
NoSQL-Datenbanken: Sharding und Replikation
Veröffentlicht: 2022-11-21NoSQL-Datenbanken werden aufgrund ihrer Fähigkeit zur horizontalen Skalierung häufig für die Datenspeicherung in großem Maßstab verwendet. Dies bedeutet, dass sie skalieren können, indem sie dem System weitere Knoten hinzufügen, anstatt die Hardware eines einzelnen Knotens zu aktualisieren. Eine Möglichkeit, diese horizontale Skalierbarkeit zu erreichen, ist das Sharding, bei dem Daten auf mehrere Knoten verteilt werden. Die Replikation ist eine weitere Möglichkeit, NoSQL-Datenbanken zu skalieren, und beinhaltet das Erstellen von Kopien von Daten auf mehreren Knoten.
Sowohl in SQL- als auch in NoSQL-Datenbanken ist das Konzept des Datenbank-Sharding für die Skalierung entscheidend. Die Datenbank ist, wie der Name schon sagt, in mehrere Chunks (Shards) aufgeteilt.
Sie können auch die NoSQL -Datenreplikation verwenden, um sicherzustellen, dass Sie keine Daten verlieren, wenn ein Server abstürzt, indem Sie Ihre strukturierten, unstrukturierten und halbstrukturierten Daten nahtlos kopieren und speichern. Auf dieser Seite erfahren Sie mehr über NoSQL-Datenbanken.
Eine relationale Datenbank kann mit der Sharding-Methode partitioniert werden, die auch als horizontale Partition bezeichnet wird. Amazon Relational Database Service ( Amazon RDS ) ist ein verwalteter relationaler Datenbankdienst, der die Verwendung in der Cloud durch die Bereitstellung einer Vielzahl von Funktionen vereinfacht.
Eine Replikationsmethode kopiert Daten von mehreren Servern und platziert sie an einem Ort, an dem sie gefunden werden können. Bei der Replikation werden Master- und Slave-Kopien erstellt, wobei Master-Kopien zu autoritativen Kopien werden, die geschriebene Daten verarbeiten, und Slave-Kopien zu asynchronen Kopien werden, die geschriebene Daten verarbeiten.
Verwendet Nosql Sharding?
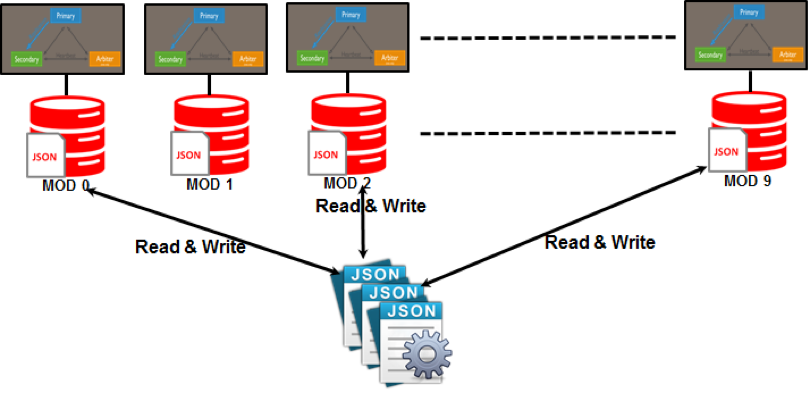
Partitionsmuster wie Sharing werden in NoSQL verwendet. Partitionierung ist ein Prozess, der jede Partition einem Server zuweist, der wahrscheinlich vom Rest des Netzwerks unabhängig ist. Mit dieser horizontalen Skalierung können Sie globalen Benutzern Zugriff auf eine Vielzahl von Daten gewähren und gleichzeitig das Leistungsniveau so hoch wie möglich halten.
MySQL Cluster ist die Lösung. MySQL Cluster ist eine Reihe von Software, die Tabellen automatisch über Knoten verteilt und es Datenbanken ermöglicht, horizontal auf kostengünstiger Standardhardware zu skalieren, um lese- und schreibintensive Workloads mit SQL sowie direkt über NoSQL-APIs zu bedienen. MySQL Cluster hat das Potenzial, für viel mehr als nur Blockchains verwendet zu werden. Es kann auch verwendet werden, um Ihre Anwendungen mithilfe von MySQL Cluster zu skalieren. Der Grund dafür ist, dass MySQL Cluster ein Scheduling-System ist. Infolgedessen können Sie Ihre Anwendungen skalieren, indem Sie entscheiden, wann und wie die Shards generiert werden. Dies ist ein großer Vorteil, da Sie nicht auf Cloud Computing angewiesen sind. Dies liegt daran, dass die Shards auf den Knoten erzeugt werden, auf denen die Arbeitslast ausgeführt wird. Dadurch können Sie steuern, wie viel Parallelität erforderlich ist. Infolgedessen verfügt MySQL Cluster über einen sehr leistungsstarken Satz von Funktionen. Es kann verwendet werden, um Ihre Anwendungen zu skalieren und zu steuern, wie viel Parallelität Sie benötigen.
