
NoSQL-Datenbank: Impala
Veröffentlicht: 2023-03-03NoSQL ist ein Begriff, der verwendet wird, um eine Datenbank zu beschreiben, die nicht die traditionelle, relationale Datenbankstruktur verwendet. Stattdessen sind NoSQL-Datenbanken oft darauf ausgelegt, eine einfachere, skalierbarere Lösung bereitzustellen.
Impala ist eine NoSQL-Datenbank, die entwickelt wurde, um eine schnelle, skalierbare Lösung für die Verwaltung großer Datenmengen bereitzustellen. Impala basiert auf dem Datenmodell von Google Bigtable und verwendet ein spaltenförmiges Speicherformat. Impala ist als Open-Source-Projekt verfügbar und wird von Cloudera unterstützt.
Apache Impala ist eine Open-Source-SQL-Abfrage-Engine, die auf einem Hadoop-Cluster installiert ist und Massive Parallel Processing (MPP) für auf dem System gespeicherte Daten durchführt. Das ursprünglich 2012 entwickelte Open-Source-Projekt ist als „Microsoft Formula 1“ bekannt.
Die Impala-Plattform ermöglicht es Benutzern, SQL-Abfragen mit geringer Latenz auf Hadoop-Daten durchzuführen, die in HDFS und Apache HBase gespeichert sind, ohne die Daten verschieben oder transformieren zu müssen.
Basiert Impala auf SQL?
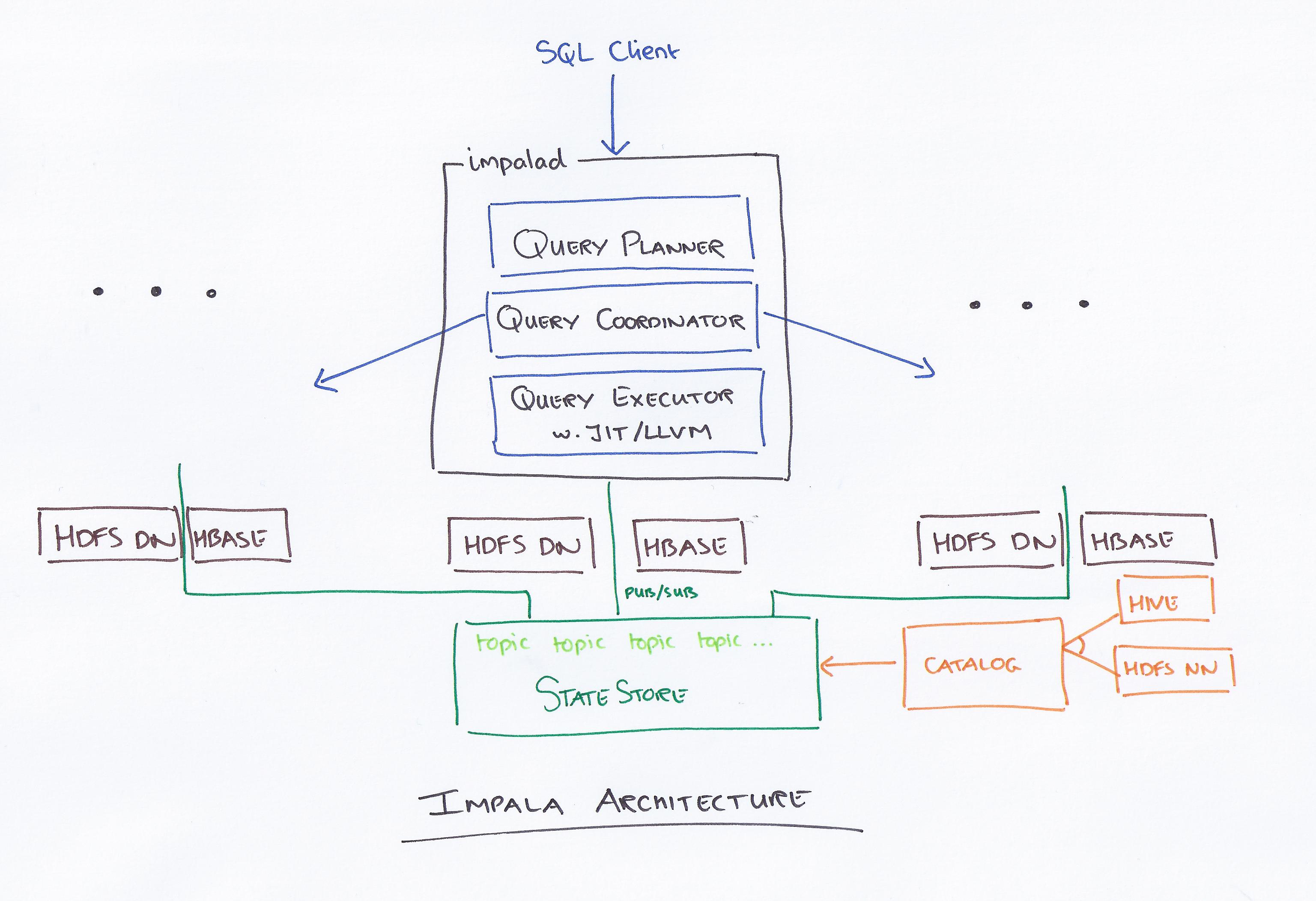
Impala ist eine SQL-basierte Abfrage-Engine, die auf Apache Hadoop läuft. Es ermöglicht Benutzern, in HDFS und HBase gespeicherte Daten mit SQL abzufragen. Impala bietet im Vergleich zu anderen Hadoop-Abfrage-Engines wie Hive und Pig eine hohe Leistung und geringe Latenz.
Die analytische MPP-Datenbank von Impala bietet branchenweit die kürzeste Time-to-Insight. Es ist in CDH integriert und kann über Cloudera Enterprise aufgerufen werden. MPP-Datenbanken für Apache Hadoop, wie z. B. Impala, verwenden HDFS, um schnellere Einblicke zu ermöglichen.
Impala ist eine Datenbank
