
Die Unterscheidungsmerkmale von Hadoop: Open-Source-Skalierbarkeit und Fehlertoleranz
Veröffentlicht: 2022-11-18Hadoop ist ein Open-Source-Software-Framework für die verteilte Speicherung und Verarbeitung großer Datenmengen über Computer-Cluster hinweg. Es ist so konzipiert, dass es von einem einzelnen Server auf Tausende von Maschinen skaliert werden kann, von denen jede lokale Berechnung und Speicherung bietet. Anstatt sich auf Hardware zu verlassen, um Hochverfügbarkeit bereitzustellen, ist das Framework darauf ausgelegt, Fehler auf der Anwendungsebene zu erkennen und zu handhaben. Hadoop ist eine Nosql-Datenbank, da sie eine völlig andere Architektur als eine herkömmliche relationale Datenbank verwendet. Hadoop ist auf horizontale Skalierung ausgelegt, was bedeutet, dass es skaliert werden kann, um mehr Daten aufzunehmen, indem weitere Standardserver zum Cluster hinzugefügt werden. Hadoop ist außerdem fehlertolerant ausgelegt, was bedeutet, dass das System ohne diesen Server weiter funktionieren kann, wenn ein Server im Cluster ausfällt.
Hadoop wird weder zum Speichern von Daten verwendet, noch erfordert es die Verwendung von relationalem Speicher; Vielmehr wird es verwendet, um riesige Datenmengen auf verteilten Servern zu speichern. Eine Hadoop-Datenbank ist eher eine Art von Daten als ein Softwaresystem, das massive parallele Datenverarbeitung ermöglicht. Es handelt sich um einen Bindungstyp einer NoSQL-Datenbank (z. B. HBase), der es Benutzern ermöglicht, Datenbanken in einer gebundenen Vielfalt abzufragen und zu durchsuchen. RDBMS in seiner aktuellen Form wäre nicht in der Lage, mit Hadoop zu konkurrieren, da es sowohl relative als auch Transaktionsdaten verwalten kann. Hadoop ist in der Lage, jede Art von Daten zu verarbeiten, ob strukturiert, halbstrukturiert oder unstrukturiert, und unterstützt eine Vielzahl von Methoden. Big-Data-Analysen verschaffen Unternehmen einen echten Wettbewerbsvorteil, indem sie tiefere Einblicke liefern. Hadoop unterstützt als Service die Nutzung von Online Analytical Processing (OLAP) in der Datenverarbeitung. Es ist wichtig, sich daran zu erinnern, dass die Datenverarbeitungsgeschwindigkeit durch die Anzahl der Datenanfragen bestimmt wird. Sie können Hadoop verwenden, wenn Sie beispielsweise keine ACID-Transaktionen oder OLAP-Unterstützung wünschen.
Hadoop und In-Memory-Datenbanken sind zwei völlig unterschiedliche Technologien, die sich überschneiden. Sie sind nicht gleich, aber sie stimmen in einigen Dingen überein.
Analytische Anwendungen, die SQL-on-Hadoop verwenden, kombinieren etablierte Abfragemethoden im SQL-Stil mit neueren Elementen des Hadoop-Datenframeworks . SQL-on-Hadoop ermöglicht Unternehmensentwicklern und Geschäftsanalysten die Zusammenarbeit auf Hadoop-Clustern mit vertrauten SQL-Abfragen.
Es ist eine NoSQL-Datenbank, die ein Mittel zum Speichern und Abrufen von Daten bietet. Nicht-relational/nicht-SQL ist einer der Begriffe, die in diesem Bereich häufig verwendet werden.
Daten werden auf verschiedene Weise von Hadoop und SQL verwaltet. SQL ist eine Programmiersprache, während Hadoop ein Framework von Komponenten in Software ist. Beide Tools sind für Big Data nützlich, haben aber Nachteile. Die Hadoop-Plattform kann einen viel größeren Datensatz verarbeiten, schreibt Daten jedoch nur einmal.
Was ist der Unterschied zwischen Hadoop und Nosql?
