
Die Oracle NoSQL-Datenbank
Veröffentlicht: 2022-12-17Die Oracle NoSQL-Datenbank ist eine verteilte Schlüsselwertdatenbank. Es wurde entwickelt, um ein skalierbares, leistungsstarkes Datenmanagement zu bieten und gleichzeitig eine einfache Schnittstelle beizubehalten. Die Oracle NoSQL-Datenbank baut auf der Oracle Berkeley DB Java Edition auf, die eine hochleistungsfähige, integrierbare Datenbank-Engine bietet. Die Oracle NoSQL-Datenbank ist als herunterladbares Image einer virtuellen Maschine oder als Cloud-Service verfügbar.
In-Memory verwendet eine einzigartige duale Formatarchitektur, die es ermöglicht, Tabellen gleichzeitig im Speicher darzustellen. Da das neue Spaltenformat ein reines In-Memory-Format ist und keinen Festplattenspeicher benötigt, entstehen keine zusätzlichen Speicherkosten oder Speichersynchronisierungsprobleme. Die Kapazität von In- Memory-Datenbanken , Abfragen mit der erstaunlichen Rate von Milliarden von Zeilen pro Sekunde auf einem CPU-Kern zu verarbeiten, ist erstaunlich. Die meisten dieser analytischen Indizes können mit In-Memory eliminiert werden, indem das In-Memory-Spaltenformat verwendet wird, das die abzurufende Datenmenge reduziert und gleichzeitig eine Leistung bietet, die mit einem Index für jede Spalte vergleichbar ist. Das Entfernen analytischer Indizes beschleunigt OLTP-Operationen, da die Indizes nicht mehr von jeder Transaktion gepflegt werden müssen. Nur speicherprivilegierte Tabellen und Partitionen können in den Speicher von Benutzern eingefügt werden.
Das NoSQL-Datenbankverwaltungssystem In-Memory wie MongoDB und Redis speichert alle Daten im Hauptspeicher und aktualisiert sie auf der Festplatte auf unbestimmte Zeit. Um die Persistenz zu gewährleisten, wird jede Änderungsanforderung in einem Binärprotokoll gespeichert. Da das Protokoll nur angehängt werden kann, ist es selten ein Problem, es in Eile zu schreiben.
Ist Oracle Database In-Memory?

Ja, Oracle Database befindet sich im Arbeitsspeicher. Die In-Memory-Spaltenspeicherfunktion von Oracle ermöglicht das Speichern und Zugreifen auf Daten im Arbeitsspeicher und bietet eine erhebliche Leistungssteigerung für analytische Workloads. In Kombination mit der Real Application Clusters (RAC)-Technologie von Oracle kann Oracle Database ein noch höheres Maß an Skalierbarkeit und Verfügbarkeit bieten.
Database In-Memory ist eine Reihe von Funktionen, die Echtzeitanalysen und gemischte Workloads verbessern, indem sie erhebliche Leistungssteigerungen bieten. Der Column Store (IM-Spaltenspeicher) wurde Oracle Database 12c Release 1 (12.1.0.2) als Komponente von Oracle Database 12c Release 1 (12.1.0.2) hinzugefügt. In herkömmlichen relationalen Datenbanken können Daten entweder in Zeilen- oder Spaltenformaten gespeichert werden. Das Auswählen von Spalten in einer spaltenorientierten Datenbank entspricht dem Auswählen von Zeilen in einer Zeilendatenbank. Database In-Memory umfasst einen datenbankinternen Spaltenspeicher, erweiterte Abfrageoptimierungen und Zugriffslösungen. Der IM-Spaltenspeicher speichert Kopien aller Spalten, Tabellen, Partitionen usw. in einem komprimierten Spaltenformat, das für schnelles Scannen ausgelegt ist. Durch die parallele Verarbeitung können Data Warehouses und gemischt genutzte Datenbanken Größenordnungen schneller verarbeiten.
