
NoSQL-Datenbanken: Big Table
Veröffentlicht: 2023-01-04NoSQL-Datenbanken werden aufgrund ihrer Flexibilität, Skalierbarkeit und Leistung immer beliebter. Eine NoSQL-Datenbank benötigt kein vordefiniertes Schema und kann Daten in jedem Format speichern. Dies macht es ideal für Anwendungen, die große Datenmengen speichern müssen, die sich ständig ändern. Big Table ist eine Art NoSQL-Datenbank, die zum Speichern großer Datenmengen entwickelt wurde. Big Table wird von vielen großen Organisationen wie Google, Facebook und Amazon verwendet. Big Table ist hochgradig skalierbar und kann Milliarden von Zeilen und Millionen von Spalten verarbeiten. Big Table ist auch sehr schnell und kann Echtzeitzugriff auf Daten bieten.
Google hat eine Reihe allgemein verfügbarer Updates für seinen Datenbankdienst Cloud Bigtable veröffentlicht. Durch die neuen Updates steht nun bis zu fünfmal so viel Speicherplatz pro Node zur Verfügung. Google hat außerdem verbesserte Autoscaling-Funktionen hinzugefügt, die es einem Datenbankcluster ermöglichen, je nach Bedarf automatisch zu wachsen oder zu schrumpfen. Eine neue CPU-Auslastungsmetrik und Cluster-Gruppen-Routing ermöglichen mehr Transparenz darüber, wie die Ressourcen einer Anwendung verwendet werden. Aufgrund der Trennung von Rechenleistung und Speicherung kann jede Art von Ressource bei Bigtable separat skaliert werden. Dank der neuen Funktionen können Benutzer jetzt Hochverfügbarkeitsbereitstellungen einfach verwalten und das Workload-Management verbessern.
NoSQL ist eine beliebte Wahl zum Speichern großer Datenmengen. Diese Art von Datenbank wird heute bei Internetunternehmen immer beliebter. Befürworter von NoSQL-Lösungen sagen, dass sie eine einfachere Skalierbarkeit und eine höhere Leistung bieten als herkömmliche Datenbanken.
Bigtable ist eine Art NoSQL-Datenbankdienst , der sowohl von Entwicklern als auch von Datenbankadministratoren verwendet werden kann. BigQuery ist ein Hybrid, da es SQL-Dialekte verwendet und auf Googles Datenverarbeitungstechnologie Dremel basiert.
Ist Bigtable SQL oder Nosql?
Es gibt keine endgültige Antwort auf diese Frage, da es davon abhängt, wie Sie jeden Begriff definieren. Wenn wir jedoch eine breite Definition von SQL als jede Datenbank nehmen, die eine strukturierte Abfragesprache verwendet, und NoSQL als jede Datenbank, die keine strukturierte Abfragesprache verwendet, dann würde Bigtable als NoSQL-Datenbank betrachtet.
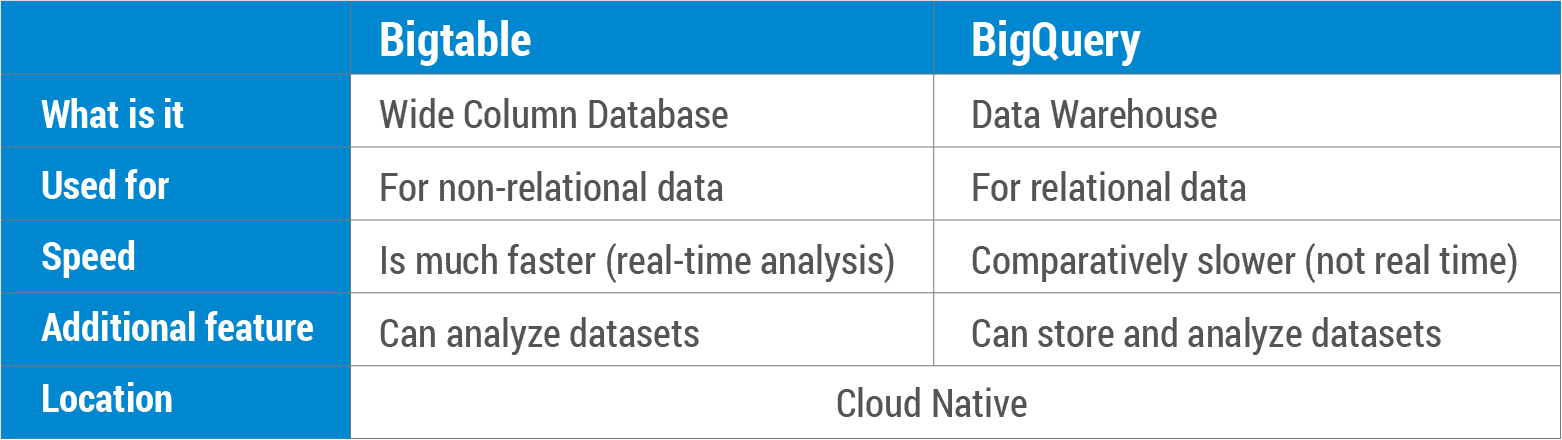
Was ist ein Bigtable- und ein BigQuery-Vergleich? Bigtable ist eine NoSQL-Datenbank, mit der Sie Daten sicher und skalierbar speichern können. BigQuery ist ein relationales Data Warehouse, das riesige Datenmengen in einer SQL-Datenbank speichert. Bigtable wurde für den täglichen Betrieb in Google-Produkte wie Analytics, Finanzen, personalisierte Suche, Earth und Writely integriert. Bigtable, eine NoSQL-Datenbank mit veränderlichen Daten , funktioniert gut mit OLTP-Szenarien. BigQuery ist ein relationales SQL-Data Warehouse, das für OLAP-Anwendungen verwendet werden kann. Sowohl Bigtable als auch BigQuery sind Cloud-nativ und verfügen über branchenführende Service Level Agreements. Darüber hinaus bieten sie automatisches Backup (mit Replikation) sowie unendliche Skalierbarkeit, automatisches Sharding und automatische Fehlerbehebung (mit Replikation).
