
NoSQL-Datenbanken: Vor- und Nachteile
Veröffentlicht: 2022-11-16NoSQL-Datenbanken haben sich in den letzten Jahren zu einer beliebten Lösung zum Speichern und Verwalten von Daten entwickelt. Ein wesentlicher Vorteil von NoSQL-Datenbanken besteht darin, dass sie kein Schema benötigen, was die Datenverwaltung flexibler und einfacher machen kann. Einige Experten argumentieren jedoch, dass das Fehlen eines Schemas auch ein Nachteil sein kann, da es die Abfrage und Analyse von Daten erschweren kann. Darüber hinaus argumentieren einige, dass das Fehlen eines Schemas zu Dateninkonsistenzen führen kann. Also was denkst du? Macht das Fehlen eines Schemas NoSQL-Datenbanken eher vor- oder nachteilig?
Benötigen NoSQL-Datenbanken Schemas? Das NoSQL-Feld ist in letzter Zeit zu einem heißen Thema in der Welt der Datenbankverwaltung geworden. SQL hatte in seiner jüngsten Inkarnation Schwierigkeiten, die Lücke zu füllen, die NoSQL weitgehend gefüllt hat. Das Fehlen eines Schemas ermöglicht es NoSQL-Datenbanken, Daten in einer Vielzahl von Datenmodellen zu speichern. Das Wichtigste, woran Sie beim Schreiben von Code denken müssen, ist, ihn von den anderen Funktionen, denen er dient, fernzuhalten, damit er alle erfüllen kann. Der nächste Schritt besteht darin, die Primärschlüssel der Datenbank zu entwerfen, bei denen es sich um die Daten handelt, die abgefragt werden. Die Anforderungen für Geschäftsentitäten, Benutzeranforderungen und Abfragemuster werden alle berücksichtigt.
Dieser Schritt setzt voraus, dass Sie wissen, wie NoSQL-Datenbanken ihre Primärschlüssel verwenden, um sie zu implementieren. Eine NoSQL-Datenbank , die nicht als Schema deklariert ist, kann zu einer Plattform der Anarchie werden, was zur Erstellung einer NoSQL-Datenbank führt. Es gibt mehrere Anwendungen für Schemas. Das Design der Indizes wird wie in den vorherigen Schritten erforderlich sein und je nach Anzahl der Aktien stark variieren.
Datenwissenschaftler und Ingenieure für maschinelles Lernen können NoSQL-Datenbanken verwenden, um Daten, Metadaten von Modellen, Funktionen und Betriebsparameter zu speichern. Data Engineers hingegen können sie verwenden, um bereinigte Daten zu speichern und abzurufen.
MongoDB ist als NoSQL-Datenbank als schemalos bekannt, da es kein starres, vordefiniertes Schema wie eine relationale Datenbank erfordert. Beim Schreiben von Daten erzwingt das Datenbankverwaltungssystem (DBMS) ein partielles Schema, das Sammlungen und Indizes explizit auflistet.
Was ist Schema? Ein Schema ist ein Objekt, das die Struktur und den Inhalt Ihrer Daten im JSON-Format angibt. Die BSON-Schemas von Atlas App Services, die Erweiterungen des JSON-Schemastandards sind, können verwendet werden, um das Datenmodell Ihrer Anwendung zu definieren und Dokumente zu validieren, wenn sie erstellt, geändert oder gelöscht werden.
Das Systemschema ist eine Komponente der MySQL-Datenbank. Der MySQL-Server muss alle Daten verfolgen, die in den darin enthaltenen Tabellen gespeichert sind. Das MySQL-Schema enthält Data-Dictionary-Tabellen, die Datenbankobjekt-Metadaten und Systemtabellen speichern, die in anderen Operationen verwendet werden.
Was ist Schema in der Nosql-Datenbank?
Es gibt keine formale Definition dessen, was ein Schema in einer NoSQL-Datenbank ist, aber im Allgemeinen kann es als eine Struktur oder ein Format für die in der Datenbank gespeicherten Daten betrachtet werden. Dies kann so einfach wie eine einzelne Tabelle mit einigen Spalten sein, oder es kann sich um eine komplexere Struktur handeln, die mehrere Tabellen und Beziehungen zwischen ihnen enthält. Es gibt keinen richtigen oder falschen Weg, um ein Schema zu definieren, und es ist Sache des einzelnen Datenbankdesigners, zu entscheiden, was für seine spezielle Anwendung am besten funktioniert.
