
NoSQL-Datenbanken und uneinheitliche Daten
Veröffentlicht: 2023-03-03Uneinheitliche Daten in NoSQL sind Daten, die nicht mit dem Schema der Datenbank übereinstimmen. Dies kann passieren, wenn die Daten nicht wohlgeformt sind, wenn sie nicht normalisiert sind oder wenn sie gemäß den Regeln der Datenbank nicht gültig sind. Uneinheitliche Daten in NoSQL können Probleme mit der Leistung der Datenbank verursachen und auch zu Datenverlust führen.
Was ist eine nicht-relationale Nosql-Datenbank?
Eine nicht relationale Datenbank ist eine Datenbank, die sich nicht auf das tabellarische Schema einer Standarddatenbank stützt. Nicht relationale Datenbanken hingegen verwenden ein Speichermodell, das auf die spezifischen Anforderungen des zu speichernden Datentyps zugeschnitten ist.
Datenbanksoftware, die für die Cloud entwickelt wurde, bietet Vorteile wie größere Skalierbarkeit, Leistung und Datenmodellflexibilität als herkömmliche relationale Datenbanken . Datenbanktechnologien wie NoSQL wurden entwickelt, um extrem flexibel und einfach zu verwenden zu sein, sowie nicht spezifisch für den tabellenbasierten Ansatz. Alle Datentypen, strukturiert und unstrukturiert, können einfach gehandhabt und skaliert werden, um sie kostengünstig zu speichern. Wenn es darum geht, Systeme zu erstellen, die das Kundenerlebnis personalisieren, sind NoSQL-Datenbanken die beliebteste Wahl. Einer der Hauptunterschiede zwischen einer NoSQL-Datenbank und einer relationalen Datenbank ist ihre Skalierbarkeit. Neben NoSQL-Datenbanken haben Sie die Möglichkeit, eine auszuwählen, die Ihren Daten und Zielen am besten entspricht. Eine Graphdatenbank ist ein Datenspeicher, der eine Graphmetapher verwendet, um Datenbeziehungen zu verbinden.
Datenbanken mit mehreren Modellen werden sowohl auf dem NoSQL- als auch auf dem RDBMS-Markt immer beliebter. NoSQL-Datenbanken wurden entwickelt, um dezentrale Systeme zu unterstützen, die auf Cloud-Anwendungen abzielen. Eine NoSQL-Datenbank bietet in den meisten Fällen die folgenden Vorteile gegenüber anderen Datenbankverwaltungssystemen: Sie erfordert kein vordefiniertes Schema. Sie können die Datentypen und -felder im Handumdrehen ändern. Wenn NoSQL-Datenbanken verwendet werden, stellen sie sicher, dass Daten immer verfügbar sind, indem sie Kopien davon über mehrere Server replizieren. Es wird verwendet, um eine NoSQL-Datenbank auf zwei Arten zu replizieren: primär/sekundär und Peer-to-Peer. Die APIs für jedes NoSQL-Datenmodell, wie z. B. Schlüsselwert-, Dokument-, Tabellen- und Diagrammmodelle, sind ihre eigenen.
RDBMSs sind zum Lesen, Schreiben und Verteilen von Daten konzipiert, während NoSQL-Datenbanken zum Lesen, Schreiben und Verteilen von Daten konzipiert sind. MongoDB unterstützt beispielsweise Schreib- und Lesevorgänge auf allen Knoten in einem NoSQL-Cluster wie Cassandra. Viele der NoSQL-Prinzipien, wie verteilte Systemarchitektur und SQL, werden jetzt in newSQL-Datenbanken verwendet.
NoSQL-Datenbanken können auch vertikal skaliert werden, um einer größeren Anzahl von Benutzern gerecht zu werden. Die Replikations- und Fehlertoleranzmechanismen sind zwei wichtige Möglichkeiten, um Skalierbarkeit zu erreichen. Dadurch können Daten auf mehreren Servern gespeichert werden, um die Wahrscheinlichkeit eines Ausfalls zu verringern.
