
Die Macht von Big Data: Wie NoSQL-Datenbanken die Art und Weise verändern, wie wir Daten speichern und verarbeiten
Veröffentlicht: 2022-11-22Das 21. Jahrhundert wird aus gutem Grund das „Informationszeitalter“ genannt. Daten werden immer mehr zum wertvollsten Gut der Welt. Der Begriff „Big Data“ bezieht sich auf Datensätze, die so groß und komplex sind, dass sie mit herkömmlichen Methoden nur schwer zu verarbeiten sind. Der Bedarf an Big-Data-Lösungen wurde in den frühen 2000er Jahren deutlich, als Internetunternehmen begannen, große Datenmengen von ihren Benutzern zu generieren. Diese Unternehmen mussten Wege finden, diese Daten schnell und effizient zu speichern und zu verarbeiten. Eine Lösung, die entwickelt wurde, hieß „NoSQL“, was für „nicht nur SQL“ steht. Diese Art von Datenbank ist skalierbar und flexibel und eignet sich daher ideal für Big-Data-Anwendungen . NoSQL-Datenbanken werden jetzt von einigen der größten Unternehmen der Welt verwendet, darunter Facebook, Google und Amazon. Sie haben sich als unschätzbar für den schnellen und effizienten Umgang mit großen Datenmengen erwiesen.
Big Data sind Daten, die mit keinem Software-Datenbanktool schwer zu speichern und zu analysieren sind. Eine NoSQL-Lösung ist eine Lösung, die große Datenmengen verarbeiten kann; Wir werden uns unten genauer ansehen, was sie sind. Es wird empfohlen, NoSQL-Datenbanken in großen Datenprojekten zu verwenden. Im Folgenden finden Sie einige Möglichkeiten zum Umgang mit Big-Data-Problemen . Anstatt Daten von einer Abfrage in eine andere zu verschieben, sollte die Abfrage in Daten verschoben werden. Die Verwendung von Hash-Ringen bei der Datenverteilung wird empfohlen. Während der Echtzeit wird die Datenreplikation von Datenbanken verwendet, um Backups zu erstellen. Um Leseanforderungen horizontal zu skalieren, ist die Replikation eine gute Option. Die Frageauswertung und -ausführung müssen getrennt werden, um verstanden zu werden.
Eine NoSQL-Datenbank hat keine Verknüpfungen oder Beziehungen, während ein RDBMS dies tut. Eine NoSQL-Datenbank hat deutlich geringere Wartungskosten als eine RDBMS-Datenbank. Der Bedarf an NoSQL für Programmierer und Datenbankdesigner ist größer als der von RDBMS, aber RDBMS verbraucht weniger Speicherplatz. NoSQL ist eine Art NoSQL-Datenbank, während RDBMS eine Art RDBMS-Datenbank ist.
Carlo Strozzi verwendete den Begriff NoSQL im Jahr 1998, um eine leichtgewichtige relationale Open-Source-Datenbank zu beschreiben, die nicht die standardmäßige SQL-Schnittstelle (Structured Query Language) offenlegte, sondern relational blieb. Sein NoSQL-RDBMS unterscheidet sich vom allgemeinen NoSQL-Datenbankkonzept, das um die Wende zum 21. Jahrhundert entwickelt wurde.
Die Verwendung von NoSQL-Datenbanken basiert auf dem Wunsch, die Frustration mit SQL zu überwinden, die immer von einer Reihe von Innovationen in der Datenbanktechnologie gefolgt wird, die von der Industrie und der Wissenschaft unterstützt werden . Die Entwicklung von NoSQL begann in der Branche als Reaktion auf die Bedürfnisse erfolgreicher Webscale-Anwendungspioniere und die für Suche und Werbung erforderliche Infrastruktur.
Da alle Daten in einem Hub/Knoten in Dokumentform gespeichert werden, können die Abfrage und das Ergebnis über das Netzwerk verschoben werden, ohne die Abfrage zu beeinflussen.
Wie hängt Big Data mit Nosql zusammen?
