
Solr – Eine leistungsstarke Suchplattform
Veröffentlicht: 2022-11-18Solr ist eine leistungsstarke Suchplattform, mit der Sie große Datenmengen sehr schnell abfragen können. Es baut auf der Apache Lucene-Suchbibliothek auf und bietet eine REST-ähnliche API zur einfachen Integration in Ihre Anwendung. Eines der Hauptmerkmale von Solr ist seine Skalierbarkeit – es kann problemlos Milliarden von Dokumenten und Abfragen verarbeiten. Solr wird oft als NoSQL-Datenbank bezeichnet, da es nicht das traditionelle relationale Datenbankmodell verwendet. Es ist jedoch wichtig zu beachten, dass Solr keine herkömmliche Datenbank ist und nicht als solche verwendet werden sollte. Es dient der Indexierung und Suche, nicht der Speicherung von Daten. Wenn Sie Daten speichern müssen, sollten Sie eine NoSQL-Datenbank wie MongoDB oder Cassandra verwenden.
Mit Elasticsearch als einzigem Open-Source-Projekt, das mit Solr konkurrieren kann, ist Solr eine der beiden beliebtesten Open-Source-Suchmaschinen der Welt. NoSQL steht für Not Only SQL, was bedeutet, dass es Abfragesprachen verwendet, die von herkömmlichem SQL und nicht nur Datenbanken getrennt sind. Trotz seiner hervorragenden Volltextsuchfunktion kann Solr in einer NoSQL-Datenbank äußerst nützlich sein. Gesundheitsdaten wurden über ältere Explorys- und Worklist-Anwendungen direkt aus HBase extrahiert. Solr gab Worklist drei wesentliche Funktionen: Es war extrem einfach zu bedienen und die Funktionen waren sehr intuitiv. Der Prozess des Filterns und Sortierens ist sehr effizient. Da die Solr-Filterung auf Dokument-IDs und Caching basiert, kann sie fast sofort die Anzahl der Dokumente berechnen, die die Filterkriterien erfüllen.