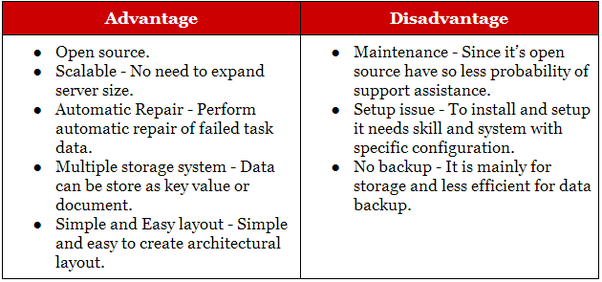
Hadoop eignet sich für analytische und historische Archivierungsanwendungen, während NoSQL ideal für betriebliche Workloads ist, die ihre relationalen Gegenstücke ergänzen. NoSQL-Datenbanken begannen als Key -Value-Store-Datenbanken , aber später kamen Document/JSON- und Graph-Datenbanken hinzu.
Echtzeitverarbeitung, große Datenmengen und unstrukturierte Daten sind nur einige der Szenarien, in denen die NoSQL-Technologie eingesetzt werden kann. Dadurch können einige dieser Herausforderungen wie Skalierbarkeit und Verfügbarkeit angegangen werden. Die NoSQL-Datenbank hat gegenüber der traditionellen relationalen Datenbank eine Reihe von Vorteilen. Sie können Datensätze viel schneller und skalierbarer verarbeiten als bisher. Datenbankverwaltungssysteme erfordern auch weniger Wissen und Fachwissen als herkömmliche Datenbanken , wodurch sie einfacher zu verwenden sind. Eine NoSQL-Datenbank hat gegenüber einer herkömmlichen relationalen Datenbank eine Reihe von Vorteilen. Die wichtigste Überlegung ist, ob Sie sie für die Echtzeitverarbeitung und große Datenmengen benötigen.
Nosql-Datenbanken sind die bessere Wahl für Unternehmen mit Big-Data-Workloads
Wenn sich Ihre Daten-Workloads mehr auf die Analyse und Verarbeitung großer Mengen unterschiedlicher und unstrukturierter Daten wie Big Data konzentrieren, sind NoSQL-Datenbanken die bessere Wahl. Im Gegensatz zu relationalen Datenbanken setzen NoSQL-Datenbanken nicht auf ein festes Schemamodell. Das RDBMS ist in Bezug auf das Speichern, Verarbeiten und Verwalten von Daten flexibler als herkömmliche RDBMS, was es zu einer besseren Option für Unternehmen macht, die schnell auf große Datenmengen zugreifen und diese unbegrenzt speichern müssen.
Ist Big Data SQL oder Nosql?

Wenn es bei Ihren Daten-Workloads in erster Linie darum geht, große Mengen unterschiedlicher und unstrukturierter Daten wie Big Data schnell zu verarbeiten und zu analysieren, ist NoSQL die beste Wahl. Das NoSQL-Datenbankmodell ist insofern einzigartig, als es nicht auf derselben Schemastruktur wie eine relationale Datenbank beruht.
Es geht nicht mehr darum, ob Big Data die Fertigung verbessern wird; es ist eine Frage des wann. In Big Data stehen riesige, vielfältige und komplexe Mengen an strukturierten und unstrukturierten Daten zur Verfügung. Sensoren, Kameras in der Produktion und Verbrauchergeräte können alle verwendet werden, um Big Data in der Fertigung zu sammeln. Da die meisten Daten in der Fertigung unstrukturiert sind, können NoSQL-Architekturen nicht mit starren Ansätzen wie SQL konkurrieren. Eine NoSQL-Datenbank benötigt keine Schemas, um Daten in derselben Datenbanktabelle zu speichern, sodass Benutzer Daten in verschiedenen Strukturen speichern können. Die Trennlinie eines Unternehmens lässt sich daran ablesen, wie viele Daten es zu verwenden gedenkt. Transaktionen müssen vier grundlegenden Funktionsprinzipien entsprechen, um als relationale Datenbanktransaktion betrachtet zu werden.
