
Das HDF5-Datenformat: Eine attraktive Option zum Speichern und Verwalten großer Datensammlungen
Veröffentlicht: 2023-02-13HDF5 ist ein Datenformat zum Speichern und Verwalten großer, komplexer Datensammlungen. Es wird häufig in wissenschaftlichen und technischen Anwendungen verwendet, und seine Popularität hat in den letzten Jahren zugenommen. HDF5 ist keine Datenbank, kann aber zum Speichern von Daten in einem hierarchischen Format verwendet werden, das einem Dateisystem ähnelt. Dies macht HDF5 zu einer attraktiven Option für Anwendungen, die große Datenmengen speichern und verwalten müssen.
Sie können Metadaten und Rohdaten aus HDF5- und netCDF4-Dateien extrahieren und Hadoop-Streaming verwenden, um Hadoop-Daten mit dem Hadoop Distributed File System (HDFS) HDF5 Connector Virtual File Driver (VFD) zu analysieren.
Ist Hdf5 eine Datenbank?
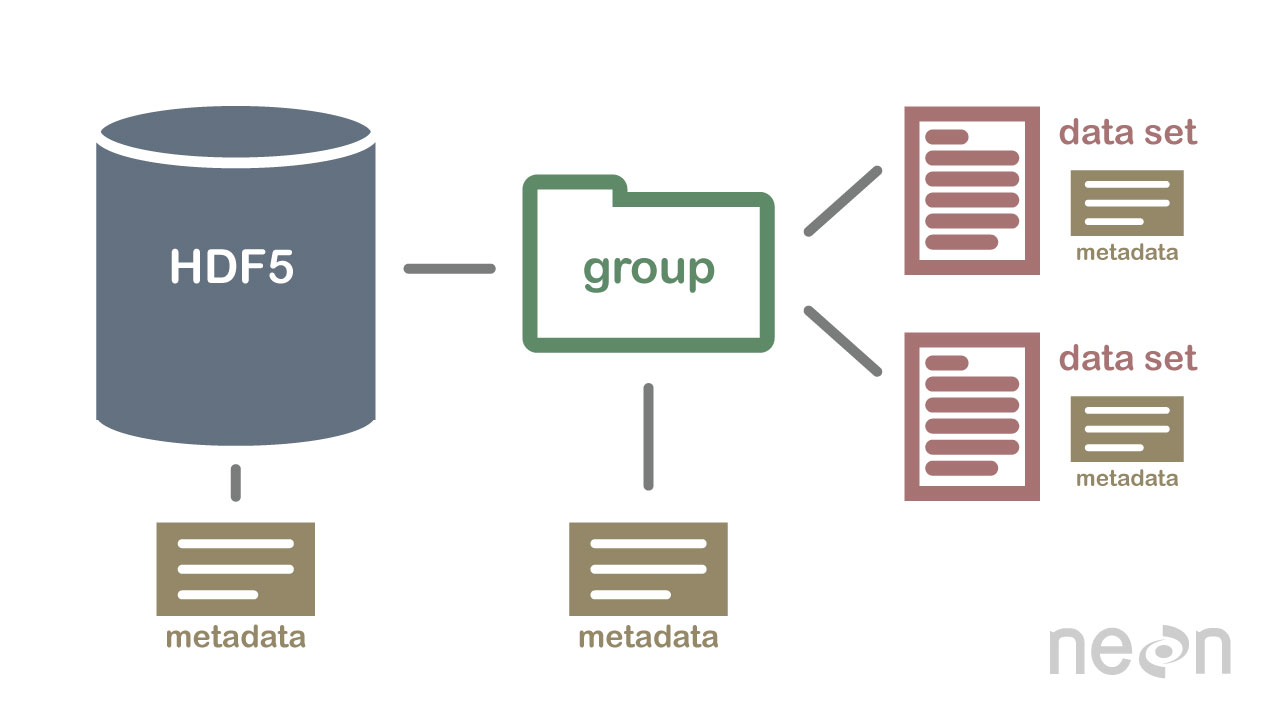
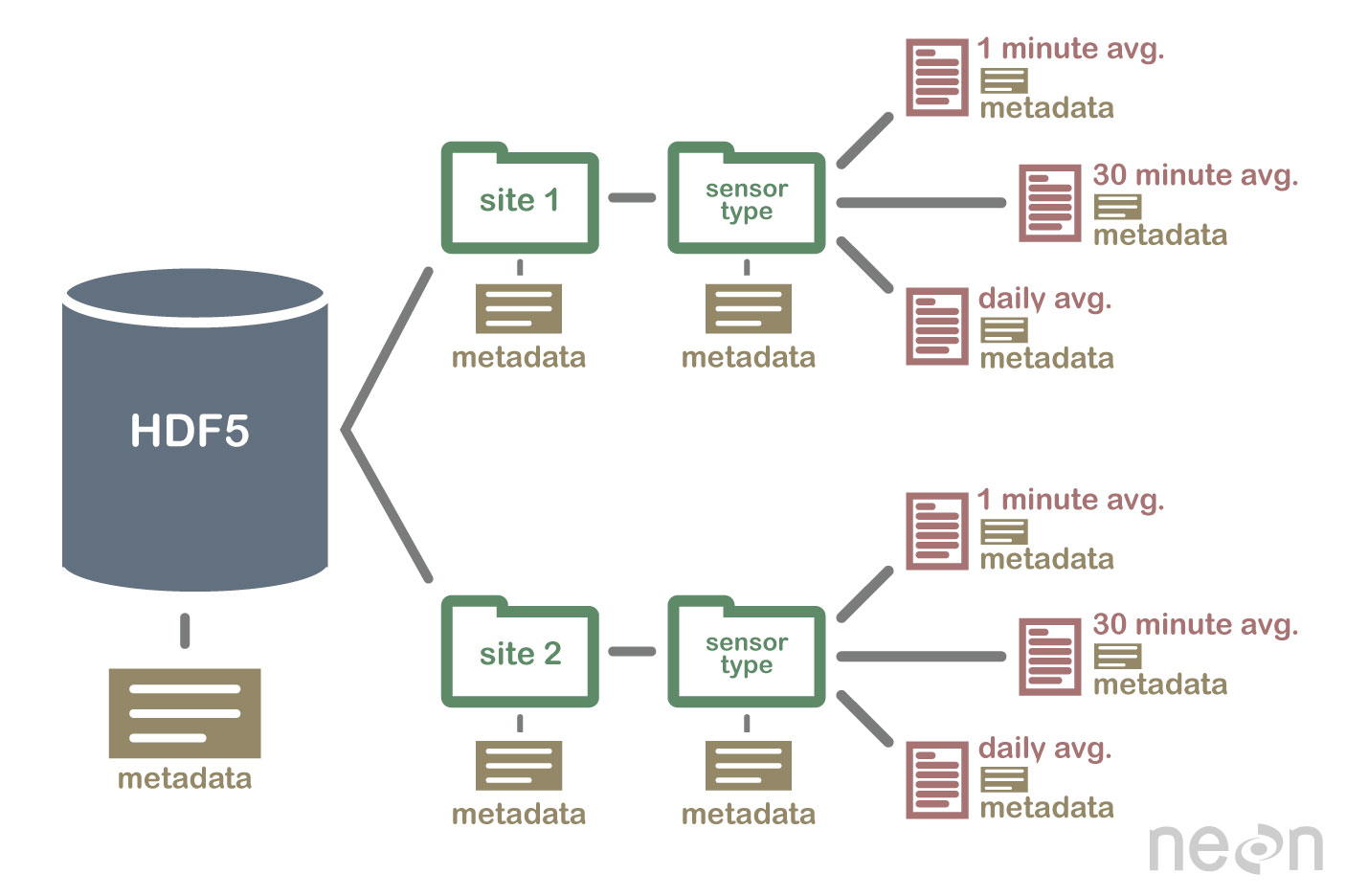
HDF5 ist keine Datenbank, aber es kann verwendet werden, um Daten in einer hierarchischen Struktur zu speichern, ähnlich einem Dateisystem. HDF5 kann zum Speichern von Daten in einer Vielzahl von Formaten verwendet werden, darunter Text, Bilder und Binärdaten .