Solr ist eine hervorragende NoSQL-Datenbanklösung, die häufig mit anderen Big-Data-Diensten kombiniert wird. Wir haben unseren Benutzern sofortiges Feedback gegeben, als sie am Hinzufügen und Konfigurieren von Filtern gearbeitet haben, indem wir die Parameterzeilen = 0 an Solr gesendet haben. Es ist wichtig, mehr als nur die Pflege eines Solr-Schemas in Betracht zu ziehen, um eine Suchmaschine zu erstellen, die gut für die Relevanz ist.
Können Sie Solr als Datenbank verwenden?
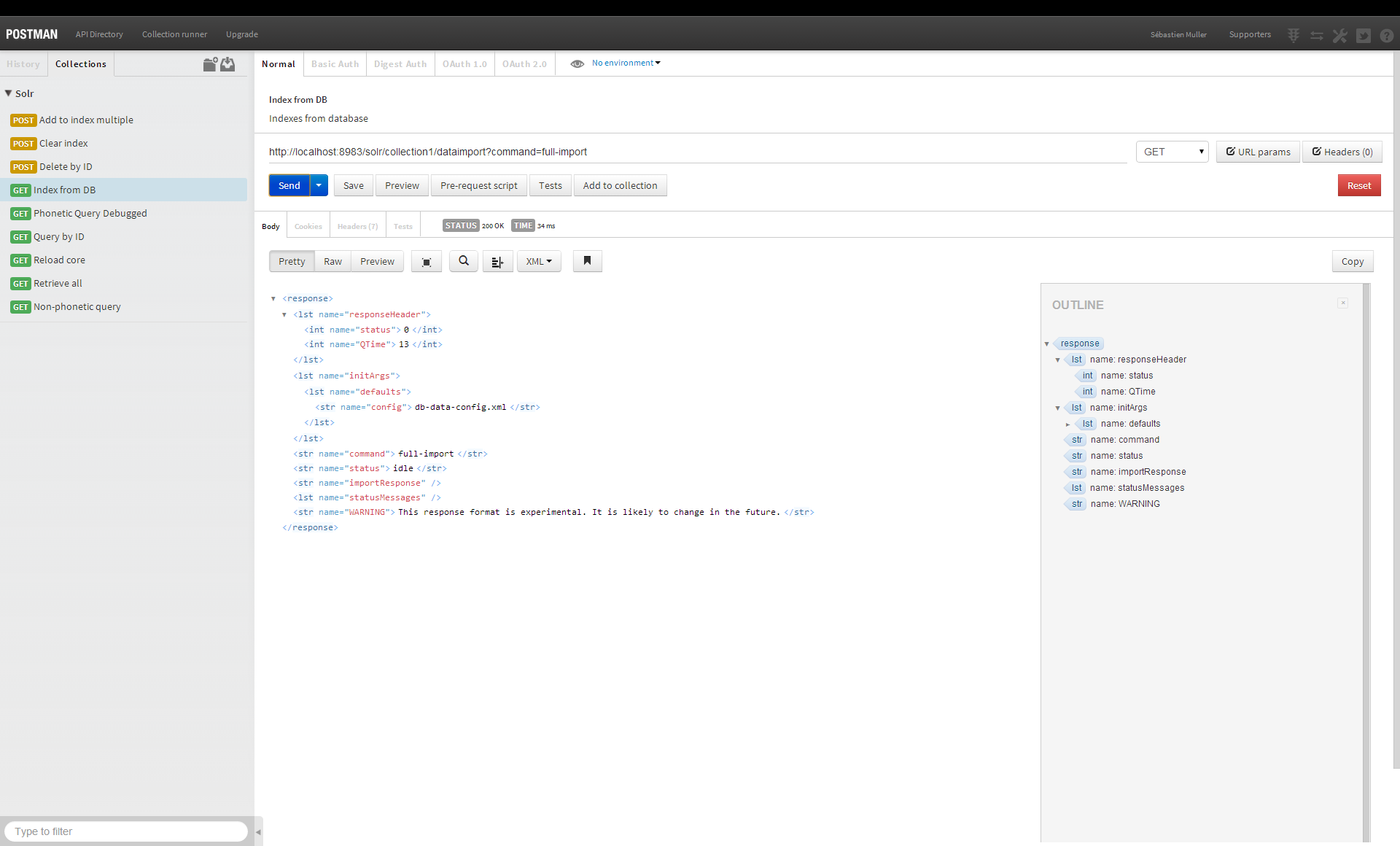
Ja, Sie können Solr als Datenbank verwenden. Es ist eine leistungsstarke Suchmaschine, die zum Indizieren und Durchsuchen von Daten verwendet werden kann. Es kann verwendet werden, um Daten in einem strukturierten Format zu speichern und schnell abzurufen.
Ist es falsch, einen Suchindex als Datenbank zu verwenden? In meinem Fall hatte ich eine ähnliche Idee, einige grundlegende Datenelemente in Solr zu speichern. Der Solr-Upgrade-Prozess hat jedoch meine Meinung geändert, und ich muss zugeben, dass ich mich geirrt habe. Wenn Sie 2 Hauptversionen aktualisiert, aber nicht neu indiziert haben (z. B. die Originaldokumente und dann die Indexdateien selbst löschen), wird der Kern nicht mehr erkannt.
Algolia, Elastic Observability, Coveo und Yext sind nur einige der beliebten Alternativen zu Apache Solr. Algolia ist eine natürlichsprachliche Suchmaschine, die Suchanfragen basierend auf dem, was wir über eine Person oder ein Thema wissen, in natürlicher Sprache analysiert und verarbeitet. Elastic Observability ist eine Datenplattform, die Echtzeit-Dateneinblicke in Daten und Anwendungen bietet. Coveo, eine Suchmaschinenmarketing-Plattform, ermöglicht es Ihnen, Ihre Suchmaschinenmarketing-Bemühungen gezielt auszurichten und zu messen. Durch die Nutzung von Yext können Sie Ihre Suchmaschinenmarketing-Kampagnen zielgerichtet ausrichten und messen.
Was sind Nosql-Datenbanken?