Da NoSQL-Systeme und Cloud-Systeme integriert werden können, bietet es sich an, Cloud-Computing-Frameworks zur Unterstützung von NoSQL-Systemen einzusetzen. Durch die Integration mit Manufacturing Execution Systems (MES) kann eine Echtzeit-Fertigungsprozessoptimierung über NoSQL erreicht werden. Möglich wurde dieser Erfolg durch den Einsatz von Big-Data-Analysen, um schneller auf sich ändernde Bedingungen reagieren zu können. MongoDB ist eine gute NoSQL-Datenbank, da sie einfach einzurichten ist und für Analysen verwendet werden kann. Die Verwendung reaktionsschnellerer Datenbankarchitekturen wie NoSQL ermöglicht es dem Management, bessere Simulationen durchzuführen und so bessere Produktentscheidungen in der realen Welt zu treffen. B2B-Datenbanken sind anfällig für Cross-Site-Angriffe sowie Injection- und Brute-Force-Angriffe. Ein Injection-Angriff tritt auf, wenn ein Angreifer Daten zu NoSQL-Abfragebefehlen oder Speicheranweisungen hinzufügt.

Der Fertigungssektor ist besonders besorgt über die Sicherheit der NoSQL-Architektur. Wenn ein Denial-of-Service-Angriff oder Injection-Angriff erfolgreich durchgeführt wird, kann ein Hersteller möglicherweise die Spezifikationen ändern. Aus diesem Grund können sich Wettbewerber in einem hart umkämpften Markt einen Vorteil verschaffen.
Geschäftsprozesse, die auf Echtzeitdaten angewiesen sind, werden immer häufiger, da Unternehmen nach Möglichkeiten suchen, ihre Effizienz und Reaktionsfähigkeit auf Kundenanforderungen zu verbessern. Cloudbasierte NoSQL-Datenbanken wie Cloud Bigtable bieten eine schnelle und effiziente Möglichkeit, große Datensätze zu speichern und darauf zuzugreifen, was sie zu einer hervorragenden Lösung für diese Art von Anwendungen macht.
Cloud Bigtable ist ein NoSQL-Datenbankdienst, der vollständig verwaltet wird und eine Betriebszeit von 99,999 % bietet. Es ist ideal für analytische und operative Workloads, da es hohe Datenzufuhrgeschwindigkeiten hat und einfach nach oben und unten skaliert werden kann. Daher ist es eine ausgezeichnete Wahl für die Echtzeit-Datenverarbeitung in Anwendungen wie Mobile Gaming und Einzelhandelsanalysen.
Ist Nosql die beste Datenbank für große Datenmengen?
MongoDB zum Beispiel ist eine ausgezeichnete Wahl für die Speicherung großer Datenmengen. Sie ermöglichen ein breites Spektrum an performanten, agilen Verarbeitungsszenarien. Darüber hinaus werden unstrukturierte Daten in NoSQL-Datenbanken auf mehreren Verarbeitungsknoten und auf mehreren Servern gespeichert. Infolgedessen waren NoSQL-Datenbanken die Standardwahl einiger der weltweit größten Data Warehouses . Welche Datenbank ist die beste für große Datenmengen? Bei dieser Frage lässt sich aufgrund der unterschiedlichen Anforderungen der Organisation nicht vorhersagen, welche Datenbank die beste für große Datenmengen ist. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 und viele andere Datenbanken gehören zu den beliebtesten Optionen für die Speicherung großer Datenmengen.
Ist Hadoop eine Datenbank
Hadoop ist ein verteiltes Dateisystem und Framework zum Ausführen von Anwendungen auf großen Clustern handelsüblicher Hardware. Hadoop ist keine Datenbank.
Hadoop, ein Open-Source-Framework, ermöglicht die effiziente Speicherung und Verarbeitung riesiger Datensätze. Hive- und Imperative-Tabellen können mithilfe von Textdateien in HDFS erstellt werden. Es unterstützt die drei wichtigsten Dateiformate: Sequenzdateien, Avro-Datendateien und Parquet-Dateien. Eine Reihe von Bytes wird durch Datenserialisierung als Speichereinheit dargestellt. Avro, ein effizientes Framework zur Datenserialisierung, wird von Hadoop und seinem Ökosystem umfassend unterstützt.
