
Entscheidungsfaktoren für NoSQL-Datenbank-Shards
Veröffentlicht: 2023-02-13Wann Shard in einer NoSQL-Datenbank erfolgen soll, ist eine Entscheidung, die auf der Grundlage einer Reihe von Faktoren getroffen werden muss, einschließlich, aber nicht beschränkt auf: Datengröße und Wachstumsrate, Abfragelast und -komplexität, Verfügbarkeits- und Skalierbarkeitsanforderungen und Datenmodell. Es gibt keine allgemeingültige Antwort, und die Entscheidung muss von Fall zu Fall getroffen werden. Es gibt jedoch einige allgemeine Richtlinien, die befolgt werden können. Wenn der Datensatz klein und die Abfragelast nicht zu hoch ist, ist Sharding möglicherweise nicht erforderlich. In diesem Fall kann wahrscheinlich eine einzelne NoSQL-Datenbankinstanz die Last bewältigen. Wenn der Datensatz wächst und die Abfragelast zunimmt, kann Sharding erforderlich werden, um eine gute Leistung aufrechtzuerhalten. Das Datenmodell kann auch vorgeben, wann Shards ausgeführt werden sollen. Wenn die Daten so strukturiert sind, dass sie leicht in separate Partitionen aufgeteilt werden können, kann Sharding eine gute Option sein. Wenn das Datenmodell andererseits komplex und vernetzt ist, ist Sharding möglicherweise nicht möglich oder nicht die beste Option. Schließlich müssen Verfügbarkeits- und Skalierbarkeitsanforderungen berücksichtigt werden. Wenn die Daten hochverfügbar und jederzeit zugänglich sein müssen, kann Sharding erforderlich sein, um Redundanz bereitzustellen und Single Points of Failure zu eliminieren. Wenn Skalierbarkeit ein wichtiges Anliegen ist, kann Sharding helfen, die Last auf mehrere Server zu verteilen.
Wann sollte ich mit dem Sharding beginnen?
Es gibt keine endgültige Antwort auf die Frage, wann man mit dem Sharding beginnen sollte. Die Entscheidung hängt von einer Reihe von Faktoren ab, darunter die gespeicherte Datenmenge, die Rate, mit der Daten hinzugefügt werden, das erwartete zukünftige Wachstum des Datensatzes, das gewünschte Leistungsniveau und die verfügbaren Ressourcen. Im Allgemeinen sollte Sharding in Betracht gezogen werden, wenn der Datensatz zu groß ist oder zu schnell wächst, um effektiv von einem einzelnen Datenbankserver verwaltet zu werden.
Warum das Sharding Ihrer Mongodb für große Datensätze unerlässlich ist
Wann sollte ich mit dem Sharding von MongoDB beginnen? Wenn eine einzelne Datenbank eine große Menge wachsender Daten verarbeiten oder speichern kann, ist der Weiterverkauf eine gute Option. Eine Verzehnfachung der Datenbankspeicherkapazität verbessert die Leistung einer Anwendung. Auch dies erhöht die Komplexität Ihres Systems. Verbessert Sharding die Leistung? Die Verwendung von Hashing zur Verbesserung der Datenbankleistung war eine der ersten Methoden. Das Produkt hat sich aufgrund der jüngsten technologischen Fortschritte zu einem der besten entwickelt. Obwohl Daten das wertvollste Gut eines Unternehmens sind, erhalten Datenbanken mittlerweile mehr Aufmerksamkeit. Warum ist Sharding besser als Replikation? Wenn Sie Daten lesen können, die nicht die neuesten sind, kann die Replikation für die horizontale Skalierung von Lesevorgängen von Vorteil sein. In einem gemeinsamen Datenpool werden die Daten mit Hilfe eines gemeinsamen Schlüssels auf mehrere Server verteilt, was eine horizontale Skalierung ermöglicht. Die Wahl des richtigen Shard-Keys ist entscheidend. Warum teilen wir MongoDB? Mit MongoDB können Bereitstellungen mit einer großen Anzahl von Datensätzen und Operationen mit hohem Durchsatz mit Sharding unterstützt werden. Ein Datenbanksystem, das riesige Datenmengen enthält oder eine große Anzahl gleichzeitiger Benutzer hat, kann auf einem einzelnen Server schwierig zu verwalten sein. Es ist möglich, dass einem Server die CPU-Ressourcen ausgehen, wenn hohe Abfrageraten auftreten. Warum wird Sharding benötigt? Die Normalisierung bezieht sich auf die horizontale (zeilenweise) Datenbankpartition, während sich die epochale Partition auf die horizontale (zeilenweise) Partition bezieht. Die Daten-Shards werden auf diese Weise in kleinere, schnellere und einfacher zu verwaltende Teile sehr großer Datenbanken unterteilt. ist ein Beispiel dafür, wie verteilte Systeme erreicht werden können. Welche DB ist die beste für Sharding? Die Verwendung von Sharding, auch bekannt als horizontale Partitionierung, als Skalierungsmethode ist ein gängiger Ansatz für Datenbanken. Amazon RDS ist ein Cloud-basierter verwalteter relationaler Datenbankdienst, der zahlreiche Funktionen umfasst, die es einfach machen, Sharding über mehrere Clouds hinweg auszuführen.