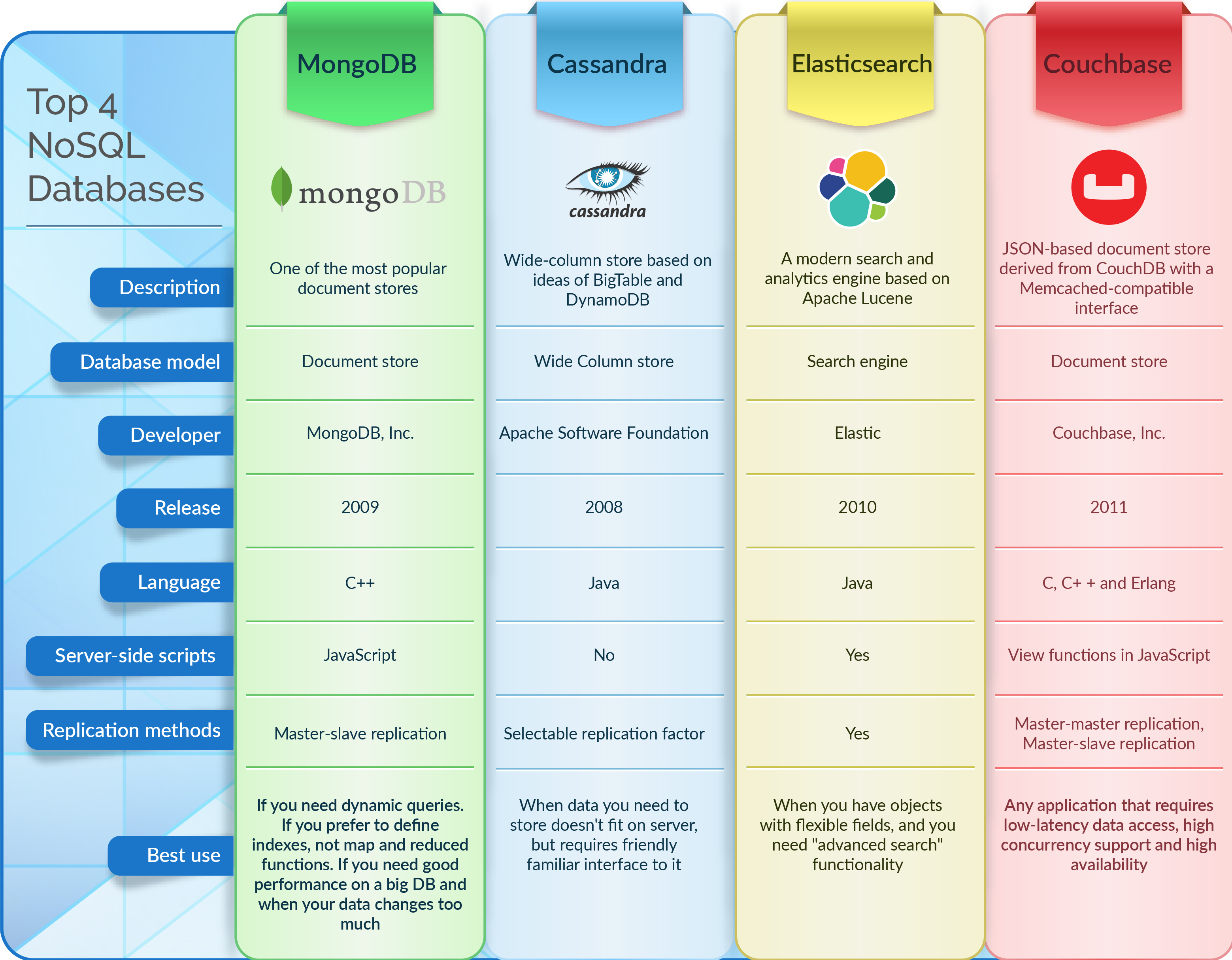
Nosql-Datenbanken sind Datenbanken, die nicht das traditionelle relationale Datenbankmodell verwenden. Stattdessen verwenden sie eine Vielzahl von Modellen, darunter Schlüsselwert-, Dokument-, Spalten- und Diagrammdatenbanken.