Datenbankschemata sind die Blaupausen von Datenbanken. Die Art und Weise, wie Daten in einer relationalen Datenbank organisiert werden, wird durch dieses Modul definiert. Dokumentstrukturen sind wichtige Werkzeuge für das Dokumentenmanagement in einem Datenbankmanagementsystem (DBMS). Datenbankschemata werden in drei Typen eingeteilt: konzeptionell, logisch und physisch. Sternschemata stellen Datenbanken auf verschiedenen Ebenen dar, während Schneeflockenschemata Datenbanken auf verschiedenen Ebenen darstellen. Ein Sternschema kann aus einer einzelnen Tabelle mit einer umgebenden Dimensionstabelle bestehen. Es wird allgemein angenommen, dass ein Sternschema wie ein Stern aussieht, während ein Schneeflockenschema einer Schneeflocke zu ähneln scheint.
Entwickler verwenden häufig Schemas, da sie es ihnen ermöglichen, eine Datenbank zu entwerfen, bevor sie erstellt wird. Darüber hinaus stellen sie sicher, dass die Datenbank nach der Erstellung korrekt und genau erstellt wird. Die Korrektheit einer Datenbank ist entscheidend für ihren Betrieb, da Benutzer auf ihre Daten zugreifen und von ihnen profitieren können. Ein Schema kann zum Erstellen eines beliebigen Datenbanktyps verwendet werden. Datenbankschemata werden beispielsweise in relationalen Datenbanken verwendet, um Daten zu organisieren. Ein Schema oder eine Tabellenstruktur ist die Grundstruktur einer relationalen Datenbank, die von einem DBMS verwendet wird. Eine Tabelle enthält Dateien auf die gleiche Weise wie Ordner in einem Dateisystem. Jede Tabelle enthält Informationen über eine bestimmte Gruppe von Objekten. Es kann verwendet werden, um eine nicht relationale Datenbank sowie ein Schema zu erstellen. Eine nicht relationale Datenbank wäre beispielsweise eine Datenbank, die kein Schema verwendet. Nicht relationale Datenbanken sind schwieriger zu erstellen und zu warten als relationale Datenbanken, aber sie können flexibler sein.
Ist das Nosql-Schema kostenlos?
Auf diese Frage gibt es keine endgültige Antwort, da sie weitgehend von der jeweiligen NoSQL-Datenbank abhängt. Im Allgemeinen sind NoSQL-Datenbanken jedoch schemafreier als ihre relationalen Gegenstücke, was bedeutet, dass sie flexibler sind und weniger Vorausplanung in Bezug auf die Datenstruktur erfordern. Dies kann in bestimmten Situationen von Vorteil sein, bedeutet aber auch, dass möglicherweise mehr Dateninkonsistenzen auftreten.
Können Nosql-Datenbanken mit diesem Schemakonzept umgehen?
Ja, NoSQL-Datenbanken können gut mit Schemakonzepten umgehen. Tatsächlich sind viele NoSQL-Datenbanken speziell so konzipiert, dass sie schemalos sind, was sie flexibler und einfacher zu handhaben macht. Natürlich gibt es immer Kompromisse, und schemalose Datenbanken sind möglicherweise nicht für jedes Projekt die richtige Wahl. Aber für viele Anwendungen können sie gut passen.
NoSQL-Datenbanken sind so konzipiert, dass sie sich vom relationalen Datenbankmodell lösen, indem sie sich von Zeilen und Spalten lösen. Viele Leute verwechseln NoSQL-Datenbanken damit, dass sie überhaupt kein Datenmodell haben. In einem Schema ist es wichtig zu beschreiben, wie Daten organisiert werden. Datenmodelle für jeden der vier Haupttypen von NoSQL-Datenbanken werden sich natürlich weiterentwickeln, um diese Unterschiede widerzuspiegeln. Infolgedessen wird das Schemadesign für eine Anwendung im Laufe der Zeit schrittweise erfolgen. Bei der Entscheidung für eine NoSQL-Datenbank für Ihre Anforderungen ist es wichtig, das Datenmodell zu berücksichtigen, für das Sie sie verwenden möchten. Wie der Name schon sagt, werden die Daten in jedem Dokument in Paaren von Feldern und Werten gespeichert, wobei eine Vielzahl von Datentypen und Datenstrukturen zum Hinzufügen von Werten verwendet werden.
