
Die verschiedenen Arten von Computerclustern
Veröffentlicht: 2023-02-16In der Computertechnik ist ein Cluster eine Gruppe unabhängiger Computersysteme, die zusammenarbeiten, sodass sie in vielerlei Hinsicht als ein einziges System betrachtet werden können. Cluster werden normalerweise bereitgestellt, um die Leistung und Verfügbarkeit gegenüber einem einzelnen Computer zu verbessern, während sie in der Regel viel kostengünstiger sind als einzelne Computer mit vergleichbarer Geschwindigkeit oder Verfügbarkeit. Es gibt verschiedene Arten von Computerclustern, darunter Hochleistungsrechencluster, Computercluster für kommerzielle Zwecke und Speichercluster. In jedem Clustertyp arbeiten die Komponentensysteme zusammen, um eine gemeinsame Aufgabe oder gemeinsame Aufgaben auszuführen. High Performance Computing (HPC)-Cluster werden für wissenschaftliche und technische Anwendungen verwendet, die viel Rechenleistung und/oder Datenspeicherung erfordern. Diese Cluster bestehen in der Regel aus einer Gruppe von Standardcomputern, die über ein schnelles LAN (Local Area Network) verbunden sind. Die Computer in einem HPC-Cluster laufen normalerweise mit demselben oder ähnlichen Betriebssystem (OS) und haben dieselben oder ähnliche Hardwarekomponenten. Kommerzielle Cluster werden verwendet, um Geschäftsanwendungen auszuführen, die ein hohes Maß an Verfügbarkeit und/oder Skalierbarkeit erfordern. Diese Cluster bestehen häufig aus Servern, auf denen verschiedene Betriebssysteme ausgeführt werden und die über verschiedene Hardwarekomponenten verfügen. In vielen Fällen sind die Server in einem kommerziellen Cluster auch an ein Storage Area Network (SAN) angeschlossen, um auf gemeinsame Datenspeicher zugreifen zu können. Speichercluster werden verwendet, um ein zentralisiertes Speicherrepository bereitzustellen, auf das eine Gruppe von Computern zugreifen kann. Speichercluster bestehen normalerweise aus einer Gruppe von Speicherservern, die mit einem SAN verbunden sind. Die Server in einem Storage-Cluster führen normalerweise eine Vielzahl von Betriebssystemen aus und verfügen über eine Vielzahl von Hardwarekomponenten.
Was ist ein geteilter Mongodb-Cluster und welchen Sinn hat es, sich mit einem in MongoDB zu verbinden? Wie verbinde ich mich mit einem oder nur mit dem localhost? Die Goldmedaille wird im Noob 7461 Abzeichen verliehen. Es wurden zehn Silberabzeichen und 23 Bronzeabzeichen hergestellt. Ein replizierter Cluster besteht aus zehn Servern, mit einem für die Mongos-Schnittstelle, drei für jeden Replikatsatz und einem für jeden Konfigurationsserver-Replikatsatz. In einem Replikationssystem wird eine Komponente dupliziert, sodass immer ein Backup vorhanden ist, falls etwas schief geht. Alle Shards müssen Replikate sein, damit sie hergestellt werden können.
Ein Mongodb-Cluster wird beispielsweise häufig verwendet, um einen Sharded-Cluster in MongoDB zu beschreiben. Eine geteilte Mongodb erfüllt die folgenden Funktionen: Skalieren Sie Lese- und Schreibvorgänge von mehreren Knoten. Da nicht jeder Knoten den gesamten Datensatz verarbeitet, können Sie die Daten nur in Regionen im Shard partitionieren.
Ein Datenbank-Cluster ist, wie der Name schon sagt, eine Sammlung von Datenbanken, die von einer Instanz eines laufenden Datenbankservers ausgeführt werden können. Postgres, was in PostgreSQL „Standard“-Datenbank bedeutet, wird nach der Erstellung als Standarddatenbank in einen Datenbankcluster aufgenommen.
Ein MongoDB-Cluster kann auch als „Replica Set“ oder „Sharded Cluster“ bezeichnet werden. In einem Replikatsatz tragen mehrere Server Kopien derselben Daten. Die Knoten in einem Replikatsatz sind normalerweise drei. Wenn eine Client-Anwendung Operationen auf einem Knoten ausführt, werden alle Lese- und Schreibvorgänge an diesen Knoten gesendet; Wenn etwas schief geht, schützen es zwei sekundäre Knoten.