Dokumentbasierte NoSQL-Datenbanken speichern Daten auf die gleiche Weise wie relationale Datenbanken. Datenverwaltungssoftware ist so konzipiert, dass sie anpassungsfähig, skalierbar und in der Lage ist, zeitnah auf die Anforderungen moderner Unternehmen zu reagieren. Dokumentdatenbanken , Schlüsselwertspeicher, Datenbanken mit breiten Spalten und Diagrammdatenbanken sind nur einige der Arten von NoSQL-Datenbanken. Die Mehrheit der 2000 größten Unternehmen der Welt setzt NoSQL-Datenbanken schnell ein, um unternehmenskritische Anwendungen zu betreiben. In diesem Zusammenhang stellen fünf Trends technische Herausforderungen dar, die für die meisten relationalen Datenbanken zu schwierig zu bewältigen sind. Aufgrund des festen Datenmodells sind relationale Datenbanken ein großes Hindernis für die agile Entwicklung. Das Anwendungsmodell definiert das Datenmodell von NoSQL.
Die Daten müssen unabhängig von ihrer Struktur in einem NoSQL-Modell modelliert werden. Das JSON-Format ist der Standard zum Speichern von Daten in einer dokumentenorientierten Datenbank. ORM-Frameworks können auf diese Weise herunterskaliert werden, wodurch die Overhead-Kosten der Anwendungsentwicklung reduziert werden. N1QL (ausgesprochen Nickel) ist eine SQL-zu-JSON-Abfragesprache, die als Teil von Couchbase Server 4.0 veröffentlicht wurde. Das Tool unterstützt auch Aggregation (GROUP BY), Sortierung (SORT BY), Verknüpfungen (LEFT OUTER / INNER) und eine Vielzahl anderer Funktionen. Eine verteilte NoSQL-Datenbank mit einer Scale-out-Architektur, ohne Single-Failure-Point und überzeugenden betrieblichen Vorteilen ist eines der attraktivsten Merkmale. Da immer mehr Kundeninteraktionen online über Web- und mobile Apps stattfinden, ist die Verfügbarkeit ein Problem.
NoSQL-Datenbanken sind einfach zu erlernen und zu verwenden. Sie sollen Informationen speichern, Bücher schreiben und lesen. Sie sind auch in der Lage, Cluster unterschiedlicher Größe und beliebiger Größe zu verwalten und zu überwachen. Die integrierte Replikation, die in einer verteilten NoSQL-Datenbank enthalten ist, wird von der Datenbank selbst bereitgestellt – es ist keine zusätzliche Software erforderlich. Darüber hinaus gewährleisten Hardware-Router den sofortigen und konsistenten Zugriff auf kritische Daten. Während Datenbankadministratoren ein Problem untersuchen, müssen Anwendungen nicht warten, bis die Datenbank ein Problem entdeckt, bevor sie ihre eigene Wiederherstellung durchführen. Die NoSQL-Technologie wird als Plattform für die heutigen Web-, Mobil- und IoT-Anwendungen immer beliebter.
Es gibt zahlreiche Gründe, warum NoSQL-Datenbanken immer beliebter werden. Sie können skaliert werden, um den Anforderungen großer Organisationen gerecht zu werden, und sie sind anpassungsfähig. Betrachten Sie als Beispiel Ryanair und Marriott als Kunden von MongoDB. Diese Organisationen nutzen MongoDB nicht nur für ihre mobilen Apps und Reservierungssysteme, sondern auch für ihre Websites. Das Content-Management-System Presto des Unternehmens basiert ebenfalls auf NoSQL. Das System hilft bei der effizienten Verwaltung der proprietären Inhalte des Unternehmens.
Die Zukunft der Arbeit Die Zukunft der Arbeit liegt in der Ferne
Was ist keine Nosql-Datenbank?
Was ist der Unterschied zwischen NoSQL- und Nicht-NoSQL-Datenbanken? Microsoft SQL Server, das Managementsystem für relationale Datenbanken des Unternehmens, ist das Hauptprodukt.