BigQuery tut dies nicht und nicht eine NoSQL-Datenbank.
Welche Art von Nosql-Datenbank ist Bigtable?
Cloud Bigtable ist eine NoSQL-Datenbank, mit der Daten analysiert und Vorgänge ausgeführt werden können. Es ist eine Alternative zu HBase, einem spaltenorientierten Datenbanksystem, das HDFS verwendet. Anwendungen mit einer Bandbreite von weniger als 10 MB eignen sich für Cloud Bigtable, das ein hohes Maß an Durchsatz und Skalierbarkeit unterstützen kann.
Big Table-Datenbanken, wie sie genannt werden, sind eine Teilmenge von NoSQL-Datenbanken. Bigtable, eine Anwendung von Google, ähnelt Kleenex. Bigtable-Datenbanken sind der Industriestandard für Nachahmung und Inspiration. Während sich der Artikel hauptsächlich mit Bigtable befasst, werden auch andere NoSQL-Datenbanken betrachtet. Bigtable wurde hauptsächlich für die interne Verwendung durch Google entwickelt, ohne Zugriff von außen. Bigtable wurde 2004 bei Google eingeführt und wurde seitdem von mehr als 60 Google-Anwendungen verwendet. Eine Bigtable-Implementierung erfordert einen Master-Server, um Tablets über einen Cluster anderer Server hinweg zu verfolgen.
Die Apache Software Foundation hat zu einer Reihe hervorragender technischer Initiativen beigetragen, insbesondere im Bereich Datenbanken. Accumulo und HBase verwenden die gleichen Designprinzipien wie Google Bigtable, jedoch in einem kommerziell erhältlichen Format. Derzeit betreibt Apache HBase das Messaging-System von Facebook und ist eng mit Hadoop integriert, sodass große Datenmengen verarbeitet werden können. Die Hypertable-Datenbank basiert auf Bigtable, einer einfachen tabellarischen Datenbank. Hypertable läuft genauso wie Hadoop und HFS. Baidu, eine der größten Suchmaschinen Chinas, ist einer der Hauptsponsoren von Hypertable. Zu den Kunden zählen Online-Auktionsseiten wie eBay, Groupon und Rediff.com sowie Offline-Händler wie Lowe's und TJ Maxx.
Hadoop ist eine Open-Source-Softwareplattform, die es Benutzern ermöglicht, riesige Datenmengen effizient zu speichern und zu verarbeiten. Dies ermöglicht NoSQL-Datenbanken, die die für die Speicherung auf einzelnen Servern erforderliche Datenmenge reduzieren können. Eine NoSQL-Datenbank hingegen benötigt kein festes Schema, da sie skalierbar ist. Aus diesem Grund sind sie eine ausgezeichnete Wahl für die verteilte Speicherung großer Datenmengen.
In welche Art von Nosql-Datenspeicher fällt Bigtable?
Eine der wenigen Funktionen, die auf dem Generikamarkt verfügbar sind. Auf der einfachsten Ebene ist Bigtable eine NoSQL-Datenbank, die eine Vielzahl von Spalten umfasst.
Ist Bigtable Columnar Database?
Wide-Column-Stores wie Bigtable und Apache Cassandra sind keine Spalten im herkömmlichen Sinne, da sie auf den beiden Ebenen überhaupt keine spaltenförmigen Datenstrukturen verwenden.
Ist Bigtable eine nicht relationale Datenbank?
Auf diese Frage gibt es keine endgültige Antwort, da dies davon abhängt, wie Sie eine „nicht relationale Datenbank“ definieren. Bigtable ist ein spaltenorientierter Datenspeicher, den manche Leute für eine Art NoSQL-Datenbank halten. Es unterstützt jedoch Transaktionen und Indexierung, die normalerweise mit relationalen Datenbanken verbunden sind. Es hängt also wirklich davon ab, wie Sie eine nicht relationale Datenbank definieren.
