
Skalierung einer NoSQL-Datenbank: Tipps und Tricks
Veröffentlicht: 2022-11-18NoSQL-Datenbanken werden immer beliebter, da die von Unternehmen generierte Datenmenge weiterhin exponentiell wächst. Viele Unternehmen zögern jedoch, auf NoSQL umzusteigen, weil sie befürchten, dass es schwieriger zu skalieren ist. Das Skalieren einer NoSQL-Datenbank unterscheidet sich eigentlich nicht wesentlich vom Skalieren einer relationalen Datenbank. Der Hauptunterschied besteht darin, dass NoSQL-Datenbanken so konzipiert sind, dass sie horizontal skalierbar sind, was bedeutet, dass sie skaliert werden können, indem sie dem System weitere Knoten hinzufügen. Dies steht im Gegensatz zu relationalen Datenbanken , die vertikal skalierbar sind, was bedeutet, dass sie nur skalieren können, indem sie einem einzelnen Server mehr Ressourcen hinzufügen. Beim Skalieren einer NoSQL-Datenbank sind einige Dinge zu beachten: 1. Stellen Sie sicher, dass Ihre Daten gleichmäßig auf alle Knoten verteilt sind. 2. Fügen Sie nach und nach Knoten hinzu, um eine Überlastung des Systems zu vermeiden. 3. Überwachen Sie die Leistung des Systems genau, um Engpässe zu identifizieren. 4. Stimmen Sie das System regelmäßig ab, um eine optimale Leistung sicherzustellen. Mit diesen Tipps sollte die Skalierung einer NoSQL-Datenbank nicht schwieriger sein als die Skalierung einer relationalen Datenbank.
Je nach Typ gibt es zahlreiche Methoden und Prinzipien, um eine Datenbank zu skalieren. Die Skalierung von NoSQL- und SQL-Datenbanken ist abhängig vom Konzept des Datenbank-Shardings. Die Vorteile, mehr Daten speichern zu können, ergeben sich, wenn Server verteilt werden, aber wir übernehmen auch die Probleme, die mit der Verteilung einhergehen. Automatisches Sharding wird von einer monolithischen Datenbank nicht unterstützt, und Ingenieure müssten manuell Logik schreiben, um damit umzugehen. Um dieses Problem zu lösen, kann vor dem Abfragedienst und der Datenbank ein Proxy, z. B. ein Load Balancer, installiert werden. Wir können schnellere Abfragen erhalten, wenn der Shard groß ist, da dieser Proxy erneut verwendet werden kann. Mangels Kenntnis der Endbenutzer ist die Skalierung von NoSQL-Datenbanken weitgehend unsichtbar.
Jeder Shard ist einzigartig, im Gegensatz zu einer Master-Slave-Architektur. Wenn es Leseanfragen auf dem Master-Shard gibt, wird eine Anfrage an die Slave-Shards gesendet. Auf Rechenzentrumsebene können wir die Datenbank replizieren, um sicherzustellen, dass wir über ein Backup verfügen. Der Knoten ist ein Knoten, der mit anderen Knoten kommunizieren und Informationen austauschen kann. Jeder Knoten kommuniziert über ein Protokoll mit einer festen Anzahl anderer Knoten. Da alle Knoten in Cassandra gleich sind, kann ein Knoten seine Daten von einem zum nächsten replizieren, ohne sich Gedanken über den Verlust von Daten machen zu müssen. Das Gossip-Protokoll ist eine der vielen Möglichkeiten, wie Knoten Informationen austauschen können.
Eine verteilte Datenbank kann neben dem Erhalt zusätzlicher Eigenschaften eine Reihe von Vorteilen haben. Eine entscheidende Komponente zur Sicherstellung der Verfügbarkeit ist die Datenreplikation. Wenn Sie die asynchrone Replikation für Ihre Datenbank verwenden, ist diese anfangs nicht immer vollständig konsistent, wird aber mit der Zeit immer konsistenter. SQL-Datenbanken werden in Finanzanwendungen verwendet, die eine hohe Datenpräzision erfordern, während NoSQL-Datenbanken in weniger bedeutenden Anwendungen wie der Zählung von Ansichten verwendet werden.
Vertikale Skalierung bezieht sich auf den Prozess der schrittweisen Erhöhung der Rechenlast durch Hardware-Upgrades. Der Wechsel zu einer verteilten Architektur und das Hinzufügen weiterer Computer zur Lösung unseres Problems erfordert eine Skalierung nach außen, auch bekannt als horizontale Skalierung oder Skalierung.