In den späten 2000er Jahren wurde durch NoSQL-Datenbanken ein Fokus auf Skalierung, schnelle Abfrageergebnisse und Vereinfachung der Programmierung erreicht. NoSQL-Datenbanken sind einfach zu erstellen, da sie über ein flexibles Datenmodell, ein skalierbares Datenmodell und eine einfach zu verwendende Benutzeroberfläche verfügen. Relationale SQL-Datenbanken (Structured Query Language) sind in der Regel mit starren, komplexen und tabellarischen Schemata sowie mit unerschwinglich großer vertikaler Skalierung aufgebaut. Die Version 4.0 von MongoDB enthielt Unterstützung für ACID-Transaktionen mit mehreren Dokumenten, und die Version 4.2 fügte Unterstützung für Sharding-Cluster hinzu. Die Liste enthält keine Datenmodelle. In den meisten NoSQL-Datenbanken werden Abfragen statt Datenduplizierung optimiert. Außerdem einige Nr.
NoSQL-Datenbanken unterstützen die Komprimierung, um den Speicherbedarf zu reduzieren. Graphdatenbanken können zum Beispiel nützlich sein, um Beziehungen zu analysieren, aber sie sind möglicherweise nicht die bequemsten, um tägliche Daten abzurufen. Die Verwendung von MongoDB oder einer anderen Datenbank in Ihrem Anwendungsfall wird im Whitepaper Where to Use MongoDB demonstriert. Die Verwendung von MongoDB Atlas als Ausgangspunkt ist eine der einfachsten Möglichkeiten, NoSQL-Datenbanken zu erlernen. Die MongoDB University bietet völlig kostenlose Online-Schulungen an, um Sie beim Erlernen von MongoDB zu unterstützen.
Es gibt jedoch einige Nachteile von NoSQL-Datenbanken. NoSQL-Datenbanken sind nicht nur ACID-frei, sondern haben auch nicht die gleichen Eigenschaften wie relationale Datenbanken. Transaktionen in Ihrer Anwendung können zu Problemen führen, wenn Ihr System darauf angewiesen ist. Darüber hinaus bieten NoSQL-Datenbanken normalerweise nicht das gleiche Maß an Laufzeitflexibilität wie SQL-Datenbanken. Sie sollten die Verwendung von NoSQL-Datenbanken vermeiden, wenn Ihre Anwendung ihre Datenmodelle dynamisch ändern muss.
Welche der folgenden ist keine Datenbank?
Da sich alle Abfragen, Berichte und Tabellen auf Datenbanken beziehen, sind Beziehungen keine Datenbankobjekte; Sie sind mit der Mathematik verwandt.
Ist Mongodb eine Nosql-Datenbank?
Das Datenbankverwaltungsprogramm MongoDB NoSQL ist Open Source und kann kostenlos verwendet werden. Die NoSQL-Sprache ist eine Alternative zu herkömmlichen relationalen Datenbanken. NoSQL-Datenbanken eignen sich hervorragend für die groß angelegte Verteilung von Daten. Dokumentorientierte Informationen können mit MongoDB, einem Dokumentenverwaltungstool, verwaltet, gespeichert oder abgerufen werden.
Wie speichert Solr Daten?
Apache Solr indiziert Daten im lokalen Dateisystem, wie der Name schon sagt. Als Ergebnis des HDFS (Hadoop Distributed File System) können Benutzer eine Vielzahl von Vorteilen genießen, darunter groß angelegte und verteilte Speicherung mit Redundanz- und Failover-Funktionen. Apache Solr enthält Unterstützung für HDFS.
Im Gegensatz zu vielen anderen Suchmaschinen kann Solr sofortige Ergebnisse liefern, da es einen Index durchsucht, anstatt direkt den Text zu durchsuchen. Durch Scannen des Index auf der Rückseite eines Buchs kann der Index verwendet werden, um Seiten abzurufen, die sich auf ein Schlüsselwort beziehen. Dieser Index wird im Datenverzeichnis als Index in einem als Datenverzeichnis bezeichneten Verzeichnis gespeichert. Die Solr-Suchmaschine wird von Lucene betrieben, einer Open-Source-Volltextsuchmaschine. Die Beziehung zwischen Solr und Lucene ähnelt der eines Autos und seinem Motor. Auf die Unterschiede zwischen Lucene und Solr gehen wir in diesem Artikel ausführlich ein.