Daten im hierarchischen Format (HDF5) sind in der wissenschaftlichen Forschung äußerst nützlich. Das HDF5-Dateisystem ist ein ausgezeichnetes Format, da es einem Dateisystem sehr ähnlich ist und sehr effizient ist. Wenn es um verschlüsselte Daten in diesem Format geht, kann es schwierig sein, darauf zuzugreifen. Dieser Leitfaden führt Sie durch, wie Apache Drill Ihnen dabei helfen kann, auf HDf5-Datensätze zuzugreifen und diese abzufragen. Drill hat über die Option defaultPath Zugriff auf einzelne HDF5-Dateien. Dies wird entweder durch direktes Ausführen der Funktion table() während der Abfragezeit oder über die Konfiguration erreicht. Die Ergebnisse dieser Abfrage finden Sie in der folgenden Tabelle. Drill kann dann die Spalten auswählen und einzeln filtern, gefiltert, aggregieren oder mit anderen Daten kombinieren, die abgefragt werden können.
Die HDF5-Spezifikation definiert ein Dateiformat zum Speichern von Datenarrays. Ein Datenarray kann aus beliebigen Datentypen bestehen, einschließlich Zeichenfolgen-, Gleitkomma-, komplexen und ganzzahligen Daten. Ein Array kann Daten beliebiger Größe enthalten und jede Form haben. In HDF5 muss man zuerst eine Header-Datei erstellen, um einen Datensatz zu erstellen. Die Header-Datei enthält Informationen über den Datensatz sowie Metadaten. Die Header-Datei enthält zwei wichtige Informationen: den Namen des Datensatzes und die Versionsnummer des Datensatzes. Ein Datenarray wird verwendet, um die Daten eines Datensatzes zu speichern. Blöcke bestehen aus Daten in einem Datenarray. In einem Datenarray enthält jeder Datenblock einen zusammenhängenden Datensatz. Die Anzahl der Blöcke eines Datensatzes wird durch die Anzahl der darin enthaltenen Bytes bestimmt. Auf die Daten kann über eine Reihe von Methoden gemäß der HDF5-Spezifikation zugegriffen werden. Indizierungsmethoden werden am häufigsten verwendet, um Daten in einem Datensatz zu erhalten. Mit diesen Methoden können Sie auf Daten zugreifen, indem Sie den Namen eines Blocks in das Datenarray eingeben, auf das Sie zugreifen möchten. Die Strukturmethode kann verwendet werden, um auf Daten in einem Datensatz zuzugreifen. Wenn Sie diese Methoden verwenden, können Sie auf Daten zugreifen, indem Sie die Struktur eines Datenarrays verwenden. Im folgenden Beispiel können Sie auf die Daten in einem Datenarray zugreifen, indem Sie die Offset- und Längenwerte der Strukturmethode verwenden. Eine andere Möglichkeit, Daten aus einem Dataset abzurufen, ist die Verwendung von Funktionsmethoden. Sie können Daten mit einer der Methoden abrufen, indem Sie die Funktion in der Header-Datei für die Daten auswählen. Die Methode für den Zugriff auf ein Daten-Array kann verwendet werden, indem der Wert in der Header-Datei als Daten-Array-Element des Arrays definiert wird. Schließlich können Sie mit der Zugriffsmethode auf die Daten in einem Dataset zugreifen. Durch Anwendung dieser Methoden können Sie auf die Daten zugreifen, indem Sie die in der Header-Datei festgelegten Zugriffsrechte verwenden. Mit anderen Worten, die Verwendung des Leseprivilegs kann über die Zugriffsmethode auf Daten in einem Datenarray zugreifen. Daten können mit der HDF5-Spezifikation auf vielfältige Weise erstellt und verwendet werden. Die create-Methode ist die gebräuchlichste Methode zum Erstellen eines Datasets. Mit der create-Methode können Sie einen Datensatz erstellen, indem Sie den Namen des Datensatzes und die Versionsnummer des Datensatzes eingeben. Neben der HDF5-Spezifikation kann die Nutzung von Datensätzen auf vielfältige Weise bewerkstelligt werden. Die am häufigsten verwendete Methode.

Ist Hdf5 eine relationale Datenbank?
HDF5 ist keine relationale Datenbank.
Ist Graphql Nosql oder SQL?