Ist Cluster und Datenbank gleich?
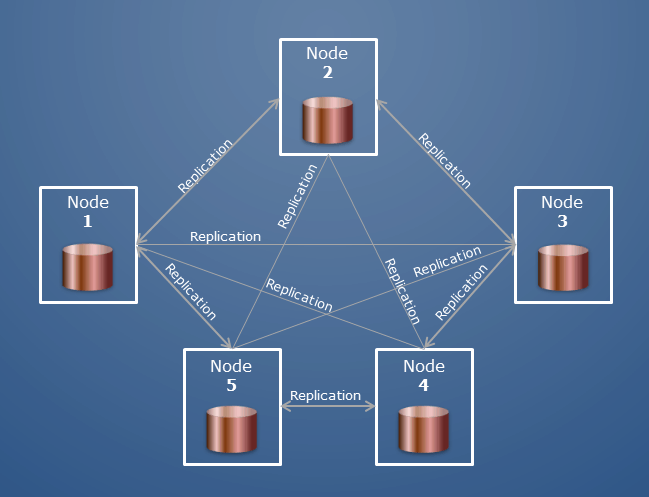
Es gibt mehrere Cluster von Hosts, die einen Cluster bilden. Die Hosts eines Sharding-Clusters werden in verschiedene Rollen eingeteilt. Eine Datenbank ist eine Sammlung von Sammlungen; in Oracle wäre es äquivalent zu einer Datenbank und einem Schema.
Ein Datenbank-Cluster ist eine Sammlung von Servern oder Instanzen, die eine Datenbank mit einer anderen verbinden. Datenbank-Clustering wird von Servern aus einer Vielzahl von Gründen verwendet, von denen die wichtigsten Datenredundanz, Lastausgleich, Hochverfügbarkeit sowie Überwachung und Automatisierung sind. Wenn also ein Computer ausfällt, stehen alle unsere Daten anderen zur Verfügung, was uns den Vorteil der Datenredundanz verschafft. Mit Clustering besteht die Möglichkeit, viele Datenbankprozesse zu automatisieren und gleichzeitig Regeln zu erstellen, um potenzielle Probleme zu identifizieren. In der Cluster-Architektur werden alle Anfragen an eine Reihe von Computern geleitet, von denen jeder in der Lage ist, die Anfrage zu bearbeiten und für den Benutzer zu produzieren. Ein Failover- oder Hochverfügbarkeitscluster repliziert Server und konfiguriert die Hardware neu, um die Dienstverfügbarkeit sicherzustellen. Diese Arten von Clustern sind profitabel für Computerbenutzer, die sich vollständig auf ihre Systeme verlassen. Das Ziel von Hochleistungsclustern ist es, die Netzwerkkapazität zu erhöhen und gleichzeitig die Leistung zu verbessern.
In einem verteilten Hadoop-System fungieren Knoten als Datenspeicher- und Verarbeitungszentren. Der Hauptunterschied zwischen einem Cluster und einem Server besteht darin, dass der Cluster mehrere Knoten verwendet, die miteinander kommunizieren, um eine Reihe von Operationen auszuführen. Ein Cluster enthält eine Reihe von Knoten, die eine Reihe von Operationen ausführen. Das verteilte Hadoop-System kann bis zu 10.000 Datenbanken unterstützen. Ähnliche Abfrageergebnisse können erhalten werden, wenn Daten aus mehreren Tabellen in derselben Datenbank in einer Abfrage aus mehreren Datenbanken in demselben Cluster kombiniert werden.
Die Vorteile von Cluster
Mit einem Cluster können Sie problemlos mehrere Datenbanken verwalten, indem Sie für alle eine einheitliche Tabellen- und Spaltenspeicherung bereitstellen. Dies verbessert die Leistung und Datenintegrität und macht das System somit effizienter.
Wo ist der Clustername in Mongodb?
Auf diese Frage gibt es keine pauschale Antwort, da der Clustername je nach Typ des verwendeten MongoDB-Clusters an unterschiedlichen Stellen zu finden ist. Beispielsweise wird der Clustername in einem Replikatsatz normalerweise in der Sammlung local.system.replset gespeichert, während er in einem Sharded-Cluster normalerweise in der Sammlung config.shards zu finden ist.
