
Pig: Eine High-Level-Plattform für Apache Hadoop
Veröffentlicht: 2023-02-22Pig ist eine High-Level-Plattform zum Erstellen von Programmen, die auf Apache Hadoop ausgeführt werden. Der Begriff „Pig“ bezieht sich auf die Infrastrukturebene der Plattform, die aus einer Compiler- und Ausführungsumgebung sowie einer Reihe von High-Level-Operatoren besteht. Die Infrastrukturschicht von Pig bietet Entwicklern eine Reihe von Tools zum Erstellen, Warten und Ausführen ihrer Pig-Programme. Pig ist ein Open-Source-Projekt, das Teil des Apache Hadoop-Ökosystems ist. Das Programmiermodell von Pig basiert auf Datenfluss, was es einfach macht, Programme zu schreiben, die große Datenmengen verarbeiten. Pig-Programme bestehen aus einer Reihe von Operatoren, die in einem gerichteten azyklischen Graphen ausgeführt werden. Pig ist eine großartige Wahl für die Verarbeitung großer Datenmengen, da es skalierbar, effizient und einfach zu bedienen ist.
Als NoSQL-Lösung benötigen Sie spezifische, vordefinierte Möglichkeiten zur Analyse und zum Zugriff auf Daten. SQL (UNION, INTERSECT usw.) ist ein gängiger Abfrageausdruck, der in der Welt von Big Data nicht sehr oft verwendet wird. Da Hive für Batch- und Big-Data-Verarbeitung optimiert ist, ist es am besten, jede Zeile zu berühren. Hive wendet viel weniger Zeit und Geld für den Betrieb auf als Hadoop, was den Vorteil der Skalierung bietet. Selbst kleine Abfragen auf Entwicklungssystemen können um Größenordnungen langsamer sein als ähnliche Abfragen auf RDBMS. Hive speichert keine Abfrageergebnisse im Cache. Das erneute Senden einer wiederholten Abfrage ist eine gängige Praxis in MapReduce.
Es gibt zwei Arten von Hive: 1) Hive ist keine Datenbank; vielmehr handelt es sich um eine Abfrage-Engine, die für Abfragedaten spezifische SQL-Teile unterstützt. b) Hive ist eine Datenbank mit SQL-Unterstützung. c) Hive ist eine SQL-spezifische Datenbank. Hive ist ein SQL-basiertes Data-Warehouse-System für Hadoop, das unter anderem Pig und Python enthält; Hive wird zum Speichern von Hadoop-Daten verwendet.
Ist Pig ein SQL?
Auf diese Frage gibt es keine richtige oder falsche Antwort, da es auf die persönliche Meinung ankommt. Einige Leute glauben vielleicht, dass Pig ein SQL ist, während andere dies nicht tun. Letztendlich ist es jedem selbst überlassen, ob es sich bei Pig um eine SQL handelt oder nicht.
Heute sind Apache Hive und Pig zwei Begriffe, die schnell zum Synonym für Big Data werden. Mit diesen Tools können Datenentwickler und Analysten die Komplexität von MapReduce reduzieren und gleichzeitig ein hohes Maß an Datenintegrität beibehalten. Hive ist eine Data-Warehouse-Infrastruktur, die auch als ETL-Tool (Extraction, Loading, and Transformation) bekannt ist. Apache Hive, Pig und SQL sind drei beliebte Tools für die Datenanalyse und -verwaltung. Sie müssen sich darüber im Klaren sein, welche Plattform für Ihre Bedürfnisse am besten geeignet ist und wie oft Sie sie verwenden sollten. Schauen wir uns die drei verschiedenen Möglichkeiten an, Hive, Pig und SQL im Kontext dieser drei Technologien zu verwenden. Trotz der Dominanz von Apache Hive und Apache Pig ist SQL immer noch der König der Big-Data-Verwaltung und -Analyse. Da jede eine bestimmte Funktion erfüllt, sind ihre Anforderungen auf das Unternehmen zugeschnitten. Apache Pig basiert auf Skripten und erfordert spezielle Kenntnisse, während Apache Hive die einzige Datenbanklösung ist, die für den Entwickler nativ ist.
Schwein ist ein vielseitiges Tier mit viel Flexibilität. Pig kann beispielsweise Protokolldateien verarbeiten, die JSON- oder XML-Daten enthalten, sodass Sie die Daten lesen können. Es ist auch möglich, Daten von Webdiensten in Pig zu speichern.