NoSQL kann die Skalierung basierend auf horizontalen Methoden unterstützen.
MongoDB ist als NoSQL-Datenbank skalierbar, da ihre Daten nicht in relationalen Datenbanken gespeichert werden. Daten werden als JSON-ähnliche Dokumente gespeichert, auf die über eine HTTP-Anfrage leicht zugegriffen werden kann. Mit dieser Methode kann die Dokumentenverteilung horizontal über mehrere Knoten erfolgen.
Wie skalieren Sie die Nosql-Datenbank?
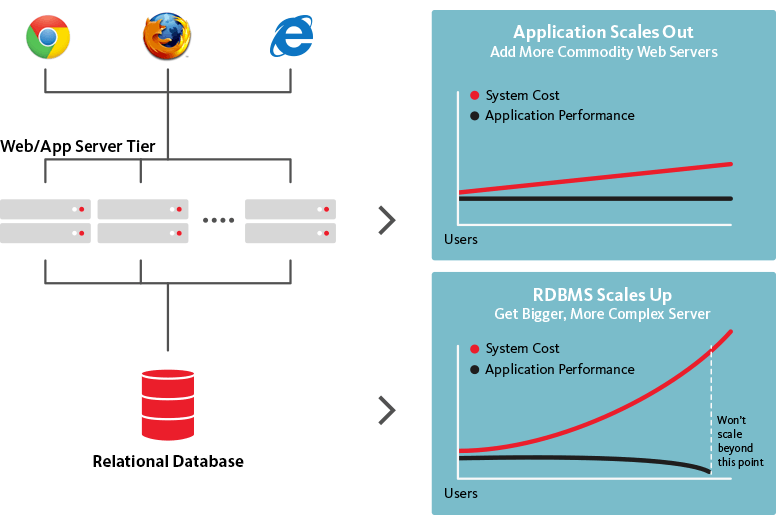
NoSQL-Datenbanken hingegen sind horizontal skalierbar, was bedeutet, dass sie bei Bedarf erhöhten Datenverkehr bewältigen können, indem sie einfach weitere Server zur Datenbank hinzufügen. Da NoSQL-Datenbanken in viel größere und leistungsfähigere Strukturen umgewandelt werden können, ist es die logische Wahl für große Datensätze und sich ständig weiterentwickelnde Datenbanken.
Damit dieses Tutorial funktioniert, müssen Sie über eine funktionierende Node.js-Umgebung verfügen. In diesem Beitrag werde ich die DynamoDB- Dateien in einen Ordner namens nodejs-dynamodb-sample entpacken. Eine detaillierte Version davon finden Sie auf meiner GitHub-Seite: https://www.gofundme.com/adamfowleruk/nodesurvey.html. Die Beispiel-App kann Filminformationen aus DynamoDB suchen und abrufen. Wir werden Daten in S3 auf Amazon Web Services speichern und über den Identity and Access Management Service (IAM) von Amazon auf DynamoDB zugreifen. Um den In-App-Analytics-Service von Amazon nutzen zu können, müssen Sie sich zunächst registrieren und ein Konto erstellen. Notieren Sie sich das Jahr und den Titel jedes Films, den Sie veröffentlichen möchten /movies.
Sie können ein Schlüsselfeld eingeben, um Filme aus einem bestimmten Jahr zu finden. Anschließend können Sie Ihre eigene Anwendung von Grund auf entwerfen. Sie können Ihre Tabellen verwenden, bis Sie sie fertiggestellt haben, aber Sie sollten sie löschen, sobald sie verwendet wurden. Besuchen Sie die DynamoDB-Konsole auf Amazon Web Services, um zu sehen, wie viel Speicherplatz Sie bisher verwendet haben. Auf der Registerkarte „Filme“ können Sie die Elemente in einer Tabelle und die Messwerte Ihrer Anwendung sowie die geschätzten monatlichen Kosten pro Monat auf der Registerkarte „Kapazität“ anzeigen. Dieser Code ist auf meiner GitHub-Seite zu finden: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase und Cassandra sind drei NoSQL-Datenbanken, die sich ideal für die horizontale Skalierung eignen. Da ihre Datenstrukturen horizontaler sind, erleichtert dies das Hinzufügen weiterer Server zum System, während gleichzeitig die Notwendigkeit entfällt, sie zu ändern. Darüber hinaus sind diese Datenbanken relativ neu und werden daher noch entwickelt und verfeinert, was bedeutet, dass sie sich im Laufe der Zeit wahrscheinlich verbessern werden.