Für die Abfrage steht eine breite Palette von Feldwerttypen zur Verfügung, und es wurde eine Reihe leistungsstarker Abfragesprachen entwickelt, um sie bei der Auswahl zu unterstützen. Eine NoSQL-Datenbank enthält einen Schlüssel und zugehörige Spalten in Zeilen, die als Spaltenfamilien bezeichnet werden. Die zugrunde liegende Struktur von NoSQL-Datenbanken wird verwendet, um Daten in jedem der vier Haupttypen zu speichern. Trotzdem können die Details der Datenorganisation sehr flexibel sein, auch wenn sie offiziell als „schemalos“ bezeichnet werden. Dokumentdatenbanken, Datenbanken mit breiten Spalten und Diagrammdatenbanken verwenden normalerweise eine Reihe von Abfragesprachen.
Welche Art von Schema wird für die Nosql-Datenbank verwendet?
Diese Funktion wird von NoSQL-Datenbanken bereitgestellt, was eine schnellere und iterativere Entwicklung ermöglicht. NoSQL-Datenbanken zeichnen sich durch die Verarbeitung sowohl strukturierter als auch unstrukturierter Daten aus, da sie ein flexibles Datenmodell verwenden.
Welche Art von Datenbank unterstützt Schemas?
Schema ist eine Komponente von SQL, die für fast alle relationalen Datenbanken erforderlich ist.
Benötigt Mongodb ein Schema?
Da MongoDB kein starres, vordefiniertes Schema erfordert, wird es eher als NoSQL-Datenbank denn als relationale Datenbank betrachtet.
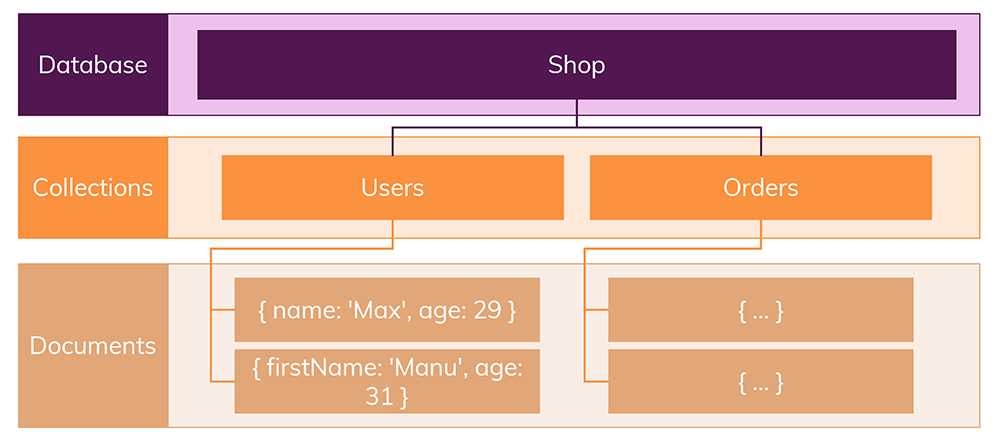
Nosql-Schema
Das Nosql-Schema ist ein Datenbankschema , das nicht auf dem traditionellen tabellenbasierten relationalen Modell basiert. Stattdessen basiert es auf einem flexibleren dokumentenorientierten Modell. Dadurch eignet es sich gut zum Speichern von Daten in einem nicht relationalen Format wie JSON oder XML.
Bei NoSQL-Technologien ist das Design von größter Bedeutung, da sie nicht die einzigen sind, die alle Anwendungsfälle abdecken, wie z. B. RDBMS. Es ist entscheidend, dass wir eine Reihe von NoSQL-Datenbanken entwickeln, die wirklich kundenspezifisch sind. Dieser Artikel versucht, eine Vorlage für die Entwicklung eines NoSQL-Datenmodells basierend auf einer gemeinsamen Methodik bereitzustellen. Eine NoSQL-Implementierung muss basierend auf abfragegesteuerten Prozessen entworfen werden – in diesem Fall kann sich die Abfrage je nach Anforderung ändern – daher muss die NoSQL-Implementierung iterativ modifiziert werden. Der erste Schritt besteht darin, Container mithilfe eines Abfragemusters zu identifizieren. Wir verwenden diese Funktion, um alle Abfrageanforderungen und Attributattribute von Entitäten zu aggregieren und später die Data Governance zu erleichtern. Dies erfordert den Einsatz agiler Prozesse wie Anforderungserhebung und User-Story-Analyse.