Kartendatentypen, Tupel und Taschendatentypen können austauschbar verwendet werden. Sie sind in der Lage, Daten aus beliebigen Quellen zu verarbeiten.

Ist Pig ein Etl-Tool?
Auf diese Frage gibt es keine endgültige Antwort, da dies davon abhängt, wie Sie ein ETL-Tool definieren. Im Allgemeinen ist ein ETL-Tool eine Softwareanwendung, mit der Sie Daten aus einer oder mehreren Quellen extrahieren, in ein mit Ihrem Zielsystem kompatibles Format umwandeln und in dieses System laden können. Einige Leute würden sagen, dass Pig ein ETL-Tool ist, weil es all diese Funktionen ausführen kann. Andere könnten argumentieren, dass Pig kein ETL-Tool ist, weil es nicht speziell für die Datentransformation entwickelt wurde. Letztendlich hängt die Antwort auf diese Frage von Ihrer eigenen Definition eines ETL-Tools ab.
Wie können Sie Pig für die Etl-Verarbeitung verwenden?
Eine Pig-Anwendung kann als ETL-Transaktionsmodell beschrieben werden, das beschreibt, wie ein Prozess Daten aus einem Objekt extrahiert und sie basierend auf einem Regelsatz in einen Datenspeicher umwandelt. Benutzer definieren die benutzerdefinierten Funktionen (UDF) des Schweins, um Daten aus Dateien, Streams und anderen Quellen aufzunehmen.
Was ist Pig-Tool?
Eine Plattform oder ein Tool namens Pig verarbeitet große Datensätze. Diese Bibliothek enthält eine hohe Abstraktionsebene für die Verarbeitung von Daten im MapReduce-Prozess. Pig Latin ist eine High-Level-Skriptsprache, die im Codierungsprozess verwendet wird, um die Datenanalysecodes zu entwickeln.
Was ist der Unterschied zwischen Pig und SQL?
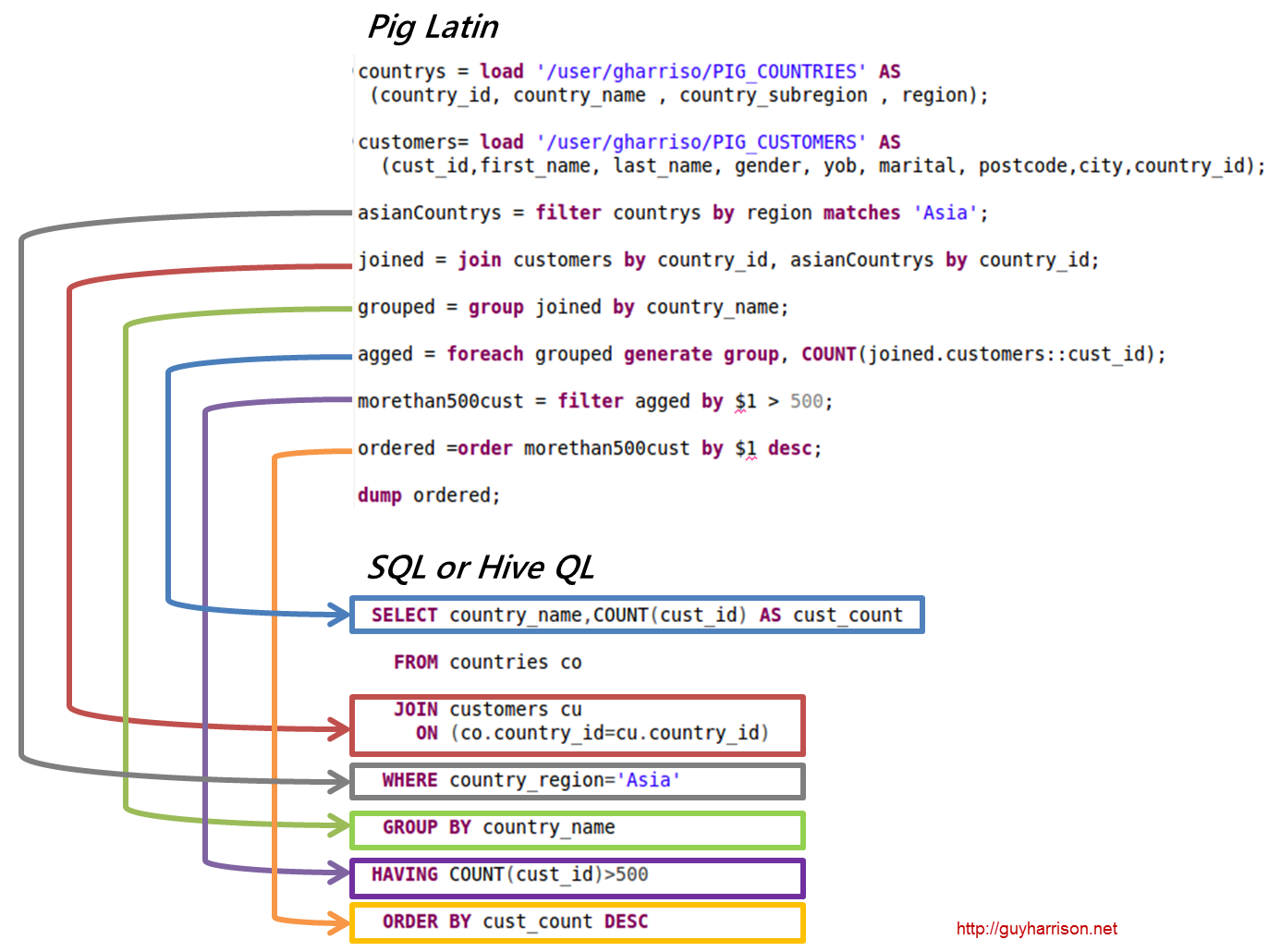
SQL Pig Latin und Apache Pig sind prozedurale Sprachen. SQL ist eine Skriptsprache mit deklarativem Charakter. Es liegt ganz bei Apache Pig, ob ein Schema verwendet wird oder nicht. Daten können ohne die Notwendigkeit eines Schemas gespeichert werden (Werttypen werden in $, $ usw. gespeichert).
Ist Pig Teil von Hadoop?