Warum ist es einfach, Nosql zu skalieren?
Nosql ist einfach zu skalieren, da es so konzipiert ist, dass es horizontal skalierbar ist. Dies bedeutet, dass es skaliert werden kann, indem einem nosql-Cluster weitere Knoten hinzugefügt werden. Nosql ist auch einfach zu skalieren, da es große Datenmengen und eine große Anzahl von Abfragen pro Sekunde verarbeiten kann.
Anwendungen erfordern ein hohes Maß an Skalierbarkeit, um ordnungsgemäß zu funktionieren. Ebenso wichtig ist die Auswahl von Datenspeichern mit einer einfachen und effizienten Benutzeroberfläche. Der Hauptstreitpunkt ist, ob die Verwendung einer 'ASL'- oder 'Nosql'-Datenbank besser ist. NoSQL-Datenbanken sind im Gegensatz zu SQL-Datenbanken beliebt, weil sie einfach zu erstellen sind. Das Stoppen aller Vorgänge in einer NoSQL-Datenbank ist von Natur aus abhängig von Sharding. Im Allgemeinen erfordert jede Datenoperation die Verwendung eines qualifizierenden Operators, der verwendet werden kann, um einen Knoten mit den Daten zu identifizieren. Daten werden auf mehreren Computern gespeichert, was es sehr einfach macht, Datenoperationen selbst auf den kleinsten Computern durchzuführen.

Infolgedessen können NoSQL-Speicher so skaliert werden, dass sie eine relativ einfache Commodity-Maschine verwenden. Es wird davon ausgegangen, dass Benutzer die Daten so planen und strukturieren, dass sie auf einmal von demselben Knoten abgerufen werden können, um eine bestimmte Operation in der NoSQL-Datenbank auszuführen. Das Denormalisieren von Daten auf diese Weise könnte auch bedeuten, dass der Knoten bereit ist, vorgekochte Daten auszuführen. Joins in NoSQL sind möglich, aber sie sind nicht so robust wie SQL-Joins. In der praktischen Welt von NoSQL glauben Anwendungsdesigner, dass die Datenkonsistenz irgendwann eintreten wird. Neben der Bereitstellung von Schaltern zum Anpassen der Konsistenz zwischen verschiedenen NoSQL-Systemen bieten viele NoSQL-Systeme Routinen, um die Konsistenz hervorzuheben. Ein wichtiger Bestandteil jeder Architekturentscheidung ist die Bewertung des Anwendungsfalls und die Auswahl des geeigneten Datenspeichers basierend auf diesem Fall.
Sind alle Nosql-Datenbanken skalierbar?
Infolge der Internet- und Cloud-Computing-Ära wurden NoSQL-Datenbanken erstellt, um die Implementierung einer Scale-out-Architektur zu erleichtern. Skalierbarkeit wird erreicht, indem die Speicherung von Daten mit der Arbeit kombiniert wird, die erforderlich ist, um sie auf einer großen Anzahl von Computern in einer Scale-out-Architektur zu verarbeiten.
Das System sollte in der Lage sein, extrem große Datenbanken mit sehr geringer Latenz zu verarbeiten und gleichzeitig sehr hohe Anforderungsraten zu verarbeiten. Bei großvolumigen Websites wie eBay, Amazon, Twitter und Facebook sind Skalierbarkeit und Hochverfügbarkeit entscheidend. Mit horizontaler Skalierung können Sie mehrere Instanzen eines Servers gleichzeitig ausführen.
Die Datenbank von MongoDB ist in Bezug auf Umfang und Anzahl der Benutzer sowohl horizontal als auch vertikal skalierbar. In MongoDB können Sie Ihren Cluster vertikal oder horizontal skalieren, indem Sie weitere Ressourcen hinzufügen und Ihre Daten in kleinere Blöcke aufteilen. Daher ist MongoDB eine beliebte Wahl für umfangreiche Anwendungen und Datenspeicher.
Beste Nosql-Datenbanken für schnelle Skalierung und hohes Datenvolumen
Andere NoSQL-Datenbanken können genau wie andere Datenbanken an Ihre spezifischen Anforderungen angepasst werden. MongoDB zum Beispiel ist eine beliebte Programmiersprache, weil sie schnell skalieren und viele Daten verarbeiten kann. Auf Redis basierende Datenspeicher sind aufgrund ihrer In-Memory-Fähigkeiten und Geschwindigkeit weit verbreitet.