So verwenden Sie gespeicherte Felder in Sol
Das Feldformat eines Dokuments wird in Solr verwendet. Ein Dokument kann irgendeine Art von Feld enthalten, das einfach eine Sammlung von Daten ist. Wenn Sie mit Solr nach einem Dokument suchen, enthalten die Ergebnisse die Übereinstimmungen für alle Felder im Dokument, das es indiziert.
Ein gespeichertes Feld ist ein Feld, das nicht durchsucht werden muss, aber dennoch angezeigt werden muss, wenn nach etwas gesucht wird. In Solr werden diese als gespeicherte Felder bezeichnet. Solr indiziert alle gespeicherten Felder als Ergebnis seines Indizierungsalgorithmus. Wenn Sie also nach einem Dokument suchen, gibt Solr Ergebnisse zurück, die alle gespeicherten Felder enthalten.
Das Speichern von Feldern hat zahlreiche Vorteile. Wenn Sie den Titel eines Dokuments in der Ergebnisliste anzeigen möchten, müssen Sie den Titel ggf. als Datei speichern. Wenn Sie alle Dokumente finden möchten, die Sie jemals mit derselben ID durchsucht haben, können Sie die ID eines Dokuments durch mehrere Suchen nachverfolgen.
Suchergebnisse können auch durch Speichern von Feldern angezeigt werden. Der Titel eines Dokuments kann in der Ergebnisliste erscheinen, wenn es beschriftet ist. Möglicherweise möchten Sie auch die Dokument-ID anzeigen, damit Sie sie leicht finden können, indem Sie mehrere Websites nach dem Dokument durchsuchen.
Zu den Fähigkeiten von Solr gehört die Möglichkeit, Daten zu indizieren und zu speichern. Um ein Dokument zu indizieren, muss Solr zunächst eine Datenbank aller darin enthaltenen Felder erstellen, und dann werden Informationen über die Position jedes Felds gespeichert. Sie können nach dieser Art von Informationen suchen und Ergebnisse anzeigen.
Zusätzlich zu seinen leistungsstarken Suchfunktionen können Sie mit Solr leistungsstarke Anwendungen zum Abrufen von Dokumenten verwenden. Wenn Sie Benutzern Daten basierend auf ihrer Anfrage bereitstellen, basieren diese auf ihrer Anfrage.
Solr-Datenbank-Tutorial
Eine Solr-Datenbank ist ein Datenbanktyp, der die Solr-Software verwendet, um Daten zu indizieren und zu durchsuchen. Es ist ein leistungsstarkes Tool, mit dem große Datenmengen sehr schnell indiziert und durchsucht werden können.
Da dieses Tutorial mit Solr 8 verifiziert wurde, funktioniert es möglicherweise auch mit älteren Versionen. Das ID-Feld ist bereits in jedem Lucene und Solr vordefiniert, daher muss verstanden werden, welche Arten von Feldern es auf die richtige Weise indizieren kann. Dynamische Felder können spontan erstellt werden, ohne dass Voreinstellungen erforderlich sind, sodass Sie sie jederzeit ändern können. Die Lucene-Bibliothek , die Solr für die Volltextsuche verwendet, verwendet Point-in-Time-Snapshots, die regelmäßig aktualisiert werden müssen, um sicherzustellen, dass Abfragen neue Details präsentiert werden. Solr ist im Gegensatz zum datenformatagnostischen JSON oder XML datenformatagnostisch.