MongoDB Atlas ist ein MongoDB-as-a-Service-NoSQL-Datenbank-as-a-Service-Angebot, das in den öffentlichen Clouds von Microsoft Azure, Google Cloud Platform und Amazon Web Services verfügbar ist. Sie können in wenigen Minuten mit Ihrem bevorzugten Webbrowser einen funktionierenden MongoDB-Cluster erstellen, indem Sie auf einen Link klicken, um ihn einzurichten. Es ist nicht erforderlich, Software auf Ihrer Workstation zu installieren, um sich über diese mit dem Internet zu verbinden, und Sie können dazu die Webschnittstelle verwenden. Wenn MongoDB-Replikatsätze in Verbindung mit mehreren MongoDB-Servern verwendet werden, sind Datenredundanz und Hochverfügbarkeit gewährleistet. Der MongoDB-Cluster verfügt über zusätzliche Kapazitäten für Lesevorgänge, sodass Clients auf zusätzliche Server geleitet werden können. Bei einer Replikation werden ein oder mehrere Mitglieder des Replikatsatzes asynchron vom Oplog des primären Knotens zu den sekundären Knoten repliziert, sodass der Replikatsatz trotz potenzieller Ausfälle seiner Mitglieder funktionieren kann. In MongoDB können Sie zusätzlich zu den standardmäßigen Eingabe- und Ausgabebefehlen zusätzliche Lese- und Schreibvorgänge ausführen.
In den meisten Fällen ist der primäre Knoten die Quelle aller Lesevorgänge, aber das Routing zu sekundären Knoten kann konfiguriert werden. Das Risiko potenziell veralteter Daten ist höher, wenn der nächstgelegene Knoten ein sekundärer Knoten ist. Damit der Schreibvorgang erfolgreich über den Cluster verteilt wird, müssen Sie Optionen zum Schreiben von Daten in einen MongoDB-Replikatsatz einbeziehen. Als Teil dieses Prozesses muss eine Write Concern-Eigenschaft zum Einfügen hinzugefügt werden. Wenn eine Schreibanforderung empfangen wird, wird der Cluster aufgefordert, zu bestätigen, dass er in der überwiegenden Mehrheit der datentragenden Knoten erfolgreich war. Durch die Konfiguration eines Sharding-Clusters kann dieser auch als Replikatsatz konfiguriert werden. Ein Replikatsatz enthält sowohl primäre als auch sekundäre Mongod-Prozesse. Wenn der Master ausfällt, wird empfohlen, dass die Gesamtzahl dieser Prozesse ungerade ist, um sicherzustellen, dass die Mehrheit ausgeführt wird.
MongoDB-Cluster sind, wie der Name schon sagt, Cluster von Knoten, die zusammenarbeiten, um Daten zu speichern und zu verwalten. Beim Erstellen eines MongoDB-Clusters geben Sie an, wie viele Knoten enthalten sein sollen und wofür sie konfiguriert werden müssen. Sie können Ihre Anwendung nach der Erstellung mit Node mit Ihrem MongoDB-Cluster verbinden. MongoDB Compass kann als Treiber für die MongoDB JS-Bibliothek oder als PyMongo-Treiber für MongoDB betrachtet werden. Der Hauptvorteil der Verbindung Ihrer Anwendung mit einem Cluster besteht darin, dass sie Daten lesen und darauf schreiben kann. Mit MongoDB Compass können Sie Ihre Daten auf vielfältige Weise untersuchen, ändern und visualisieren. Ein Beispiel dafür, wie Sie Ihre Daten anzeigen können, finden Sie in einem Raster, mit dem Sie beobachten können, wie sich Daten im Laufe der Zeit ändern und wer Daten in Ihrem Cluster verteilt.
Wo ist Cluster im Mongodb-Atlas?
Auf diese Frage gibt es keine endgültige Antwort, da der Standort eines Clusters in MongoDB Atlas von einer Reihe von Faktoren abhängen kann, einschließlich der geografischen Region, in der es sich befindet, und den spezifischen Anforderungen der Anwendung, die es unterstützt. Im Allgemeinen ist ein Cluster in MongoDB Atlas jedoch im Abschnitt „Cluster“ der MongoDB Atlas-Konsole zu finden.