Die Denormalisierung kann durch Techniken wie Embedding/Flatting sowie Referenzierung erreicht werden. Die Denormalisierung von Attributen in spaltenorientiertem NoSQL erfolgt durch Erstellen einer flachen Liste von Spalten (optional gruppiert nach Spaltenfamilien) aus der zweiten Entität. Die hier beschriebenen Funktionen werden mithilfe spezieller Datentypstrukturen wie Listen, Sets, Maps und eingebetteten Strukturen erstellt. Der Dokumentschlüssel besteht aus einer Wertkette mit einer Verkettung von Typfeldern in Form einer Hash-Map, die auf dem Cluster gespeichert ist. In einigen NoSQL-Datenbanken wie HBase sind Sekundärindizes verfügbar. In jedem Fall sollten Indizes so konzipiert sein, dass sie ähnlich wie Data Mining und unkritische/datenintensive Abfragen funktionieren.
Die vielen Verwendungsmöglichkeiten eines Schemas
SQL-Datenbanken bestehen aus SQL-Anweisungen und -Schemas, die die Struktur der Daten in diesen Anweisungen beschreiben. Der Datenbankadministrator kann steuern, wie auf Daten über ein Schema zugegriffen wird. Benutzer können das Schema auch verwenden, um zu steuern, wie Daten vom Datenbankadministrator behandelt werden.
Ein SQL-Datenbankschema ist eine Reihe von Regeln, die die Struktur von Daten beschreiben. Die Regeln können vom Datenbankadministrator verwendet werden, um den Zugriff auf Daten einzuschränken. Die Regeln können auch vom Datenbankadministrator verwendet werden, um die Daten einzuschränken, auf die er zugreifen kann.
Nosql-Datenmodell
Was ist das NoSQL-Datenmodell? Im Gegensatz zu einem relationalen Datenbankmanagementsystem (RDBMS) ist es nicht auf DBMS angewiesen, um es zu verstärken. Folglich gibt es keinen expliziten Weg, um zu bestimmen, wie Daten zusammenhängen – wie alle Elemente miteinander verbunden sind.
8 Datenmodellierungsmuster in Redis: Ein umfassendes E-Book ist eine umfassende Studie zur Datenmodellierung in NoSQL. Das Buch befasst sich mit acht Datenmodellen, die Entwickler verwenden können, um moderne Anwendungen ohne die Probleme zu erstellen, die mit traditionellen relationalen Datenbanken verbunden sind. Eine NoSQL-Datenbank kann zwei separate Tabellen oder Sammlungen an einem gemeinsamen Ort speichern, wobei eine Tabelle in die andere eingefügt wird. Sie können alle relevanten Daten finden und ihre Beziehung leichter verstehen, indem Sie ihrer Beziehung folgen. Jede Tabelle von NoSQL bietet ihre eigene Ansicht als Teil ihrer eigenen Anwendung. Wenn Sie Eins-zu-Viele-Beziehungen modellieren möchten, betten Sie unbegrenzte Listen (dh Listen bekannter Dimensionen) in separate Sammlungen ein. In diesem Fall ist das Produkt das einzige; Die Variablen sind die vielen Rezensionen, Autorennamen, Erscheinungsdatum, Bewertung und Kommentare.
Ein Muster folgt der Entwicklung von Viele-zu-Viele-Beziehungen mit unbegrenzten Seiten. Jedes Produkt in einer relationalen Datenbank muss in einer separaten Tabelle gespeichert werden. Mit dem Redis-Stack können Sie Sammlungstypen anhand ihrer Typfelder unterscheiden. Das Bucket Pattern eliminiert Overhead, indem es Ihnen ermöglicht, Zeitreihendaten kontinuierlich zu aggregieren und zu speichern. Das Revisionsmuster hat das Potenzial, in einer Vielzahl von Situationen verwendet zu werden, in denen Echtzeitdaten erforderlich sind. Diese Muster können verwendet werden, um die Komplikationen gemeinsamer Operationen in NoSQL zu reduzieren. Dieses Muster ist besonders nützlich, wenn es mit umfangreichen JOIN-Vorgängen wie Personalwesen, CMS, Produktkatalogen und sozialen Netzwerken verwendet wird.
Ein relationales Datenbankmanagementsystem (RDBMS) kann dieses Modell nicht replizieren. Daten können auf einer Festplatte, im Arbeitsspeicher oder beidem gespeichert werden. Die Redis Launchpad-Website enthält eine Reihe von Redis- und NoSQL-Anwendungen.