Wird Sharding in Nosql benötigt?
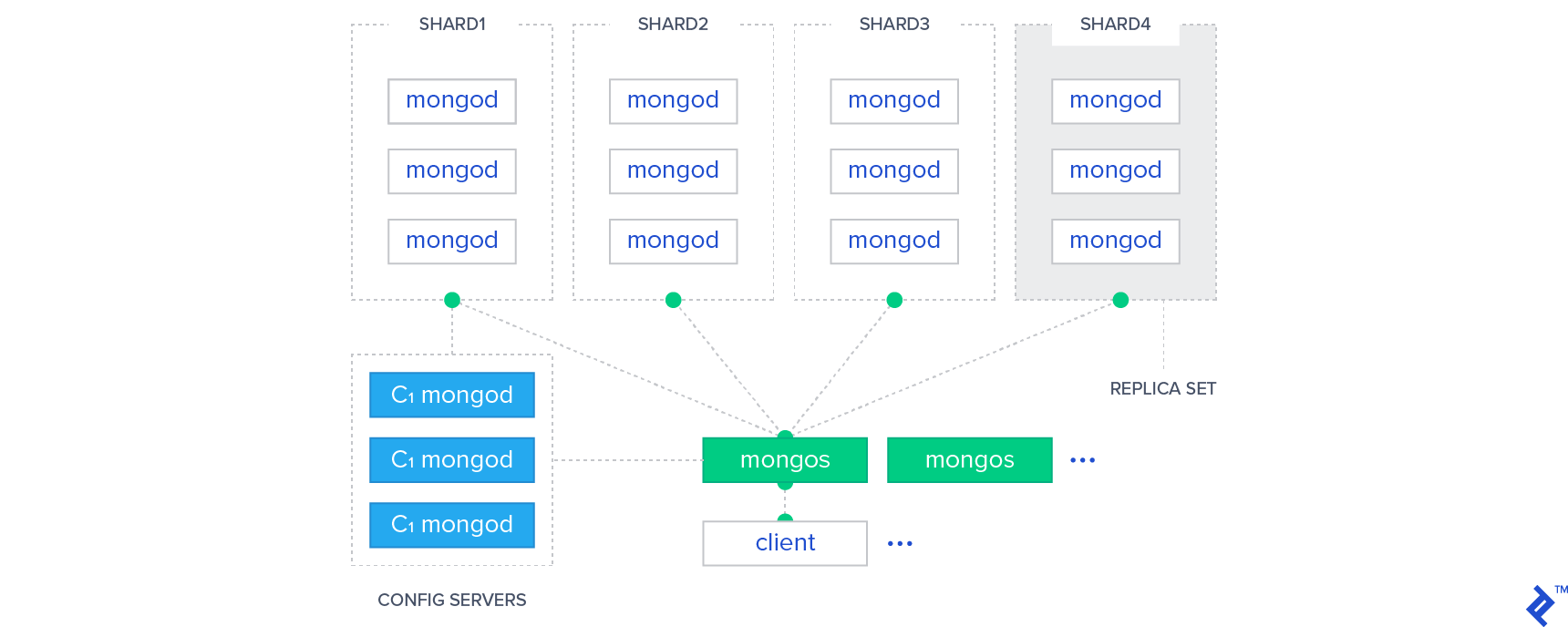
In NoSQL wird das Sharding-Muster zum Partitionieren von Daten verwendet. Partitionierung ist eine Methode, bei der jede Partition auf möglicherweise separaten Servern platziert wird, die über die ganze Welt verstreut sind. Durch die horizontale Skalierung können Benutzer problemlos an verschiedenen Punkten auf der ganzen Welt auf den Datensatz zugreifen.