Die CREATE EXTERNAL TABLE-Anweisung kann verwendet werden, um eine Tabelle in BigQuery zu erstellen, indem eine Tabelle angegeben wird, aus der Daten abgerufen werden sollen. Die Option uri kann verwendet werden, um eine Tabelle anzugeben, aus der Daten abgerufen werden sollen. Das Tabellenschema umfasst den Tabellennamen, den Tabellentyp, die Spaltennamen und Datentypen sowie das Tabellenschema der Option bigtable_options.
Wenn Sie MySQL verwenden, kann das BigQuery-Importtool verwendet werden, um Daten aus einer MySQL-Tabelle automatisch in BigQuery zu importieren. Ein Tabellenname und eine Spaltenfamilie werden in das Tool eingegeben, das die Daten in eine BigQuery-Tabelle importiert.
Wenn Sie die Google Cloud-Konsole verwenden, müssen Sie den Tabellennamen und die qualifizierenden Parameter der Spaltenfamilie manuell eingeben. Das Importieren von Daten aus einer Vielzahl von Quellen ist auf der Google Cloud-Plattform möglich, darunter MySQL, PostgreSQL, MongoDB und Redis.
Hauptmerkmale von Bigtable
Was sind einige Funktionen von Bigtable?
Die Geschwindigkeit von Bigtable beim Lesen und Schreiben, seine enorme Skalierbarkeit und die Fähigkeit, große Datenmengen zu verarbeiten, sind nur einige der vielen Merkmale. Da Bigtable eine NoSQL-Datenbank ist, werden SQL-Abfragen außerdem nicht unterstützt. Dadurch entfällt die Notwendigkeit, SQL-Operationen in separaten Datenbanken auszuführen.
Ist Bigtable eine Datenbank?
Bigtable ist keine relationale Datenbank. Es handelt sich um ein verteiltes Speichersystem zur Verwaltung strukturierter Daten, das auf eine sehr große Größe skaliert werden kann: Petabytes an Daten auf Tausenden von Standardservern. Google verwendet Bigtable, um viele seiner großen Dienste wie Google Analytics und Google Maps zu betreiben.
Der Cloud BigTable bietet eine einzigartige Reihe von Funktionen, mit denen er auf über 100.000 Spalten und Milliarden von Zeilen skaliert werden kann. Es unterstützt die Speicherung von ungefähr Petabyte und Terabyte an Daten. Im Vergleich zu BigTable hat es eine sehr geringe Latenz, hat aber auch das Potenzial, eine große Datenmenge zu speichern. BigTable kann strukturierte Daten in Spalten speichern und so Webdienste und Internetsuchdaten von Unternehmen verarbeiten. Komprimierungsalgorithmen werden auch verwendet, um die Kapazität des Systems zu erhöhen. BigTable verfügt über leistungsstarke Back-End-Server, die bessere Vorteile bieten als die selbstverwaltete HBase-Installation, die in BigTable enthalten ist. Die Zeilen auf der BigTable haben dieselbe Grenze, daher werden sie auch als Blöcke bezeichnet.
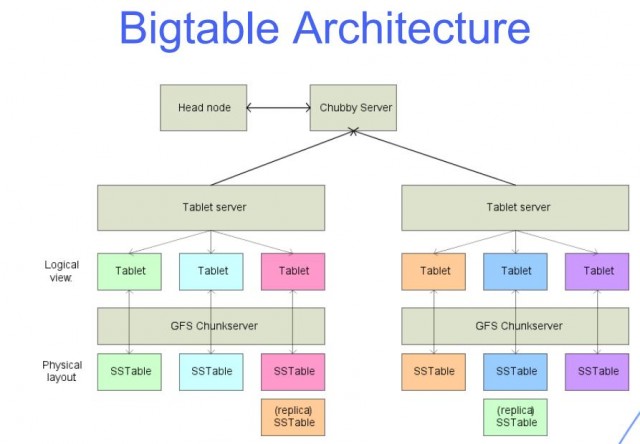
Diese Geräte, die als „Tablets“ bezeichnet werden, unterstützen Sie bei der Verwaltung Ihrer Abfragearbeitslast. Googles Cloud-basiertes Dateisystem Colossus wird verwendet, um alle Tablets zu speichern. Alle Schreibvorgänge in BigTable werden im gemeinsam genutzten Protokoll von Colossus gespeichert, ebenso wie die SSTable-Dateien. Die sieben Schlüsselfunktionen von BigTable sind entscheidend für den Erfolg eines Unternehmens. BigTable hat das Potenzial, Ihr Leben auf vielfältige Weise zu personalisieren, zu beschleunigen und zu automatisieren. Zeilen und Spalten sind die zwei Dimensionen von Daten in BigTable. Jede Zeile enthält einen eindeutigen Bezeichner oder Index, auf den mit dem einzelnen Zeilenschlüssel zugegriffen werden kann.