Auch eine NoSQL-Datenbank wird stark nachgefragt. Sie haben eine geringe Ausfallrate und halten hohen Belastungen stand. Aufgrund ihrer geringen Latenz und ihres geringen Durchsatzes eignen sie sich hervorragend für Anwendungen mit hohen Durchsatzanforderungen.
Die Vorteile nicht relationaler Datenbanken
Welche Vorteile hat es, keine relationalen Datenbanksysteme zu verwenden?
Die Verwendung einer nicht relationalen Datenbank gegenüber einer relationalen Datenbank bietet zahlreiche Vorteile. Eine nicht relationale Datenbank ist die beste Wahl für eine schnelle Anwendungsentwicklung. Es ist bequemer, Daten darin zu speichern, weil sie häufig schneller laufen und eine höhere Geschwindigkeit haben. Sie sind jedoch anpassungsfähiger und schneller zu handhaben, sodass sie problemlos verwaltet werden können.
Was ist ein Datentyp in Nosql?
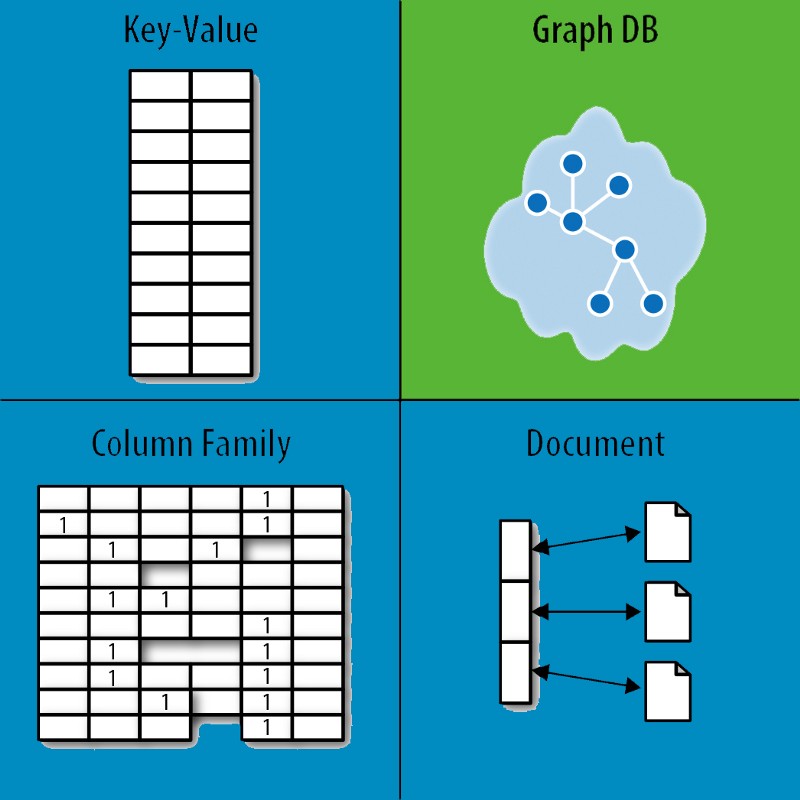
Als Alternative zur herkömmlichen SQL-Datenbank wird ein NoSQL-System bezeichnet. SQL-Datenbanken und NoSQL-Datenbanken sind sehr unterschiedliche Datenbanken. Sie haben ihr Datenmodell auf andere Weise erstellt als herkömmliche Tabellenmodelle mit Zeilen und Spalten, die in relationalen Datenbankverwaltungssystemen (RDBMS) verwendet werden.
Eine NoSQL-Datenbank besteht aus vier Typen: Schlüsselwertspeicher, Dokumentspeicher, spaltenorientierte Datenbanken und Diagrammdatenbanken . Eine relationale Datenbank kann ein Problem nicht mit irgendeiner Art von Lösung lösen. OrientDB ist beispielsweise eine Datenbank, die NoSQL- und Multi-Model-Typen kombiniert. Es gibt zahlreiche Entitätstypen und Tabellenverknüpfungsoptionen für eine große relationale Datenbank. Alle Entitäten (Personen) werden in einer Reihe über mehrere Spalten verteilt dargestellt. Die Spalten werden separat in einer Spaltendatenbank gespeichert, was die Suche erleichtert, wenn nur wenige Spalten betroffen sind. Der Index zeichnet Zeilen und Spalten in Daten, während die Spaltendatenbank Zeilen und Spalten in Daten darstellt.