Als Ergebnis der Auffüllung werden zeilenbasierte Daten auf der Festplatte in spaltenweise Daten im IM-Spaltenspeicher umgewandelt. Wenn Sie beispielsweise eine Tabelle oder Ansicht in partitionierte Partitionen aufteilen möchten, können alle oder ein Teil der Partitionen für die Auffüllung konfiguriert werden. In-Memory-Ausdruck (IM-Ausdruck) in DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS ermöglicht die Identifizierung und Auswahl von heißen Ausdrücken. Wenn eine Datenbankinstanz neu gestartet wird, spart die Database In-Memory FastStart (IM FastStart)-Methode Zeit, indem sie die Datenmenge reduziert, die in den IM-Spaltenspeicher gefüllt werden muss. Das Spaltenformat ist aufgrund seines hohen Durchsatzes ideal für das Scannen von Daten. Sie können die Echtzeit-Datenanalyse verwenden, um neue Möglichkeiten und Iterationen zu erkunden. Es ist möglich, Daten in ihrem komprimierten Format zu scannen, ohne sie zuerst in der Oracle-Datenbank zu dekomprimieren.
Ein WHERE-Klauselprädikat wird für komprimierte Daten in der Datenbank verwendet, wenn Spalten mithilfe von Algorithmen komprimiert werden, die eine automatische Komprimierung von Spalten ermöglichen. Bloom-Filter erweitern Joins, indem sie Prädikate für kleine Dimensionstabellen in Filter für große Dimensionen umwandeln. Wenn Daten im IM-Spaltenspeicher gespeichert werden, ist es einfacher, komplexe Abfragen zu organisieren und durchzuführen. Das Erstellen von Zugriffsstrukturen ist ein entscheidender Schritt zur Verbesserung der analytischen Abfrageleistung. Der gebräuchlichste Ansatz besteht darin, analytische Indizes, materialisierte Ansichten und OLAP-Würfel zu erstellen. Eine Zeile muss in eine Tabelle eingefügt werden, was eine Änderung aller Indizes erforderlich macht. Oracle-Datenbanken werden im On-Disk-Speicherformat von Oracle gespeichert, das mit dem Spaltenformat identisch ist.
Es wird vollständig von RMAN, Oracle Data Guard und Oracle ASM unterstützt. Die Verwendung eines benutzerverwalteten Datenmigrationstools ist nicht erforderlich. Wenn Sie Oracle-Analysefunktionen oder einen benutzerdefinierten PL/SQL-Code verwenden, haben Sie Zugriff auf eine breitere Palette von Analyseabfragen. Die einzigen erforderlichen Aufgaben sind die Dimensionierung des IM-Spaltenspeichers und die Angabe von Objektwerten für die Auffüllung. In der folgenden Tabelle finden Sie eine Liste der grundlegendsten Konfigurationsaufgaben des IM Column Store. Sie können den In-Memory Advisor für PL/SQL herunterladen und damit die analytische Verarbeitungslast Ihrer Datenbank analysieren. Die analytische Verarbeitung unterscheidet sich von anderen Datenbankaktivitäten basierend auf der Plankardinalität, der Verwendung paralleler Abfragen und anderen Faktoren.
Der In-Memory Advisor ist nicht in den auf dem System gespeicherten PL/SQL-Paketen enthalten. Sie müssen das Paket zuerst vom Oracle Support beziehen. Die Schätzungen des Beraters deuten auf Verbesserungen der analytischen Verarbeitungsleistung basierend auf den folgenden Faktoren hin. Wartezeiten für Benutzer-I/O, Cluster-Übertragungen und Puffer-Cache-Latch-Ereignisse können eliminiert werden. Je nach Komprimierungstyp fallen Heuristiken für Komprimierungskosten an.
Was ist im Speicher in der Datenbank?
Eine In-Memory-Datenbank ist im Gegensatz zu einer festplattenbasierten oder SSD-basierten Datenbank darauf ausgelegt, Daten hauptsächlich zu Datenspeicherungszwecken im Arbeitsspeicher zu speichern. Im Arbeitsspeicher erstellte Datenspeicher verwenden eine kostengünstige Methode, um den Zugriff auf Festplatten zu eliminieren und die Antwortzeiten zu verkürzen.