Ein Cluster kann entweder ein Replikatsatz oder ein fragmentierter Satz sein. Die Gesamtzahl der Knoten jedes Projekts wird durch eine bestimmte Einschränkung eingeschränkt, die auf ihrem Funktionsumfang in den Regionen basiert. Jedes Atlas-Projekt kann bis zu 25 Datenbanken bereitstellen. Wenden Sie sich bei Fragen zum Datenbankbereitstellungslimit bitte an Datenbankadministratoren. TLS-Version 1.2 ist die standardmäßige TLS-Version für Cluster, die nach dem 1. Juli 2020 erstellt wurden.

Was ist ein Cluster in Mongodb
In MongoDB ist ein Cluster eine Gruppe von Datenbankservern, die Kopien derselben Daten verwalten. Jeder Server in einem Cluster wird als Knoten bezeichnet. Ein Cluster kann einen oder mehrere Knoten haben.
Wozu dient Datenbank-Clustering? Der Vorgang des Verbindens mehrerer Server oder Instanzen mit einer einzelnen Datenbank wird als SQL-Verbindung bezeichnet. In MongoDB ist ein Cluster je nach MongoDB-Typ entweder ein Replikatsatz oder ein fragmentierter Cluster. In den folgenden Abschnitten werde ich auf die unterschiedlichen Aspekte jedes dieser Cluster eingehender eingehen. Aufgrund des Lastausgleichs und der Anzahl der Maschinen von MongoDB hat es ein hohes Maß an Verfügbarkeit. Ein Cluster kann verwendet werden, um viele Datenbankprozesse zu automatisieren und gleichzeitig die Erstellung von Regeln zur Warnung vor potenziellen Problemen zu ermöglichen. Eine MongoDB-Datenbank kann in zwei Typen aufgeteilt werden: Replikatsätze und Sharding-Cluster.
Daten werden auf mehreren Computern in einem Shard gespeichert. Darauf basiert die Methode von MongoDB, Datenskalierbarkeit bereitzustellen. Dies reduziert den Zeitaufwand für die Verwaltung großer Datenmengen. Aufgrund der Datenmenge, die Replikate bereitstellen, können auch verteilte Anwendungen davon profitieren.
Leistungsprobleme und Datenkonflikte können auftreten, wenn mehrere Atlas-Projekte im selben Cluster bereitgestellt werden. Atlas empfiehlt, dass Sie nur einen kostenlosen Cluster pro Atlas-Projekt verwenden. Ein gutes Daten-Clustering-Tool ist in einer Vielzahl von Datenanalyse- und Data-Mining-Anwendungen erforderlich. Um potenzielle Leistungsprobleme und Datenkonflikte in Atlas-Projekten zu vermeiden, empfiehlt Atlas, dass Sie nur einen kostenlosen Cluster pro Projekt verwenden.
Mongodb-Cluster-Architektur
Ein MongoDB-Cluster ist eine Gruppe von MongoDB-Servern, die zusammenarbeiten, um Ihre Daten zu speichern. Jeder Server in einem Cluster wird als Knoten bezeichnet. Ein Cluster kann beliebig viele Knoten haben. Ein Cluster besteht aus einem Replikatsatz, bei dem es sich um eine Gruppe von Knoten handelt, die jeweils über eine Kopie Ihrer Daten verfügen. Ein Replikatsatz hat mindestens drei Knoten, sodass Ihre Daten immer noch verfügbar sind, wenn ein Knoten ausfällt.
Die Architektur von Replikatsätzen ist ein wichtiger Faktor für die Kapazität und Leistungsfähigkeit von MongoDB. MongoDB-Cluster werden normalerweise auf drei Knotenreplikate verteilt. Die Datenbankwiederherstellung nach einem Desaster muss dauerhaft stabil sein, insbesondere in der Zeit danach. Eine der besten Möglichkeiten zum Bereitstellen eines Sharding-Clusters ist die Verwendung einer Replikationsstrategie. Die in den Shard Keys enthaltenen Daten müssen auf die gleiche Weise verteilt werden. Sie sollten die Datenbank horizontal skalieren und die Anzahl der Operationen reduzieren, die auf einer einzelnen Instanz ausgeführt werden können. Bei wenigen Shards können Lese- und Schreibvorgänge träge werden, da die Anzahl der Shards die Anzahl der Vorgänge begrenzt.
