines.com/en/rankings.html.
Ist Amazon ein Nosql oder SQL?
SQL ist die bevorzugte Programmiersprache für die Entwicklung datenbankgesteuerter Anwendungen, und es stehen mehrere Tools zur Verfügung, die diesen Prozess unterstützen. Sie können Ad-hoc-DynamoDB-Aufgaben mithilfe der AWS Management Console, der AWS CLI oder der NoSQL WorkBench ausführen .