So verwenden Sie die Solr-Suchmaschine in Java
Der Java-Client ist erforderlich, um eine Verbindung zum Solr-Server herzustellen, verwenden Sie daher die Datei org.apache.solr.client.solrjimpl. Die Klasse, die das HttpSolrServer-Protokoll verwendet, heißt HttpSolrServer. Diese Klasse verwendet Java Socket, um mit dem Solr-Server zu kommunizieren. Wenn Sie eine Solr-Serveranwendung erstellen, müssen Sie zuerst die entsprechenden Klassen laden. In Java kann beispielsweise auf die Solr-Suchfunktion über die Datei org.apache.solr.client.solrj.impl zugegriffen werden. Die Klasse org.apache.solr.client.solrj.request ist die Komponente der Klasse SolrServer. Diese Klasse erstellt eine RequestHandler-Klasse. Mit dieser leistungsstarken Suchmaschine finden Sie ganz einfach die gewünschten Informationen. Um auf den Solr-Server zuzugreifen, verwenden Sie den Java-Client.
Solr gegen Lucene
Die Apache-Projekte Solr und Lucene bestehen aus den gleichen Komponenten. Apache Solr hingegen ist ein eigenständiger Server, wenn auch einer mit vielen erweiterten Funktionen. Apache Lucene hingegen ist eine auf Java-Bibliotheken basierende Lösung, die Daten indiziert (speichert) und durchsucht.
Aufgrund seines Caches hat Solr einen Vorteil im statischen Datenfeld, was das Abrufen von Ergebnissen erleichtern kann. Zeitreihendaten werden häufig von Elasticsearch verarbeitet, das zusätzlich zu Zeitreihendaten seine Filter- und Gruppierungsfunktionen einsetzt.
Solr vs. Elasticsearch
Diese Frage lässt sich nicht pauschal beantworten, da sie von individuellen Bedürfnissen und Vorlieben abhängt. Einige wesentliche Unterschiede zwischen Solr und Elasticsearch sind jedoch:
-Solr basiert auf einem traditionellen relationalen Datenbankmodell, während Elasticsearch einen dokumentenorientierten Ansatz verwendet.
- Solr ist in der Regel schneller beim Indizieren und Durchsuchen großer Datensätze, während Elasticsearch im Allgemeinen skalierbarer ist.
-Solr unterstützt erweiterte Abfragefunktionen wie Joins und verschachtelte Objekte, während Elasticsearch eine einfachere Abfragesyntax hat.
Es gibt eine große Community von Mitwirkenden an beiden Technologien, und Expertenunterstützung ist verfügbar. Elasticsearch war früher als Apache 2.0 bekannt und Open Source. Ab 2021 mit der Veröffentlichung von Version 7.11 kann Elasticsearch unter der Server Side Public License kostenlos verwendet werden. Es ist für Textsuchen auf Unternehmensebene vorgesehen, die das Abrufen von Informationen und/oder Analysen erfordern. Auch Volltextsuchen sind in Elasticsearch möglich und Rich-Dokumente wie PDF und Word können gelesen werden. Elasticsearch benötigt mehr Heap-Speicher als Solr (1 GB gegenüber 512 MB), aber diese Standardwerte können geändert werden. Die Elasticsearch-Plattform ermöglicht mehr Automatisierung durch die Kombination von Cluster-Rebalancing mit Datenbereinigung, die normalerweise manuell erfolgt.
Sharding ist eine Methode zur Verteilung von Daten auf mehrere Server, die von Solr und Elastic unterstützt wird. Sowohl Solr als auch ElasticSearch sind beliebte Suchmaschinendatenbanken mit großen, engagierten Communities und ähnlichen Fähigkeiten. Elasticsearch ist benutzerfreundlicher als Solr, einfacher zu skalieren und verfügt über bessere Analyse- und Abfragefunktionen. Die Apache Tika-Bibliothek, die von beiden Datenbanken verwendet werden kann, ermöglicht ihnen die Durchführung von Volltextsuchen und das Lesen umfangreicher Dokumente.
Apache Solr-Nutzung
Da es Dokumente und E-Mail-Anhänge indizieren und durchsuchen sowie mehrere Websites indizieren und durchsuchen kann, ist es ein beliebtes Tool sowohl für Websites als auch für die Unternehmenssuche.
