
NoSQL-Datenbanken: Webbasierte Datenbanken für hohen Datenverkehr und große Datensätze
Veröffentlicht: 2022-11-18Nosql-Datenbanken sind Web-Scale-Datenbanken, die hohen Datenverkehr und große Datensätze verarbeiten können. Sie sind skalierbar und für hohe Lasten ausgelegt. Eine nosql-Datenbank kann horizontal skaliert werden, indem dem System weitere Server hinzugefügt werden. Dadurch kann das System mehr Verkehr bewältigen und mehr Daten speichern.
Die steigende Nachfrage nach komplexen Anwendungen erfordert eine höhere Flexibilität. Ebenso wichtig ist es, Datenspeicher auszuwählen, die einfach zu skalieren und effizient zu betreiben sind. Die wichtigste Frage ist, ob „ASL“- oder „NoSQL“-Datenbanken besser zum Ausführen einer Anwendung geeignet sind. SQL-Datenbanken sind schon seit geraumer Zeit im Einsatz, aber NoSQL-Datenbanken sind dafür bekannt, dass sie einfacher zu skalieren sind. Für NoSQL-Datenbanken gilt die Annahme, dass Sharding in allen Vorgängen durchgeführt werden sollte. Ein Knoten kann durch eine qualifizierende Funktion identifiziert werden, die von jeder Datenoperation in der Datenbank erwartet wird. Da Daten auf mehreren Computern gespeichert werden, ist es sehr effizient, Datenoperationen selbst auf den einfachsten Computern durchzuführen.
Mit dieser Funktion können einfache Commodity-Maschinen zum Skalieren von NoSQL-Stores verwendet werden. NoSQL geht davon aus, dass der Benutzer die Daten so planen und strukturieren kann, dass sie nur zu einem bestimmten Zeitpunkt für eine bestimmte Operation von demselben Knoten abgerufen werden. Darüber hinaus kann eine Denormalisierung von Daten über Knoten hinweg (vorgekochte Daten für den Start) durchgeführt werden. Es gibt einen Platz für NoSQL-Joins, aber erwarten Sie nicht, dass sie SQL-reich oder optimiert sind. In der Praxis wird davon ausgegangen, dass Daten bei NoSQL-Anwendungen immer konsistent sind. Es gibt zahlreiche NoSQL-Systeme, die Schalter bereitstellen, um die Konsistenz im Laufe der Zeit zu ändern, wenn Konsistenz wichtig ist. Das Ziel jeder Architekturentscheidung ist, wie auch das Ziel der Bewertung des Anwendungsfalls, die Auswahl des geeigneten Datenspeichers.
Ein Ressourcenpool mit horizontaler Skalierung kann durch Hinzufügen weiterer Maschinen erweitert werden, während ein Pool mit vertikaler Skalierung durch Hinzufügen weiterer Maschinen erweitert werden kann.
SQL-Datenbanken und NoSQL-Datenbanken verwenden eine vertikale Skalierung aufgrund der Art und Weise, wie Daten gespeichert werden (verbundene Tabellen im Vergleich zu nicht verwandten Sammlungen), während NoSQL-Datenbanken eine horizontale Skalierung verwenden, da sie keine verwandten Tabellen verwenden.
Die von NoSQL unterstützte Skalierungsart ist horizontal.
Zur horizontalen Skalierung verwendet MongoDB einen integrierten Mechanismus, mit dem Sie Daten über mehrere Server hinweg verschieben können. Dieser Vorgang wird als Sharding bezeichnet und kann durch Drücken einer Umschaltfläche auf der Konfigurationsseite der Atlas-Benutzeroberfläche ausgeführt werden. Abgesehen davon kann der Prozess auch ohne Ausfallzeiten abgeschlossen werden.
Wie funktioniert die horizontale Skalierung in Nosql?