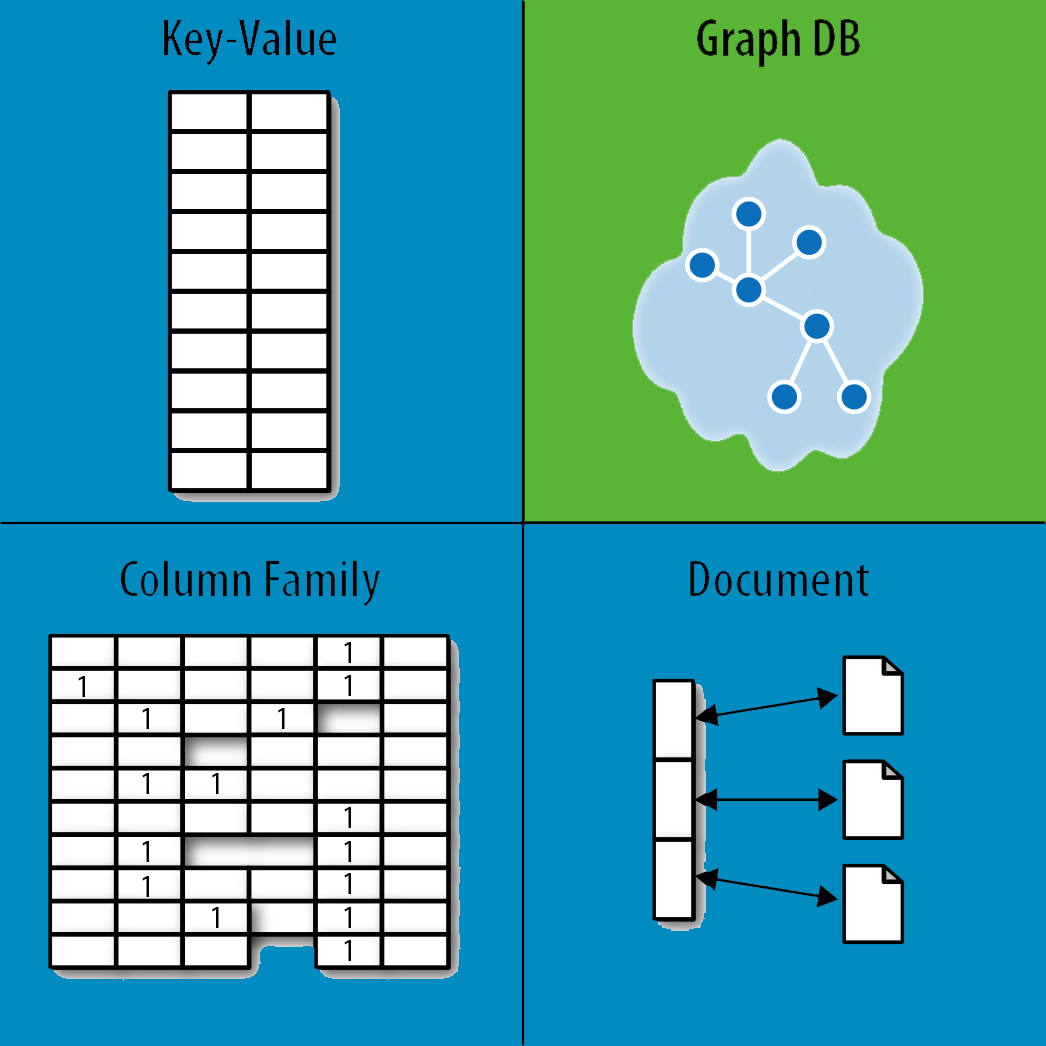
Diejenigen Unternehmen, die mit einer großen Menge unterschiedlicher und unstrukturierter Daten wie Big Data umgehen, verwenden NoSQL tendenziell häufiger als andere. Eine NoSQL-Datenbank verlässt sich nicht wie eine relationale Datenbank auf das feste Schemamodell.
