
Die verschiedenen Möglichkeiten zum Speichern von Diagrammdaten auf der Festplatte
Veröffentlicht: 2022-11-22Graphdatenbanken sind eine Art NoSQL-Datenbank, die Graphstrukturen für semantische Abfragen mit Knoten, Kanten und Eigenschaften verwenden, um Daten darzustellen und zu speichern. Diagrammdatenbanken unterscheiden sich von anderen NoSQL-Datenbanken dadurch, dass sie ihre Daten in einem Diagrammformat speichern. Das bedeutet, dass Daten durch Knoten (die Entitäten) und die Beziehungen zwischen diesen Knoten (die Kanten) dargestellt werden. Dies ermöglicht viel mehr Flexibilität und einfachere Abfragen als herkömmliche Datenbanken. Es gibt verschiedene Möglichkeiten, wie Graphdatenbanken ihre Daten auf der Festplatte speichern können. Am gebräuchlichsten ist die Verwendung einer Adjazenzliste. Hier hat jeder Knoten eine Liste aller anderen Knoten, mit denen er verbunden ist. Dies ist die einfachste Methode zum Speichern von Diagrammdaten, kann jedoch ineffizient sein, wenn das Diagramm sehr groß ist. Eine andere Möglichkeit, Diagrammdaten zu speichern, ist die Verwendung einer Adjazenzmatrix. Hier wird eine Matrix verwendet, um die Kanten zwischen Knoten darzustellen. Dies ist für größere Diagramme effizienter, kann jedoch schwieriger abzufragen sein. Die letzte Möglichkeit, Diagrammdaten zu speichern, ist die Verwendung eines Eigenschaftsdiagramms. Hier hat jeder Knoten eine Reihe von Eigenschaften (Attributen) und die Kanten zwischen den Knoten werden durch diese Eigenschaften definiert. Dies ist die flexibelste Methode zum Speichern von Diagrammdaten, kann jedoch schwieriger abzufragen sein. Graphdatenbanken sind ein mächtiges Werkzeug zur Datenanalyse und können für eine Vielzahl von Anwendungen eingesetzt werden. Sie eignen sich besonders gut für Anwendungen, die komplexe Abfragen erfordern oder Daten flexibel speichern müssen.
Welche Methoden verwenden diese Papiere, um die Grafik im Dateisystem zu speichern? Ich bin mir nicht sicher, was in den Speicher geladen werden muss und welche IDs speziell erforderlich sind. Wenn mehr Forschung erforderlich ist, kann das Aufzeigen der wichtigsten Merkmale, nach denen gesucht werden muss, dazu beitragen, dies zu einem klareren Verständnis zu bringen.
Hierbei handelt es sich um eine Technologie zur Verwaltung großer Sammlungen strukturierter, halbstrukturierter oder unstrukturierter Daten, die sowohl SQL als auch NoSQL („nicht nur SQL“) verwendet. Es ermöglicht Unternehmen ein besseres Verständnis ihrer Big Data- und Social-Media-Analysen durch die Integration und Analyse von Daten aus einer Vielzahl von Quellen.
Graphdatenbanksysteme speichern Daten in Bezug auf die Datenstruktur typischerweise in einer ähnlichen Struktur wie verknüpfte Listen. In ihnen sind nicht nur Datenketten, sondern direkte Links zu Daten gespeichert.
Definieren Sie unter Verwendung Ihres Datentyps als primäre Kennung ein Typsystem für Ihre API und verwenden Sie dieses, um Abfragen mit der Abfragesprache GraphQL auszuführen. Da GraphQL auf vorhandenem Code und Daten basiert, ist keine spezielle Datenbank oder Speicher-Engine erforderlich.
Die Daten des Diagramms werden in Speicherdateien gespeichert, die Informationen zu einem bestimmten Teil des Diagramms enthalten, z. B. Knoten, Beziehungen, Bezeichnungen und Eigenschaften. Wie bereits erwähnt, werden Daten auf diese Weise geteilt, um hochleistungsfähige Graphtraversen zu unterstützen.
Wie werden Daten in Graph Nosql gespeichert?