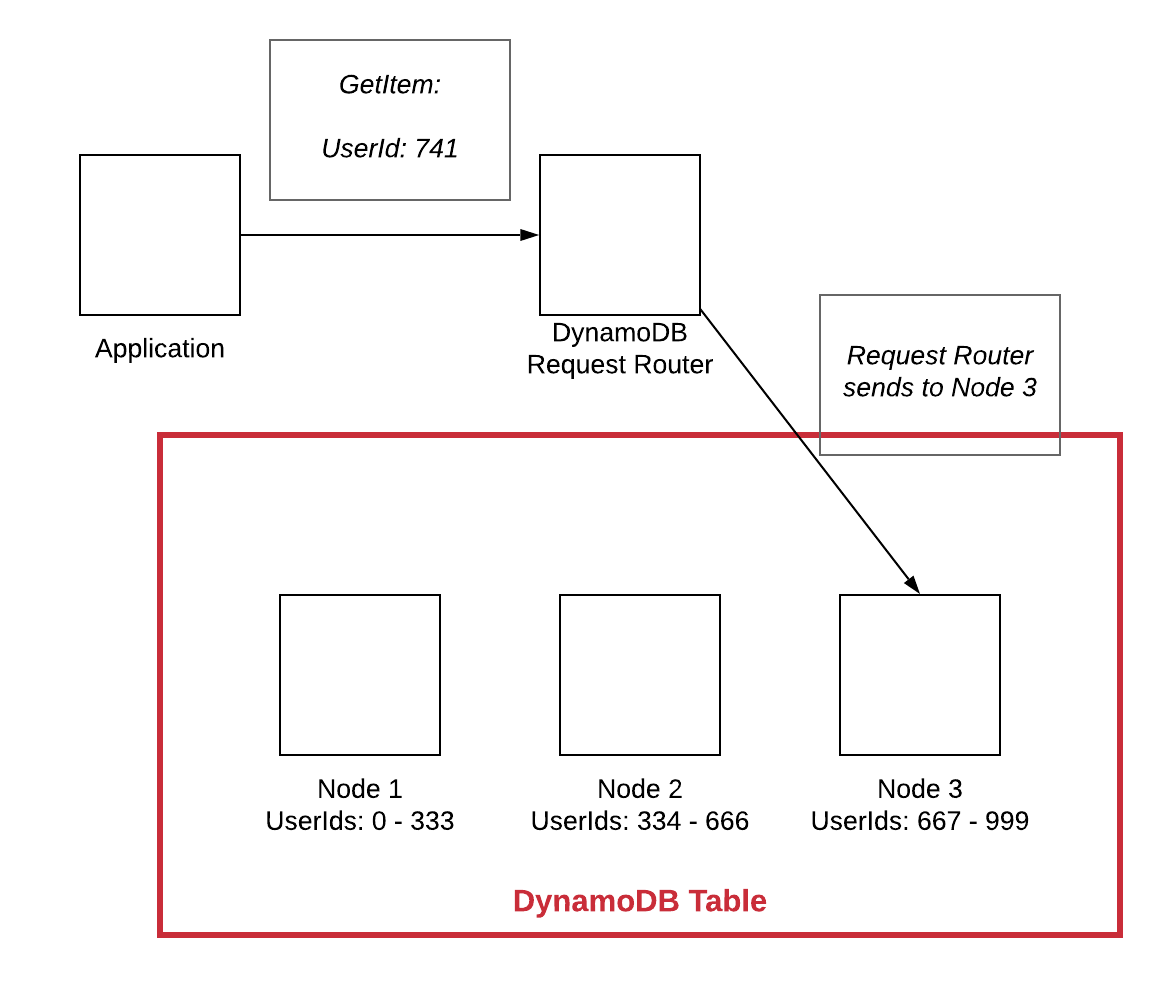
Horizontale Skalierung in einer NoSQL-Datenbank bedeutet, dass die Datenbank skaliert werden kann, indem dem System weitere Maschinen hinzugefügt werden, anstatt eine einzelne Maschine schneller oder leistungsfähiger zu machen. Dadurch kann das System mehr Datenverkehr und Daten verarbeiten, ohne dass es zu Leistungsproblemen kommt.
Die Vorteile der horizontalen Skalierung sind zahlreich: Sie können problemlos weitere Server hinzufügen, um den erhöhten Datenverkehr zu bewältigen, und Sie müssen sich keine Gedanken über das gleichzeitige Laden von Zeilen von mehreren Servern machen. Daher sind NoSQL-Datenbanken eine ausgezeichnete Wahl für Unternehmen, die Daten nach Bedarf speichern und gleichzeitig Geld für die Datenspeicherung sparen möchten.
Nosql-Datenbanken eignen sich besser für die Handhabung großer Datenmengen
Aufgrund der Einschränkungen relationaler Datenbanken können sie keine großen Datensätze verarbeiten. NoSQL-Datenbanken wie MongoDB speichern Ihre Daten in einem eigenständigen Dokumentformat, sodass Sie Ihre Daten auf mehrere Knoten verteilen können. Mit dieser Funktion ist die Datenbank in der Lage, große Datenmengen schnell und einfach zu verarbeiten.
Wie kann Mongodb horizontal skalieren?