Ein Schlüsselwertspeicher ist im Gegensatz zu einer NoSQL-Datenbank am wenigsten komplex. Sie können alltägliche Dokumente so speichern, dass sie leicht abgefragt und berechnet werden können, und sie speichern Dokumente so, wie sie sind. Normalisierung ist für Dokumentspeicher nicht wichtig, solange die Daten korrekt strukturiert sind. Das Ziel von grafischen Datenbanken ist es, Beziehungen zwischen Entitäten einfacher nachzuverfolgen. Graphdatenbanken bestehen aus zwei Hauptkomponenten: Daten und Struktur. Die Entität als Ganzes. Eine Kante ist eine Eigenschaft zweier Objekte, die durch Linien dargestellt werden. Dokumentenspeicher und Schlüsselwertspeicher halten sich an BASE, während Graphdatenbanken wie Neo4j behaupten, ACID aufrechtzuerhalten.
Flexible Datenspeicherung mit Json
Da JSON-Dokumente flexibel und einfach zu verwenden sind, sind sie ein beliebter Datentyp in NoSQL-Datenbanken. JSON ist eine Art der Datenspeicherung, die einer Tabellenkalkulation ähnelt, außer dass sie in Zeilen und Spalten und nicht in Zeilen und Spalten gespeichert wird. Dies ist ideal zum Speichern halbstrukturierter Daten, die kein spezielles Organisationsverfahren erfordern.
Sind Nosql unstrukturierte Daten oder halbstrukturierte Daten?
Eine NoSQL-Datenbank eignet sich typischerweise für die Verarbeitung von halbstrukturierten Daten, vollständig unstrukturierten Daten, Dokumenten, Diagrammen oder dynamischen Schemata. Während herkömmliche RDBMS stark strukturierte Daten verarbeiten können, tun NoSQL-Datenbanken dies normalerweise auf halb- oder vollständig strukturierter Ebene.
Es gibt viele verschiedene Arten von Daten, von Tabellenkalkulationen über Text- und Video- bis hin zu Audiodateien. Strukturierte Daten sind eine Art von Daten, die vordefiniert wurden, damit sie auf eine bestimmte Art und Weise im Speicher gespeichert werden können. Da sie kein vordefiniertes Datenmodell enthalten, werden unstrukturierte Daten nicht in einer relationalen Datenbank gespeichert. Der Begriff unstrukturierte Daten bezieht sich auf unstrukturierte Daten, die unstrukturiert sind, aber Metadaten enthalten, die es Benutzern ermöglichen, eine teilweise oder hierarchische Struktur zu identifizieren. Wissenschaftler und Ingenieure, die maschinelles Lernen oder künstliche Intelligenz verwenden, extrahieren Bedeutungen aus dieser Art von Daten mit Techniken, die sowohl effizient als auch tiefgreifend sind. Eine halbstrukturierte Datendatei enthält E-Mails und andere Dokumente, die dasselbe Format haben, aber Metadaten enthalten, die es Benutzern ermöglichen, auf Informationen auf einer bestimmten Ebene zuzugreifen. In diesem Artikel sehen wir uns einige reale Beispiele für jeden Datentyp an und erörtern ihre primären Anwendungen in modernen Organisationen.

Strukturierte Daten werden typischerweise in einer Datenbank gespeichert, und auch Data Warehouses gehören dazu. Da ihnen ein definiertes Schema fehlt, das für ein bestimmtes Attribut befolgt werden muss, werden unstrukturierte Daten in einer Data Lakes-Datenbank oder einer nicht relationalen Datenbank gespeichert. Moderne NoSQL-Datenbanken wie MongoDB werden verwendet, um halbstrukturierte Daten (mit Struktur oder Hierarchie) auf irgendeine Weise zu speichern.
