
Die Stärke von MarkLogic: Big Data Management und Sicherheit an einem Ort
Veröffentlicht: 2023-01-29MarkLogic ist eine leistungsstarke Nosql-Datenbank, mit der Unternehmen große Datenmengen einfach und schnell speichern, verwalten und durchsuchen können. Es ist hochgradig skalierbar und bietet eine hohe Leistung, wodurch es sich ideal für Big-Data-Anwendungen eignet. MarkLogic verfügt außerdem über integrierte Sicherheitsfunktionen, die Daten vor unbefugtem Zugriff schützen und die Datenintegrität gewährleisten.
Als Reaktion auf die Nachfrage nach einer flexibleren und effizienteren Methode zum Speichern großer Datenmengen wurde eine Bewegung namens NoSQL geboren. Dieser Beitrag soll eine allgemeine Einführung für alle sein, die sich für dieses aufstrebende Gebiet interessieren. Diese Bemühungen wurden unternommen , um bestimmte Beschränkungen abzumildern , die in der RDBMS - Welt bestehen . Joins sind in einigen NoSQL-Optionen nicht möglich, daher müssen Sie mehrere Kopien der Daten aufbewahren. Dies liegt höchstwahrscheinlich an einem Mangel an globalen Indizes und an der Tatsache, dass Daten mithilfe eines Schlüssels, der zum Abrufen verwendet wird, auf Commodity-Servern partitioniert werden. NoSQL-Benutzer erwarten Volltextsuchmaschinen wie Lucene, Solr und Sphinx, aber sie sind nicht die besten. Die Scale-out-Lösung von MarkLogic ist nachweislich horizontal auf handelsüblicher Hardware mit einer Petabyte-Kapazität einsetzbar.
Es ist eine ganz andere Art von Datenbank als andere Datenbanken. MarkLogic wurde nie entwickelt, um ein bestimmtes Problem lösen zu können. Es wurde von Grund auf als Plattform für Anwendungen der Enterprise-Klasse entwickelt, unabhängig von der Größe.
Das Operational Data Warehouse der neuen Generation von MarkLogic ist ein Softwaretool zur Durchführung von Betriebsanalysen.
Navigieren Sie zu http://localhost:8000/appservices/, um die Seite „Anwendungsdienste“ zu finden. Mit dem Datenbankabschnitt in MarkLogic Server können Sie auf alle Datenbanken zugreifen und Datenbanken löschen sowie eine Datenbank erstellen und konfigurieren.
Welche Datenbank verwendet Marklogic?
Die meisten Organisationen benötigen heute eine Datenbank, um ihre Operationen auszuführen. Es wird verwendet, um Transaktions-, Betriebs- und Analyseanwendungen vom Rechenzentrum aus auszuführen und eine Vielzahl von Datenquellen sicher zu verwalten.
Die Plattform von MarkLogic ermöglicht das gleichzeitige Laden, Abfragen, Bearbeiten und Rendern von Inhalten. Sie können schnell nach Inhalten suchen, wenn diese automatisch in XML konvertiert und indiziert werden. Big Publishing verwendete XML-Elementabfragen, XML-Näherungssuche und Volltextsuche, um seine Suchfunktionen zu verbessern. In 4 bis 5 Monaten könnte ein Unternehmen eine Lösung implementieren und mit der Nutzung beginnen. Die Regierung von Quakezone County möchte es den Mitarbeitern, Entwicklern und Einwohnern des Bezirks erleichtern, auf Echtzeitinformationen zuzugreifen, indem sie es ihnen erleichtert, dies zu tun. Sie benötigen eine schnell und einfach zu implementierende IT-Infrastrukturlösung. Mit MarkLogic kann der Landkreis Daten auf vielfältige Weise anzeigen und korrelieren, unter anderem durch Transformation und Anreicherung.