MongoDB kann mithilfe von Sharding horizontal skaliert werden. Sharding ist ein Prozess zum Aufteilen von Daten auf mehrere Server. Jeder Server hat seinen eigenen Teil des Datensatzes, und die Daten werden gleichmäßig auf die Server verteilt. Wenn eine Anfrage gestellt wird, bestimmt der MongoDB-Server, welcher Server die angeforderten Daten enthält, und ruft sie von diesem Server ab. Dieser Prozess ermöglicht es MongoDB, horizontal zu skalieren und große Datenmengen zu verarbeiten.
Wenn es um die Skalierung der Infrastruktur geht, haben viele Unternehmen Schwierigkeiten. Die Datenbank-as-a-Service-Plattform von MongoDB unterstützt eine Vielzahl von Skalierungsoptionen und ist in ihr Backend integriert. Die Technik der horizontalen Skalierung wird als Sharding bezeichnet (weil sie bevorzugt wird). Der Begriff „gestufte Skalierung“ bezieht sich auf die Fähigkeit eines einzelnen Servers oder Clusters, nach oben zu skalieren. Es handelt sich um eine horizontale Skalierungsmethode, bei der Daten auf mehrere Knoten verteilt werden. Die MongoDB-Atlas-Plattform konfiguriert automatisch einen Shard-Key, der immer noch an uns liegt. Es ist klar, dass Replikatsätze und Sharding ähnlich sind, aber die Datensätze sind nicht gleich.
Außerdem können sie bei großen Mengen an Schreibtransaktionen für Anwendungen Probleme verursachen. MongoDB Atlas unterstützt auch die horizontale und vertikale Skalierung. Die Bereitstellung eines Sharding-Clusters ermöglicht eine horizontale Skalierung. Kurz gesagt, die vertikale Skalierung ist so einfach wie das Konfigurieren einer Cluster-Ebene. Im Falle eines vollständigen Herunterfahrens kann der Cluster angehalten werden, um den Cluster auf 0 zu halten, wodurch der gesamte Cluster mit Ausnahme des Speichers effektiv auf 0 skaliert wird.
MongoDB ist eine ausgezeichnete NoSQL-Datenbank, ebenso wie eine moderne Anwendung, die horizontal skaliert werden muss, um große Datensätze zu verarbeiten. MongoDB verfügt über eine einfache API, die Entwicklern den Zugriff auf und die Bearbeitung von Daten erleichtert, und die schemafreie Speicherung erleichtert das Speichern und Abrufen von Daten. Da MongoDB die Replikation unterstützt, können Daten außerdem problemlos über mehrere Server repliziert werden, wodurch sichergestellt wird, dass sie für die zukünftige Verwendung verfügbar bleiben.
Skalierbarkeit von Mongodb
MongoDB ist eine der elastischsten Programmiersprachen. In einer dokumentenorientierten Datenbank wie MongoDB werden Daten in JSON-ähnlichen Dokumenten gespeichert. Der MongoDB-Prozess wird durch die Verwendung von Sharding horizontal skaliert. Srave ist eine Datenverteilungstechnik, die mehrere Sammlungen und Computer verwendet, um Daten über Datenbanken und Computer zu verteilen.
Ist Sql Db horizontal skalierbar?
Bei der horizontalen Skalierung werden Datenbanken hinzugefügt oder entfernt, um eine bestimmte Aufgabe auszuführen, z. B. das Erhöhen oder Verringern der Gesamtkapazität oder -leistung. Die horizontale Skalierung wird typischerweise implementiert, indem Daten aus mehreren identisch strukturierten Datenbanken kombiniert und dann in separate Tabellen aufgeteilt werden.
Jede Datenbank muss jeden Tag skaliert werden, um das generierte Datenvolumen zu bewältigen. Die Skalierung wird in zwei Typen eingeteilt: vertikal und horizontal. Der Arbeitsspeicher eines 2-TB-Servers reicht aus, um mehr Daten zu speichern. Es kauft einen großen Server zu einem extrem hohen Preis. Das Hinzufügen weiterer Maschinen zum Server wird als horizontale Skalierung bezeichnet. Sein Ziel ist es, den Datensatz auf mehrere Server oder Shards aufzuteilen. Es wäre sinnlos, einen Single Point of Truth auf der Grundlage von Denormalisierung zu haben. Dieser Ansatz hat einen Nachteil: Wenn der Master beim Ausführen eines Schreibvorgangs die Slave-Repliken nicht aktualisiert, aktualisiert der Master die Slave-Repliken nicht.

