
NoSQL-Datenbanken: Hochverfügbarkeit und Skalierbarkeit durch Replikation
Veröffentlicht: 2022-11-19Es gibt viele verschiedene Arten von NoSQL-Datenbanken, jede mit ihren eigenen Fähigkeiten und Merkmalen. Ein gemeinsames Merkmal vieler NoSQL-Datenbanken ist jedoch die Fähigkeit, Daten über mehrere Server zu replizieren. Replikation ist der Vorgang des Kopierens von Daten von einem Server auf einen anderen, sodass die Daten auf mehreren Servern verfügbar sind. Die Replikation kann eine erhöhte Verfügbarkeit und Leistung bieten, indem Daten von mehreren Servern gelesen werden können. NoSQL-Datenbanken verwenden typischerweise ein Master-Slave-Replikationsmodell, bei dem ein Server als Master bezeichnet wird und alle anderen Server Slaves sind. Der Master-Server verwaltet eine Kopie der Daten und repliziert Änderungen an den Slaves. Die Slaves können zum Lesen von Daten verwendet werden, aber alle Schreibvorgänge müssen über den Master erfolgen. Ein Vorteil der Replikation besteht darin, dass sie helfen kann, die Leistung zu verbessern, indem Lesevorgänge auf mehrere Server verteilt werden. Die Replikation kann auch die Verfügbarkeit verbessern, indem mehrere Kopien von Daten bereitgestellt werden, falls ein Server ausfällt. NoSQL-Datenbanken bieten in der Regel eine hohe Verfügbarkeit und Skalierbarkeit, da sie Daten über mehrere Server replizieren können.
In ähnlicher Weise ist die NoSQL -Datenreplikation eine robuste Funktion, mit der Sie strukturierte, unstrukturierte und halbstrukturierte Daten nahtlos kopieren und speichern sowie Datenverlust verhindern können, wenn ein Server abstürzt. Erfahren Sie mehr über NoSQL-Datenbanken auf dieser Seite.
Es findet sowohl eine Master-Slave- als auch eine Slave-Run-Replikation statt, und die Master-Slave-Replikation bestimmt einen Knoten als maßgebliche Kopie, die sowohl Schreib- als auch Lesevorgänge verarbeiten kann. Ein Peer-to- Peer-Replikationsprozess ermöglicht Knoten, miteinander zu schreiben, und jeder Knoten kopiert die Daten zum nächsten.
Die MongoDB-Replikation bezieht sich auf die Erstellung eines Replikatsatzes, der einen gemeinsamen Datensatz mit anderen MongoDB-Instanzen teilt. Der Replikatsatz enthält eine Reihe von Knoten, die Daten tragen, und der Knoten, der ein Arbiter ist, ist optional. Es gibt sechs Knoten in einer datentragenden Umgebung, wobei ein Mitglied als primärer Knoten und die anderen Mitglieder als sekundäre Knoten klassifiziert sind.
Im Allgemeinen ist ein Experiment oder Verfahren, das mehr als eine bestimmte Menge an Ergebnissen liefert, ein Erfolg; in diesem Fall wird die Replikation von DNA kopiert oder repliziert. Der Vorgang, etwas zu replizieren, wird als Replikation bezeichnet.
Was ist Nosql-Datenreplikation?
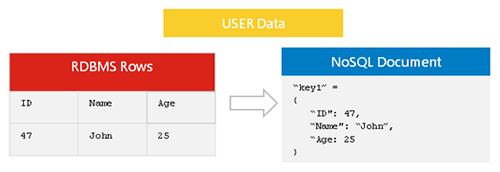
Die Nosql-Datenreplikation ist der Vorgang des Kopierens von Daten von einer Nosql-Datenbank in eine andere. Dies kann aus verschiedenen Gründen erfolgen, z. B. zum Erstellen eines Backups oder zum Verteilen von Daten auf mehrere Server. Die Nosql-Datenreplikation wird im Allgemeinen asynchron durchgeführt, was bedeutet, dass die Kopie der Daten keine exakte Kopie der Originaldaten sein muss.
Seit vielen Jahren ist die Datenreplikation ein wesentlicher Bestandteil der Dateninfrastruktur eines jeden Unternehmens. Ein Datenreplikationssystem schützt Ihre Daten, indem es eine hohe Verfügbarkeit, Sicherung und Notfallwiederherstellung gewährleistet. Darüber hinaus unterstützt die Replikation die Fähigkeit der Organisation, die Datenkonsistenz und -genauigkeit zu verbessern. Es ist eine Methode zur Verbesserung der Datenzuverlässigkeit durch den Replikationsprozess. Indem Sie Daten replizieren, können Sie sicherstellen, dass sie immer verfügbar und gesichert sind und auch im Katastrophenfall. Durch die Replikation von Daten kann auch deren Konsistenz und Genauigkeit verbessert werden. Beim Entwerfen einer Dateninfrastruktur ist es wichtig, die Datenreplikation zu berücksichtigen.
Was ist Sharding und Replikation in Nosql?
Was ist der Unterschied zwischen Sharding und Replikation? Der primäre Serverknoten kopiert im Rahmen der Datenreplikation Daten von den sekundären Serverknoten. Auf diese Weise können Sie die Verfügbarkeit von Daten erhöhen und sie zu einem Notfall-Backup machen, falls der primäre Server ausfällt. Es verwaltet die Skalierung von Servern auf horizontalen Flächen mithilfe eines Shard-Schlüssels.