Graphdatenbanken sind eine Art NoSQL-Datenbank, die Graphstrukturen für semantische Abfragen mit Knoten, Kanten und Eigenschaften verwenden, um Daten darzustellen und zu speichern.
Die Graphdatenbank (auch bekannt als NoSQL oder SQL) ist ein Datenbanktyp, der große Sammlungen von strukturierten, halbstrukturierten und unstrukturierten Daten speichern kann. Es unterstützt Unternehmen dabei, Zugang zu Daten aus einer Vielzahl von Quellen zu erhalten, diese zu integrieren und zu analysieren, sodass sie ihre Social-Media- und Big-Data-Analysen analysieren können. Es muss nicht neu definiert werden, bevor neue Daten zu einer NoSQL-Datenbank hinzugefügt werden, die nicht neu definiert werden muss. Die W3C-Standards, die zur Darstellung von Daten im Web verwendet werden, werden in Graphdatenbanken verwendet. Die Verwendung von Standardpraktiken erleichtert die Datenintegration, den Austausch und die Zuordnung zwischen Datensätzen. Mit Inferenz können Organisationen die Leistungsfähigkeit ihrer Graphdatenbank steigern, indem sie neues Wissen hinzufügen und es ihnen ermöglichen, alle ihre Daten auf viel relevantere Weise anzuzeigen. Auch im Bereich Social Media Analytics können Organisationen von semantischer Technologie und NoSQL profitieren.
Graphdatenbanken gibt es schon seit einiger Zeit, aber sie werden immer beliebter. Ihre Datenspeicherung ist einzigartig und sie können für einige Benutzer von Wert sein. Es ist nützlich für die Problemlösung, bei der herkömmliche Datenbanken versagt haben, wie z. B. das Dokumentieren und Priorisieren von Beziehungen zwischen Entitäten.
In Bezug auf Graphdatenbanken ist MongoDB eine gute Wahl. Da es über einen kostenlosen MongoDB-Atlas-Cluster verfügt, wird die Einrichtung und Verwendung einer Graphdatenbank so einfach wie möglich gemacht.
Graphdatenbanken: Die Zukunft der Datenspeicherung
Die Daten werden in grafischer Form nach Knoten (z. B. Personen, Posts, Kommentare), Beziehungen (z. B. Likes, Shares) und Eigenschaften (z. B. Zeitstempel) gespeichert. Diese Arten von Strukturen ermöglichen eine einfachere Visualisierung von Daten und machen Zuordnungen zwischen Entitäten einfacher. Graphdatenbanken können auch verwendet werden, um riesige Datenmengen zu speichern, die stark miteinander verbunden sind. Beziehungen zwischen Daten werden priorisiert, um eine einfache Visualisierung zu ermöglichen.
Graphdatenbanken sind als eigenständige Datenbank derzeit nur in NoSQL-Formaten verfügbar. Graphing hingegen ist in MongoDB über die $graphLookup-Funktion verfügbar. Es bedeutet auch, dass Sie die Daten von jedem Ort aus einsehen können, ohne bei Null anfangen zu müssen.
Wie wird Graph Db gespeichert?
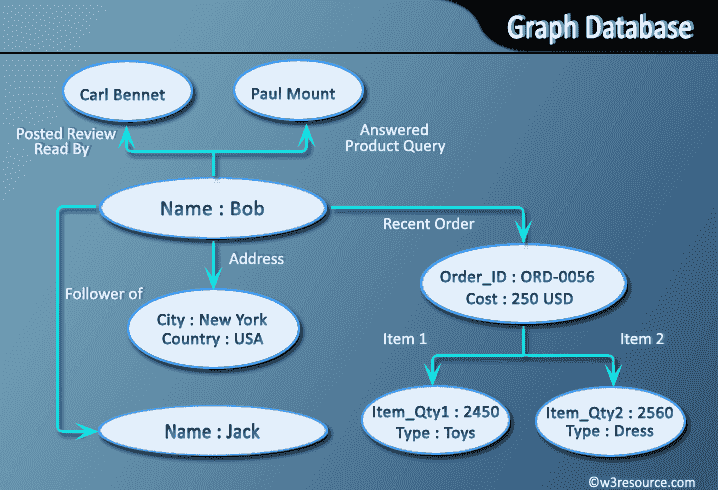
Graphdatenbanken speichern Daten in einem Graphen, der eine Sammlung von Knoten und Kanten ist. Knoten stellen Entitäten wie Personen, Orte oder Dinge dar, und Kanten stellen die Beziehungen zwischen ihnen dar. Beispielsweise könnten in einem sozialen Netzwerk Knoten Personen darstellen und Kanten könnten die Beziehungen zwischen ihnen darstellen (z. B. Freunde, Familie, Kollegen usw.).