Diese Art von Datenbank bietet Vorteile wie eine schnellere Entwicklung und ein flexibleres Datenmodell, was sie zu einer beliebten Wahl macht. MongoDB, die führende NoSQL-Lösung , ist besonders gut darin, unstrukturierte Daten zu archivieren. Infolgedessen speichert sein Dokumentdatenmodell alle zugehörigen Daten in einem einzigen Dokument, das weitaus flexibler ist als ein starres relationales Datenbankmodell. Daher ist MongoDB eine ausgezeichnete Wahl für unstrukturierte und halbstrukturierte Daten.
Die vielen Vorteile halbstrukturierter Daten
Halbstrukturierte Daten lassen sich, wie der Name schon sagt, in keine der folgenden Kategorien einordnen: Struktur, Menge oder Zusammensetzung. Die beiden Arten von Daten können als gemischt und übereinstimmend betrachtet werden. Die Arten von halbstrukturierten Daten, die gespeichert werden können, sind JSON, XML und Text.
Nosql-Datenbanken
Eine NoSQL-Datenbank bietet einen Mechanismus zum Speichern und Abrufen von Daten, der lockerere Konsistenzmodelle als herkömmliche relationale Datenbanken verwendet. NoSQL-Datenbanken sind oft skalierbarer und bieten eine bessere Leistung.
Im Gegensatz zu herkömmlichen Datenbanken sind NoSQL-Datenbanken flexibler. NoSQL-Datenbanken speichern Daten in derselben Datenstruktur wie andere Datenbanktypen, z. B. Dokumente. Eine nicht-relationale Datenbank kann aufgrund ihrer geringen Relationalität zur Verwaltung großer und typischerweise unstrukturierter Datensätze verwendet werden. Datenbank NoSQL-Systeme benötigen keine Verbindung von Tabellen. Mit NoSQL-Datenbanken können Sie eine Vielzahl von Datenstrukturen speichern, was sie für Datenanalysen, soziale Netzwerke und mobile Apps nützlich macht. Jeder Datenbanktyp hat mehrere Vorteile, aber NoSQL und relationale Datenbanken werden in großer Zahl von Unternehmen verwendet. Dokumentendatenbanken enthalten Daten als Dokumente, die bei der Verwendung in Anwendungen miteinander synchronisiert werden.
Dokumentendatenbanken werden häufig von Content-Management-Systemen sowie Benutzerprofilen verwendet. Die Informationen werden in großen Datenbanken in Spalten gespeichert, sodass Benutzer einfach auf bestimmte Spalten zugreifen können. Apache HBase und Apache Cassandra sind beispielsweise zwei Beispiele für diese Art von Datenbanken. Eine Graphdatenbank verwaltet und speichert ein Netzwerk von Verbindungen zwischen Graphelementen. Da die Daten nicht auf der Festplatte, sondern im Arbeitsspeicher gespeichert werden, kann schneller auf sie zugegriffen werden als bei herkömmlichen, festplattenbasierten Datenbanken. Es ist vorteilhaft, eine auf Microservices basierende Anwendung zu haben, da sie die Notwendigkeit eines einzigen, gemeinsam genutzten Datenspeichers für mehrere Anwendungen eliminiert. Dadurch kann IBM eine große Auswahl an NoSQL- und NoSQL-Datenbanken für eine Vielzahl von Anwendungen anbieten. Die IBM Data Management Platform for MongoDB Enterprise Advanced ist eine Komponente der IBM Cloud Pak for Data Suite. Apache CouchDB, PouchDB und andere beliebte Web- und Mobilentwicklungsbibliotheken werden alle von dem Dienst unterstützt, der Teil eines Open-Source-Ökosystems ist.
Was ist der beste Weg, um ein Schema für eine NoSQL-Datenbank zu erstellen? Beim Erstellen eines Schemas für eine NoSQL-Datenbank kann die native Struktur der Datenbank als Ausgangspunkt dienen. Zusätzlich können Sie das Schema mit Hilfe eines Schema-Editors erstellen.