Es ist eine Datenbank, die ich glaube.
Ist Impala ein Etl-Tool?
Impala ist kein ETL-Tool, sondern eine SQL-Abfrage-Engine, die verwendet werden kann, um SQL-Abfragen durchzuführen, nachdem Daten durch einen Prozess bereinigt wurden.
Wofür wird Apache Impala verwendet?
Mithilfe von SQL-ähnlichen Abfragen können wir mit Impala Daten aus einer Vielzahl von Quellen lesen. Apache Impala schneidet besser ab als Hive und andere SQL-Engines, wenn es um den Zugriff auf Daten geht, die im Hadoop Distributed File System gespeichert sind. Wir verwenden Impala, um Daten in Hadoop HBase, HDFS und Amazon S3 zu speichern.
19 Unternehmen, die Apache Impala in ihren Tech-Stacks verwenden
Apache Impala ist eine beliebte Datenverarbeitungs-Engine für eine Vielzahl großer Unternehmen. Berichten zufolge verwenden 19 Technologieunternehmen, darunter Stripe, Agoda und Expedia.com, Apache Impala. Die Impala-Plattform ist flexibel und effizient und kann große Datenmengen schnell und effektiv verarbeiten. Die weite Verbreitung dieses Tools zeigt, wie nützlich es ist und wie nützlich es in der Datenverarbeitung ist.
Was sind die Unterschiede zwischen Sql Hive und Impala?
Das Ziel von Hive ist es, lang andauernde Abfragen zu verarbeiten, die mehrere Transformationen und Verknüpfungen erfordern. Aufgrund ihrer geringen Latenz und der Fähigkeit, kleinere Abfragen zu verarbeiten, ist die Abfrageverarbeitungs-Engine von Impala ideal für interaktives Computing. Spark unterstützt neben kurz- und langfristigen Abfragen sowohl kurz- als auch langfristige Abfragen.
Hive eignet sich besser für Batch-Jobs mit langer Laufzeit
Der primäre Zweck der Werkzeuge ist nicht die Stapelverarbeitung. Hive eignet sich besser für langfristige Stapelverarbeitung als Impulsa, das kleinere Datensätze verarbeiten kann.