Was ist Sharding und Replikation in Nosql?
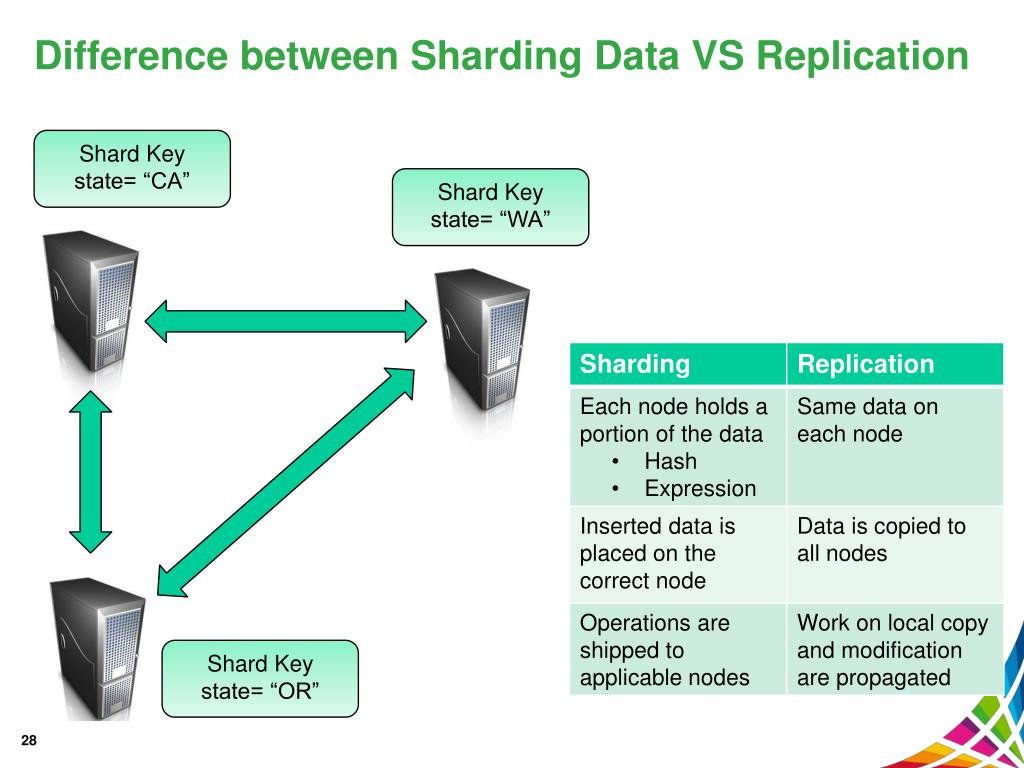
Was ist der Unterschied zwischen Replikation und Sharding? Datenreplikation ist die Übertragung von Daten vom primären Serverknoten auf die sekundären Serverknoten . Als Backup für den Fall, dass der primäre Server ausfällt, kann dies helfen, sicherzustellen, dass Daten verfügbar sind. Diese Funktion kann verwendet werden, um Server mithilfe eines Shard-Schlüssels horizontal zu skalieren.
Die Vorteile des Shardings
Wenn Sie es mit Daten zu tun haben, die partitioniert werden müssen, denen aber die Ressourcen fehlen, um sie zu replizieren, können Abstände in einer Vielzahl von Situationen von Vorteil sein. Wenn Sie Lesevorgänge skalieren müssen, ist die Replikation nützlich, aber Datenschreibvorgänge können mit Sharding effizienter gehandhabt werden. Die Wahl des falschen Shard Keys kann sich negativ auf die Leistung des Systems auswirken.
Verwendet Mongodb Sharding?