MongoDB hat ein wichtiges Tool in seiner Datenbank, das als Sharding bekannt ist. Es kann verwendet werden, um die Leistung zu steigern, indem große Datensätze auf mehrere Server verteilt werden. Ein Datenelement auf einem Server wird mithilfe eines Shard-Schlüssels als Datenelement auf einem anderen Server identifiziert. Dadurch können Daten serverübergreifend kopiert werden, ohne sie neu indizieren zu müssen.
Ist Sharding die richtige Lösung für Ihre Datenbank?
Wenn die einzelne Datenbank Ihrer Anwendung eine große Menge wachsender Daten nicht verarbeiten oder speichern kann, ist das Speichern in einer Sharding-Instanz eine gute Option. Das Vorhandensein von Sharding verbessert die Datenbankleistung und skaliert die Anwendung. Dies führt jedoch zu einer zusätzlichen Komplexität Ihres Systems. Wenn Sie immer noch nicht sicher sind, ob Sharding die richtige Lösung für Sie ist, denken Sie daran, dass MongoDB auch horizontale Skalierung unterstützen kann.
Wann sollten Sie Mongodb teilen?
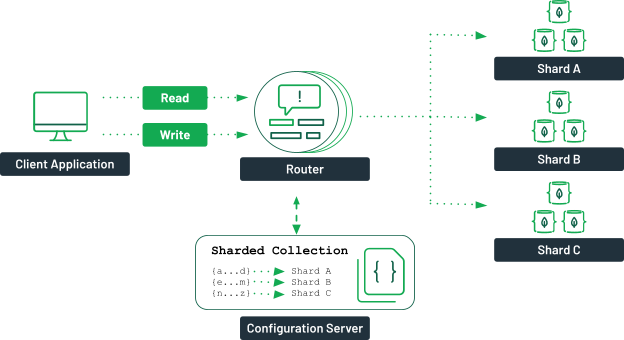
MongoDB sollte fragmentiert werden, wenn die Datengröße die Kapazität eines einzelnen Servers übersteigt und wenn eine hohe Abfrageleistung erforderlich ist.
Wann Sie Ihre Mongodb-Datenbank teilen sollten
Sollten Sie erwägen, Ihre MongoDB-Datenbank zu fragmentieren? Sie sollten mehrere Faktoren berücksichtigen, wenn Sie entscheiden, ob Sie einen Shard für Ihre MongoDB-Datenbank verwenden möchten oder nicht. Wenn Ihre MongoDB-Anwendung hohe Abfrageraten aufweist, ist es in erster Linie eine gute Idee, Sharding zu verwenden. Sraving kann auch helfen, die Datenbank bei Bedarf zu erweitern. Bevor Sie sich entscheiden, ob Sie Sharding verwenden möchten, sollten Sie dessen Nutzen und Kosten abwägen. Wie teilt man MongoDB? Wenn Sie Ihre MongoDB-Datenbank teilen möchten, empfehlen wir die Verwendung von Amazon Relational Database Service (Amazon RDS). Die Funktionen von Amazon RDS machen Sharding einfach in der Cloud zu verwenden und es hat auch das Potenzial zur Skalierung.
Warum sollten Sie eine Datenbank teilen?
Was ist Datenbank-Sharding ? Ein Beispieldatensatz kann mithilfe der Technik des Epochenwechsels auf mehrere Datenbanken verteilt werden, die dann auf mehreren Computern gespeichert werden. Die Gesamtspeicherkapazität des Systems wird durch die Aufteilung größerer Datensätze in kleinere Chunks und deren Speicherung in mehreren Datenknoten erhöht.
Ist Sharding die Antwort auf Ihre Datenbankprobleme?