Vertikale Nosql-Skalierung
Nosql-Datenbanken sind horizontal skalierbar, was bedeutet, dass sie erhöhten Datenverkehr bewältigen können, indem sie dem System weitere Knoten hinzufügen. Dies steht im Gegensatz zur vertikalen Skalierung, bei der das System skaliert wird, indem einem einzelnen Knoten weitere Ressourcen hinzugefügt werden.
Jede Datenbank muss skaliert werden, um die täglich generierte Datenmenge zu bewältigen. Der Begriff „Skalierung“ wird in zwei Arten eingeteilt: vertikal und horizontal. Wenn Sie mehr Daten speichern möchten, sollten Sie in einen 2-TB-Server investieren. Ein einzelner Server wird immer teurer und größer. Das Hinzufügen von Maschinen zu einem Server führt zu einer horizontalen Skalierung. In diesem Fall werden Daten in einen Satz aufgeteilt und auf mehrere Server oder Shards verteilt. Da es dem Denormalisierungsmodell folgt, ist kein Single Point of Truth erforderlich. Dieser Ansatz führt möglicherweise nicht zu einer Aktualisierung von Informationen, wenn der Master einen Schreibvorgang nicht durchführt, da er keine Informationen auf Slave-Replikaten aktualisiert, wenn der Master einen Schreibvorgang nicht durchführt.
Was ist vertikale Skalierung in SQL?
Das Ziel des vertikalen Skalierungsansatzes besteht darin, die Kapazität einer einzelnen Maschine zu erhöhen, indem die Ressourcen desselben logischen Servers erhöht werden. Vorhandene Software muss mit Ressourcen wie Arbeitsspeicher, Speicherplatz und Verarbeitungsleistung aufgerüstet werden, um optimal zu funktionieren.
So skalieren Sie die Datenbank horizontal
Was ist horizontale Skalierung und wie funktioniert sie? Ein horizontales Skalierungsverfahren ist eines, das das Hinzufügen zusätzlicher Knoten erfordert, um die Last aufzunehmen. Dies ist bei relationalen Datenbanken äußerst schwierig, da es schwierig ist, zusammengehörige Daten über Knoten zu verteilen.
Zusätzlich zum Hinzufügen weiterer Instanzen zum Teilen der Last bedeutet das horizontale Skalieren (oder Aufskalieren), dass die Anzahl der Instanzen einer Anwendung oder eines Dienstes erhöht wird. Im Gegensatz dazu erfordert die vertikale Skalierung das Hinzufügen weiterer Ressourcen zur Instanz, z. B. CPU-Leistung und Arbeitsspeicher. Aufgrund der zugrunde liegenden Protokolle von HTTP, den meisten Web-Apps und APIs können sie problemlos unabhängig voneinander skaliert werden. Einige Datenbanken ermöglichen es Ihnen jetzt, Ihre geschriebenen Daten zwischen mehreren Instanzen zu synchronisieren und zu teilen. Wenn der Datenverkehr auf diese Weise geleitet wird, werden den am häufigsten angeforderten Elementen mehr Ressourcen zugewiesen. Obwohl Reverse-Proxys häufig verwendet werden, um HTTP-Anforderungen zu verarbeiten, werden dafür nicht immer Datenbanken verwendet. Die meisten Datenbanken können mit Software wie nginx oder HAproxy weitergeleitet werden, die beide auf TCP-Ebene durchgeführt werden können.
Wenn Ihr Proxy verstehen kann, wie die Verbindungen auf Protokollebene funktionieren, kann er feststellen, ob ein Lesereplikat nicht synchron ist oder nicht reagieren kann, selbst wenn die Netzwerkverbindung aktiv ist. Die Route kann je nach Auslastung des Replikats sowie der Anzahl der Verbindungen angepasst werden. Es gibt einige Proxy-Server, die eine Vielzahl von Funktionen ausführen können. Bei persistenten Volumes und Ansprüchen wurden einige Fortschritte erzielt, aber es gibt auch inhärente Schwierigkeiten, wenn Sie keine Datenbank auswählen, die jede Instanz gleichermaßen bewertet. Da Container im Cluster verschoben werden, sollte der Neustart einer Ihrer Read Replicas in Ordnung sein. Wenn dies der Hauptdatenbank passiert, werden Sie wahrscheinlich nicht begeistert sein.