Jede der Spalten in einer Familie hat eine qualifizierende Spalte. Die Verwendung von spaltenqualifizierenden Einheiten wie Zeilenschlüsseln hilft bei der Spaltenidentifikation. Wenn es um Datenbanken geht, ist BigTable als spärlich bekannt. Jede der Zeitstempelversionen von BigTable wird durch eine Zelle dargestellt, die eine der Dimensionen innerhalb der 3D-Kartenstruktur darstellt. Diese leistungsstarke Datenbank, die personalisiert und geschwindigkeitsabhängig sein kann, kann verwendet werden, um mobile Websites und Apps zu betreiben. Wenn Sie in die Vergangenheit zurückdenken, können Sie herausfinden, welche Interaktionen zu den besten Ergebnissen geführt haben. Es wird Sie bei der Implementierung von mehr Datenanalysen unterstützen und zu einem besseren Kundenservice führen.
Google Cloud Bigtable, eine Open-Source-NoSQL-Datenbank, ist in Googles Cloud integriert. Die Tatsache, dass es mit so vielen bestehenden Big-Data- und Hadoop-Ökosystemen kompatibel ist, bedeutet, dass es für unstrukturierte Daten oder Daten, die eine geringe Latenz benötigen, verwendet werden kann.
Bigtable: Eine ausgezeichnete Wahl für datenintensive Anwendungen
Bigtable, ein NoSQL-Datenbankdienst, wird für große analytische und operative Workloads verwendet. Daher ist es eine ausgezeichnete Wahl für datenintensive und Echtzeitanwendungen. Da es außerdem spaltenorientiert ist, eignet es sich ideal zum Speichern von Daten in drei Dimensionen.
Bigtable gegen Mongodb
Es gibt einige wichtige Unterschiede zwischen Bigtable und MongoDB. Erstens ist Bigtable eine spaltenorientierte Datenbank, während MongoDB eine dokumentenorientierte Datenbank ist. Das bedeutet, dass Daten in Bigtable in Spalten gespeichert werden, während Daten in MongoDB in Dokumenten gespeichert werden. Zweitens unterstützt Bigtable im Gegensatz zu MongoDB keine sekundären Indizes. Das bedeutet, dass Sie, wenn Sie Daten in Bigtable abfragen möchten, die spezifische Spalte kennen müssen, die Sie abfragen möchten. In MongoDB können Sie jedes Feld in einem Dokument abfragen. Schließlich ist Bigtable für die horizontale Skalierung konzipiert, während MongoDB für die vertikale Skalierung konzipiert ist. Das bedeutet, dass Sie in Bigtable Ihrem Cluster weitere Maschinen hinzufügen können, um die Kapazität zu erhöhen, während Sie in MongoDB Ihrem Server mehr RAM und CPU hinzufügen können, um die Kapazität zu erhöhen.
Googles Cloud Bigtable: Nicht nur für Big Data
Bigtable ist immer noch eine Komponente der Google-Infrastruktur, die 2007 erstellt wurde. Obwohl Cloud Bigtable ideal zum Speichern großer Datenmengen mit geringer Latenz ist, ist es nicht ideal für Daten, die keinen häufigen Zugriff erfordern. Cloud Bigtable zum Beispiel würde nicht gut zu einem Data Lake passen.
Bigtable-Datenbank
Eine Bigtable-Datenbank ist eine Datenbank, die eine Bigtable-Datenstruktur verwendet . Eine Bigtable ist ein verteiltes Speichersystem für strukturierte Daten, das auf eine sehr große Skalierung ausgelegt ist.
Eine große Tabelle hat viele Zeilen und Spalten und ist normalerweise nur spärlich gefüllt. Bigtable ist aufgrund seiner geringen Latenz und hohen Dichte ideal für große Datenmengen. Diese Datenquelle ist ideal für MapReduce-Vorgänge, da sie einen hohen Lese-Schreib-Durchsatz bei geringer Latenz unterstützt und ideal für große Datenmengen ist. Die Daten einer Bigtable-Tabelle werden in Blöcke zusammenhängender Zeilen aufgeteilt, die jeweils als Tablet bezeichnet werden, um die Abfragelast zu reduzieren. Das SSTable-Format wird verwendet, um Google-Tablets in Colossus, dem Dateisystem des Unternehmens, zu speichern. Jedes Tablet ist mit einem bestimmten Knoten in der Bigtable-Instanz verknüpft, der auch als Knoten bezeichnet wird. Das Hinzufügen von Knoten zu einem Cluster kann die Kapazität des Clusters zur Verarbeitung mehrerer gleichzeitiger Anforderungen erhöhen.