Vorteile von In-Memory-Datenbanken
In-Memory-Datenbanken sind in den letzten Jahren immer beliebter geworden, da sie viele Vorteile gegenüber herkömmlichen Datenbanken bieten. Der erste Vorteil von ihnen ist, dass sie alle Arten von Daten im selben System speichern können, was sie ideal für Anwendungen macht, die große Mengen unstrukturierter Daten speichern müssen. Zusätzlich zur Geschwindigkeit und Effizienz von In-Memory-Datenbanken können Benutzer schneller auf Daten zugreifen. Darüber hinaus können In-Memory-Datenbanken von kleinen Unternehmen und Verbrauchern verwendet werden, da sie einfach zu verwenden und zu verwalten sind.
Verfügt Oracle über eine Nosql-Datenbank?
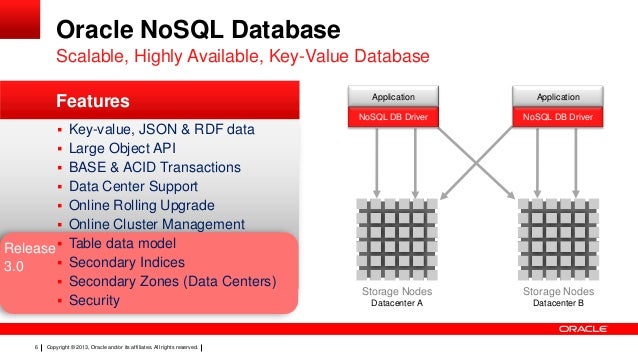
Ja, Oracle hat eine Nosql-Datenbank namens Berkeley DB. Berkeley DB ist eine leistungsstarke, skalierbare Open-Source-Datenbank.
Wo werden Nosql-Daten gespeichert?
Anstatt Daten in einer relationalen Datenbank zu speichern, speichern NoSQL-Datenbanken Daten in Dokumenten. Anders ausgedrückt unterteilen wir sie in SQL und eine Vielzahl flexibler Datenmodelle, um sie zu klassifizieren. Eine NoSQL-Datenbank kann eine reine Dokumentendatenbank, eine Key-Value-Store-Datenbank, eine Wide-Column-Datenbank oder eine Graph-Datenbank sein.
Eine der häufigsten Anwendungen von NoSQL-Datenbanken ist die schnelle Speicherung großer Mengen unabhängiger Daten. NoSQL ist ein Datenbanktyp, der keine relationalen Daten teilt. In den 1970er Jahren gewannen relationale Datenbanken als Standard für die Datenspeicherung an Popularität. Laut Ben Finkel, einem CBT-Trainer, geht es bei NoSQL um Geschwindigkeit und Flexibilität, nicht um Konsistenz und Effizienz. Trotz ihrer Geschwindigkeit und Effizienz sind Datenbanken, die mit relationaler Technologie erstellt wurden, nicht so einfach, wie es scheint. Database NoSQL erfordert kein Design oder Planung der Datenstrukturen. Dadurch können Entwickler Anwendungen viel schneller erstellen, prototypisieren und bereitstellen.
Sie funktionieren ähnlich wie die ebenfalls beliebte agile Softwareentwicklung. NoSQL-Datenbanken können eine Vielzahl von Datentypen speichern, wodurch sie einfach einzurichten sind. NoSQL-Datenbanken erfordern mehr Rechenleistung als relationale Datenbanken. Der Raspberry Pi kann kleine NoSQL-Datenbanken ausführen, aber Webserver werden deutlich anspruchsvoller sein. Diagramme sind im Gegensatz zu Schlüssel:Wert-Paaren oder Dokumenten abstrakt. Knoten und Kanten sind die beiden Komponenten von Graphen. Knoten können Informationen über ein Objekt enthalten (Person, Ort, Sache, Idee usw.). Die Beziehung zwischen einem Knoten und seinen Kanten wird durch Kanten erklärt. Das Wide-Column-Datenmodell ähnelt den Zeilen und Spalten in einer relationalen Datenbank.