Das Hauptziel von GraphQL ist es, ein Typsystem zu verwenden, um Daten schneller und effizienter zurückzugeben. SQL (Structured Query Language) ist eine ältere, weiter verbreitete Sprache zum Speichern von Daten in tabellarischen oder relationalen Datenbanksystemen . Wenn Sie möchten, dass Ihre API auf einer NoSQL-Datenbank aufbaut, wäre es eine gute Idee, mit GraphQL zu arbeiten.
The Type Mismatch ist eine GraphQL- und NoSQL-Datenbank, die von Herman Camarena und Roger Cochrane erstellt wurde. Die Verwendung von GraphQL kann zur Einführung eines Typsystems anstelle eines NoSQL-Systems führen, wodurch die durch NoSQL-Systeme geschaffene Flexibilität beseitigt wird. Eine GraphQL-Sammlung enthält eine Vielzahl von Dokumenten, die in ihrer Struktur konsistent sind und einige Ausnahmen enthalten. Da GraphQL über einen integrierten Satz von Datentypen verfügt, die den Typen von Backends entsprechen, können Entwickler auswählen, welche Datentypen erstellt werden sollen. GraphQL sollte sich mit dem Problem der Typkonflikte befassen, um sein Potenzial voll auszuschöpfen. In Bezug auf seine Funktionen bietet es aufgrund seiner vielen Vorteile eine Mismatch-Lösung auf niedrigerem Niveau. Mit Tools wie JSON2SDL von StepZen wird die Arbeit immer mehr automatisiert.
Es ist ein leistungsstarkes Tool, mit dem widerstandsfähigere und effizientere Anwendungen erstellt werden können, aber SQL ist kein Ersatz. In Bezug auf die Wartung kann sich dies negativ auswirken, da einige Aufgaben dadurch erschwert werden.
Graphql: Eine Abfragesprache für jede Datenbank
Die Abfragesprache GraphQL ermöglicht es Clients und Servern, miteinander zu kommunizieren. Eine GraphQL-Instanz kann Änderungen entweder aus einer Datenquelle oder einem persistenten Zustand abrufen und beibehalten. Ein Resolver ist ein Satz willkürlicher Funktionen, die für den Zugriff auf und die Bearbeitung von Daten verwendet werden. Die API ist in einer Vielzahl von Datenbanken verfügbar, und GraphQL kann mit jeder verwendet werden. Die MongoDB-Datenbank ist eine beliebte Datenquellendatenbank , die für verschiedene Datentypen agnostisch ist.
Verwendet Nosql B-Bäume?
NOSQL-Datenbanken verwenden keine B-Bäume, da sie nicht auf dem relationalen Modell basieren. NOSQL-Datenbanken basieren häufig auf Schlüssel-Wert-Paaren, Dokumentspeichern oder Graphdatenbanken.
B-Bäume sind die standardmäßige Indizierungsstruktur in MongoDB. Bei der Datenspeicherung ist ein B-Baum eine effizientere Methode. Die Daten können mithilfe von Ganzzahlen und Zeichenfolgen organisiert werden, wenn sie zusammen verwendet werden. Daher sollten Datenbanken mit einem hohen Datenvolumen die Verwendung in Betracht ziehen. Da B-Bäume viel Platz einnehmen können, sind sie ein effizientes Modell. Dies ist vorteilhaft für Datenbanken, die eine große Datenmenge speichern müssen. B-Trees sind auch eine gute Wahl für Datenbanken, die Daten auf eine bestimmte Weise organisieren müssen.
Welche Datenbank verwendet B-Tree?
Es existiert schon lange und kann in einer Vielzahl von Datenbanken verwendet werden. NoSQL-Datenbanken können zusätzlich zu B-Tree-Engines auf B-Tree-Engines aufgebaut werden. MongoDB beispielsweise indiziert Daten in B-Bäumen. Der Algorithmus ist für das DBMS derselbe wie für eine relationale Datenbank, obwohl es einige Ausnahmen gibt. Zeichenfolgen und ganze Zahlen können verwendet werden, um Daten im B-Baum zu organisieren.
Welche Datenbank verwendet B-Tree? MySQL verwendet im folgenden Artikel sowohl Btree als auch B+tree. SQL Server speichert Indizes basierend auf schlüsselbasierten persistenten Daten in Form eines BTree. Als Ergebnis erscheint jeder Knoten in einem solchen Baum als einzelne Seite.