Time Traders Services ersetzte sein Legacy-System durch MarkLogic Server. Die Lösung ist in Bezug auf die Alarmlatenz stark reduziert und liefert gleichzeitig sofortige und relevante Informationen an das Portal und die E-Mail des Kunden. Finanzhändler verschaffen sich einen Vorteil im Büro und auf dem Handelsparkett, indem sie Kunden über neue verfügbare Forschungsergebnisse informieren. MarkLogic wird verwendet, um streng geheime Installationen in der Bundesregierung zu verwalten. Börsen profitieren von geringeren Kosten für das Hardwaresystem, wenn MarkLogic handelsübliche Hardware optimiert. Bei hoher Leistung gibt es weniger Hardware-Server, mit denen Sie sich auseinandersetzen müssen. Anstatt größere, teurere Server zu kaufen, ermöglicht eine verbesserte Skalierbarkeit die Installation von mehr handelsüblichen Servern.
Einer der Hauptvorteile von MarkLogic Data Hub ist seine Fähigkeit zur Integration mit anderen Datenquellen. Die Software kann problemlos mit Legacy-Systemen wie ERP und CRM sowie neueren Quellen wie Kunden-Data-Warehouses und Streaming-Datenquellen verbunden werden. Darüber hinaus ist MarkLogic Data Hub in der Lage, eine Vielzahl von Datenformaten zu verarbeiten, was die Datenaufnahme vereinfacht. Schließlich ist MarkLogic Data Hub extrem benutzerfreundlich. Es ist ein kostenloses Programm, Sie müssen also nichts bezahlen, um es zu nutzen. Darüber hinaus ist das Programm Open Source, sodass Sie es an Ihre spezifischen Anforderungen anpassen können.
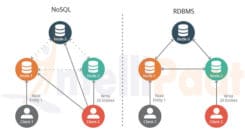
Datenbanken mit mehreren Modellen: Das Beste aus beiden Welten
In der folgenden Tabelle sind die gängigsten Datenbanktypen für Datenbanken mit mehreren Modellen aufgeführt. Eine Datenbank mit mehreren Modellen ermöglicht es Ihnen, Datenmodelle auszuwählen, deren Wartung kostengünstiger ist. MarkLogics Indexierung im Suchstil und die Transaktionsdatenspeicherung ermöglichen es dem Unternehmen, die Daten in seinen Systemen zu kombinieren und anzureichern. Dadurch kann es zum Ausführen von ETL-Prozessen verwendet werden. Da MarkLogic eine Graphdatenbank ist, ist es außerdem eine ausgezeichnete Triple-Stack-Option für diejenigen, die nach einer Graphdatenbank suchen.
Ist LDAP ein Nosql?
Da jede NoSQL-Datenbank über ein eigenes Protokoll verfügt, bindet Sie die Auswahl eines Protokolls im Wesentlichen an diesen einen Datenbanktyp. Wenn Sie den Server ändern müssen, müssen Sie auch die Clients ändern.
Als es von Pearson Education verwendet wurde, wurde NoSql zum Hosten von Online-Kursen, Schülerakten usw. verwendet. In diesem Fall musste jeder im Team mit Mongo schnell loslegen. Den Ldap-Dienst, der von Hunderttausenden von Servern und Desktops auf der ganzen Welt verwendet wird, vergisst man leicht. Mit dem 389-ds-Konsolentool können Sie problemlos neue Objekte und Attribute erstellen. In Bezug auf Cloud Computing würde ich zwei Master-Festplatten in jeder Zone platzieren, um die WAN-Replikation (Multimaster) sicherzustellen. Sie können die Replikationsebenen feinabstimmen. Um das Schema zu ändern, können Sie dies online tun.
Was ist ein Beispiel für ein Nosql?
Die meisten Branchen, in denen NoSQL-Datenbanken verwendet werden, sind für eine Vielzahl von Zwecken auf sie angewiesen. Der Typ der in einem bestimmten Fall verwendeten NoSQL-Datenbank wirkt sich auf deren Betrieb aus. Dokumentendatenbanken wie MongoDB sind Beispiele für Universaldatenbanken . Große Datenmengen können in Schlüssel-Wert-Datenbanken gespeichert werden, wodurch Suchabfragen einfach werden.