Jede Zeile enthält eine Kombination aus der Spaltenfamilie, der Spaltenkennung und dem Zeitstempel, im Wesentlichen ein Array von Schlüssel/Wert-Einträgen. In den allermeisten Fällen konvertiert Bigtable alle Daten in rohe Byte-Strings. Da Bigtable Mutationen sequenziell speichert und sie nur alle paar Monate komprimiert, nehmen Mutationen mehr Speicherplatz ein, wenn sie in eine Reihe geändert werden. Bigtable komprimiert Daten mithilfe eines intelligenten Algorithmus und verwendet eine Komprimierungstechnologie. Da Deletionen eine spezielle Art von Mutationen sind, erfordern sie kurzfristig zusätzlichen Speicherplatz. Die proprietären Speichermethoden von Google ermöglichen es, den Test der Zeit für Daten zu überstehen, die über den Bereich der standardmäßigen Drei-Wege-HDFS-Replikation hinausgehen. Nutzer können mithilfe der ihnen von Ihrem Google Cloud-Projekt und Identity and Access Management (IAM) zugewiesenen Rollen auf Ihre Bigtable-Tabellen zugreifen. Der Großteil der Google Cloud-Daten wird im Ruhezustand mit denselben gehärteten Schlüsselverwaltungssystemen verschlüsselt, die wir für unsere verschlüsselten Daten verwenden. Eine Sicherung kann verwendet werden, um eine Kopie des Schemas und der Daten der Tabelle zu speichern und um die Sicherung später in einer neuen Tabelle wiederherzustellen.
Bigtable ist ein gut konzipiertes, verteiltes Speichersystem, das bis zu Petabyte an Daten speichern kann. Da es einfach zu bedienen ist, ist es eine ausgezeichnete Wahl für die Speicherung großer Datenmengen .
Die Macht der Cloud Bigtable
Die Cloud Bigtable-Datenbank kann Zehntausende von Zeilen und Spalten enthalten und ist von überall auf der Welt aus zugänglich. Daher eignet es sich gut für die Speicherung großer Datenmengen. Cloud Bigtable ist jetzt seit dem 6. Mai 2015 in Google Cloud verfügbar. Dies hat dazu geführt, dass seitdem mehr als 10 EXAbyte an Daten bereitgestellt und über 5 Milliarden Anfragen pro Sekunde verarbeitet werden. Daher wird Cloud Bigtable immer noch verwendet und ist ein wertvolles Werkzeug für die Datenspeicherung.

Bigtable gegen Kassandra
Jeder Knoten wird unter Verwendung seiner eigenen Methode für Lese- und Schreiboperationen ausgewählt. In Cassandra wird ein Partitionsschlüssel identifiziert, während in Bigtable ein Zeilenschlüssel verwendet wird. Die Load-Balancing-Richtlinie von Cassandra wird zuerst vom Client überprüft.
Datenbanksysteme wie Bigtable und Cassandra werden verbreitet. Sie erstellen mehrdimensionale Schlüsselwertspeicher, die Zehntausende von Abfragen pro Sekunde (QPS) verarbeiten können. Ziel dieses Dokuments ist es, die Unterschiede und Gemeinsamkeiten zwischen den beiden Datenbanksystemen zu erläutern. Bigtable enthält viele der in Bigtable beschriebenen Hauptfunktionen. Das Papier beschreibt ein verteiltes Speichersystem für strukturierte Daten. Wenn Bigtable die Bereichszuweisung als für einen Datensatz erforderlich identifiziert, können Datenbereiche für einen Verarbeitungsknoten einfach geändert werden, da die Speicherschicht von der Verarbeitungsschicht getrennt ist. Darüber hinaus ermöglicht Bigtable die asynchrone Replikation zwischen geografisch verteilten Clustern in bis zu vier Topologien.
Die Fehlertoleranz wird von Cassandra bereitgestellt, die mit dem Grad der Konsistenz korreliert. Mithilfe einer konfigurierbaren Datenreplikationstopologiestrategie können Sie die geografische Replikation definieren. In den meisten Topologien mit mehreren Rechenzentren ist QUORUM (oder LOCAL_QUORUM) die Standardeinstellung. Damit diese Ebeneneinstellung als erfolgreich angesehen wird, ist die Mehrheit der Antworten eines Replikatknotens an den Koordinatorknoten erforderlich. Die Datenrepliken in Cassandra können in Bezug auf die Fehlertoleranz verbessert werden, indem Rechenzentrums- und Rack-Konfigurationen verwendet werden. Die Topologie bestimmt, welche Knoten erforderlich sind, um die Konsistenz bei Lese- und Schreibvorgängen zu gewährleisten. Die Bigtable-Instanz kann einen oder mehrere Cluster oder eine Sammlung von bis zu vier replizierten Clustern haben.
Bigtable und Cassandra fungieren beide als NoSQL-Wide-Column-Stores. Der Zeilenschlüssel bestimmt die Reihenfolge, in der die globale Datensortierung einer Tabelle in Bigtable angezeigt wird. In Bigtable werden Knoten verwendet, um die Verantwortung für Schlüsselbereiche auszugleichen, die allgemein als Tablets bezeichnet werden. Der Bigtable-Dienst erzwingt keine Spaltendatentypen, die der Client sendet. Die Bigtable-Spaltenfamilie wählt aus, welche Spalten in einer Tabelle gespeichert und von einer zur nächsten abgerufen werden sollen. Jede Tabelle muss mindestens eine Spaltenfamilie haben, aber Tabellen haben häufig mehr (die maximale Anzahl von Spalten, die eine Tabelle haben kann, ist 100). In einer Zelle befindet sich ein Zeilenschlüssel und in der anderen ein Spaltenname.