Nosql-Datenbanken: Vor- und Nachteile
NoSQL-Datenbanken werden manchmal mit SQL-Datenbanken verglichen, die häufiger von Unternehmen verwendet werden. NoSQL-Datenbanken sind auch nützlich für Anwendungen, die Daten auf andere Weise speichern, als SQL verarbeiten kann.
Dokumentendatenbanken können beispielsweise Daten im JSON- oder XML-Format speichern. Beim Speichern von Daten in Schlüsselwertspeichern müssen zwei Schlüsselwertpaare vorhanden sein. Daten werden in Spalten mit unterschiedlicher Breite in Wide-Column-Speichern gespeichert, was sie ideal zum Speichern von Daten macht, die nicht gut definiert sind oder einen schnellen Zugriff erfordern. Daten können in Graphdatenbanken gespeichert werden, um Beziehungen zwischen verschiedenen Entitäten durch Anzeigen von Graphen darzustellen.
SQL-Datenbanken hingegen sind nicht so leistungsfähig wie NoSQL-Datenbanken. Darüber hinaus sind SQL-Datenbanken deutlich teurer und können nur eine begrenzte Anzahl von Transaktionen verarbeiten. Infolgedessen werden unstrukturierte Daten, die oft schwierig in einer relationalen Datenbank zu speichern sind, eher von diesen Systemen verarbeitet.
Es gibt jedoch einige Einschränkungen für NoSQL-Datenbanken. SQL-Datenbanken sind klar definiert und viel besser für mehrzeilige Transaktionen geeignet, während diese Datenbanken möglicherweise nicht ganz so gut geeignet sind. Außerdem sind sie schwieriger zu erlernen als SQL-Datenbanken.
Datenspeicher
Datenspeicher sind Aufbewahrungsorte für Daten, auf die Computer zugreifen können. Sie können in zwei Haupttypen unterteilt werden: aktive Datenspeicher, die zum Speichern von Daten verwendet werden, die aktiv von Anwendungen verwendet werden, und passive Datenspeicher, die zum Speichern von Daten verwendet werden, die nicht aktiv von Anwendungen verwendet werden. Datenspeicher können weiter in zwei Untertypen unterteilt werden: relationale Datenspeicher, die Daten in einem tabellarischen Format speichern, und nicht relationale Datenspeicher, die Daten in einem nicht tabellarischen Format speichern.
Was versteht man unter Datenspeicher?
Ein Datenspeicher ist eine Verbindung, die zwischen zwei oder mehr Datenspeichern besteht, unabhängig davon, ob die Daten in einer Datenbank oder in einer oder mehreren Dateien gespeichert sind. Der Datenspeicher, oder er könnte die Datenquelle für einen Prozess sein, oder er könnte die Quelle der Staging Data-Ergebnisse eines Prozesses für einen Datenspeicher sein.
Die Bedeutung des Primärspeichers
Es ist der primäre Speicher des Computers, der Daten, Programme und Anweisungen speichert, die gerade verwendet werden. Aufgrund des primären Speichers des Motherboards können Daten extrem schnell gelesen und geschrieben werden. Ein Server ist ein Computer, der Daten von mehreren Clients in einem Netzwerk empfängt und speichert. Es wird für den langfristigen Zugriff auf Dateien auf einer Festplatte gespeichert. Speicher kann als Komponente eines Serversystems integriert oder vom Server getrennt werden.
Gängige Graph-Datenbankmodelle
Es gibt drei übliche Graph-Datenbankmodelle: das Property-Graph-Modell, das Ressourcenbeschreibungs-Framework-Modell und das Triple-Store-Modell. Das Eigenschaftsgraphmodell ist das beliebteste Modell und wird von vielen Graphdatenbanken verwendet, einschließlich Neo4j. Das Ressourcenbeschreibungs-Rahmenmodell ist ein Standardmodell zum Speichern von Daten in einer Graphdatenbank und wird von Datenbanken wie AllegroGraph verwendet. Das Triple-Store-Modell ist ein einfaches Modell, das von vielen Graphdatenbanken, einschließlich Virtuoso, verwendet wird.
Mongodb: Eine Graph-Datenbank?
MongoDB ist eine Graphdatenbank.