NoSQL-Datenbanken wie MongoDB, Apache Cassandra und HBase sind erheblich schneller gewachsen als ihre RDBMS-Pendants . Wenn Sie Datenworkloads ausführen, die die schnelle Verarbeitung und Analyse großer Mengen unterschiedlicher und unstrukturierter Daten erfordern, ist NoSQL die bessere Option. Eine Datenbank ohne Relativität ist gegenüber herkömmlichen RDBMS-Produkten in vielerlei Hinsicht vorteilhaft, einschließlich hoher Leistung, Skalierbarkeit und Verfügbarkeit. Die NoSQL-Datenbank wird für Unternehmen nützlicher sein, die große Mengen strukturierter, halbstrukturierter und unstrukturierter Daten speichern und analysieren möchten, insbesondere in Echtzeit. Um mit dem Datenwachstum Schritt zu halten, müssen dem Cluster weitere physische Server hinzugefügt werden. Die Architektur von NoSQL-Datenbanken ermöglicht eine horizontale Skalierung. Aufgrund seiner Open-Source-Natur ist NoSQL weitaus kostengünstiger als herkömmliche Datenbanken. Darüber hinaus können Sie durch die Kombination der Stärken von NoSQL und RDBMS eine höhere Effizienz erreichen.
NoSQL-Datenbanken können riesige Datenmengen speichern und verwalten. Da sie über ein flexibles Schema und eine hohe Leistung verfügen, sind sie ideal für Echtzeit-Webanwendungen und Big Data.
Ist Mongodb Big Data?
Letztendlich sind sowohl Hadoop als auch MongoDB eine gute Wahl für die Verwaltung großer Datenmengen. Obwohl sie viele Ähnlichkeiten aufweisen (z. B. Open Source, NoSQL, schemafrei und Map-Reduce), haben sie unterschiedliche Ansätze zur Datenverarbeitung und -speicherung.
Was führte zur Entwicklung der Nosql-Datenbank?
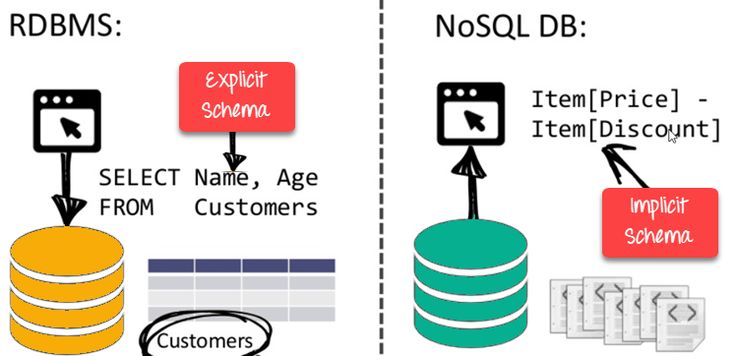
Carlo Strozzi verwendete den Begriff NoSQL erstmals 1998, als er eine „relationale“ Open-Source-Datenbank beschrieb, die kein SQL benötigte. Es kam 2009 wieder ans Licht, als Eric Evans und Johan Oskarsson damit nicht relationale Datenbanken beschrieben.
Das Konzept, Daten in Zeilen und Spalten mit einem bestimmten Schlüssel zu speichern, der die Beziehung zwischen ihnen angibt, geht auf das Jahr 1970 zurück, als Edgar F. Codd es erstmals vorstellte. Aufgrund ihrer strukturierten Natur waren Daten bis vor kurzem immer perfekt auf eine relationale Datenbank abgestimmt. Der Boom der unstrukturierten Daten begann als Folge des zunehmenden Internetzugangs. Der wachsende Bedarf zum Erstellen, Lesen, Aktualisieren und Löschen von Daten (CRUD) macht die Verwendung und Wartung relationaler Datenbanken schwieriger und teurer. In einigen Fällen ist es nicht möglich, Beziehungen zwischen Daten aufrechtzuerhalten, da dies zu einer so großen Aufgabe geworden ist. Viele talentierte Personen in der Technologie haben Datenbanken erstellt, die keine Schema- oder Datenbeziehungen zum Speichern und Abrufen unstrukturierter Daten erfordern. Große und unstrukturierte Datensätze werden in NoSQL-Datenbanken geschrieben, da diese immer beliebter werden. Viele große Unternehmen, darunter Twitter, Facebook und Google, verwenden NoSQL, um ihre Online-Erfahrung zu verbessern. Da einige Datenbanken jetzt Multi-Modelle sind, können sie Daten in mehreren Formaten speichern.