Jedes Datenelement in einem Shard besteht aus einer Teilmenge dieses Elements, basierend auf einem bestimmten Satz von Kriterien. Es ist üblich, dass die Mindestanzahl von Shards, die erforderlich ist, um die Sharding-Signifikanz zu erreichen, zwei beträgt. Scatter-Gather-Abfragen sollten nur verwendet werden, wenn sie gleichzeitig auf allen Shards verwendet werden können. Bei der Auswahl eines Clusters ist es entscheidend, mindestens sieben stimmberechtigte Mitglieder zu haben, um den Wahlprozess so einfach wie möglich zu gestalten. Wenn Sie nur sieben oder weniger stimmberechtigte Mitglieder, aber eine gleiche Anzahl von Mitgliedern haben, muss der Schiedsrichter eingesetzt werden. Arbiter speichern keine Datenkopien, wodurch weniger Ressourcen zum Verarbeiten der Daten erforderlich sind. Die Verwendung eines logischen DNS-Hostnamens anstelle einer IP-Adresse wird beim Konfigurieren von Replikatsatzmitgliedern oder Sharding-Clustermitgliedern bevorzugt. Da einige Treibergruppen-Replikatsatzverbindungen nach Replikatsatznamen bestehen, sollten diese Namen separat für die Sätze verwendet werden. Die geografische Verteilung der Replica-Set-Knoten ist ideal, um redundante Redundanz zu adressieren und Fehlertoleranz sicherzustellen, wenn eines der Rechenzentren fehlt.
Name des Mongodb-Clusters
Ein MongoDB-Cluster ist eine Gruppe von MongoDB-Servern, die zusammenarbeiten, um Hochverfügbarkeit und Skalierbarkeit bereitzustellen. Ein Cluster hat normalerweise einen primären Server, der als Master-Server fungiert, und einen oder mehrere sekundäre Server, die als Slaves fungieren. Der primäre Server enthält die Daten, und die sekundären Server kopieren Daten vom primären Server.
Mit Hilfe von MongoDB, einem plattformübergreifenden Programm, werden dokumentenorientierte Datenbankprogramme für die Massenspeicherung erstellt. MongoDB, ein NoSQL-Datenbankprogramm, wird als solches klassifiziert, weil es Dokumente im JSON-Stil mit optionalen Schemas verwendet. Sie können die Leistung verbessern, indem Sie Ihre Datenbank im selben Rechenzentrum wie Ihre anderen DigitalOcean-Ressourcen installieren. Die Region verfügt über ein oder mehrere Rechenzentren, und jedes hat sein eigenes VPC-Netzwerk. Der Maschinentyp, die Anzahl und die Größe der Datenbankknoten können ausgewählt werden. Anders ausgedrückt: Sie können Ihrem Cluster bis zu zwei Standby-Knoten hinzufügen. Fügen Sie einen Projektnamen hinzu, vervollständigen Sie es und verwenden Sie alle Tags, die Sie verwenden möchten, wenn Sie es erstellen. Die Fertigstellung eines Clusters kann bis zu fünf Minuten dauern.
Die Macht des Mongodb-Atlas-Clusters
MongoDB Atlas Cluster ist eine NoSQL-Datenbank-as-a-Service-Lösung in der öffentlichen Cloud, die in MongoDB ausgeführt wird. Es ist eine robuste, skalierbare Datenplattform, mit der Sie Anwendungen schnell erstellen und bereitstellen können. Durch die Verwendung von MongoDB Atlas Cluster können Sie sich von jedem Ort der Welt aus sicher mit MongoDB verbinden.
So erstellen Sie Cluster in Mongodb
Verwenden Sie die folgenden Schritte, um einen Cluster in MongoDB zu erstellen:
1. Wählen Sie eine Bereitstellungstopologie aus.
2. Wählen Sie den Replikatsatztyp aus, den Sie bereitstellen möchten.
3. Wählen Sie die Anzahl der Replikatsätze aus, die Sie bereitstellen möchten.
4. Konfigurieren Sie die Replikatsätze.
5. Stellen Sie eine Verbindung zum Mongos-Router her.
6. Konfigurieren Sie den Shard-Schlüssel.
7. Fügen Sie dem Cluster Shards hinzu.
8. Stellen Sie sicher, dass der Cluster betriebsbereit ist.
MongoDB Atlas ist eine kostenlose Stufe von MongoDB, dem vollständig verwalteten Cloud-Datenbankdienst von MongoDB. Der Dienst ist für Unternehmens-Workloads sowie globale Cluster konzipiert. Sie müssen kein Konto bei Amazon Web Services (AWS), Google Cloud Platform oder Microsoft Azure erstellen. Sie werden aufgefordert, ein Administratorkonto zu erstellen, um auf den Dienst zugreifen zu können. Um auf den Dienst zuzugreifen, muss ein Cluster mit einer IP-Adresse verknüpft werden. Die Standardsicherheitseinstellungen von MongoDB Atlas verhindern alle externen Verbindungen. Ihr Passwort sollte keine Sonderzeichen und nur alphanumerische Zeichen enthalten, um die Verbindung zu Studio 3T zu vereinfachen. Beim Erstellen einer Verbindungszeichenfolge für MongoDB müssen Sonderzeichen codiert werden. Wählen Sie in Schritt 1 Java aus der Dropdown-Liste TREIBER und dann aus der Dropdown-Liste VERSION aus. Wenn Sie den Treiber und die Version auswählen, aktualisiert der Dienst die Verbindungszeichenfolge in Schritt 2 automatisch.
Mongodb-Clustering: Eine großartige Option für hohen Durchsatz
Mit MongoDB-Clustering können Sie hohe Durchsatz-, Verfügbarkeits- und Durchsatzanforderungen für große Umgebungen erfüllen. MongoDB-Cluster können so konfiguriert werden, dass sie eine breite Palette von MongoDB-Replikatsatztypen unterstützen, von einfachen Einzelknoten-Setups bis hin zu hochverfügbaren Konfigurationen mit mehreren Knoten.
Mongodb-Cluster-Tutorial
Ein MongoDB-Cluster ist eine Gruppe von MongoDB-Servern, die zusammenarbeiten, um Ihre Daten zu speichern. Ein MongoDB-Cluster kann so klein wie ein einzelner Server oder so groß wie Hunderte von Servern sein. Wenn Sie einen MongoDB-Cluster erstellen, geben Sie die Anzahl der Server (Knoten) an, die Sie im Cluster haben möchten. Jeder Knoten in einem MongoDB- Cluster speichert eine Teilmenge Ihrer Daten. MongoDB-Cluster sind so konzipiert, dass sie skalierbar sind und eine hohe Verfügbarkeit bieten. Sie können einem Cluster jederzeit Knoten hinzufügen, um seine Kapazität zu erhöhen oder einen ausgefallenen Knoten zu ersetzen. Wenn Sie einen Knoten aus einem Cluster entfernen, verteilen die anderen Knoten die Daten vom entfernten Knoten neu, sodass die Daten weiterhin gleichmäßig über den Cluster verteilt sind.
Hevos Easy Guide to MongoDB Clustering ist der erste Schritt. Wenn eine Datenbank zu klein oder zu langsam ist, um ein System auszuführen, läuft der Betrieb einer Organisation weiter. MongoDB verfügt über zahlreiche erweiterte Funktionen, die für die Cloud entwickelt wurden, wie z. B. Sharding und Replikation. MongoDB ermöglicht es, mehrere Kopien derselben Daten zu speichern, wodurch sie extrem zugänglich sind. Fällt ein Server aus, können Daten vom anderen sofort abgerufen werden. Mit Hevo Data können Sie den Prozess der Datenreplikation automatisieren, vereinfachen und erweitern. Die Datenreplikation ist einfach und problemlos zu verwenden, wenn Sie Zugriff auf unsere 14-tägige kostenlose Testversion haben.
Um MongoDB-Cluster einzurichten, müssen Sie zuerst alle drei erforderlichen Komponenten installieren. Mit der automatisierten No-Code-Plattform von Hevo können Sie alles nachverfolgen, was Sie für eine reibungslose Datenreplikationserfahrung tun müssen. Um eine maximale Verfügbarkeit zu gewährleisten, müssen mehrere Konfigurationsserver oder Router vorhanden sein. Wenn der Router feststellt, in welchem Shard die Daten gespeichert sind, sendet er Anfragen an den entsprechenden Cluster. Beim Einrichten von MongoDB-Clustern sind die folgenden Schritte erforderlich, um ihnen Shards hinzuzufügen. In einer Clusterkonfiguration wird Port 27018 als Standard für die Shard-Server verwendet. Es bedeutet, dass es sich eher um einen Shard-Server als um einen Konfigurationsserver handelt.