Mehrere Faktoren tragen zur zunehmenden Popularität von NoSQL-Datenbanken bei. Herkömmliche relationale Datenbanken sind ineffizient, zeitaufwändig und anfällig für Datenkorruption, während auf Microservices basierende Datenbanken eine bessere Leistung erbringen. Aus gutem Grund ist JSON das bevorzugte Format für NoSQL-Datenbanken. Einfach ausgedrückt sind JSON-Dokumente kompakter und lesbarer als andere Dokumenttypen. JSON ist ein in JavaScript erstelltes Datendarstellungsformat.
JSON ist besser lesbar und kompakter als das Standard-Textformat.
NoSQL-Datenbanken sind in Bezug auf Geschwindigkeit und Leistung effizienter als herkömmliche relationale Datenbanken.
Sie erleichtern die Verwendung.
Sie sind widerstandsfähiger gegen Datenkorruption als andere Tiere.

Die verschiedenen Arten von Nosql-Datenbanken
NoSQL-Datenbanken wie MongoDB sind aufgrund ihrer Einfachheit beim Speichern von Daten beliebt, die viel einfacher zu verstehen ist als die Arten von Datenmodellen, die in SQL-Datenbanken verwendet werden. Entwickler haben häufig direkten Zugriff auf die Struktur einer NoSQL-Datenbank.
Eine NoSQL-Datenbank ist eine nicht tabellarische Datenbank, die Daten auf andere Weise speichert als eine relationale Datenbank (auch bekannt als SQL). Die verschiedenen Arten von NoSQL-Datenbanken basieren auf ihren Datenmodellen. Die wichtigsten Arten von Dokumenten sind Grafiken, Diagramme und Key-Value-Statements.
Wie installiere ich Nosql, um Daten in strukturierter Form zu speichern?
Daten können in einer NoSQL-Datenbank strukturiert, halbstrukturiert oder unstrukturiert sein, sodass über eine Reihe von Mechanismen darauf zugegriffen werden kann. Der Hauptvorteil ihrer Software besteht darin, dass sie halbstrukturiert ist (JSON, XML, aber nicht alle Felder sind bekannt), was zu unstrukturierten Daten führt.
Wie können Daten in einer nicht relationalen Datenbank gespeichert werden?
Da eine nicht relationale Datenbank nicht das tabellarische Schema der meisten herkömmlichen Datenbanken verwendet, gibt es keine Zeilen oder Spalten. Nicht relationale Datenbanken hingegen verwenden ein Speichermodell, das für die Art der zu speichernden Daten optimiert ist.
Was ist die Oracle Nosql-Datenbank?
Eine Oracle NoSQL-Datenbank ist ein skalierbarer, verteilter Schlüsselwertspeicher, der für hohe Leistung, horizontale Skalierbarkeit und einfache Verfügbarkeit ausgelegt ist. Oracle NoSQL Database ist eine NoSQL-kompatible Datenbank, die Schlüssel-Wert-Paar-Datenspeicherung bereitstellt. Oracle NoSQL Database wird auf einem Cluster von Commodity-Servern ausgeführt und bietet eine einfache Java-API für den Zugriff auf die Datenbank.
Das Oracle NoSQL SDK für Spring Data enthält ein Spring Data-Implementierungsmodul. Diese Funktion kann verwendet werden, um eine Verbindung zu einem Oracle NoQL Database-Cluster oder dem Oracle NoQL Cloud Service herzustellen. Fügen Sie dem XML Ihres Projekts eine Maven-Abhängigkeit für die Verwendung mit dem SDK hinzu. Um Zugriff auf diese Informationen zu haben, muss man Folgendes verwenden. Nosql.spring ist ein Client von Oracle. Verwenden einer NosqlDbConfig-Methode zum Konfigurieren einer Datenbank. Definieren Sie eine Entitätsklasse wie folgt.
Es wird empfohlen, ein Repository für die Nosql-Erweiterung zu erstellen. Die Anwendungsklasse sollte geschrieben werden. Indem Sie Abhängigkeitsdateien zu org.springframework.boot:spring-boot hinzufügen, können Sie mit dem Spring Framework loslegen.