Ist Impala eine Datenbank
Ein Impala ist eine Datenbank, die Daten in einem Spaltenformat speichert. Es ist so konzipiert, dass es skalierbar ist und eine hohe Leistung für große Datenmengen bietet.
In der ersten Version von Impala werden die folgenden Kernspaltendatentypen unterstützt: STRING, VARCHAR, VARChar2, INT und FLOAT anstelle von Zahlen, und es wird kein BLOB-Typ unterstützt. Impala SQL-92 enthält einige Erweiterungen der SQL-Standards, aber nicht alle. Wenn Daten zu groß sind, um sie auf einem einzigen Server zu produzieren, zu bearbeiten und zu analysieren, bietet Impala eine bessere Leistung als andere Data Warehouses und ist skalierbarer. Es ist nicht erforderlich, den ursprünglichen Speicherort der Datendateien beim Laden von Impala zu entfernen, da es leicht ist. Der erste Schritt beim Erlernen von Leistungstests, Skalierbarkeit und Multi-Node-Clusterkonfigurationen besteht normalerweise darin, riesige Datenmengen zu sammeln. Cloudera Impala ist für das Laden und Massenlesen von Daten in großen Datensätzen optimiert, sodass Sie mit weniger mehr erreichen können. Die Multimegabyte-Blockgröße von HDFS ermöglicht es Impala, riesige Datenmengen parallel über mehrere vernetzte Server zu verarbeiten.
Anstatt normalisierte Indizes und den Zeit- und Arbeitsaufwand für deren Erstellung einzuplanen, erledigen Sie dies in Impala. Die Abfrage-Engine von Impala kann große Datenmengen verarbeiten, die aus Data Warehouses stammen. Es analysiert einen Cluster und verteilt Aufgaben auf Knoten, um die Menge der verbrauchten Ressourcen zu reduzieren. Die Partitionierung eines Data Warehouse ist ein vertrautes Konzept in Impala. Die Partitionierung reduziert die Festplatten-E/A und erhöht die Abfrageskalierbarkeit in Impala. Datendateien sind erforderlich, da Sie auf keine integrierten Tabellen in Impala zugreifen können. INSERT ist eine der verfügbaren Optionen.
Verwenden Sie eine Wertanweisung, um zwei Spielzeugtische zu erstellen. Wenn Sie Batch-orientierte Software verwendet haben, können Sie es versuchen. Sie können die SQL-on- Hadoop-Technologie in Ihre Apache Hive-Konfiguration integrieren. Die Hive-Tabellen in Impala werden nicht zeitaufwändig geladen oder konvertiert.
Impala: Ein leistungsstarkes Datenverwaltungstool für Hadoop
Die SQL-Syntax ist Benutzern von Impala vertraut, die in HDFS und Apache HBase gespeicherte Daten abfragen können. Auf diese Weise können Hadoop und Impulsa anstelle traditioneller relationaler Datenbanken verwendet werden. Darüber hinaus ist es dank seiner Funktionen ein leistungsstarkes Datenverwaltungstool. Darüber hinaus sind seine Fähigkeiten für große Datensätze beeindruckend und können mit großer Leichtigkeit damit umgehen.
Impala in Big Data
Impala ist eine Open-Source-MPP-SQL-Abfrage-Engine, die auf Apache Hadoop ausgeführt wird. Es bietet schnelle, interaktive SQL-Abfragen zu Daten, die in HDFS und HBase gespeichert sind. Impala wurde entwickelt, um die Leistung von Apache Hadoop zu verbessern, indem es eine schnelle, interaktive SQL-Schnittstelle für in HDFS und HBase gespeicherte Daten bereitstellt.