Native Graphdatenbanken gewinnen als praktikable Alternative zu NoSQL und relationalen Datenbanken auf dem Markt an Bedeutung. Native Graphdatenbanken sollten laut Designtheorie einen großen Funktionsumfang haben, aber Neo4j scheint derzeit am beliebtesten zu sein. Alle Kanten enthalten die Quelle und das Ziel einer Kanten-(Beziehungs-)Zeile. Mit einem Index können Sie die Größe Ihrer Daten erhöhen und gleichzeitig die Zeit verringern, die Sie mit dem Schreiben verbringen. Um diese Probleme zu lösen, verwenden wir ein natives Graph-Speichermodell, das O(log(n) ist. In jedem Datensatz wird die Beziehungs-ID eines Knotens (first_rid) angezeigt. Kante A ist beispielsweise an beide Knoten 1 gebunden.
In diesem Fall müssen Sie einen neuen Knoten 4 sowie einen neuen Knoten 2 hinzufügen. Die first_rid von Knoten 4, D, wird im Beziehungsspeicher mit einem neuen Datensatz gespeichert [Abbildung 4 (d)]. Der Code des Servers hat zwei Parameter: einen src und einen dst. Das Diagrammspeichermodell in Abbildung 4 (a) wurde aktualisiert. Ein kontinuierlicher Datenblock wird mithilfe von mmap im physischen Speicher von Native-Graph gespeichert. Als Ergebnis können Sie den Datensatz direkt aus der Konstante ID * record_size im kontinuierlichen Blob lesen/schreiben. Mmap ist ein nützliches Tool, da es verhindert, dass doppelte Kopien sowohl auf dem Betriebssystem als auch in der Anwendung erscheinen.
Die in_use-Informationen, first_rid, erste Eigenschafts-ID und erste Label-ID im Node-Datensatz von Neo4j können gefunden werden. Knoten. Property-ID und Label-ID sind zwei Zeiger auf die Eigenschaften und Labels des Knotens. Auf die gleiche Weise wird eine andere Methode verwendet, um den Nutzen eines Beziehungsdatensatzes für die gesamte Zeitdauer zu maximieren.
Da das Erlernen einer neuen Abfragesprache für jede API entfällt, ist GraphQL ein leistungsstarkes Tool. Die Verwendung derselben Abfragesprache mit jeder API ist die beste Lösung. Auf diese Weise können Sie Ihre Anwendungen einfacher entwickeln und warten. Das GraphQL-Schema definiert die Datenstruktur in einer Netzwerkdatenbank. Die Datenknoten in diesem Schema werden durch Beziehungen zwischen ihnen dargestellt. Aus diesem Grund kann auf die Datenstruktur in einer regulären relationalen Datenbank nur durch Inferenz zugegriffen werden. APIs, die GraphQL verwenden, sind keine Datenbanken, sondern Abfragesprachen. Es kann mit einer Vielzahl von Datenbanktypen sowie ohne Datenbank integriert werden, sodass es überall dort verwendet werden kann, wo Datenbanken vorhanden sind. Aufgrund der einfachen Verwendung von GraphQL entfällt die Notwendigkeit, dass eine API für jede Abfrage eine neue Sprache lernt. Da es eine genauere Kontrolle der Daten ermöglicht, ist die Verwendung von GraphQL eine gute Wahl für Netzwerkdatenbanken. Dies ist besonders wichtig, da es die Anzahl der Optionen und die Flexibilität erhöht, mit denen Daten angepasst werden können.
Wie speichert Neo4j Festplattendaten?