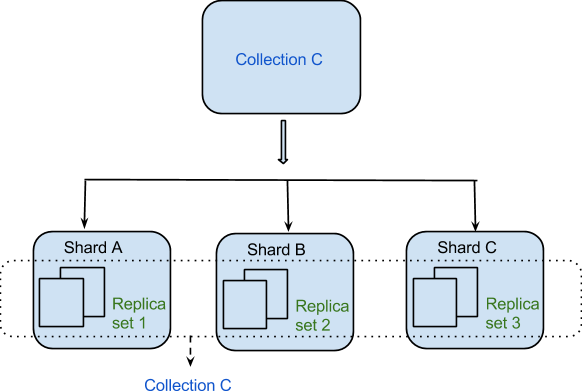
Daten werden aufgrund von Sharding auf verteilte Weise zwischen Maschinen verteilt. MongoDB verwendet Sharding, um umfangreiche Bereitstellungen zu unterstützen, die einen hohen Durchsatz erfordern. Es kann schwierig sein, einen einzelnen Server für ein Datenbanksystem mit einer großen Anzahl von Datensätzen oder einer Anwendung mit hohem Durchsatz zu erstellen.
Die gebräuchlichste Strategie zur Lösung von Fernkampfproblemen besteht darin, es im allgemeinsten Sinne anzugehen. Der Stammknoten des Clusters verfügt über eine vorgegebene Anzahl von Shards, die basierend auf ihrer Entfernung vom Rechenzentrum des Clusters aufgeteilt werden können. Der primäre Knoten wird als Root-Knoten bezeichnet, da er der erste Knoten ist, der im Datensatz erstellt wird. Eine andere Art von Fragment wird als sekundäres Fragment bezeichnet. Sowohl eine Bereichs- als auch eine Hash-Transaktion sind möglich. Der Hash-Schlüsselwert eines bestimmten Shards bestimmt, wie viele Daten er generieren kann. Durch den Hash-Schlüssel wird für jedes Datenelement in einer Transaktion eine Kennung erstellt. Jede Strategie hat zahlreiche Vor- und Nachteile. Es ist einfacher, Range Sharding zu implementieren, wenn der Datensatz klein ist, im Gegensatz zu einem großen Satz, und es ist effizienter, wenn er klein ist. Wenn der Datensatz groß ist, ist Hashing effizienter. Der Ruf von MongoDB für Geschwindigkeit beruht auf der Tatsache, dass es die Delegation von Daten an andere MongoDB-Dienste unterstützt. Datensatzfragmente können auf mehrere Server in MongoDB verteilt werden, um die Datenverarbeitungsgeschwindigkeit zu verbessern. MongoDB unterstützt zusätzlich zum Sharding mehrere Replikationsoptionen. Infolgedessen ermöglicht die Replikation die Verteilung eines Datensatzes auf mehrere Server, um die Konsistenz zu wahren. Die Replikation von Daten ist notwendig, wenn Sie sicherstellen möchten, dass die Informationen immer korrekt und aktuell sind. Darüber hinaus können verstreute Cluster in MongoDB nützlich sein, um die Leistung zu verbessern. Sraving ist eine Technik zum Übertragen großer Datenmengen von einem Server auf einen anderen auf die gleiche Weise wie bei der Replikation. Ein Shard-Schlüssel ist ein Datenelement, das von einem Server auf einen anderen kopiert werden kann (oder „Shards“). Die beiden primären Methoden zum Verteilen von Daten über Sharding-Cluster in MongoDB sind bereichsbasiert und verteilt. Hashing kann mithilfe eines verschlüsselten Servers durchgeführt werden. Indem Sie Dinge aufteilen, können Sie mehr als eine Sache erreichen.

Sollten Sie Ihre Mongodb teilen?
Es ist nicht sicher, ob Sharding in einigen Fällen die Leistung verbessert oder nicht, aber es hat sich gezeigt, dass es in einigen Fällen die Leistung erhöht. Darüber hinaus bringt Sharding seine eigenen Herausforderungen mit sich, wie z. B. die Gewährleistung robuster Backups und Wiederherstellungen. Bevor Sie sich für eine Sharding-Strategie entscheiden, sollten Sie sich Gedanken über die Vor- und Nachteile machen.