Warum ist es notwendig, eine Datenbank zu fragmentieren? Sharding ist eine großartige Lösung, wenn die einzelne Datenbank in Ihrer Anwendung eine große Menge wachsender Daten nicht verarbeiten/speichern kann. Im Allgemeinen können Sie durch Skalieren der Datenbank die Leistung Ihrer Anwendung verbessern. Darüber hinaus erhöht es die Komplexität Ihres Systems. Was ist ein Shard in einer Datenbank? Das Ziel der Datenbankreplikation besteht darin, eine große Anzahl von Datensätzen in Partitionen oder Shards aufzuteilen. Jeder Knoten kann seine eigene Datenzeile in jedem Shard in Form von eindeutigen Zeilen speichern, die getrennt voneinander gespeichert werden. Das ursprüngliche Datenbankschema oder -design wird von allen Shards gemeinsam genutzt, aber die Knoten, auf denen die Shards ausgeführt werden, unterscheiden sich geringfügig. Können Sie einen SQL-Server zum Sharding verwenden? Mithilfe von Chunks kann ein großer Datensatz effektiver skaliert und verwaltet werden. Es gibt zahlreiche Methoden zum Aufteilen eines Datensatzes in Shards. Zum Sharding kann eine NoSQL- oder SQL-Datenbank verwendet werden. Können wir die MySQL-Datenbank fragmentieren? In einem Cluster werden Partitionsreihen (Cluster) automatisch über Knoten hinweg ausgeführt, sodass Datenbanken auf kostengünstiger Standardhardware horizontal skaliert werden können, um lese- und schreibintensive Workloads sowie SQL- und NoSQL-APIs direkt vom Server zu bewältigen. Ist Sharding nur für relationale Datenbanken möglich? Eine der beliebtesten Scale-Out-Methoden für relationale Datenbanken ist die Sharding-Methode der horizontalen Skalierung. Amazon Relational Database Service (Amazon RDS) ist ein verwalteter relationaler Datenbankdienst, der das Sharding in der Cloud aufgrund seiner umfangreichen Funktionen vereinfacht.

Warum brauchen wir Sharding in Mongodb?
Der Prozess der Verteilung von Daten auf mehrere Computer wird als Hashing bezeichnet. Mit MongoDB können Bereitstellungen mit großen Datensätzen und Hochgeschwindigkeitsvorgängen von der Verwendung von Sharding profitieren. Ein Datenbanksystem mit einer großen Datenmenge oder eine Anwendung, die eine große Anzahl von Anforderungen verarbeiten kann, kann möglicherweise schwierig auf einem einzelnen Server ausgeführt werden.
Brauchen wir Sharding in Nosql?
Datenbank-Sharding ist für die Skalierung von SQL- und NoSQL-Datenbanken erforderlich, die sowohl SQL- als auch NoSQL-Datenbanken sind. Wie der Name schon sagt, teilen wir die Datenbank in mehrere Teile (Shards) auf. Jeder Shard hat seinen eigenen Index, der verwendet wird, um zu bestimmen, welche Daten er speichert.
Die Vorteile von Sharding
Das Verteilen von Daten auf mehrere Server in einem Cluster wird als Sharding bezeichnet. Es ist möglich, die Leistung einer Datenbank zu verbessern, indem die Arbeit, die sie ausführen muss, auf mehrere Server verteilt wird.
Der MongoDB-Dienst verwendet einen Shard-Schlüssel, um Dokumente von einer Sammlung an eine andere zu verteilen. MongoDB unterteilt die Daten in Chunks, die entsprechend der Spannweite der Schlüsselwerte in nicht überlappende Bereiche unterteilt werden. Das MongoDB-Backend versucht, diese Chunks gleichmäßig auf die Cluster zu verteilen.
Es gibt keine einzige Möglichkeit, Cassandra zum Sharding zu verwenden. In Mongodb speichert jeder sekundäre Knoten alle Daten des primären Knotens, während in Cassandra nur wenige Schlüsselpartitionen von jedem sekundären Knoten aufbewahrt werden. Wenn Cassandra geshardet ist, kann es die gleichen Leistungsniveaus wie MongoDB erreichen, ohne dass ein sekundärer Knoten erforderlich ist.
Warum brauchen wir Sharding in relationalen Datenbanken?
Aufgrund der besten Daten- und Arbeitslastverteilung in einer gut konzipierten Datenbankarchitektur können alle Datenbank-Shards gleichmäßig verteilt werden. Jedes Mal, wenn eine Abfrage einen anderen Satz von Shards durchläuft, stimmt sie mit der Leistungserwartung überein.