Impala, angeführt von Cloudera, ist ein neues Abfragesystem. Hadoop verfügt über HDFS und HBase, sodass dort gespeicherte Big Data auf PB-Ebene abgefragt werden können. Diese Technologie basiert auf Hive und Speicher für die Berechnung sowie unter Berücksichtigung von Data Warehouse und bietet Echtzeit-Batch-Verarbeitung und mehrfache gleichzeitige Verarbeitung. Ein Client sendet eine Abfrageanforderung an einen Knoten innerhalb eines Impalad-Netzwerks, wo eine Abfrage-ID für nachfolgende Client-Operationen zurückgegeben wird. Während des ersten Schritts des Erstellungsprozesses des Analysators wird ein eigenständiger Ausführungsplan (Einzelmaschinenplan, verteilter Ausführungsplan) generiert, und SQL wird ebenfalls ausgeführt, z. B. Änderungen der Join-Reihenfolge, Prädikat-Pushdowns usw. Alle Knoten bewahren eine Kopie der neuesten Metadateninformationen auf, um sicherzustellen, dass Sie nicht auf dem Laufenden bleiben. Bevor Sie Hadoop, Hive oder Impurbia verwenden, müssen Sie zunächst die erforderliche Datenverarbeitungssoftware installieren.

Die Konfigurationsdatei von Impala kann geändert werden. Jeder Knoten führt eine Konfigurationsänderung in Impala durch. Alle Knoten sind dafür verantwortlich, das MySQL-Treiberpaket mit einer Datenbank zu verbinden. Knoten ändern den Java-Pfad von Bigtop.
Ein Vergleich von Hive und Impala
Neben diesen drei großen gibt es auch ein paar kleinere Unterschiede. In Hive gibt es eine Teilmenge von HiveQL, während es in Implicit eine Teilmenge von HiveQL gibt. Hive und Impala werden jeweils für Data Warehousing und interaktive Abfragen verwendet. Hive ist im Gegensatz zu Impala nicht für Interactive Computing gedacht.
Was ist Impala in Hadoop
Impala ist eine Open-Source-SQL-Abfrage-Engine für Daten, die in einem Hadoop-Cluster gespeichert sind. Es wurde entwickelt, um schnelle, interaktive SQL-Abfragen zu Daten bereitzustellen, die in HDFS, HBase oder einer anderen Hadoop-Datenquelle gespeichert sind.
Impala verwendet eine breite Palette bekannter Hadoop-Komponenten . INSERT kann nur Daten schreiben, die von dem Typ sind, den Impala lesen kann, während SELECT Daten lesen kann, die von dem Typ sind, den Impala lesen kann. Bei Verwendung eines Avro-, RCFile- oder SequenceFile-Dateiformats werden die Daten in Hive geladen. Tabellenstatistiken und Spaltenstatistiken können zusätzlich zu Tabellen- und Spaltenstatistiken verwendet werden. Alle DDL- und DML-Anweisungen werden automatisch mit dem katalogisierten Daemon in Impala 1.2 und höher aktualisiert, wenn sie über den katalogisierten Daemon gesendet werden. Die Methode INVALIDATE METADATA gibt Metadaten für alle Tabellen im Metastore zurück, auf die zugegriffen wurde. Datendateien werden in Verzeichnissen für eine neue Tabelle gespeichert und unabhängig vom Dateinamen gelesen, wenn Impala ausgeführt wird.
Insgesamt schneidet Apache Hive als Data-Warehousing-Plattform gut ab, während Impala besser für Parallelverarbeitung geeignet ist. Der Hive ist fehlertolerant, der Impulsa hingegen nicht.
Apache Impala
Apache Impala ist eine schnelle, interaktive SQL-Abfrage-Engine für Apache Hadoop. Es ermöglicht Benutzern, SQL-Abfragen mit geringer Latenz auf in HDFS und Apache HBase gespeicherte Daten zu stellen, ohne dass Daten verschoben oder transformiert werden müssen.