Cassandra und Bigtable verwenden unterschiedliche Methoden, um den Verarbeitungsknoten sowohl für Lese- als auch für Schreibvorgänge auszuwählen. In Cassandra wird der Partitionsschlüssel unterschieden, während in Bigtable der Zeilenschlüssel verwendet wird. Durch das Erstellen einer Multi-Cluster-Richtlinie bietet eine Load-Balancing-Richtlinie, die Rechenzentren kennt, die Vorteile eines Failover. Beide Datenbanken wurden für schnelles Schreiben optimiert und verwenden dafür einen ähnlichen Prozess. Beide Datenbanken speichern Daten in SSTable-Dateien, die unveränderliche Dateien sind. In Cassandra müssen mehrere Kopien kontaktiert werden, bevor der Koordinator den Kunden darüber informiert, dass das Schreiben abgeschlossen ist. Da jeder Zeilenschlüssel in Bigtable nur einem Knoten zugewiesen ist, ist eine Antwort von diesem Knoten erforderlich, um zu bestätigen, dass ein Schreibvorgang erfolgreich war.
Als Ergebnis der SSTable-Zusammenführung können beide Datenbanken Zellen ausschließen. Bei der Rückgabe von Daten an Cassandra beschränkt die WHERE-Klausel in einer CQL-Abfrage die Anzahl der Zeilen. Bei der Verwendung von Bigtable muss nur der für den Schlüsselbereich zuständige Knoten konsultiert werden. Die Leseergebnisse eines Knotens können auf vielfältige Weise eingeschränkt werden. Während einer Komprimierungsphase speichern Bigtable und Cassandra Daten in SSTables, die regelmäßig zusammengeführt werden. Bigtable beschränkt die Anzahl der Zeitstempelversionen für jede Zelle nicht, aber andere Zeilengrößen können dies tun. Die von Colossus bereitgestellte Replikation garantiert eine hohe Datenbeständigkeit.
Die Befehlszeilenschnittstelle von Bigtable sowie seine Client-Bibliotheken für eine Vielzahl gängiger Programmiersprachen ergänzen die Fähigkeiten von Cassandra. Jeder Bigtable-Knoten muss eine Reihe von SSTables bedienen, die Daten enthalten, die in diesen Tabellen gespeichert sind. Sie müssen Speicherreplikate in Bigtable nicht mehr so berechnen, wie Sie es in Cassandra tun würden, wenn Sie die Größe des Clusters bestimmen. Bigtable-Instanzen speichern Daten normalerweise auf Solid-State-Laufwerken (SSDs) oder Festplatten (HDDs). Im Gegensatz zu Cassandra, das auf der Theorie basiert, dass es keinen Verlust an Speicherdichte gibt, um Fehlertoleranz zu erreichen, verliert die Arbeitslast nicht an Dichte. Es ist einfach, eine Bigtable-Instanz je nach Bedarf nach oben oder unten zu skalieren, um die Workload-Anforderungen zu erfüllen und gleichzeitig minimalen Aufwand und Ausfallzeiten zu gewährleisten. Eine Instanz kann nur vier Cluster haben, aber sie können in jeder unterstützten Cloud-Region auf der Welt geclustert werden.
Um eine Metrik für QPS-Pernode zu erstellen, empfiehlt Google, die Leistung von Bigtable mit repräsentativen Daten und Abfragen zu verwenden. Bigtable enthält verwaltete Komponenten für allgemeine Cassandra-Verwaltungsfunktionen. Eine Tabelle, die Teil des Clusters ist, wird als wiederherstellbare Kopie der Tabelle in einer Bigtable-Sicherung erstellt. Der Preis einer Sicherung ist niedriger als der von Cloud Storage oder verbraucht keine Knotenressourcen. Eine weitere Option ist die Verwendung eines verwalteten Datenexports in Cloud Storage, um Bigtable zu sichern. Bigtable verwaltet gängige interne Cassandra-Wartungsaufgaben wie Betriebssystem-Patching, Knotenwiederherstellung, Knotenreparatur, Überwachung der Speicherkomprimierung und Rotation von SSL-Zertifikaten mit Leichtigkeit. Dashboards sind vorgefertigt, um Durchsatz- und Nutzungsmetriken auf Instanz-, Cluster- und Tabellenebene auf der Bigtable-Seite der Google Cloud-Konsole zu verfolgen. Sie können das Überwachungs-Dashboard verwenden, um eine erweiterte Leistungsoptimierung durchzuführen.
SQL wird in Bigtable verwendet, ebenso wie der Zeilenschlüsselzugriff auf Daten in einer NoSQL-Datenbank. Die Knoten sind über das Netzwerk verteilt, und Klatsch wird verwendet, um die Netzwerkkonsistenz aufrechtzuerhalten. Mit diesem System wird die Datenspeicherkapazität erhöht und die Verfügbarkeit ohne Single Point of Failure aufrechterhalten.
Bigtable hingegen ist skalierbarer und bietet ein höheres Maß an Verfügbarkeit als Cassandra. Bigtable ist auch benutzerfreundlicher als andere Programmiersprachen, was es zu einer ausgezeichneten Wahl für Datensätze mit weniger Ressourcen macht.