Eine Replikation ist der Vorgang des Austauschs von Daten zwischen Knoten in einem Cluster. Durch die Replikation von Daten können Sie die Verfügbarkeit und Wiederherstellung eines Servers erhöhen. Darüber hinaus kann die Replikation verwendet werden, um die Last auf mehrere Knotencluster zu verteilen. Eine Organisation kann ihre Daten horizontal in kleinere Blöcke aufteilen und diese Blöcke auf mehrere Knoten verteilen. Die horizontale Partitionierung verbessert die Leistung. Zusätzlich zu den standardmäßigen MongoDB-Clustern gibt es verschiedene Arten von MongoDB -Clustern . Der Single-Node-Cluster ist im Allgemeinen der einfachste Clustertyp und eignet sich gut für Tests und Entwicklung. Ein Zwei-Knoten-Cluster ist der häufigste Clustertyp und eignet sich für mittlere bis große Anwendungen. Ein Drei-Knoten-Cluster ist ebenfalls beliebt und eignet sich für große Anwendungen. In einem Zwei-Knoten-Cluster werden die Daten beispielsweise auf jedem Knoten in zwei separate Shards aufgeteilt. In diesem Fall hat jeder Knoten eine Kopie der Daten. Wenn die Last eines Knotens wächst, kann der andere Knoten die Last bewältigen. Ein Cluster mit Lastenausgleich ist einer der häufigsten Clustertypen. Ein Drei-Knoten-Cluster besteht aus drei separaten Rechenzentren, von denen jedes drei separate Shards enthält. Wenn die Last eines Knotens steigt, können die anderen beiden Knoten möglicherweise übernehmen. Ein ausgeglichener Cluster ist einer dieser Cluster. Die MongoDB-Datenbank ist eine moderne dokumentbasierte Datenbank mit horizontalen Skalierungsfunktionen: Replikation und horizontale Partitionierung (oder Sharding). Der Prozess der horizontalen Skalierung einer Datenbank beinhaltet das Hinzufügen weiterer Instanzen oder Knoten, um der gestiegenen Nachfrage gerecht zu werden. Wenn Sie mehr Kapazität benötigen, fügen Sie dem Cluster einfach weitere Server hinzu. Darüber hinaus sind Server in der Regel kleiner und kostengünstiger als diejenigen, die für Desktop-Computing verwendet werden. Es ist ein Vorgang zum Kopieren von Daten zwischen Knoten in einem Cluster. Die horizontale Partitionierung von Daten unterteilt sie in kleinere Blöcke und verteilt sie auf mehrere Knoten in einem verteilten System. Es gibt verschiedene Arten von MongoDB-Clustern, die jeweils unterschiedliche Funktionen aufweisen. Drei-Knoten-Cluster sind ebenfalls üblich, obwohl sie nicht so effektiv sind wie ein Vier-Knoten-Cluster.
Horizontal skalieren mit einer relationalen Datenbank
Eine herkömmliche SQL-Datenbank kann normalerweise nicht horizontal skaliert werden, da sie mehr Server aufnehmen muss, aber wir können dennoch Repliken anderer Computer hinzufügen. Das Write-Ahead-Protokoll wird verwendet, um alle Schreiboperationen vom Hauptserver an andere Computer weiterzugeben. Aufgrund der Flexibilität der Abfragesyntax können relationale Datenbanken nicht horizontal skaliert werden. Um sicherzustellen, dass keine Teile Ihrer Daten abgerufen werden, bis Sie Ihre Abfrage ausführen, können Sie mit SQL so viele Bedingungen und Filter zu Ihren Daten hinzufügen, dass es für Ihre Datenbank unmöglich ist, vorherzusagen, welche Teile abgerufen werden. Als Ergebnis kann die Datenbank träge werden, wenn sie versucht, große Datenmengen zu verarbeiten. Da relationale Datenbanken horizontal skaliert werden können, können sie dazu beitragen, Bereiche abzudecken, in denen Spark normalerweise weniger effektiv ist, sei es als Speichermedium für Spark-Streaming oder Batch-Berechnungen. Die Cloud-SQL-Plattform unterstützt diese Konfigurationen nicht nativ, sie können jedoch mit Branchentools wie ProxySQL implementiert werden. Das zugrunde liegende Konzept von Cloud SQL ist jedoch nicht für diese Art von Szenarien vorgesehen.
Warum ist Nosql horizontal skalierbar?
NoSQL-Datenbanken können je nach Bedarf horizontal oder vertikal skaliert werden. Sie können Situationen mit hohem Datenverkehr bewältigen, indem Sie Ihre NoSQL-Datenbank fragmentieren und dem Prozess weitere Server hinzufügen. NoSQL-Datenbanken sind die bevorzugte Wahl für große und sich häufig ändernde Datensätze, da sie horizontal statt vertikal skaliert werden können.