Welche Db eignet sich am besten zum Sharding?
Datenbank-Sharding ist in Cassandra, HBase, HDFS, MongoDB und Redis möglich. MySQL, PostgreSQL, Memcached, Zookeeper und Sqlite sind nur einige der Datenbanken, die das Sharding von PostgreSQL und MySQL nicht nativ unterstützen. Wenn eine Datenbank keine integrierte Sharding-Logik unterstützt, muss sie in der Anwendung gespeichert werden.
Sharding in Nosql
Es gibt verschiedene Möglichkeiten, das Sharding in einer NoSQL-Datenbank anzugehen. Am gebräuchlichsten ist die Verwendung einer Hash-Funktion, um zu bestimmen, auf welchem Shard ein bestimmtes Datenelement gespeichert werden soll. Dies kann entweder auf Anwendungsebene oder auf Datenbankebene erfolgen. Ein weiterer Ansatz ist die Verwendung von bereichsbasiertem Sharding, bei dem Daten basierend auf dem Wertebereich, in den sie fallen, auf verschiedenen Shards gespeichert werden. Dies wird häufig für Dinge wie Zeitreihendaten verwendet. Es gibt auch ein paar andere, weniger gebräuchliche Ansätze, aber dies sind die beiden häufigsten.
Warum Sharding der Schlüssel zur Skalierung einer Cassandra-Datenbank ist
Beim Skalieren einer nosql-Datenbank ist der Schlüssel die Verwendung von Sharding. Die Datenbank wird in mehrere Teile partitioniert, die als Slabs bezeichnet werden, auf die dann von mehreren Computern aus zugegriffen werden kann. Das System kann größere Datensätze in kleineren Blöcken und Clustern von Knoten speichern, wodurch die Gesamtspeicherkapazität erhöht wird.
Insbesondere Sraving kann die Form von schlüsselbasiertem Sharding annehmen und die Verteilung von Daten über Knoten in Cassandra automatisieren. Anders ausgedrückt: Cassandra kann große Datensätze verarbeiten, ohne dass zusätzliche Hardware oder Software erforderlich ist.
Für welche Kategorie von Nosql-Datenbanken wird empfohlen, Daten nicht zu teilen?
Auf diese Frage gibt es keine endgültige Antwort, da dies von den spezifischen Anforderungen der Anwendung abhängt. Es wird jedoch im Allgemeinen empfohlen, Daten in Schlüsselwertspeichern oder dokumentorientierten Datenbanken nicht zu fragmentieren.
Nosql-Sharding vs. Partitionierung
Partitionierung und Sharding sind beides Methoden, um eine große Datenmenge in kleinere Teilmengen aufzuteilen. Die Partitionierung unterscheidet sich vom Sharding darin, dass Daten auf mehrere Computer aufgeteilt werden, anstatt sie auf sie zu verteilen. Die Partitionsfunktion einer Datenbankinstanz wird verwendet, um Teilmengen von Daten unter ihr aufzuteilen.
Skalieren Sie Ihre Datenbank mit Sharding
Nosql-Datenbanken können horizontal skaliert werden, indem das Schema repliziert und in Shards aufgeteilt wird. Beim Partitionieren von Datenbanken wird das Schema repliziert und dann basierend auf einer Schlüsselkennung auf einer separaten Datenbankserverinstanz in verschiedene Teile aufgeteilt, um die Last zu verteilen. Jede verteilte Tabelle enthält einen Shard-Schlüssel.
Große Datasets können verarbeitet werden, indem sie in Microservices aufgenommen und gespeichert werden. Es gibt zahlreiche Möglichkeiten, eine große Datenmenge in kleine Teile aufzuteilen. SQL- und NoSQL-Datenbanken können zum Kombinieren und Verwerfen von Daten verwendet werden.
Sowohl SQL- als auch NoSQL-Datenbanken zeichnen sich durch ihre Fähigkeit aus, Skalierung und Datenheterogenität zu verwalten, während SQL-Datenbanken von der Fähigkeit der Datenbank-Engine zur Partitionierung profitieren. Shrsiting ist eine effiziente Methode zur Verwaltung Ihrer Daten, unabhängig davon, ob Sie nach oben oder unten skalieren müssen.
Was ist eine Möglichkeit, dass eine verteilte Nosql-Datenbank normalerweise Daten fragmentiert?