Die Vorteile von Nosql-Datenbanken
Im Gegensatz zu herkömmlichen relationalen Datenbanken unterscheiden sich NoSQL-Datenbanken dadurch, dass sie sich vom traditionellen Datenorganisationsmodell zugunsten einer flexibleren Struktur lösen, die viel dynamischere und umfangreichere Datenspeicher ermöglicht. Dies ist ein Vorteil, wenn es darum geht, einen Datenspeicher für mehr Datenverkehr zu skalieren oder wenn Sie auf unterschiedliche Benutzeranforderungen eingehen müssen. Aufgrund der einzigartigen Vorteile, die NoSQL-Datenbanken bieten, werden sie immer beliebter, und nicht jede Anwendung wird davon profitieren. Wenn Sie nach einem flexibleren Datenspeicher suchen, der ein breiteres Spektrum an Anforderungen bewältigen kann, sind NoSQL-Datenbanken eine ausgezeichnete Wahl.
Verwendet Uber Sql oder Nosql?
Wenn eine Datenbank ohne Algorithmen zum Speichern von Daten verwendet wird, wird sie als NoSQL-Datenbank bezeichnet. Da NoSQL-Datenbanken keine Indexunterstützung bieten (aufgrund des Mangels an verteilten Transaktionen), verwendet das Fulfillment-Team von Uber eine separate Tabelle, um den Index zu speichern.
Uber hat auf seiner Website einen Artikel veröffentlicht, in dem erklärt wird, warum Uber von PostgreSQL auf InnoDB umgestiegen ist. Dieser Beitrag wurde aus dem Uber-Artikel zusammengestellt, um ein besseres Verständnis zu vermitteln. PostgreSQL muss immer alle Indizes in einer Tabelle aktualisieren, wenn Zeilen aktualisiert werden, wenn eine Tabelle indiziert wird, wie in diesem Artikel ausführlich beschrieben. Dieser Ansatz führt auch zu einer Erhöhung der Festplatten-IOs für Updates, die nicht indizierte Spalten ändern. In diesem Artikel beschreiben sie den Clustered-Index-Strafe als leichten Nachteil, der erheblich ist, wenn Sie viele Abfragen mit sekundären Indizes ausführen. Der Artikel erwähnt nicht, dass diese Strafe für alle Anweisungen mit einer where-Klausel gilt, nicht nur für select. Ein Postgres-Index-Only-Scan hingegen ist ziemlich nutzlos.
Sie scheinen in Zukunft in einem wichtigen Anwendungsfall für Schlüsselspeicher gut zu funktionieren. Es sind Pakete verfügbar, die für die Arbeit mit SQL-Frontends gedacht sind (aber nur sehr wenige Funktionen haben). Uber hat zusätzlich zur Verwendung von InnoDB und MariaDB eine eigene Datenbank (Schemaless) erstellt. Eine Knotenteilung ist eine wichtige Operation in einem B-Baum. Eine Knotenteilung tritt auf, wenn ein oder mehrere Knoten keinen neuen Eintrag hosten können. Im schlimmsten Fall sprudelt die Aufspaltung bis zum Wurzelknoten, der ebenfalls gespalten und durch einen neuen Knoten ersetzt wird. Infolgedessen fällt der gesamte Baum, wodurch das Gleichgewicht des Index konstant bleibt.