Verwendet Google immer noch Bigtable?
Google Analytics, Webindizierung, MapReduce und viele andere Google-Anwendungen wie Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code-Hosting verwenden es zum Generieren und Ändern von Daten, die in Bigtable, Google Maps gespeichert sind , Google Bücher, Meine Suche
Verwendet Google Cassandra?
Die DataStax Astra Cassandra as a Service-Topologie wurde auf Google Cloud mit dem TensorFlow-Betriebssystem sowie mit dem Apache Cassandra-Betriebssystem in drei Google Cloud-Zonen bereitgestellt.
Ist Bigtable dasselbe wie Hbase?
Ein Bigtable-Zeitstempel wird in Mikrosekunden gespeichert, während ein HBase-Zeitstempel in Millisekunden gespeichert wird. Diese Unterscheidung kann nützlich sein, wenn Sie die HBase-Clientbibliothek für Bigtable verwenden und sich umgekehrte Zeitstempel ansehen.
Wofür ist Bigtable gut?
Die Bigtable NoSQL-Datenbank ist eine breitspaltige Datenbank, die sich ideal für die Verwendung in einer NoSQL-Datenbank eignet. Das System ist optimiert, um eine geringe Latenz, eine große Anzahl von Lese- und Schreibvorgängen und eine hohe Leistung im großen Maßstab bereitzustellen. Die Verwendung von Tabellenfällen ist in der Regel auf einen bestimmten Umfang oder Durchsatz beschränkt, der eine hohe Latenz erfordert, wie z. B. das Internet der Dinge (IoT), AdTech, FinTech usw.
Bigtable vs. Bigquery
Es gibt einige wichtige Unterschiede zwischen bigtable und bigquery. Bigtable ist als skalierbare, spaltenorientierte Datenbank konzipiert, während Bigquery als skalierbare, relationale Datenbank konzipiert ist. Bigtable unterstützt SQL nicht, während Bigquery dies tut. Bigtable ist nicht so weit verbreitet wie Bigquery, hat aber einige Vorteile gegenüber Bigquery, wie z. B. die Möglichkeit, auf eine größere Anzahl von Spalten und Zeilen zu skalieren.
Google hat im Laufe der Jahre erhebliche Fortschritte bei der Cloud-Speicherung massiver Daten gemacht. Bigtable ist ein vollständig verwalteter NoSQL-Datenbankdienst im Petabyte-Bereich, der auf objektorientierter Datenbankverwaltung (OOPA) basiert. BigQuery basiert auf der Bigtable- und Google Cloud-Plattform sowie dem Dremel-Datenbanksystem von Google. Es gibt drei Hauptunterschiede zwischen BigQuery und Bigtable. Eine Big Data as a Service (BaaS)-Lösung wird von Google Cloud BigQuery bereitgestellt. BigQuery wird von Google-Produkten wie Analytics, Finance, Personalized Search, Earth, Orkut und Writely verwendet. Wenn die blitzschnelle Datenverarbeitung von BigQuery verwendet wird, können 35 Milliarden Zeilen in Sekundenschnelle verarbeitet werden.
Eine NoSQL-Datenbank ist ein Akronym für einen Datenbankdienst; mit anderen Worten, es handelt sich nicht um eine relationale Datenbank. Die Schlüsselspalten können mehrfach groß sein und die Schlüsselleisten können horizontal gescrollt werden. Einzelne Datenelemente mit einer größeren Speicherkapazität von 10 Megabyte können die Performance beeinträchtigen. Wenn Sie eine umfassende Speicherlösung für unstrukturierte Objekte (z. B. Videodateien) benötigen, ist Cloud-Speicher wahrscheinlich die bessere Option. Es ist eine ausgezeichnete Wahl für Abfragen, die einen Tabellenscan erfordern, oder um eine große Datenbank in einem einzigen Schuss zu durchsuchen. Es ist unmöglich, dass sich ein hochgeladenes Objekt während seiner Lebensdauer in BigQuery ändert, und seine Daten sind immer unveränderlich. Tabellen innerhalb einer Bigtable speichern skalierbare Daten , die nach Schlüssel, Zeile und Zeitstempel in sortierte Schlüssel/Wert-Maps sortiert wurden.
Mit Integrate.io können Sie einen ETL- und Datenintegrationsprozess automatisieren, um Ihre Datenquellen und Cloud-Data-Warehouses zu verknüpfen. Die Integrationsplattform umfasst mehr als 100 vorgefertigte Integrationen, einschließlich BigQuery, und eine Drag-and-Drop-Oberfläche, die die Verwaltung Ihrer Integrationsprozesse einfacher denn je macht. Wenden Sie sich an unser Team von Datenexperten, um Ihre Situation zu besprechen oder ein 14-tägiges Pilotprojekt der Integrate-Plattform zu starten.