Neo4j speichert Festplattendaten in einem proprietären Format, das für schnelles Lesen und Schreiben optimiert ist. Die Daten werden in mehreren Dateien gespeichert, die jeweils eine bestimmte Menge an Daten enthalten. Wenn der Datenbank ein neues Datenelement hinzugefügt wird, wird es in einer neuen Datei gespeichert. Wenn ein Datenelement aus der Datenbank gelöscht wird, wird die Datei gelöscht.
Datenbezogene Dateien werden im Neo4j-Datenverzeichnis abgelegt, wenn sie im Dateityp data/databases/graph.db (v3.x+) abgelegt werden. Ein Feld wird entweder in einem Schlüssel oder einem Wert gehalten. Wenn eine Zeichenkette oder ein Array nicht in 8B-Blöcke passt, hat es einen Zeiger auf einen Datensatz im Zeichenketten-/Array-Speicher (128B). Plattendaten sind in einer verknüpften Liste in all ihren Datensätzen mit fester Größe organisiert. Die Eigenschaften werden als verknüpfte Listen von Datensätzen gespeichert, die jeweils einen Schlüssel und einen Wert enthalten und auf die nächste Eigenschaft verweisen. Das können Sie sich als Beispiel vorstellen: eine Speicherplatzberechnung. Der Anfangsstatus dieses Szenarios.
Die Knotenanzahl beträgt 4 Millionen. Jeder Knoten hat drei (12) unterschiedliche Eigenschaften. Eine Beziehung wird in Form von zwei oder mehr anderen Beziehungen gebildet. Jede Beziehung hat zwei Eigenschaften (M). Dies entspricht den folgenden Datenträgergrößen. Knoten 4.000.x15B hat 600.000 MB Speicherkapazität.
Wo speichert The Graph Daten?
Der Graph speichert Daten in einer Datenbank.
Es wird auf eine Weise verwendet, die relationale Datenbanken nicht ausführen können, um Daten darzustellen und zu speichern. Auf dem Eigenschaftsdiagramm sind Daten mit Analysen und Abfragen verknüpft, während es sich auf dem RDF-Diagramm um Datenintegration handelt. Es gibt zwei Arten von Graphen: solche, die aus Punkten (Scheitelpunkten) bestehen, und solche, die Verbindungen zwischen diesen Punkten beinhalten. Graphen und Graphdatenbanken werden nicht nur zur Darstellung von Beziehungen zwischen Daten verwendet, sondern auch zur Erstellung von Graphmodellen. Diese Systeme sind in der Lage, Abfragen durchzuführen und Graphalgorithmen anzuwenden, um Muster, Pfade, Communities, Influencer, Single-Point-Fehler und andere Beziehungen zu identifizieren. Zu den Fähigkeiten von Graphen in der Analytik gehört ihre Fähigkeit, Einblicke zu liefern, unterschiedliche Datenquellen zu verknüpfen und Einblicke zu generieren. Graphdatenbanken haben eine Fülle von Funktionen, die sie extrem vielseitig und leistungsfähig machen.
Diagramme können auf vielfältige Weise verwendet werden, da sie die Beziehung zwischen Daten betonen. Graphanalysen können verwendet werden, um soziale Netzwerke, Kommunikationsnetzwerke, Websites, Verkehr und Nutzung sowie Finanztransaktionen und -konten zu untersuchen. Graphdatenbanken können verwendet werden, um eine breite Palette von sozialen Netzwerken zu analysieren, aber sie werden typischerweise verwendet, um Graphen zu analysieren. Aus Transaktionen zwischen Entitäten oder Entitäten, die Informationen teilen, erstellte Diagramme können verwendet werden. Graph Analytics kann verwendet werden, um natürliche Muster anstelle von Bot-Mustern zu identifizieren. Graphdatenbanken haben sich zu einem effektiven Werkzeug zur Betrugserkennung in der Finanzbranche entwickelt. Die häufigste Methode zur Aufdeckung von Betrug, die Mustererkennung, ist häufig die erste Verteidigungslinie.