Die Verwendung von Textdateien als Speicherformat für Hive- und implizite Tabellen vereinfacht die Datenverwaltung und -manipulation. Daher ist es eine gute Wahl für die Stapelverarbeitung oder das Speichern von Daten in einer Vielzahl von Formaten. Darüber hinaus ermöglicht die Datenserialisierung über Avro eine effiziente und komfortable Datenspeicherung und -abfrage. Daher ist es eine gute Option, um Daten in einer Vielzahl von Formaten zu speichern oder eine parallele Verarbeitung durchzuführen.
Hadoop vs. Nosql
Hadoop verarbeitet Big Data für einen Cluster von Standardhardware. Wenn die Funktionalität Ihren Anforderungen nicht entspricht oder nicht funktionsfähig ist, kann sie geändert werden. Dies wird als NoSQL bezeichnet und ist eine Art Datenbankverwaltungssystem , das strukturierte, halbstrukturierte und unstrukturierte Daten speichert.
MongoDB wurde 2007 als NoSQL-Datenbank (Not Only SQL) als Ergebnis der C++-Entwicklung erstellt. Ein Hadoop ist eine Sammlung von Open-Source-Softwareprogrammen, die hauptsächlich in Java für die Verarbeitung großer Datenmengen geschrieben sind. Diese Plattform umfasst auch eine Volltextsuche, erweiterte Analysetools und eine benutzerfreundliche Abfragesprache. Obwohl Hadoop vor allem für seine Fähigkeit bekannt ist, große Datenmengen zu speichern und zu verarbeiten, tut es dies auch in kleinen Stapeln. MongoDB bietet eine Vielzahl von Echtzeit-Datenverarbeitungstools. Die Konnektoren von MongoDB für externe Tools wie Kafka und Spark vereinfachen die Datenerfassung und -verarbeitung. Beim Datenhandling bieten Hadoop und MongoDB zahlreiche Vorteile gegenüber herkömmlichen Datenbanken. Hadoop ist aufgrund seines verteilten Dateisystems ein hervorragendes Werkzeug für den Umgang mit großen Datenstrukturen. MongoDB ist die einzige Datenbank, die als Ersatz für herkömmliche Datenbanken verwendet werden kann.
Ist Spark eine Nosql-Datenbank?
In der Dokumentation wird angegeben, dass ein NoSQL-DataFrame ein Spark-DataFrame ist, der auf dem Spark-Format zum Speichern von Daten basiert. Im Gegensatz zu früheren Datenquellen unterstützt diese Datenbereinigung und -filterung (Prädikat-Pushdown), sodass Spark-Abfragen weniger Daten abfragen und nur die erforderlichen Daten nach Bedarf laden können.
Es ist wichtig, taktisches Bewusstsein zu bewahren, wenn Apache Spark- und NoSQL-Datenbanken ( Apache Cassandra und MongoDB) zusammen in einer Anwendung verwendet werden. Dieser Blog konzentriert sich auf die Verwendung von Apache Spark in einer NoSQL-Anwendung. CassandraLand und MongoLand im TCP/IP sPark sind zwei der beliebtesten Fahrgeschäfte und ein großartiger Ort für einen Besuch, wenn Sie Themenparks mögen. Beim Nachschlagen von Daten des Energieministeriums fing unsere Spark-Anwendung an, sich zu drehen. Hier ist eine kurze Lektion darüber, wie wichtig die Cassandra-Tastenfolge beim Abfragen ist. Es gibt auch die Achterbahn Partitioner im CassandraLand. Kunden, die Spaß an Achterbahnen haben, können ihre Informationen mit den Fahrgeschäftbetreibern teilen, damit sie täglich verfolgen können, wer sie gefahren ist.
Die erste Lektion in MongoDB Lektion 1 ist die ordnungsgemäße Verwaltung von MongoDB-Verbindungen. Wenn Sie Informationen über den neuen Mitgliedsstatus des Energieministeriums aktualisieren müssen, sind Mongo-Indizes äußerst nützlich. Als MongoDB- oder Spark-Kunde sollten Sie im Falle von Systemaktualisierungen eine ordnungsgemäße Verbindung und Indizes aufrechterhalten.