Die unterschiedlichen Datenmodelle von Nosql-Datenbanken
Dokumentdatenbanken wie MongoDB verwenden keine Schemas, die meisten anderen NoSQL-Datenbanken jedoch schon. Die Daten in diesen Datenbanken sind einfache Textdateien, die zum Erstellen von Dokumenten verwendet werden können. MongoDB hat eine Dateierweiterung, die als „.mongo“ bekannt ist, während die meisten anderen Dokumentdatenbanken eine Dateierweiterung haben, die als „.Json“ oder „. XML. Eine Sammlung von Dateien ähnelt einer Tabelle in einer relationalen Datenbank, außer dass die Daten in diesen Dateien normalerweise in Sammlungen unterteilt sind. Jedes Dokument in einer Sammlung wird durch einen eindeutigen Schlüssel identifiziert und kann in einer Sammlung auf dieselbe Weise angezeigt werden wie jedes andere Dokument in einer Sammlung. Schlüsselwertspeicher sind eine Art NoSQL-Datenbankdatenmodell. Ein Schlüsselwertspeicher ist eine Art Datenbank, in der ein Schlüsselpaar und ein Wert zusammen gespeichert werden. Bevor Sie dem Schlüsselwertspeicher ein Dokument hinzufügen können, müssen Sie zuerst den Schlüssel für das Dokument suchen und seinen Wert in das entsprechende Feld eingeben. Eine Datenbank mit breiten Spalten ist ein weiteres Datenmodell, das in NoSQL-Datenbanken verwendet wird. Eine Datenbank mit breiten Spalten speichert Daten in Tabellen, die größer sind als die Standard-SQL-Tabelle. Wenn Sie Daten organisieren möchten, die nicht sauber in Zeilen und Spalten organisiert sind, können Sie eine Datenbank mit breiten Spalten verwenden. Eine Datenbank mit breiten Spalten könnte beispielsweise Daten in einer Tabelle mit der folgenden Gliederung enthalten. Beschreiben Sie den Artikel. Ich denke, ich bin sehr glücklich, einen sehr netten Mann kennengelernt zu haben. Es ist eine Freude, mit dem Mädchen zusammen zu sein. Graphdatenbanken sind das letzte Datenmodell, das in NoSQL-Datenbanken verwendet wird. Daten in Diagrammen werden in Diagrammdatenbanken in Datenstrukturen gespeichert. Die Knoten und Kanten in einem Graphen sind so angeordnet, dass sie eine Einheit bilden. Ein Knoten ist ein einzelnes Dokument, während eine Kante eine Verbindung zwischen ihm und dem Rest darstellt. All diese Datenmodelle haben mehrere Vor- und Nachteile. Ein Schlüsselwertspeicher ist einfach zu verwenden, kann jedoch nicht zum Durchführen von Transaktionen verwendet werden. Eine breitspaltige Datenbank ist schwieriger zu verwenden als eine einspaltige Datenbank, bietet jedoch eine größere Datenspeicherung und Transaktionsunterstützung. Eine Graphdatenbank hingegen kann mehr Daten speichern und komplexere Beziehungen zwischen Objekten bereitstellen, da sie schwieriger zu verwenden ist.

Nosql-Datenbank-Design-Tool
Es gibt heute viele Nosql-Datenbank-Design-Tools auf dem Markt. Jedes Werkzeug hat seine eigenen Stärken und Schwächen, daher ist es wichtig, das richtige Werkzeug für die jeweilige Aufgabe auszuwählen. Zu den beliebtesten Nosql-Datenbankdesign-Tools gehören MongoDB, Couchbase und Cassandra.
Damit eine NoSQL-Datenbank erfolgreich ist, muss sie zunächst ausgewählt werden. Da eine NoSQL-Datenbank nicht relational ist, ist sie flexibler als eine SQL-Datenbank. Die Geschäftsdatenentitäten, auf die zugegriffen werden soll, müssen zunächst von Datenarchitekten und -entwicklern katalogisiert werden. Der erste Schritt beim Entwerfen von Anwendungen besteht darin, die Schlüssel und Indizes zu definieren, die es ihnen ermöglichen, Daten effizienter abzufragen. Mit NoSQL-Datenbanken sind Hochverfügbarkeit und geringe Latenz garantiert. Durch die Nutzung von Partitionsdaten können Datenarchitekten und Betreiber zukünftiges Wachstum planen, indem sie die Last auf mehrere Knoten verteilen. Erstellen Sie einen Partitionsschlüssel, der sich in Zukunft wahrscheinlich nicht ändern wird und mit dem nur sehr wenige partitionsübergreifende Abfragen generiert werden können.
Welches Tool wird für das Nosql-Datenbankdesign verwendet?
Hackolade, DbSchema und Cassandra Data Modeler sind einige der NoSQL-Datenbankschema- Designtools, die verwendet werden können. Das visuelle Schemadesign von Hackolade eignet sich für eine Vielzahl von NoSQL-Datenbanken. DbSchema konvertiert zuvor veröffentlichte NoSQL-Datenbanken in Schemata.