Es ist eine Open-Source-Suchplattform, die zum Erstellen von Such-Apps verwendet wird. Es basiert auf der beliebten Volltextsuchmaschine Lucene . Solr ist eine Cloud-native, hochflexible Plattform, die für den Betrieb in Unternehmen bereit ist. Parallele Abfragen wurden in der neuesten Version von Solr, Solr 6.0, die 2016 veröffentlicht wurde, aktiviert. Die Solr-Plattform ermöglicht es uns, Indizes für große (Big Data) Anwendungen zu skalieren, zu verteilen und zu verwalten. Während Sie mit Solr arbeiten, müssen Sie kein Programmierer mit Java-Kenntnissen sein. Anstelle von Lucene bietet es einen sehr einfachen und benutzerfreundlichen Dienst zum Erstellen eines Suchfelds mit automatischer Vervollständigung.
Die vielen Vorteile von Apache Sol
Die Suchmaschine Apache Solr ist sowohl bei kleinen als auch bei großen Organisationen eine beliebte Suchmaschine. Diese Software ist sehr vielseitig und kann in einer Vielzahl von Situationen verwendet werden, einschließlich Datenanalyse und Datenabruf. Solr ist ein Dienst, der Suchfunktionen für Unternehmen bietet, was ihn zur idealen Wahl für die Verwaltung großer Datenmengen macht.
Nützliche Nosql-Datenbanklösung
Heutzutage sind viele nützliche NoSQL-Datenbanklösungen verfügbar. NoSQL-Datenbanken sind oft skalierbarer und leistungsfähiger als herkömmliche relationale Datenbanken. Sie sind in der Regel auch flexibler und ermöglichen eine einfachere Datenmodellierung und Schemaentwicklung. Einige beliebte NoSQL-Datenbanken sind MongoDB, Cassandra und HBase.
NoSQL-Datenbanken werden künftig von Entwicklern nicht mehr verwendet. Die Zukunft ist hier, wo diese Datenbanken ein gemeinsames Werkzeug für die Stromversorgung beliebter Anwendungen sein werden. Möglicherweise wissen Sie nicht, dass einige beliebte Anwendungen auf NoSQL-Datenbanken ausgeführt werden und warum NoSQL ideal für diese Anwendungen ist. 1996 war Forbes die erste Wirtschaftspublikation, die eine Website startete. Forbes hat seinen Dienst zu MongoDB Atlas migriert, um die Anforderungen seiner 140 Millionen Online-Benutzer zu erfüllen. Aufgrund der Auswirkungen der COVID-19-Pandemie wechselte die Publikation in eine Cloud-Infrastruktur und konnte schwierige Zeiten bewältigen. BangDB wurde von Accenture als NoSQL-Datenbank für seine Lead-Scoring-Anwendung ausgewählt.
Facebook Messenger läuft auf der Cassandra NoSQL-Datenbank ohne Single-Point-of-Failure, was es ihm ermöglicht, seinen Betrieb über mehrere Plattformen hinweg zu skalieren. Bigtable ist eine Komponente von Google Mail, die Google Bigtable unterstützt, ein Online-Unternehmen, das eine Vielzahl von Google Mail-Transaktionen unterstützt. Die Espresso-Datenbank stellt sicher, dass alle LinkedIn-Anwendungen normal funktionieren. Laden Sie BangDB kostenlos herunter, um zu sehen, ob es das richtige Tool für Sie ist.
Die Vorteile von Nosql-Datenbanken
Viele NoSQL-Datenbanken können verwendet werden, um strukturierte, halbstrukturierte und unstrukturierte Daten in einer Datenbank zu speichern und zu modellieren, was sie ideal zum Speichern und Modellieren von Datenstrukturen und Semantik macht. Sie können eine bessere Leistung erbringen und stabiler sein als herkömmliche relationale Datenbanken, und sie können für Entwickler einfacher zu implementieren sein. Mit der wachsenden Popularität von NoSQL-Datenbanken werden sie wahrscheinlich weiter an Popularität gewinnen.
Mongodb »
MongoDB ist ein leistungsstarkes dokumentenorientiertes Datenbanksystem. Es verfügt über eine indexbasierte Suchfunktion, die das Abrufen von Daten schnell und einfach macht. MongoDB bietet auch eine Skalierbarkeitsfunktion, die es ermöglicht, große Datenmengen zu verarbeiten.