Google BigQuery hat die Nase vorn, obwohl MySQL immer noch weit verbreitet ist. Dies gilt insbesondere für Funktionen, die häufig in Geschäftsanwendungen verwendet werden, wie z. B. Datenimport und -export, Datenanalyse und Datenföderation. MySQL hingegen hat nur 28 Funktionen, was bedeutet, dass es möglicherweise nicht in der Lage ist, die Anforderungen vieler Unternehmen zu erfüllen. Google BigQuery ist Cloud-basiert, sodass von jedem Ort mit Internetverbindung darauf zugegriffen werden kann. MySQL hingegen läuft auf einer Client-Server-Architektur und ist nicht in der Cloud verfügbar.
Was ist der Unterschied zwischen Bigquery und Bigtable?
Bigtable ist eine NoSQL-Datenbank mit breiten Spalten, die für umfangreiche Lese- und Schreibvorgänge optimiert ist. Im Gegensatz zu BigQuery, einem Enterprise Data Warehouse für große Mengen relationaler Daten, dient Oracle Data Warehouse als Deduplizierungsdienst.
Ist Bigquery auf Bigtable aufgebaut?
Bigtable, ein Cloud-basierter Abfragedienst, der in Zusammenarbeit mit Google und Microsoft entwickelt wurde, und Googles Dremel-System für Ad-hoc-Abfragen folgten bald.
Wann sollte ich Bigtable verwenden?
Bigtable ist ideal für Anwendungen, die einen hohen Durchsatz und Skalierbarkeit bei der Verarbeitung von Schlüssel/Wert-Daten mit nicht mehr als 10 MB Daten pro Wert erfordern. Die Stärken von Bigtable liegen in Batch-MapReduce-Operationen, Stream-Verarbeitung/Analyse und maschinellem Lernen.
Skalierbarer Nosql-Datenbankdienst
Ein skalierbarer Nosql-Datenbankdienst ist ein Datenbanktyp, der große Datenmengen verarbeiten kann. Es handelt sich um einen webbasierten Dienst, mit dem große Datenmengen gespeichert und verwaltet werden können. Diese Art von Datenbank ist so konzipiert, dass sie skalierbar ist, sodass sie große Datenmengen verarbeiten kann.
In diesem Tutorial wird davon ausgegangen, dass Sie über eine funktionierende Node.js-Umgebung verfügen. Ich habe einen Ordner namens nodejs-dynamodb-sample erstellt, in den die DynamoDB-Dateien entpackt werden. Die GitHub-Seite für das Projekt ist https://www.gofundme.com/adamfowleruk/nodesurvey.html. Die Beispiel-App verwendet DynamoDB zum Suchen und Abrufen von Filmdaten. Um Daten auf S3 zu speichern, verwenden wir den Identity and Access Management Service (IAM) von Amazon, und um auf DynamoDB auf AWS zuzugreifen, verwenden wir den DynamoDB-Service von Amazon. Um den iADM-Dienst von Amazon nutzen zu können, müssen Sie sich zunächst registrieren und einen Benutzer anlegen. Ein Filmtitel und ein Jahr können zum Abschnitt POST/Filme Ihrer Suche hinzugefügt werden.
Erstellen Sie eine Liste mit Filmen aus einem bestimmten Jahr, indem Sie das Schlüsselfeld eingeben. Nach diesem grundlegenden Beispiel können Sie nun Ihre eigene Anwendung erstellen. Wenn Sie beabsichtigen, Ihre Tabellen erneut zu verwenden, sollten Sie sie löschen, nachdem Sie sie nicht mehr verwendet haben, wodurch AWS-Hosting- und Servicekosten anfallen. Gehen Sie in AWS zur DynamoDB-Konsole und geben Sie die Menge an Speicherplatz ein, die Sie verwendet haben. Sie können die Elemente in einer Tabelle anzeigen, indem Sie auf „Filme“ klicken, die Messwerte anzeigen, die Sie in Ihrer Anwendung sehen, und die geschätzten monatlichen Kosten anzeigen, indem Sie auf die Registerkarte „Kapazität“ klicken. Auf meiner GitHub-Seite füge ich ein Beispiel des Codes in diese Übung ein: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Google Cloud Bigtable-Datenbank
Google Cloud Bigtable ist ein schneller, vollständig verwalteter NoSQL-Datenbankdienst im Petabyte-Bereich, der sich ideal für große analytische und operative Workloads eignet.
Der Datenspeicher von Google eignet sich besser für Anwendungen, die schnelle Antworten auf Benutzeranfragen benötigen.
In der Bigtable-Datenbank von Google gibt es keine relationale Datenbank. SQL-Abfragen, Verknüpfungen und mehrzeilige Transaktionen werden nicht unterstützt. Wenn Sie also nach standardmäßiger Datenbankunterstützung suchen, können Sie diese nicht erwarten. Bigtable hingegen bietet keine große Menge an Daten oder Analysen. Die Optimierung von Bigtable ist zum Teil auf seine leistungsstarken Analyse- und Datenverarbeitungsfunktionen zurückzuführen. Datastore hingegen ist so konzipiert, dass Anwendungen hochwertige Transaktionsdaten bereitgestellt werden können. Daher eignet sich Datastore besser für Anwendungen, die schnelle Antworten auf Benutzeranfragen erfordern.