Die neue Welle von Datenbanken: Nosql
In der zweiten Welle der Datenbankentwicklung werden NoSQL-Datenbanken eingeführt. Das Datenwachstum ist ein großes Problem in diesem Bereich, und diese Datenbank wurde erstellt, um dieses Problem zu lösen.
Warum wird Nosql in Big Data verwendet?
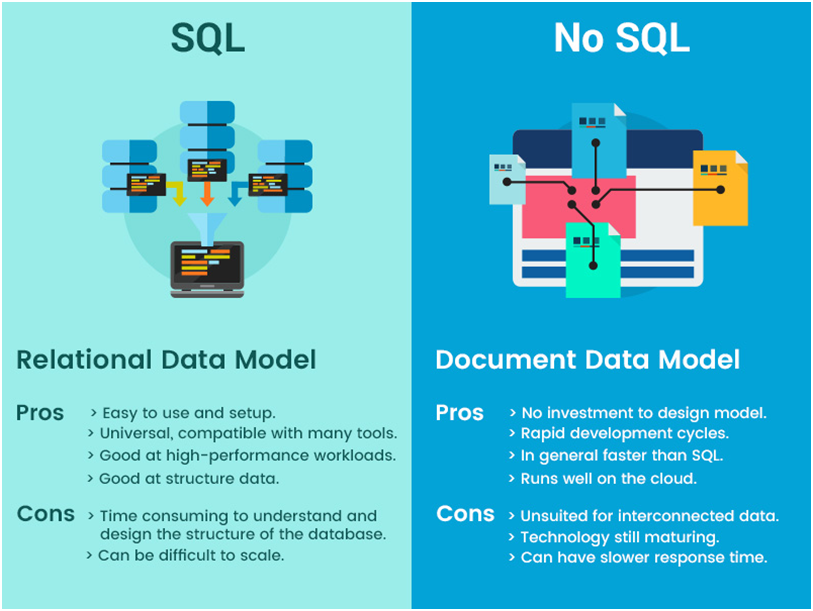
Nosql wird in Big Data verwendet, weil es ein skalierbares, leistungsstarkes Datenbanksystem ist, das große Datenmengen verarbeiten kann. Es ist außerdem so konzipiert, dass es leicht skalierbar ist und hohe Verkehrslasten bewältigen kann.
Als RDBMS an Effektivität verlor, entwickelten Internetunternehmen wie Amazon, Google, LinkedIn und Facebook NoSQL-Datenbanken, um die Nachteile zu überwinden. Mit NoSQL werden die Anforderungen an die Datenverarbeitung reduziert und unstrukturierte Daten werden schnell und einfach verarbeitet. Laut Evardo de Oliveira, Direktor für Geschäftsentwicklung bei FairCom, gibt es einige Probleme mit NoSQL, die mit einer herkömmlichen Datenbank nicht zu lösen sind . Die NoSQL-Datenbanktechnologie wird von den Big-Data-Communities des Webs, Big Data und Big Users verwendet. Eine NoSQL-Datenbank besteht aus zahlreichen Datenbanken, die alle eine unterschiedliche Art der Datenspeicherung haben. Die häufigsten Typen sind Diagramme, Schlüssel-Wert-Paare, Spalten und Dokumente. Weborientierte Unternehmen wie Amazon, eBay usw. benötigten eine Datenbank wie NoSQL vs. SQL, die am besten zu dem sich ändernden Datenmodell passt, um flexibler in ihren Abläufen zu werden.