Das Architekturkonzept von Impala ermöglicht es ihm, interaktive Abfragen mit HDFS effizienter als jede andere Abfrage-Engine zu verarbeiten. Hive ist aufgrund seiner Festplatten-I/O-Vorgänge viel langsamer, aber Apache ist viel schneller, weil es eine völlig andere Engine ist. Es gibt keinen Unterschied zwischen Impulsa und Presto, da Impulsa eine viel schnellere Technologie verwendet und Presto eine ähnliche Architektur verwendet. Wenn es um Parkettfeilen geht, schneidet Impala am besten ab. Bestimmen Sie anhand der Abfragen Ihrer Analysten, welche Daten Sie partitionieren sollten. Mit Compute Stats Statistics werden Ihre Abfragen viel einfacher, insbesondere wenn sie mehr als eine Tabelle (Joins) betreffen. Wir hatten viermal pro Woche einen Absturz des Impala-Katalogservers, und unsere Abfragen dauerten viel zu lange, bis sie abgeschlossen waren.
Darüber hinaus wirkt sich die Menge der von uns erstellten Dateien stark auf unsere Abfrageleistung aus. Infolgedessen begannen wir, unsere Partitionen zu verwalten und sie in der optimalen Dateigröße von ungefähr 256 MB zusammenzuführen. Es wird angegeben, dass jede Partition nur eine Datei hat (es sei denn, ihre Größe beträgt > 256 MB). Aus allen von Implizit unterstützten Datentypen sollte der am besten geeignete Spaltentyp ausgewählt werden. Verwenden Sie die Impala-Zulassungskontrolle, um die Anzahl der gleichzeitigen Abfragen oder den Y-Speicher zu begrenzen, auf die ein Benutzer zugreift. Wenn eine Abfrage länger als 30 Minuten dauert, gilt sie als tot.
Der beste Motor für Big Data: Impala
Die Impala-Engine ist eine Hadoop-Datenverarbeitungs-Engine, die speziell für große Cluster entwickelt wurde. Es verbraucht viel weniger Energie und verbraucht deutlich weniger Ressourcen als die standardmäßige MapReduce-Engine von Hadoop. Implizit verwendet das verteilte Dateisystem HDFS als primäres Datenspeichermedium und verlässt sich auf die Redundanz von HDFS, um Hardware- oder Netzwerkausfälle Knoten für Knoten zu verhindern. Datendateien, die Tabellendaten darstellen, werden physisch durch bekannte HDFS-Dateiformate und Komprimierungscodecs dargestellt.
Abfragemodul für parallele Verarbeitung
Eine Parallelverarbeitungs-Abfrage-Engine ist eine Art Datenbank-Engine, die für die parallele Verarbeitung von Abfragen ausgelegt ist. Dies kann durch die Verwendung mehrerer Prozessoren, mehrerer Kerne oder mehrerer Maschinen erfolgen. Die Parallelverarbeitung kann die Leistung einer Abfragemaschine erheblich verbessern, insbesondere bei komplexen Abfragen.
Ein Multiprozessor-Computer wird verwendet, um komplexe Abfragen in Ausführungspläne umzuwandeln, die gleichzeitig ausgeführt werden können, wodurch große Datenmengen auf einmal verarbeitet werden können. Für eine hohe Leistung ist eine effiziente Ausführung erforderlich, z. B. eine gute Abfrageantwortzeit oder ein hoher Abfragedurchsatz. Dies wird durch die Verwendung effizienter paralleler Ausführungstechniken und Abfrageoptimierung erreicht.
Parallele Verarbeitung: Die Zukunft von Etl?
Eine High-Level-Abfrage kann in einen Ausführungsplan umgewandelt werden, der von einem Mehrprozessorcomputer unter Verwendung einer parallelen Abfrageverarbeitung effizient ausgeführt werden kann. Die Parallelverarbeitung verwendet die Technik des Kombinierens paralleler und verteilter Daten sowie die verschiedenen Ausführungstechniken, die durch das parallele Datenbanksystem bereitgestellt werden. Die parallele Abfrageverarbeitung wird in ETL implementiert, indem der Satz von Datensätzen in jeder Quelltabelle, die der Übertragung zugewiesen ist, in Blöcke gleicher Größe aufgeteilt wird und dann der Datentransformationsprozess für jede Quelltabelle in einem Zyklus durchgeführt wird, wobei die Daten nacheinander Stück für Stück ausgewählt werden .