Haben Nosql-Datenbanken Datenredundanz?
Wenn ein erhebliches Datenvolumen vorhanden ist und Datenredundanz toleriert werden kann, eignet sich die NoSQL-Datenbank am besten für bestimmte Arten von Anwendungen und ausgewählte Anwendungsfälle.
Kann Nosql geteilt werden?
Die Partitionierung nach einem Microservices-Muster wird in NoSQL-Umgebungen verwendet. Das Muster beinhaltet die Aufteilung jeder Partition in mehrere Server, die sich möglicherweise am selben Ort auf der ganzen Welt befinden oder nicht. Dieses Scale-out funktioniert gut für Menschen aus der ganzen Welt, die auf verschiedene Teile des Datensatzes zugreifen und eine hohe Leistung erzielen möchten.
Was ist Replikation in einer Datenbank?
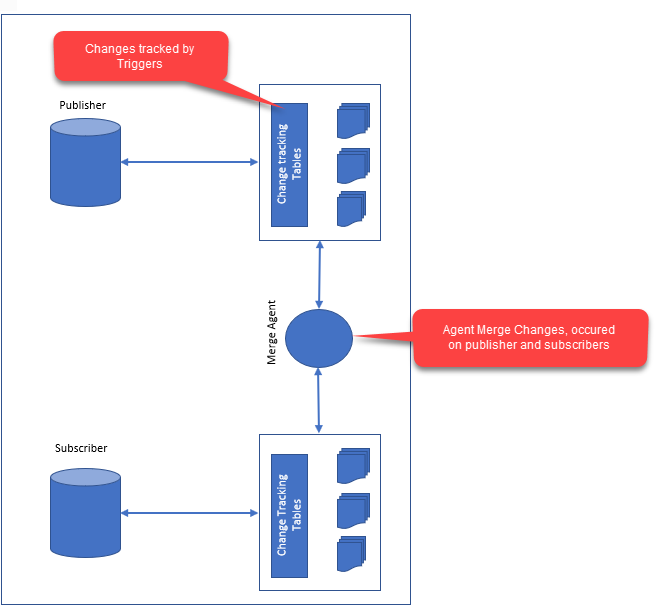
Die Replikation in einer Datenbank ist der Vorgang des Kopierens von Daten aus einer Quelldatenbank in eine Zieldatenbank. Die beiden Datenbanken können sich auf demselben Server oder auf unterschiedlichen Servern befinden. Die Replikation kann verwendet werden, um eine Datensicherung zu erstellen, Daten auf mehrere Server zu verteilen oder mehreren Benutzern den Zugriff auf die Daten zu ermöglichen.
Datenintegrität und -leistung sind heute entscheidende Aspekte der Datenreplikation . Das Umschreiben von Daten kann so einfach sein wie das Senden an einen Abonnenten oder so kompliziert wie das gleichzeitige Durchführen mehrerer Experimente. Die häufigste Form der Replikation ist die Snapshot-Replikation. Wenn eine große Datenmenge vorhanden ist oder der Teilnehmer entfernt ist, sendet er den gesamten Datensatz an ihn. Es ist eine fortgeschrittenere Form der Replikation als die Transaktionsreplikation. In einigen Fällen sendet es Datenänderungen nur an den Abonnenten oder die Daten, was in kleinen oder lokalen Dateien von Vorteil sein kann. Dies ist eine komplexere Replikationstechnik. Elemente können sowohl beim Verleger als auch beim Abonnenten geändert werden, was in Situationen nützlich sein kann, in denen die Daten umfangreich sind oder der Verleger und der Abonnent entfernt sind. Die Replikation heterogener Daten ist somit möglich, um auf eine Vielzahl von Datenbankprodukten zuzugreifen. Dies ist besonders nützlich für große Datenmengen mit mehreren Maschinentypen, z. B. Herausgeber und Abonnenten.
Was versteht man unter Replikation in Mongodb?
Eine MongoDB-Replikation ist eine Methode zum Replizieren des Datensatzes mehrerer MongoDB-Server. Sie können dies erreichen, indem Sie einen Replikatsatz verwenden. Ein Replikatsatz ist eine Sammlung von MongoDB-Instanzen, die denselben MongoDB-Datensatz bedienen und demselben Prozess zugeordnet sind.
Beim Erstellen eines Replikatsatzes wird der primäre Knoten automatisch ausgewählt. Sobald er verfügbar ist, ist der sekundäre Knoten der primäre Knoten mit der höchsten Replikatsatzbezeichnung. Der MongoDB -Replikationssatz gibt die Rollen des primären und sekundären Knotens an, und wenn beide Knoten verfügbar sind, konfiguriert MongoDB automatisch den primären Knoten. Es ist eine Sammlung von MongoDB-Instanzen, die in Bezug auf Datensatz und Prozess identisch sind. Datenbankadministratoren können Datenredundanz bieten, indem sie Daten replizieren. Daten sind weit verbreitet. Ein Replikatsatz ist eine Sammlung von MongoDB-Knoten, die zur Replikation in Gruppen organisiert sind. Ein Replikationssatz muss mindestens drei MongoDB-Knoten haben: Einer der drei Knoten gilt als primärer Knoten, der für den Empfang aller Schreibvorgänge verantwortlich ist. Wenn der erste Replikatsatz erstellt wird, wird der primäre Knoten automatisch ausgewählt.