Datenbank NoSQL -Datenbanken können im Gegensatz zu relationalen Datenbanken Daten auch in Echtzeit speichern und verarbeiten. Die Landschaft der Datenbanken ist im Laufe der Jahre gewachsen, und es gibt jetzt mehr Datentypen, mehr Datensätze und mehr Datenvolumen, und nur NoSQL-Datenbanken wie HBase, Cassandra und Couchbase können diese Herausforderungen bewältigen. Eine NoSQL-Datenbank betrachtet die Konsistenz der Verfügbarkeitspartitionstoleranz als Teil des CAP-Prioritätsprozesses.
Ist Sql oder Nosql besser für Big Data?
SQL wird dadurch zu einem wichtigen Aspekt von NoSQL, da es vollständig auf unterschiedlichen Datenmodellen basiert. Verschachtelte Tabellen werden in einer relationalen Datenbank durch Zeilen und Spalten dargestellt. Jede Tabelle in diesen Tabellen ist durch einen Fremdschlüssel verknüpft.
Nosql-Datenbanken werden für die Speicherung von Big Data immer beliebter
NoSQL kann verwendet werden, um eine große Datenmenge zu speichern. Diese Art von Datenbank wird aufgrund ihrer Beliebtheit bei Webunternehmen immer beliebter. Befürworter von NoSQL-Lösungen behaupten, dass ihre Technologien schneller skalieren können als herkömmliche relationale Datenbanken und gleichzeitig eine höhere Leistung bieten. MongoDB ist eine Dokumentendatenbank, die gut funktioniert, einfach zu bedienen ist und eine hohe Verfügbarkeit bietet. Aufgrund seiner Fähigkeit, große Datenmengen zu verarbeiten, wird es bei Webunternehmen immer beliebter.
Was bedeutet Nosql in Big Data?
NoSQL-Datenbanken (auch bekannt als SQL) haben keine Zeilenstruktur und speichern Daten anders als relationale Datenbanken. Eine NoSQL-Datenbank kann basierend auf ihrem Datenmodell eine Vielzahl von Typen haben. Dokumenttypen, Schlüsselwerttypen, Breitspaltentypen und Diagrammtypen sind die häufigsten.
Warum Nosql für die Datenverarbeitung wichtig ist
NoSQL ist aus folgenden Gründen eine wichtige Technologie: Es ermöglicht Benutzern, die Daten abzufragen und sie zu untersuchen, wenn sie sich ändern. Dadurch ist es möglich, große Datenmengen mit hoher Geschwindigkeit agil zu verarbeiten. NoSQL kann verwendet werden, um unstrukturierte Daten über mehrere Verarbeitungsknoten sowie über mehrere Server hinweg zu speichern. Aus diesem Grund können Daten in einer Vielzahl von Formaten gespeichert werden, die nicht unbedingt im strukturierten Format vorliegen müssen. Es ist wichtig zu beachten, dass diese Funktion es ermöglicht, Daten an anderen Orten als einem zentralen Server zu speichern.
Welche Datenbank verwendet Big Data?
Amazon Redshift, Azure Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 und andere Big-Data-Datenbanken sind nur einige Beispiele.

SQL Server: Der beste Weg, Big Data zu speichern und zu analysieren
Big-Data-Cluster können verwendet werden, um große Datenmengen mit SQL Server zu analysieren und zu speichern. Darüber hinaus können sie Sie dabei unterstützen, Ihre relationalen Daten mit Big Data zu kombinieren, um aufschlussreichere Datensätze zu erstellen. Big Data wird häufig verwendet, um den Betrieb von Unternehmen zu verbessern, einen besseren Kundenservice zu bieten und personalisierte Marketingkampagnen zu erstellen.
Verwendet Hadoop Nosql?
Hadoop ist ein Software-Ökosystem, das im Gegensatz zu Datenbanken, die hauptsächlich für die Datenbankverwaltung verwendet werden, massives paralleles Computing ermöglicht. Beispielsweise kann es verwendet werden, um bestimmte Arten von verteilten NoSQL-Datenbanken (z. B. HBase) zu aktivieren, wodurch Daten über Tausende von Servern verteilt werden können und die Leistung kaum beeinträchtigt wird.