Das erwartete Kaufverhalten eines Benutzers wird durch Faktoren wie seinen Standort, seine Häufigkeit und seinen Ladentyp beeinflusst. Die Fähigkeit von Graph Analytics, Muster zwischen Knoten zu verstehen, ist unübertroffen. Aufgrund der gestiegenen Leistungsfähigkeit und Größe der Daten haben sich Graphdatenbanken entwickelt. Maschinelles Lernen wird normalerweise verwendet, um Betrug aufzudecken, aber Graphanalysen können diese Bemühungen ergänzen, um sie genauer und effizienter zu machen. Die konvergierte Datenbank von Oracle ist für Umgebungen mit mehreren Modellen, mehreren Workloads und mehreren Mandanten ausgelegt.

Diagramme bieten neben ihrer Bequemlichkeit eine Fülle von Vorteilen. Die Verwendung eines Diagramms hat mehrere Vorteile. Ein weiterer Vorteil des Graph Computing besteht darin, dass ein Graph basierend auf einer Vielzahl von Faktoren berechnet werden kann. Diagramme können auf verschiedene Arten gespeichert werden. Eine der einfachsten Möglichkeiten, dies zu tun, besteht darin, für jede Kante einen Vektor zu behalten. Die Situation kann sehr ineffizient werden, wenn dies nicht richtig gemacht wird. Um einen Graphen zu speichern, ist es auch eine gute Idee, ein Paar für jede Kante zu behalten. Dies ist effektiver, aber es kann schwierig sein, den Überblick darüber zu behalten, welche Kanten verwandt sind. Es ist auch möglich, einen Graphen zu speichern, indem man jeder Kante eine Struktur zuweist.
Die Vor- und Nachteile von Graphdatenbanken
In Graphdatenbanken können Beziehungen implizit dargestellt werden, was einen erheblichen Vorteil bei der Datenspeicherung hat. Es ermöglicht Ihnen, die gesuchten Daten direkt zu finden. Graphdatenbanken können auch schwieriger zu manipulieren sein, wenn sie ebenfalls anfällig für diese Art von Schwachstelle sind.
Graphdatenbanken sind die beste Wahl zum Speichern von Daten, die mit etwas zusammenhängen. Diese Kategorie kann auf Daten aus allen Quellen angewendet werden, einschließlich sozialer Netzwerke und wissenschaftlicher Forschung.
Graph-Datenbankspeicher
Graphdatenbankspeicherung ist eine Art von Datenbankspeicherung, die eine Graphdatenstruktur zum Speichern von Daten verwendet. Diese Art der Speicherung eignet sich gut zum Speichern von Daten, die viele Beziehungen zwischen Datenelementen aufweisen. Beispielsweise könnte ein soziales Netzwerk ein Graphdatenbank-Speichersystem verwenden, um Informationen über Benutzer und ihre Beziehungen zu anderen Benutzern zu speichern.
Die Unterschiede zwischen einer Graphdatenbank und einer relationalen Datenbank liegen hauptsächlich in ihren Methoden zum Speichern von Beziehungen zwischen Entitäten. Da es in Graphdatenbanken keine vorgegebene Struktur für die Daten gibt, muss bei einer Abfrage jeder Datensatz einzeln untersucht werden. Eine Spalte in diesem System unterscheidet sich von einer Tabelle dadurch, dass sie sehr flexibel sein kann, wenn es um Datenstruktur und -typen geht. Wenn Sie beabsichtigen, Daten häufig abzurufen, ist die Graph-Datenbank die beste Option, und sie wurde für den Datenabruf optimiert. Wenn Ihre Daten transaktionaler Natur sind, ist es höchst unwahrscheinlich, dass Sie lieber eine Graphdatenbank verwenden würden. Daten können effektiver gespeichert werden und manchmal sind weniger komplexe Analysen erforderlich. Eine Graphdatenbank hingegen kann flexibler und abstrakter sein als eine Schemadatenbank.