Oracle In-Memory-Beispiel
Ein Oracle-In-Memory-Beispiel wäre ein Unternehmen, das eine Oracle-Datenbank verwendet, um seine Daten im Speicher zu speichern und zu verarbeiten. Dies würde eine schnellere Datenverarbeitung und einen schnelleren Abruf ermöglichen sowie den Bedarf an Plattenspeicher verringern.
Ohne Änderungen an der Codebasis haben sich Abfragetypen wie Gruppieren nach Operationen (analytische Abfragen) um das 4- bis 27-fache verbessert. Eine Online-Analytics-Abfrage, die 11 Sekunden benötigte, dauerte mit OIM 399 Millisekunden. Es ist eine gute Idee, die am häufigsten abgefragten Partitionen für große partitionierte Tabellen im Speicher zu behalten. Wenn eine Tabelle sehr breite Spalten hat, empfiehlt es sich, selten abgefragte Spalten auszuschließen. Da nicht jede Spalte eine In-Memory-Komponente einer Abfrage ist, setzt Oracle den Puffer-Cache auf 0. Das Komprimierungsverhältnis wird erhöht, sodass weniger Verarbeitung erforderlich ist, um es zu verarbeiten, wodurch Platz gespart wird. Je spezifischer die Abfrage, desto größer der Geschwindigkeitsschub durch OIM. Eine Abfrage, die 75 Zeilen aus einer 20-M-Zeilentabelle mit Oracle In-Memory zurückgab, dauerte 69-mal so lange wie mit Standard-DBMS . Infolgedessen kann es bis zu 67-mal schnellere Leistungssteigerungen liefern (bei hochselektiven Abfragen).
Warum der Pl/sql-Bereich mehr Speicher verdient
Für PL/SQL und die zugehörigen Objekte werden sowohl PL/SQL-Prozeduren als auch globale Objekte im PL/SQL-Bereichsspeicher gespeichert. Alle diese Objekte haben benutzerdefinierte Funktionen, sind mit einem PL/SQL-Paket verknüpft und haben Objektberechtigungen. Auch die parallele Ausführung von Oracle Database über den PL/SQL-Area-Speicher ist möglich.
Die allgemeine Empfehlung von Oracle lautet, 95 % des Gesamtspeichers dem SGA- und 5 % dem PL/SQL-Bereich zuzuweisen.
Oracle Nosql gegen Cassandra
Es gibt einige wichtige Unterschiede zwischen Oracle NoSQL und Cassandra. Zum einen ist Cassandra ein Open-Source-Projekt, während Oracle NoSQL ein proprietäres System ist. Cassandra ist ebenfalls eine spaltenorientierte Datenbank, während Oracle NoSQL eine zeilenorientierte Datenbank ist. Schließlich konzentriert sich Cassandra auf Hochverfügbarkeit und horizontale Skalierbarkeit, während Oracle NoSQL sich auf Benutzerfreundlichkeit und die Verwaltung hierarchischer Daten konzentriert.
Apache Cassandra ist eine NoSQL-Datenbank, die sich gut für hohe Leistung, lineare Skalierbarkeit, einstellbare Konsistenz und Workloads mit geringer Latenz über verschiedene Workloads hinweg eignet. In den meisten Fällen ist Apache Cassandra nicht die beste Wahl für Ihren Anwendungsfall, da es an konsistenter Semantik zwischen Ihrer relationalen Datenbank und NoSQL-Datenbanken mit ACID-Transaktionen mangelt. Wenn Sie eine reduzierte Datenredundanz und ACID-Konformität benötigen, sollten Sie die Verwendung von SQL-Datenbanken anstelle von Oracle in Erwägung ziehen. HBase wird normalerweise nicht von Web- oder Mobilentwicklern verwendet, da es für die Arbeit mit kalten oder historischen Data Lake-Anwendungsfällen konzipiert ist. Andererseits ist eine Cassandra-Anwendung leichter verfügbar und in der Lage, sehr anspruchsvolle Umgebungen zu handhaben.
Was ist der Unterschied zwischen Kassandra und Orakel?