Es gibt verschiedene Möglichkeiten, wie eine verteilte NoSQL-Datenbank Daten fragmentieren kann, aber ein gängiger Ansatz ist die Verwendung einer Hash-Funktion. Diese Funktion wird verwendet, um zu bestimmen, auf welchem Knoten in der Datenbank ein Datenelement gespeichert werden soll. Wenn ein neues Datenelement eingeht, wird die Hash-Funktion verwendet, um zu bestimmen, auf welchem Knoten es gespeichert werden soll. Wenn der Knoten bereits voll ist, werden die Daten an den nächsten Knoten in der Datenbank gesendet.
Die Scherbe in einer Datenbank
Was ist ein Shard in einer Datenbank?
Der Shard eines Datenbankservers ist eine Teilmenge von Daten, die auf diesem Server gespeichert sind. Eine Datensammlung, die als Shard bezeichnet wird, besteht aus gleichen Teilen. Da größere Datensätze auf mehreren kleineren Servern gespeichert werden können, können Clients schneller darauf zugreifen.
Mongodb-Splitter
Mongodb-Sharding ist ein Prozess zum Verteilen von Daten auf mehrere Computer. Es ist eine Möglichkeit, eine Mongodb-Datenbank zu skalieren, indem die Daten in kleinere Teile aufgeteilt und auf mehrere Server verteilt werden. Dies ermöglicht eine horizontale Skalierung der Datenbank, was bedeutet, dass dem System je nach Bedarf weitere Server hinzugefügt werden können, um den erhöhten Datenverkehr zu bewältigen.
Sharding Ihrer Datenbank
Es stehen verschiedene Sharding-Typen zur Verfügung, darunter Ranged/Dynamic, Algorithmic/Hashed, Entity/Relationship-based und Geography-based. Das Spannen der Daten in Bereiche und das Zuweisen von Servern zu jedem von ihnen erfolgt über dynamisches Sharding . Der Server wird je nach Größe des Arrays in andere Regionen verschoben, wenn dem Array Daten hinzugefügt werden. Algorithmisches/gehashtes Sharding unterteilt Daten in Buckets und weist jedem Bucket einen Server zu. Wenn die Daten dem Bucket hinzugefügt werden, wird dem Server ein Hash-Wert zugewiesen. Eine beziehungsbasierte Sharding-Methode unterteilt Daten in Entitäten und Beziehungen zwischen Entitäten. Jede Entität hat eine Liste aller Entitäten, mit denen sie verbunden ist. Geografiebasiertes Sharding unterteilt Daten in Regionen, weist jeder Region einen Server zu und teilt die Daten dann in Regionen auf.
Schlüsselbereich-Partitionsstrategie
Eine Partitionsstrategie für Schlüsselbereiche definiert, wie Daten in einer partitionierten Tabelle auf mehrere physische Partitionen verteilt werden. Der Schlüsselbereich basiert auf den Werten einer Partitionierungsspalte, und jeder Partition wird basierend auf den Partitionierungsschlüsseln ein Wertebereich zugewiesen. Diese Strategie wird häufig verwendet, um Daten gleichmäßig auf mehrere Server zu verteilen oder um sicherzustellen, dass Daten am selben physischen Ort gespeichert werden.
Bereichspartitionierung: Der Ansatz des Integration Service zur Datenverteilung
Der Integration Service, der Datenzeilen basierend auf einem Port oder einer Gruppe von Ports verteilt, die als Partitionsschlüssel definiert sind, verwendet Bereichspartitionierung, um Datenzeilen zu verteilen. Die Wertebereiche für jeden Port werden im folgenden Format angegeben. Als Ergebnis verwendet der Integration Service den Schlüssel und den Bereich, um Zeilen an die entsprechende Partition zu senden.
Der Integration Service verteilt Datenzeilen basierend auf einem Port oder einer Gruppe von Ports, die Sie als Partitionsschlüssel definieren, indem er die Bereichspartitionierung verwendet.
Wenn Sie neue Daten laden und alte Daten entfernen, ist dies eine großartige Möglichkeit. Der Bereichsaufteilungsprozess wird dadurch erleichtert. Das Rollout von Daten ist beispielsweise eine gängige Praxis, bei der Daten der letzten 36 Monate online gehalten werden.