Wenn Ihr Datenmodell inkonsistent ist und häufige Änderungen erfordert, sollten Sie die Verwendung einer Diagrammdatenbank in Betracht ziehen. Mit Graphdatenbanken können Sie Beziehungen durchlaufen, wenn Sie einen bestimmten Punkt haben, mit dem Sie beginnen möchten, oder zumindest eine Reihe von Punkten, denen Sie folgen müssen. Eine Graphdatenbank kann ein mächtiges Werkzeug im Bereich des vernetzten Datenmanagements sein. Wenn Sie keine Graphdatenbanken verwenden möchten, verwenden Sie stattdessen einfache Bezeichner (Schlüssel), um einen einzelnen Knoten zurückzugeben. Graphdatenbanken sind nicht die beste Option, wenn Sie extrem große Datensätze wie BLOBs und CLOBs speichern müssen. Wenn Sie diese Attribute jedoch mit anderen Entitäten in der Datenbank verbinden müssen, ist eine Graphdatenbank möglicherweise vorteilhafter als eine Datenbank.
Diagramme eignen sich besser als Tabellen, um Beziehungen zwischen Daten in relationalen Datenbanken darzustellen, da Tabellen zum Speichern von Daten verwendet werden. Das Diagramm stellt sowohl Daten als auch Beziehungen dar, wobei Scheitelpunkte Objekte darstellen und Kanten Beziehungen zwischen ihnen darstellen. Graphdatenbanken sind im Gegensatz zu relationalen Datenbanken als Ganzes strukturiert, wobei Beziehungen im Mittelpunkt stehen.
Graphdatenbanken können aufgrund ihrer hohen Konnektivität große Mengen miteinander verbundener Daten in beträchtlicher Zeit verarbeiten. Die klaren und überschaubaren Darstellungen von Beziehungen in Diagrammen machen sie leicht verständlich. Darüber hinaus machen die Flexibilität und Agilität von Diagrammen sie ideal für eine Vielzahl von Daten.
Ein Nachteil einer Graphdatenbank ist, dass sie keine einheitliche Abfragesprache hat. Infolgedessen kann es für Benutzer schwierig sein, die Datenbank zu erfassen und zu verwenden. Außerdem kann die Darstellung von Zusammenhängen schwer nachvollziehbar sein.
Graphdatenbanken nutzen eine Reihe von Vor- und Nachteilen, aber ihre Stärken sind deutlich größer als ihre Schwächen. Daher ist es eine gute Wahl für Systeme, die stark vernetzte Daten übersichtlich und überschaubar darstellen müssen.
Der Unterschied zwischen Graphdatenbanken und Big Data
Es gibt ein weit verbreitetes Missverständnis, dass Graphdatenbanken und Big Data dasselbe sind. In einer Graphdatenbank gibt es keine Beschränkungen, wie Daten in Blöcken gespeichert werden können. Da Knoten und Beziehungen zum Speichern von Daten verwendet werden, können kleinere Datensätze effizienter verwaltet werden. Obwohl Graphdatenbanken auch heute noch verwendet werden, sind sie im Umgang mit großen Datensätzen effizienter als traditionelle relationale Datenbanken.
Diagramm in relationaler Datenbank speichern
Es gibt viele Möglichkeiten, ein Diagramm in einer relationalen Datenbank zu speichern. Eine Möglichkeit besteht darin, die Kanten des Graphen als Datensätze in einer Tabelle zu speichern, wobei jeder Datensatz die IDs der beiden Eckpunkte enthält, die die Kante verbindet. Eine andere Möglichkeit besteht darin, die Kanten des Diagramms als Datensätze in einer Tabelle zu speichern, wobei jeder Datensatz die ID des Scheitelpunkts enthält, an dem die Kante beginnt, die ID des Scheitelpunkts, an dem die Kante endet, und die Gewichtung der Kante.
Es ist eine Datenstruktur, die aus Knoten und Kanten besteht. Es ist üblich, Kanten zu finden, die eine Beziehung zwischen zwei Knoten anzeigen. Beziehungen zwischen Knoten sind die Themen dieser Beziehungen in der Datenbank. Tabellen können diese Struktur auf verschiedene Weise darstellen. Aufgrund seines Wachstums nimmt die Anzahl der Zellen mit NULL-Werten zu. Sparse-Tabellen sind einfach zu implementieren, aber nicht so effizient wie viele Entitäten in einem einzigen System. Der Betrieb kann in einigen Fällen festgefahren oder verzögert werden, und Migrationen können schmerzhaft sein.