Was ist Nosql-Datenbankdesign?
Das Hauptziel von NoSQL-Suchdatenbanken besteht darin, analytische Leistung für halbstrukturierte Daten bereitzustellen. Datenmodelle sind Datenmodelle, die in Software eingebaut sind. Demnach normalisiert das relationale Modell Daten in Tabellen, die aus Zeilen und Spalten bestehen. Tabellen, Zeilen, Spalten, Indizes und Beziehungen zwischen Tabellen und anderen Datenbankelementen werden alle in einem Schema angegeben.
Die Nosql-Datenbanken von Google sind ideal für Big Data
Die NoSQL-Datenbankdienste von Google sind insofern einzigartig, als sie sehr große und dynamische Datensätze verarbeiten können, ohne dass ein festes Schema erforderlich ist. Dadurch können sie ein breites Aufgabenspektrum bewältigen, darunter Echtzeit-Ereignisverarbeitung, Datenanalyse und die Erstellung von Suchmaschinen. Die Relational Database Services (RDS) von Amazon sind ein umfassendes Tool-Set, das die Entwicklung datenbankgestützter Anwendungen vereinfacht. SQL wird von all diesen Tools verwendet. Die AWS Management Console, die AWS CLI oder die NoSQL WorkBench sind alle für die Arbeit mit DynamoDB und die Durchführung von Ad-hoc-Aufgaben verfügbar.
Nosql vs. SQL
SQL ist eine Programmiersprache, die in Verbindung mit einer relationalen Datenbank ausgeführt wird. Relationale Datenbanken modellieren Daten als Datensätze in Zeilen und Tabellen mit logischen Verbindungen zwischen ihnen. SQL wird normalerweise anstelle von NoSQLDBMs verwendet, bei denen es sich um nicht relationale Datenbanken handelt, für deren Funktion SQL nicht erforderlich ist.
Die Grundlage aller Teilbereiche der Data Science sind Daten. Ein Datenbankverwaltungssystem (DBMS) wird normalerweise verwendet, um die von Ihnen benötigten Daten zu speichern. Wenn Sie mit dem DBMS interagieren und kommunizieren möchten, müssen Sie seine Sprache verwenden. DBMS (Distributed DBMS)-Abfragen werden an die Verwendung von SQL (Structured Database Language) gerichtet. Ein weiterer Begriff, der in letzter Zeit im Bereich der Datenbanken aufgetaucht ist, sind NoSQL-Datenbanken. Datenbank NoSQL-Datenbanken speichern keine Informationen in Tabellen und Datensätzen. Anstelle einer Datenspeicherstruktur wird sie speziell für jede Anwendung entworfen und optimiert.
Es gibt vier Arten von Datenbanken: spaltenorientierte, dokumentorientierte, Schlüssel-Wert-Paare und Diagrammdatenbanken. Die MongoDB-Datenbank ist ein Beispiel für eine dokumentenorientierte Datenbank in Python. Eine NoSQL-Datenbank ermöglicht es Ihnen, wie der Name schon sagt, Ihre Datenstruktur freier zu ändern. SQL-Datenbanken hingegen haben eine starrere Struktur und einen weniger flexiblen Datentyp. Daraus lässt sich schließen, dass SQL und NoSQL die besten ersten Schritte für Anfänger sind. Jeder von ihnen hat seine eigenen Vor- und Nachteile. Treffen Sie Ihre Entscheidung also auf der Grundlage Ihrer Daten, ihrer Anwendung und der Vorteile des Verfahrens für Sie. Am Ende ist SQL nicht besser als NoSQL oder irgendetwas anderes. Auf Basis Ihrer Daten können Sie die beste Entscheidung treffen.
SQL-Datenbanken hingegen dürften derzeit weiterhin das beliebteste Format zum Speichern und Abrufen von Daten sein.
Designprinzipien für Nosql-Datenbanken
Die Entwurfsprinzipien für NoSQL-Datenbanken betonen eher Datenflexibilität als starre relationale Schemata. Duplikation und Denormalisierung können bei der Entwicklung eines NoSQL-Frameworks berücksichtigt werden. Da NoSQL-Datenbanken keine Daten zwischen Tabellen austauschen, ist das erneute Speichern von Datenelementen akzeptabel.