Eine Pig-Hadoop-Anwendung ist eine höhere Programmiersprache, mit der riesige Datenmengen analysiert werden können. Das Pig Hadoop-Projekt von Yahoo! war eines der ersten Hadoop-Projekte . Im Allgemeinen führt es einen erheblichen Teil der Datenverwaltungsarbeit aus, wenn Hadoop ausgeführt wird.
Im Bereich der Analyse großer Datenmengen ist Pig Hadoop eine höhere Programmiersprache. Um Daten mit Apache Pig zu analysieren, müssen wir zunächst Skripte mit Pig Latin schreiben. Skripte, die in MapReduce-Aufgaben umgewandelt werden. Dies wird durch die Verwendung von Pig Engine, einer Apache Pig-Erweiterung, erreicht. Indem Sie die folgenden Schritte ausführen, können Sie Apache Pig unter Linux/CentOS/Windows (über VM oder Cloudera) installieren. Der erste Schritt besteht darin, Apache Pig herunterzuladen und zu installieren. Der zweite Schritt besteht darin, die Apache Pig-Umgebungsvariablen mithilfe der bashrc-Datei zu ändern.
Bestimmen Sie in Schritt 3 die Pig-Version . Diese Datei kann nach dem Verschieben in einem anderen Verzeichnis gespeichert werden. Der fünfte Schritt besteht darin, die Grunt Shell (das Skript zum Ausführen von Pig Latin) zu starten, indem Sie auf den Befehl Pig klicken.
Warum Pig Latin die beste High-Level-Skriptsprache für die Datenanalyse ist
Der Pig Latin-Datenanalysecode ist in einer höheren Skriptsprache geschrieben. Es handelt sich um eine SQL-ähnliche Sprache, die Datenflüsse parallel verarbeiten soll.
Beispiel Apache-Schwein
Pig ist eine High-Level-Plattform zum Erstellen von Programmen, die auf Apache Hadoop ausgeführt werden. Die Sprache für diese Plattform heißt Pig Latin. Pig kann seine Hadoop-Jobs in MapReduce, Tez oder Spark ausführen. Pig Latin abstrahiert die Programmierung von der Java MapReduce-Sprache in eine Notation, die die MapReduce-Programmierung vereinfacht. Die folgende Pig Latin-Anweisung entspricht beispielsweise dem obigen Java MapReduce-Code: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); DUMP A;