Das Oracle Database Management System (ODMS) ist ein relationales Datenbankmanagementsystem (RDBMS), das in zwei Formaten verfügbar ist: S.NO.ORACLE CASSANDRA1. Es wurde 1980 von der Oracle Corporation entwickelt und 2008 von der Apache Software Foundation erstellt; 2. Es wurde geschrieben, dass auf die Open-Source-Software zugegriffen werden kann, indem sieben Zeilen mehr ausgeführt werden.
Ist Oracle eine Nosql-Datenbank?
Der Oracle NoSQL Database Cloud Service macht es Entwicklern einfach, Anwendungen mit Dokument-, Spalten- und Schlüsselwert-Datenbankmodellen zu erstellen, indem vorhersehbare Reaktionszeiten in Millisekunden, Datenreplikation für Hochverfügbarkeit und dokumentbasierte Anwendungen bereitgestellt werden.
Ist Cassandra und Nosql gleich?
Cassandra ist ein kostenloses und quelloffenes, verteiltes Datenbankverwaltungssystem mit breitem Spaltenspeicher , das auf dem quelloffenen Cassandra-Projekt basiert.
Verwendet Netflix Cassandra?
Cassandra auf Amazon Web Services dient als wichtige Infrastrukturkomponente des globalen Streaming-Dienstes von Netflix.
Oracle Nosql-Datenbank vs. Mongodb
Es gibt viele Unterschiede zwischen Oracle NoSQL Database und MongoDB. Erstens ist MongoDB eine dokumentenorientierte Datenbank, während Oracle NoSQL Database ein Schlüsselwertspeicher ist. Das bedeutet, dass MongoDB Daten in JSON-ähnlichen Dokumenten speichert, während Oracle NoSQL Database Daten in Schlüssel-Wert-Paaren speichert. Zweitens unterstützt MongoDB sekundäre Indizes, während Oracle NoSQL Database dies nicht tut. Drittens hat MongoDB eine reichhaltigere Abfragesprache als Oracle NoSQL Database. Viertens unterstützt MongoDB Auto-Sharding, während Oracle NoSQL Database dies nicht tut. Schließlich ist MongoDB Open Source, Oracle NoSQL Database hingegen nicht.
MongoDB ist einfach einzurichten und bietet eine unglaubliche Flexibilität in Bezug auf Designflexibilität. Wenn Ihre Datenformate nicht konsistent sind, ist eine NoSQL-Datenbank wie Oracle NoSQL Database eine gute Wahl. Wenn Sie weniger Datenredundanz und ACID-Konformität benötigen, ist die Verwendung einer SQL-Datenbank möglicherweise die beste Option für Sie. Da NoSQL-Datenbanken wie MongoDB keine grafischen Schnittstellen haben, sind sie normalerweise nicht für die Verwendung in Verbindung mit herkömmlichen Datenbanken vorgesehen. Um die Benutzerfreundlichkeit zu verbessern, sollten Sie Anwendungen von Drittanbietern installieren, mit denen Sie die Schemas und gespeicherten Dokumente visuell anzeigen können. Wenn Sie als DBA oder Systemadministrator nicht wissen, wie man MongoDB verwendet, ist es eine gute Idee, sich an einen Drittanbieter für MongoDB-Hosting zu wenden.
Hauptunterschiede zwischen Mongodb und Oracle
Es gibt mehrere wesentliche Unterschiede zwischen MongoDB und Oracle, die bei der Kaufentscheidung für eine Software berücksichtigt werden sollten. Die MongoDB-Plattform ist bekannt für ihre Fähigkeit, große Datenmengen zu verarbeiten, während Oracle häufiger zum Erstellen von Unternehmensanwendungen verwendet wird. Darüber hinaus enthält MongoDB erweiterte Funktionen zum Durchsuchen beliebiger Felder oder Abfragebereiche, während die Möglichkeiten von Oracle weniger eingeschränkt sind. Oracle skaliert vertikal, weil es auf Sharding basiert, während MongoDB horizontal skaliert, weil es auf Sharding basiert. Darüber hinaus basiert MongoDB auf einer verteilten Systemarchitektur und nicht auf einem monolithischen Design mit einem einzelnen Knoten, wodurch es sich in Bezug auf die Architektur von Oracle unterscheidet.