Die Satellitentabelle hat ihren Namen von der Sparse-Tabelle, die wir zuvor gesehen haben. Die Satellitentabelle enthält eine Vielzahl von Tabellen mit separaten Tabellen für jeden Entitätstyp. Da die Daten über mehrere Tabellen verteilt sind, sind Lese- und Schreibvorgänge nicht so überlastet wie beim Tabellendesign mit geringer Dichte. Die Auswirkungen von Migrationen haben zugenommen, aber ihre Verbreitung hat abgenommen. Mit NoSQL können Sie sowohl Kuchen essen als auch Informationen speichern. Es gibt nichts Besseres als RDS, und es gibt nichts Besseres als eine schemalose Abfragesprache, mit der Sie Ihre Daten als solche behandeln können. In Ihrer DB werden normale Daten normalisiert.
In den meisten Fällen finden Migrationen zu den Daten auf Datenbankebene statt. Eine NoSQL-Datenbank ist im Allgemeinen skalierbarer als eine relationale Datenbank, aber dieser Vorteil kommt nur zum Tragen, wenn eine große Anzahl von Datensätzen beteiligt ist. Die Auswahl eines guten Partitionsschlüssels sollte im Voraus getroffen werden. DynamoDB ist für Batch-Updates mit einem Durchsatzlimit vorgesehen, während MongoDB die Reduzierung von Datenbank-Mapreduces ermöglicht.
Der Vorteil der Speicherung von Beziehungen auf individueller Datensatzebene
Beziehungen können auf individueller Ebene gespeichert werden, was ihre Effizienz erhöht. Wenn Datenbanken zeitnah auf einen Datensatz zugreifen, müssen sie keine Tabellen danach durchsuchen.
Graphdatenbanken speichern Daten
Graphdatenbanken speichern Daten als Graphen, wobei die Daten als Knoten und Kanten dargestellt werden. Dies ermöglicht eine flexiblere und effizientere Abfrage der Daten sowie eine leistungsfähigere Datenanalyse.
Graphdatenbanken sollen von Benutzern verwendet werden, die stark vernetzte Daten haben. True Graphs, Triple Stores und konventionelle Datenbanken sind die drei Arten von Graphdatenbanken. Eine Graphdatenbank von Neo4j kann Unternehmen dabei helfen, ihre Daten besser zu verwalten. Es ermöglicht Unternehmen auch, KI- und maschinelle Lernmodelle schnell und einfach zu entwickeln. Es ist ideal für Situationen, in denen Elemente gleichzeitig verknüpft werden müssen, der Zugriff in Sekundenschnelle möglich ist und Millionen von Beziehungen gleichzeitig abgefragt werden können. Da physisch in der Datenbank verknüpfte Knoten miteinander verknüpft sind, ist der Zugriff auf die Beziehungen so einfach wie auf die Daten selbst. Es ist nicht möglich, für jede Art von Graphdatenbank eine einzige Lösung zu finden.
Das Ziel von Graphdatenbanken ist die Verarbeitung großer dynamischer Beziehungsnetze mit komplexen Datenmodellen. Diese Systeme sind neben Chatbots, Konversationssystemen, Empfehlungsalgorithmen, Optimierungsanwendungen, Routing und Karten für Datenmanagement und Datenintelligenz erforderlich. Wenn eine Anwendung so konfiguriert ist, dass sie mit einer Graphdatenbank arbeitet, steigt ihr Wert sprunghaft an.
Viele Menschen verwenden Graphdatenbanken aus verschiedenen Gründen. Ein erster Vorteil dieser Systeme ist, dass sie komplexe Daten speichern können, die einfach abgefragt werden können. Darüber hinaus sind sie äußerst vielseitig in der Speicherung von angeschlossenen Daten. Sie sind auch an sich ändernde Umgebungen anpassbar. Die unten aufgeführten Faktoren sollten alle bei der Auswahl einer Datenbank berücksichtigt werden.