Die Vorteile von Nosql für Big Data Analytics
Eine große Anzahl von Datenquellen befindet sich in HBase, einer spaltenorientierten Datenbank. Cassandra ist eine verteilte Datenbank, die in einem flexiblen Schema strukturiert ist.
Beide Datenbanken eignen sich hervorragend für Big-Data-Analysen.
Aufgrund ihrer Größe ist es nicht möglich, die standardmäßige Hive-Tabelle zu verwenden. Das Ziel von Pig ist es, die Daten in überschaubare Chunks zu zerlegen und sie so in der HBase-Tabelle zu speichern.
Cassandra ist ideal für halbstrukturierte Daten. Mit Cassandra können Sie Daten in Schlüssel-Wert-Paaren speichern. Auf diese Weise können Sie anhand der Daten gezielt suchen.
Eine NoSQL-Datenbank ist eine großartige Option für Big-Data-Analysen. Sie können Daten auf andere Weise als herkömmliche Datenbanken speichern, wodurch sie einfacher zu verwalten sind.
Was ist Nosql? Wie passt es in das Bild von Big Data Analytics?
Nosql ist eine Art Datenbank, die zum Speichern von Daten auf nicht relationale Weise verwendet wird. Das bedeutet, dass Daten nicht in Tabellen gespeichert werden, sondern in einem flexibleren Format, auf das leicht zugegriffen und aktualisiert werden kann. Nosql-Datenbanken werden häufig für Big-Data-Anwendungen verwendet, da sie große Datenmengen effizienter verarbeiten können als herkömmliche relationale Datenbanken.
Websites werden schneller und effizienter ausgeführt, wenn sie auf Cloud-basierten In-Memory-NoSQL-Lösungen gehostet werden. Einige dieser Produkte zeichnen sich durch die Speicherung unstrukturierter Daten aus, und Open-Source-Produkte wie Cassandra, MongoDB und Redis fallen ebenfalls in diese Kategorie. Befürworter von Datenbanken argumentieren, dass sie eine höhere Leistung und Skalierbarkeit bieten als herkömmliche Datenbanken. Einige dieser wichtigen Erkenntnisse sowie der einzigartige Komprimierungsansatz von Garantia Data machen es zu einem, den man im Auge behalten sollte. Diese ultraschnellen Datenbanken können dank der Technologie, die alle mit ihrer Verwaltung verbundenen Betriebsaspekte automatisiert, absolut einfach verwaltet werden.
Die Vorteile von Nosql-Datenbanken
Daher sind NoSQL-Datenbanken eine ausgezeichnete Wahl für die Speicherung von Big Data, da sie eine Vielzahl einzigartiger Funktionen enthalten. Da sie leistungsfähiger sind als andere Arten der Datenspeicherung, können sie sehr gut mit großen Datenmengen umgehen. Darüber hinaus sind NoSQL-Datenbanken einfacher zu verwenden als herkömmliche Datenbanken, wodurch sie einfacher zu skalieren und zu verwalten sind.
Warum ist Nosql besser für Big Data?
Nosql-Datenbanken sind aufgrund ihrer horizontalen Skalierbarkeit für den Umgang mit Big Data weitaus besser gerüstet. Das bedeutet, dass sie ihrem System problemlos weitere Knoten hinzufügen können, um ihre Speicher- und Verarbeitungsleistung zu erhöhen, ohne ihr gesamtes System neu gestalten zu müssen. Dies steht im Gegensatz zu relationalen Datenbanken, die vertikal skalierbar sind, was bedeutet, dass sie nur durch Hinzufügen leistungsfähigerer Server skaliert werden können, was sowohl teurer als auch weniger effizient ist.