Es sollte in der Lage sein, sehr große Datenbanken mit sehr hohen Anforderungsraten bei sehr geringer Latenz zu verarbeiten. Skalierung und Verfügbarkeit sind entscheidende Anforderungen für hochvolumige Websites wie eBay, Amazon, Twitter und Facebook. Wenn Sie mehrere Instanzen gleichzeitig auf einem Server ausführen können, ist die horizontale Skalierung ideal.
Aufgrund ihrer Skalierbarkeit und Flexibilität gewinnen NoSQL-Datenbanken im Vergleich zu SQL-Datenbanken an Popularität. Darüber hinaus bieten sie im Vergleich zu tabellenbasierten Datenbanken eine bessere Leistung für unstrukturierte Daten, die schwierig zu verarbeiten und zu speichern sind.
So skalieren Sie eine Nosql-Datenbank
Auf diese Frage gibt es keine allgemeingültige Antwort, da die beste Methode zur Skalierung einer NoSQL-Datenbank von den spezifischen Anforderungen der Anwendung und den zu speichernden Daten abhängt. Einige Tipps zum Skalieren einer NoSQL-Datenbank umfassen jedoch das Hinzufügen weiterer Knoten zum Cluster, um die Kapazität und Leistung zu erhöhen, das Verwenden von Sharding zum Verteilen von Daten auf mehrere Knoten und das Replizieren von Daten auf mehrere Knoten, um eine hohe Verfügbarkeit sicherzustellen.
Mehrere wichtige Punkte werden behandelt, während Rahim Yaseen von Couchbase uns durch sie führt. Unternehmen bemühen sich, ihre riesigen Datenmengen zu verwalten, zu speichern und zu monetarisieren. Eine wichtige Datenbankentscheidung ist, ob horizontal skaliert werden soll oder nicht. Die Registrierung wird im manuellen Sharding auf die Check-in-Schalter verteilt. Dies wird aufgrund eines wohldefinierten, vordefinierten Schemas erreicht. Im Rahmen des Autosharding müssten Sie zu jeder Kabine gehen, um herauszufinden, wer mit einem Nachnamen, der mit S beginnt, eingecheckt hat. Dokumentendatenbanken haben Zugriffsmuster, bei denen Benutzer über einen bestimmten Schlüssel zu einem anderen Dokument navigieren und über einen einzigen auf die Daten zugreifen müssen Schlüssel. Mit zunehmender Größe eines verteilten Datensatzes wird es immer schwieriger, ihn zu indizieren und abzufragen.
Es ist sinnlos, eine Map-Reduce-Technik zu verwenden, da jeder Knoten in der Abfrage daran teilnehmen muss. Mit zunehmendem Datenvolumen wird die Skalierung des RDBMS-Modells immer weniger machbar. Im Fall eines großen Datensatzes ist das Versagen einer Scale-up-Architektur wahrscheinlich ein sehr großer Fehlerpunkt. Das Internet ist ein Beispiel für einen Ultrascale-Shared-Nothing-Cluster.
Nosql-Datenbanken: Die Zukunft der Skalierbarkeit
Da Daten in Nosql-Datenbanken über mehrere Computer gesendet werden, sind sie extrem skalierbar. Anstatt teure Maschinen zu kaufen, die spezielle Ausrüstung erfordern, können wir daher ganz einfach CPU-Leistung hinzufügen. Darüber hinaus können Nosql-Datenbanken unbegrenzt große Datenmengen speichern, was sie zu einem sehr vielseitigen Datenverwaltungssystem macht.
Kann Sql-Datenbank horizontal skalieren
Ja, SQL-Datenbanken können horizontal skaliert werden. Das bedeutet, dass sie auf mehrere Server verteilt werden können, von denen jeder einen Teil der Gesamtdaten verarbeitet. Dies ermöglicht eine größere Skalierbarkeit , als sie ein einzelner Server bieten könnte.
Warum sind SQL-Datenbanken nicht horizontal skalierbar?
Aufgrund der Flexibilität der Abfragesyntax ist eine horizontale Skalierung in einer relationalen Datenbank nicht möglich. Als Ergebnis von SQL können Sie Ihren Daten beliebig viele Bedingungen und Filter hinzufügen, die verhindern, dass das Datenbanksystem weiß, welche Teile davon zurückgegeben werden, bis die Abfrage abgeschlossen ist.
Warum skaliert SQL vertikal?
Das Ziel der vertikalen Skalierung besteht darin, den Stromverbrauch und die RAM-Kapazität bestehender Systeme zu erhöhen und damit im Wesentlichen die verfügbaren Ressourcen zu erhöhen. Die vertikale Skalierung ist nicht nur einfacher, sondern auch kostengünstiger. Das Problem erfordert auch keine langfristige Lösung.