Die RDBMS-Denormalisierung kann verwendet werden, um ein Verständnis des relationalen Paradigmas zu erlangen. Es ist vorteilhaft, dynamische Entitäten und halbstrukturierte Aggregate in NoSQL-Datenbanken zu modellieren, da sie halbstrukturiert modelliert werden können. Anstatt Entitäten und Beziehungen zu modellieren, sollten Sie NoSQL in Bezug auf Hierarchie und Aggregate modellieren. Die Denormalisierung fährt Ihre Datenbank effektiv zu einer NoSQL-kompatiblen Datenbank in RDBMS herunter. Wenn Sie ein Aggregat von Aggregaten benötigen, müssen Sie Code verknüpfen, und wenn Sie nur einen Teil eines Aggregats benötigen, müssen Sie es analysieren. Sie müssen so schnell wie möglich ein Verständnis für Ihre Beziehungen entwickeln.
Nosql-Dokument
NoSQL-Datenbanken werden immer beliebter, da sie viel mehr Flexibilität bei der Organisation und dem Zugriff auf Daten bieten als herkömmliche relationale Datenbanken. Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht die traditionelle tabellenbasierte Struktur einer relationalen Datenbank verwendet. Stattdessen verwendet es ein flexibleres, schemaloses Datenmodell, das eine einfachere Skalierung und eine effizientere Nutzung von Ressourcen ermöglicht.
Dokumentorientierte Datenbanken sind im Gegensatz zu herkömmlichen Spalten/Zeilen-Datenbanken jetzt ein XML-basiertes Format zum Speichern von Daten. Die halbstrukturierten Daten in RDBMSs sind schwieriger zu erfassen; in diesem Fall kann es schwierigere Herausforderungen bewältigen. Dokumentenspeicher ermöglichen es agilen Softwareentwicklern, schneller zu arbeiten, indem sie zu einer natürlichen und flexiblen Lösung werden. Wenn Sie die ausdrucksstarke Abfragesprache verwenden, können Sie auf vielfältige Weise Abfragen mit facettenreicher Indizierung durchführen. Durch die Möglichkeit, ACID-Transaktionen durchzuführen, können Sie das gleiche Sicherheitsniveau wie in einer relationalen Datenbank beibehalten. Ihre Daten werden skalierbarer und belastbarer, wenn Sie verteilte Systeme verwenden. Da jedes Dokument eine unabhängige Einheit ist, ist es einfacher, es über Server zu verteilen und den Verlust von Datenlokalitäten zu vermeiden.
Es verwendet eine intuitive und praktische Modellierung im Gegensatz zu relationalen Datenbanken, die schneller gelesen werden. Die Datenqualität wird geringer und die Tabellen starr. Da es in relationalen Datenbanken kein natives Scale-out gibt, müssen Sie teure Scale-up-Systeme kaufen, um Ihre herkömmliche Datenbank zu partitionieren (Shard). Dokumentenorientierte Datenbanken haben unterschiedliche Arten von Dokumenten und können mit optionalen Feldern eingerichtet werden. Der strukturelle Aufbau jedes Dokuments ist identisch, aber die Felder sind unterschiedlich. Jedes Dokument in der Liste hat eine eindeutige ID, sodass Sie es hinzufügen, ändern, löschen und abfragen können. Dokumentbesitzer sind im Allgemeinen für verschlüsselte eingekapselte Daten (oder Informationen) in einem Format und Format verantwortlich, das mit der Absicht des Dokuments übereinstimmt.
Dokumentenorientierte Datenbanken sind in ihrer Struktur weitaus flexibler als andere Datenbanken. Wenn eine Abfrage durchgeführt wird, werden Informationen direkt aus dem Dokument und nicht aus Spalten in der Datenbank abgerufen. Die einzigen Datenfelder, die einem Datensatz hinzugefügt werden müssen, sind diejenigen, die für ihn in der Dokumentenablage relevant sind.
Mongodb: Eine dokumentbasierte Nosql-Datenbank
Dokumentbasierte NoSQL-Datenbanken umfassen MongoDB.
True Nosql
Auf diese Frage gibt es keine endgültige Antwort, da sie von den spezifischen Anforderungen der zu erstellenden Anwendung oder des zu erstellenden Systems abhängt. Im Allgemeinen sind echte nosql-Datenbanken jedoch solche, die nicht dem traditionellen relationalen Modell folgen und stattdessen einen flexibleren schemalosen Ansatz verwenden. Dies kann sie einfacher skalieren und widerstandsfähiger gegen Datenkorruption machen.