Die Nutzung von Big Data und Analytics hat das Potenzial, Fertigungsprozesse erheblich zu optimieren. Der Begriff „Big Data“ bezieht sich auf Informationen, die unstrukturiert oder in ihrer großen Vielfalt und Komplexität strukturiert sind. Sensoren liefern eine Fülle von Informationen über die Bewegungen von Versandlastwagen, Kameras in Fabriken und Verbrauchergeräten in der Fertigung. In der Fertigung wären NoSQL-Architekturen vorzuziehen, da die meisten Daten unstrukturiert sind und sie nicht auf starren Architekturen wie SQL ausgeführt werden können. NoSQL-Datenbanken benötigen keine Schemas, wodurch Daten in einer Vielzahl von Strukturen in einer einzigen Datenbanktabelle gespeichert werden können. Die Trennungslinie wird durch die Art der Daten bestimmt, die beide Unternehmen verwenden werden. Eine Transaktion in einer relationalen Datenbank muss vier grundlegende Funktionsprinzipien erfüllen.
Die Integration von NoSQL-Systemen mit Cloud-Systemen macht sie zu einer idealen Lösung bei der Arbeit mit Cloud-Computing-Frameworks. Durch die Integration von NoSQL mit Manufacturing Execution Systems (MES) ist es möglich, den Fertigungsprozess in Echtzeit zu optimieren. Als Ergebnis dieser Methode wurden mithilfe von Big-Data-Analysen schnellere Reaktionen auf sich ändernde Bedingungen generiert. NoSQL-Datenbanken erleichtern die Skalierung und können für die Datenanalyse verwendet werden. Ein Vorteil schneller reagierender Datenbankarchitekturen wie NoSQL besteht darin, dass das Management bessere Simulationen durchführen und die Entscheidung zur Herstellung eines bestimmten Produkts beeinflussen kann. Blustery-Force-Angriffe, Cross-Site-Angriffe und Injection-Angriffe sind einige der häufigsten Sicherheitslücken in NoSQL-Datenbanken . Wenn ein Benutzer Daten zu NoSQL-Abfragebefehlen oder Speicheranweisungen hinzufügt, wird ein Injektionsangriff gestartet.
Bedenken hinsichtlich der Sicherheit der NoSQL-Architektur beschäftigen die Fertigungsindustrie. Wenn ein Angreifer das Produktionssystem erfolgreich angegriffen und einen Denial-of-Service-Angriff oder Injection-Angriff durchgeführt hat, kann er die Spezifikationen ändern. Auf dem hart umkämpften Markt könnte dies den Wettbewerbern helfen.
Warum Nosql die beste Wahl für unstrukturierte Daten ist
Es gibt keinen besseren Datentyp als unstrukturierte Daten, die sich schnell ändern und auf die viele Benutzer zugreifen.
Wie sind Big Data und Nosql-Datenbanken identisch?
Es gibt keine endgültige Antwort auf diese Frage, da sie von einer Reihe von Faktoren abhängt, einschließlich der spezifischen Big Data- und NoSQL-Datenbank, um die es geht, sowie der Art und Weise, wie sie verwendet werden. Im Allgemeinen sind Big Data- und NoSQL-Datenbanken jedoch beide darauf ausgelegt, große Datenmengen zu speichern und zu verwalten, und beide verwenden dazu eine Vielzahl von Methoden.
Es ist ein verteiltes und nicht relationales Datenbanksystem, das große Datenmengen speichern kann. Diese Systeme basieren auf dem Bedarf an Agilität, Leistung und Skalierbarkeit und können von einer Vielzahl von Benutzern verwendet werden. Die NoSQL-Datenbank ist horizontal verteilt und soll Hunderte von Millionen bis Milliarden von Benutzern unterstützen. Cameron Purdy, ein ehemaliger Oracle-Manager und Java-Evangelist, erklärt, warum NoSQL-Datenbanken so gut funktionieren. Im großen Maßstab sind NoSQL-Datenbanken ideal für eine leistungsstarke agile Datenverarbeitung. Es kann unstrukturierte Daten auf mehreren Verarbeitungsknoten sowie auf mehreren Servern speichern. Ist NoSQL besser für die Analyse geeignet als andere Plattformen? Dies wird durch eine Reihe von Faktoren bestimmt, wie z. B. die Art der zu analysierenden Daten, wie viele Daten man hat und wie schnell man sie benötigt. Für halbstrukturierte Daten wie Social Media, Texte oder geografische Daten eignen sich am besten NoSQL-Datenbanken wie mongoDB, aber auch CouchDB.