Sharding in Nosql
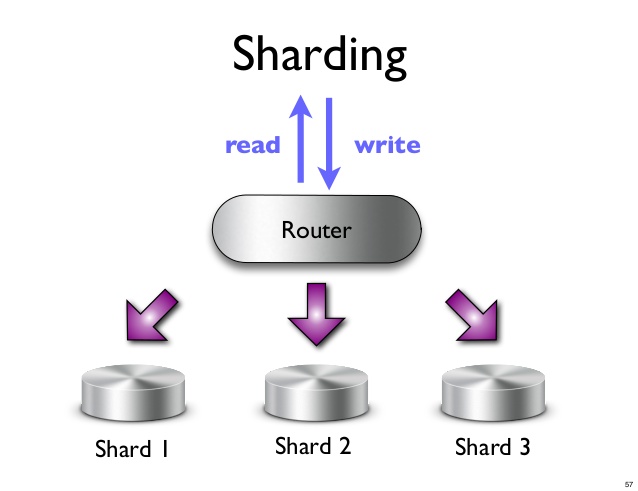
Ein Shard ist eine horizontale Partition von Daten in einer Datenbank oder Suchmaschine. Jeder Shard ist eine unabhängige Datenbank- oder Suchmaschineninstanz. In einer NoSQL-Datenbank kann eine Sammlung von Dokumenten in Shards aufgeteilt werden, die jeweils auf einem separaten Server gespeichert werden.
Sharding vs. Replikation
Der Unterschied zwischen Replikation und Sharding besteht darin, dass Replikation die Duplizierung von Daten ist, während Sharding die Aufteilung von Daten in einzelne Blöcke ist. In diesem Fall haben Sie Ihre Sammlung basierend auf Sharding in mehrere Teile aufgeteilt. Wenn Sie Ihre Datenbank abrufen, erhalten Sie Bilder aller Ihrer Datensätze.
Die Vorteile von Sharding
Die Daten werden auf mehrere Maschinen verteilt, um die Anzahl der gleichzeitigen Benutzer zu erhöhen und die Leistung zu verbessern. Die Daten werden auf separaten Partitionen in jeder der Maschinen gespeichert.
Replikation in Nosql
Es gibt verschiedene Möglichkeiten, wie die Replikation in einer NoSQL-Datenbank gehandhabt werden kann. Eine Möglichkeit besteht darin, dass sich die Datenbank automatisch auf einen sekundären Server repliziert, wenn eine Änderung vorgenommen wird. Dadurch wird sichergestellt, dass immer ein Backup verfügbar ist, falls der primäre Server ausfällt. Eine andere Möglichkeit besteht darin, die Daten regelmäßig manuell auf einen sekundären Server zu replizieren. Dies gibt dem Administrator mehr Kontrolle darüber, wann die Replikation erfolgt, bedeutet aber auch, dass der sekundäre Server im Falle eines Ausfalls möglicherweise nicht auf dem neuesten Stand ist.
Was ist Sharding in der Datenbank?
Sharding ist ein Prozess der horizontalen Partitionierung von Daten in einer Datenbank. Beim Sharding wird eine Datenbank in kleinere Teile, sogenannte Shards, aufgeteilt. Jeder Shard wird auf einem separaten Server gespeichert. Der Sharding-Prozess trägt dazu bei, die Leistung einer Datenbank zu verbessern, indem die Last auf mehrere Server verteilt wird.
Ein einzelnes Datenelement kann mit Hilfe von Sharding in einer einzigen Transaktion repliziert werden. Durch die Aufteilung eines Datensatzes in kleinere Teile und deren Verteilung auf mehrere Server kann die Gesamtspeicherkapazität des Systems erhöht werden. In einigen Fällen kann dies nützlich sein, wenn die Daten groß sind und mehrere Server erforderlich sind, um sie aufrechtzuerhalten. Fremddaten-Wrapper werden auch verwendet, um Daten von entfernten Servern zu lesen, wodurch die Datenspeicherung noch flexibler wird.
Was ist der Unterschied zwischen Partitionierung und Sharding?
Partitionierung und Sharding sind zwei Ansätze, um große Datensammlungen in kleine Fragmente zu strukturieren. Sowohl Sharding als auch Partition bedeuten, dass die Daten auf mehrere Computer verteilt sind, aber sie sind unterschiedlich. Das Verfahren zum Partitionieren einer Datenbankinstanz umfasst das Gruppieren von Teilmengen von Daten darin.
Welche Db eignet sich am besten zum Sharding?
Datenbank-Sharding wird von Cassandra, HBase, HDFS, MongoDB und Redis unterstützt. Die Datenbanken, die PostgreSQL, Memcached, Zookeeper, MySQL und Sqlite nicht nativ unterstützen, werden als Datenbanken betrachtet. Jarryd-Logik muss in einer Anwendung vorhanden sein, wenn sie keine integrierte Unterstützung für Datenbanken hat.
Ist Sharding in SQL möglich?
Es ist jedoch möglich, bereichsbasiertes Sharding (im Wesentlichen horizontal) so zu implementieren, dass es für die Anwendung transparenter wird. In SQL Server erfolgt dies normalerweise über eine partitionierte Ansicht, dies muss jedoch nicht der Fall sein.