Während eines Vorstellungsgesprächs für Softwareentwickler erwähnen die Kandidaten häufig NoSQL sowie SQL, das nicht skalierbar ist. Dies sind die wichtigsten Schlagworte, die sie auf Konferenzen oder von potenziellen Arbeitgebern hören. Stimmt es wirklich, dass SQL nicht skaliert? Lassen Sie mich kurz die Denkweise hinter NoSQL und SQL erläutern. Da NoSQL-Datenbanken beim Zusammenführen von Daten keine Ressourcen verschwenden, werden sie manchmal als No-Joins-Datenbanken bezeichnet. Das Schlüsselskalierbarkeitskonzept in diesem Fall ist, dass der Schlüssel der einzige ist, der auf Ihre Daten zugreifen kann (z. B. user_id, um Benutzerinformationen zu erhalten). Bei Tausenden von Servern (sogenannte Shards) muss die Last (CPU, Arbeitsspeicher) nicht auf sie verteilt werden.
Eine NoSQL-Lösung ist sehr einfach zu implementieren, eine komplexere erfordert jedoch eine separate Implementierung. Mit einem Schlüssel können Sie Ihre relationale Datenbank effektiv skalieren, indem Sie Ihre Last fragmentieren. SPHR-Datenbanken, die bei den FAANG-Unternehmen (Facebook, Amazon, Apple, Netflix, Google, Microsoft usw.) immer beliebter werden, wurden zum Aufbau ihrer Datenbanken verwendet. Das DynamoDB-Programm bietet Ihnen etwas Ähnliches wie Atomarität und Dauerhaftigkeit in einem Maßstab, der sowohl atomar als auch dauerhaft ist. Infolgedessen sollten Sie wegen des CAP-Theorems immer die vollständige Konsistenz vergessen. Wenn Sie eine globale Reichweite erreichen wollen, müssen Sie zuerst diese Probleme überwinden. Eine NoSQL-Datenbank kann immer einen neuen Index auf eine neue Spalte erstellen, aber auch einfügen.
Die CPU-Optimierung ist ein besonderes Merkmal von NoSQLDBs. Das SQL-Programm führt eine Optimierung des Speicherplatzes mithilfe von drei Frameworks von Drittanbietern (3NFs) durch. Der Schlüssel zum Erfolg bei No. SQL (und allgemein hoher Skalierbarkeit) ist das Verständnis Ihrer Zugriffsmuster.
Die Vorteile von Nosql-Datenbanken
Die Datenbankfunktionalität in NoSQL-Datenbanken hat im Laufe der Zeit aus verschiedenen Gründen an Popularität gewonnen. Sie sind ideal für die Verwaltung großer Mengen verteilter Daten, da ihnen jegliche SQL-Funktionen (Structured Referencing Language) fehlen. Darüber hinaus sind sie heute die am weitesten verbreiteten Datenbanken der Welt.
Nosql-Anarchie
Nosql-Anarchie ist ein Geisteszustand, in dem man glaubt, dass es keiner zentralisierten Autorität oder Regierungsbehörde bedarf, um die Ordnung aufrechtzuerhalten. Dieser Glaube basiert auf der Vorstellung, dass Menschen von Natur aus in der Lage sind, sich selbst zu regieren, und dass wir niemanden brauchen, der uns sagt, was wir tun sollen, um harmonisch zu leben.
Eine relationale Datenbank organisiert Ihre Daten in verschiedenen Tabellen, von denen jede mit einer gemeinsamen Variablen verknüpft ist. Die SQL-Programmiersprache wird am häufigsten zum Codieren und Anfordern von Daten aus relationalen Datenbanken verwendet. Bei Daten müssen wir eine spezielle Programmiersprache verwenden, die sowohl für die Datenanalyse als auch für die Datenverarbeitung verwendet werden kann. Da relationale Datenbanken nicht für jede Situation die beste Wahl sind, gibt es neue Möglichkeiten, Daten zu speichern. Diese Ideen werden in zwei Typen eingeteilt: NoSQL, das bequemer und schneller ist, und Non-NoSQL, das anpassungsfähiger ist. Datenbankrelationale Datenbanken haben eine viel langsamere Zeit zum Abschließen als NoSQL-Datenbanken. Dieser Geschwindigkeitsvorteil kann auf der gleichen Ebene einer einzelnen Operation und innerhalb eines Systems als Ganzes realisiert werden.
Joins werden in der NoSQL-Technologie nicht verwendet, da sie in ihrer Struktur nicht vorhanden sind. Wenn ein Datenpunkt denormalisiert wird, wird er automatisch repliziert. Allerdings ist NewSQL nicht für jede Situation geeignet und eine vielversprechende Entwicklung. Viele professionelle Software, die Big Data ausführt, erfordert eine Vielzahl von Datenbanken, um richtig zu funktionieren. Daten können mithilfe der In-Memory-Technologie in viel schnellerem RAM gespeichert werden als auf herkömmlichen Festplatten.