Wie unterscheidet sich Big Data von Datenbanken?
Herkömmliche Daten sind typischerweise in einem zentralisierten Datenbanksystem strukturiert, während Big Data verteilt ist. Jeder Computer in einem Netzwerk nimmt an Berechnungen teil. Infolgedessen kann Big Data gegenüber herkömmlichen Daten erheblich skaliert werden und die Vorteile einer verbesserten Leistung und Kosteneinsparungen nutzen.
Warum SQL Server Big Data-Cluster eine gute Wahl für Big Data-Anwendungen sind
Die SQL Server Big Data Cluster eignen sich aufgrund ihres hohen Funktionsumfangs gut für große Datenanwendungen . Sie können diese Funktionen verwenden, indem Sie *br auswählen. Sie haben mehr Flexibilität bei der Interaktion mit Big Data, wenn Sie Entscheidungen darüber treffen, wie Sie damit umgehen. Eine Hochgeschwindigkeits-Datenübertragungsrate kann von einem großen Rechenzentrum gehandhabt werden. Das Ergebnis ist ein hocheffizienter Betrieb. Die Verwendung von SQL Server-Tools, die mit anderen SQL Server-Technologien kompatibel sind.
Sind alle Nosql-Datenbanken ähnlich?
SQL-Datenbanken und NoSQL-Datenbanken unterscheiden sich erheblich in den Arten von Daten, die sie enthalten. Sie verwenden ein Datenmodell, das sich von dem traditionellen Zeilen- und Spaltentabellenmodell unterscheidet, das in relationalen Datenbankverwaltungssystemen (RDBMS) zu finden ist. Ebenso unterscheiden sich NoSQL-Datenbanken stark voneinander.
Mongodb ist die perfekte Wahl für die Speicherung und den Abruf von Daten in großem Maßstab.
Da es sowohl bei Lese- als auch bei Schreibvorgängen so schnell ist, ist MongoDB eine fantastische Wahl für das Speichern und Abrufen von Daten in großem Umfang.
MongoDB ist nicht nur sehr flexibel, sondern kann auch zum Erstellen und Verwalten Ihrer eigenen Datenbanken verwendet werden.
Nosql-Datenanalyse
Es ist wahr, dass „NoSQL“ sich auf „Nicht nur SQL“ bezieht. Die Daten werden hier nicht in mehrere Tabellen aufgeteilt, da sich der gesamte Datensatz in einer einzigen Spaltenstruktur befinden kann. Wenn Sie mit einer großen Datenmenge in einer NoSQL-Datenbank arbeiten, müssen Sie sich keine Gedanken über Leistungsprobleme machen.
Warum Nosql-Datenbanken wie Mongodb und Cassandra ideal für Big-Data-Analysen sind
MongoDB ist aufgrund seiner flexiblen Schemaanforderungen aufgrund seiner NoSQL-Natur eine bessere Wahl für den Umgang mit großen Datensätzen. Sie können diese Methode verwenden, um Daten so zu speichern, wie es für Sie am bequemsten ist. Eine MongoDB-Datenbank kann verwendet werden, um Daten flexibel und einfach abzufragen. Dieser Vorteil gegenüber SQL-Datenbanken ermöglicht Benutzern eine anspruchsvollere Datenanalyse.
Cassandra, eine weitere NoSQL-Datenbank, wird häufig in der Big-Data-Analyse verwendet. Diese Art der Arbeit ist für Cassandra gut geeignet, da sie zahlreiche Vorteile hat. Einer der Hauptvorteile ist, dass es hochgradig skalierbar und verfügbar ist. Infolgedessen kann das System eine große Datenmenge verarbeiten und fast sofort analysieren. Darüber hinaus verfügt Cassandra über eine Reihe von Funktionen auf Unternehmensebene, die es zu einer ausgezeichneten Wahl machen. Dieses System hat eine Vielzahl von Vorteilen, einschließlich seiner Fähigkeit, eine große Anzahl von Datenströmen zu handhaben.