Die Popularität von Graphdatenbanken ist das Ergebnis einer Vielzahl von Faktoren.
Eine Diagrammdatenbank ermöglicht Benutzern den einfachen Zugriff auf große Mengen komplexer Daten. Dies ist wichtig, da komplexe Daten oft schwer zu lesen sind. Auch Graphdatenbanken eignen sich zur Speicherung von zusammenhängenden Daten. Konnektivitäten zwischen Knoten sind häufig entscheidend für den Erfolg eines Knotens. Graphdatenbanken können auch in Bezug auf die Skalierung sehr effizient sein. Dabei können große Datenmengen ohne Leistungseinbußen gespeichert werden.
Im Allgemeinen sind in Graphdatenbanken gespeicherte Daten eine gute Wahl zum Speichern komplexer Informationen. Es ist einfach zu bedienen und bietet eine klare und leicht lesbare Darstellung der Daten. Sie sind hervorragende Rechenzentren, weil sie verbunden werden können und Daten speichern. Schließlich haben sie die Fähigkeit zu skalieren.
Kann die Graph-Datenbank Dokumente speichern?
Anstelle von Tabellen oder Dokumenten werden Knoten und Beziehungen in Graphdatenbanken gespeichert. Daten können genauso gespeichert werden, wie Sie Ihre Ideen auf einem Whiteboard skizzieren würden.
Die Vorteile von Graphdatenbanken
Graphdatenbanken werden immer beliebter, da sie zahlreiche Vorteile gegenüber herkömmlichen Datenbanken bieten. Graphdatenbanken sind effizienter, wenn Fremdschlüssel und große Datensätze in der Datenbank vorhanden sind. Darüber hinaus lassen sie sich einfacher grafisch abfragen und eignen sich gut für Echtzeit-Datenanalyseanwendungen.
Anwendungsfälle für Graphdatenbanken Graphdatenbanken
Es gibt viele Anwendungsfälle für Graphdatenbanken, darunter soziale Netzwerke, Betrugserkennung und Empfehlungsmaschinen. Anwendungen für soziale Netzwerke können Graphdatenbanken verwenden, um Beziehungen zwischen Personen, Orten und Dingen zu modellieren und abzufragen. Betrugserkennungsanwendungen können Graphdatenbanken verwenden, um Beziehungen zwischen Finanztransaktionen zu modellieren und abzufragen. Empfehlungsmaschinen können Diagrammdatenbanken verwenden, um Beziehungen zwischen Produkten, Dienstleistungen und Personen zu modellieren und abzufragen.
Wenn Sie eine Graphdatenbank verwenden, müssen Sie sich keine Gedanken über Datenverlust machen, da die Speicherung sicher ist. Beziehungen werden in Datenbanken basierend auf dem Modell von Zeilen und Spalten statt Zeilen und Spalten gespeichert. Der moderne Finanzmarkt ist besorgt über eine Vielzahl von Betrügereien. Die Verwendung von Graph-Technologie verbessert die Leistung von ML-basierten Betrugserkennungssystemen. Die Daten Ihres Unternehmens können vollständiger durch eine Diagrammdatenbank dargestellt werden. Algorithmen können verwendet werden, um nützliche Erkenntnisse aus Graphen und Netzwerken zu generieren. Graphen ermöglichen ein schnelleres und effizienteres Auffinden von Mustern.
Mithilfe von Grafiktechnologie, fortschrittlichen Algorithmen und künstlicher Intelligenz ist es möglich, die Fähigkeit zur Gestaltung von Behandlungen zu verbessern. Graphdatenbanken, die von vielen der beliebtesten Social-Media-Plattformen verwendet werden, werden verwendet, um Benutzerinteraktionen zu analysieren. Das Ziel dieser Methode ist es, erkennen zu können, welche Konten von Bots betrieben werden. Fragen Sie sich, ob eine Graphdatenbank eine gute Lösung für Ihr Unternehmen ist?
Graphdatenbanken und digitale Assets
Mit Graphdatenbanken können Sie Beziehungen herstellen und Daten speichern. Diese Fachleute sind Experten in der Kunst der Verwaltung digitaler Assets wie Filme und Fernsehsendungen.