Ein Fehler im Replikationsprozess kann große Teile des Baums vollständig unreparierbar machen. Es ist möglich, dass der Master nicht feststellen kann, was die Replikate zu tun versuchen, und Daten löscht, die noch erforderlich sind, damit die Abfrage abgeschlossen werden kann. Dieses Problem kann behoben werden, indem die Anwendung des Replikationsstroms um ein konfigurierbares Zeitlimit verzögert wird, sodass die Lesetransaktion an der Reihe ist. Es gibt einige Ingenieure, die keine Datenbankexperten sind und dieses Problem möglicherweise nicht immer verstehen, insbesondere wenn ein ORM verwendet wird, das Details auf niedriger Ebene wie offene Transaktionen verschleiert. Die Mehrheit der Entwickler ist sich bewusst, dass Transaktionen zum Zurücksetzen von Schreibvorgängen verwendet werden können. Werden mehr Mitarbeiter von einem Unternehmen eingestellt, liegt deren Qualifikation näher am Durchschnitt. Die Erhöhung der Stichprobengröße wird durch die Einstellung von mehr Mitarbeitern vorangetrieben.
Die Anwendungsfälle von Uber erforderten den Einsatz von Schemaless, einer neuen NoSQL-Datenbank . Ihr Artikel deutet darauf hin, dass Postgres durch MySQL ersetzt wurde, aber das ist nicht der Fall; Stattdessen wird ihre maßgeschneiderte Lösung von MySQL unterstützt. In diesem Artikel wird nicht erwähnt, wie sich ihre Anforderungen geändert haben, als sie von MySQL auf PostgreSQL umgestiegen sind, daher gibt es keine Möglichkeit zu sagen. Es gibt nur eine Sache, die dem Leser in den Sinn kommt: Postgres ist schrecklich.
Warum Nosql-Datenbanken perfekt für Ube sind
Die MySQL-Datenbank von Uber baut auf einer NoSQL-Datenbank auf, sodass aus dem Text abgeleitet werden kann, dass sie diese Datenbank verwenden. Des Weiteren lässt sich aus den Daten ableiten, dass diese NoSQL-Datenbank zum Cachen und Queueing von Daten verwendet wird. Amazon ist ein weiteres NoSQL-Datenbankunternehmen, da es eine umfassende Reihe von Tools für die Entwicklung datenbankgesteuerter Anwendungen anbietet.
Marklogic Nosql
MarkLogic ist eine leistungsstarke NoSQL-Datenbank, mit der Entwickler schnell und einfach Anwendungen erstellen können, die große Datenmengen verarbeiten. MarkLogic ist benutzerfreundlich und einfach zu skalieren, was es zur idealen Wahl für Unternehmen macht, die große Datenmengen verwalten müssen.
Der MarkLogic-Server ist eine Datenbank, die von Grund auf neu entwickelt wurde, um Benutzern die Suche nach großen Mengen heterogener Daten zu erleichtern. MarkLogic integriert Datenbankinterna, Suchindizes und Anwendungsserververhalten in ein einheitliches System, das gleichzeitig ausgeführt werden kann. XML- und JSON-Dokumente werden als Datenmodelle verwendet, und ihre Transaktionsdaten werden in einem Transaktionsdaten-Repository gespeichert. Dokumentdaten können als XML oder JSON beginnen, aber sie können auch transformiert werden, nachdem sie aufgenommen wurden. Dokumentdatenmodelle enthalten in der Regel alle zugehörigen Daten im selben Dokument, sodass die Daten denormalisiert werden, bevor sie veröffentlicht werden. XML-Inhalt kann als Schema definiert werden, um eine Klasse von Inhaltsmodellen von Dokumenten darzustellen. Wenn ein bestimmtes Dokument auf eine bestimmte Weise strukturiert werden muss, ist es wichtig, eine Kennung für das Dokument zu haben.
XML-Schemas können entweder in die Schemas-Datenbank importiert oder im Config-Verzeichnis abgelegt werden. Anschließend können Sie eine Reihe von Schemas für einen bestimmten App-Server oder eine Gruppe von Servern angeben. MarkLogic unterstützt auch virtuelle SQL-Schemata, die den Kontext für SQL-Ansichten bereitstellen, wie im SQL Data Modeling Guide definiert. MarkLogic Server kann semantische Daten in RDF-Tripeln suchen, speichern und verwalten, die im Arbeitsspeicher abgelegt werden. Semantik ist eine Reihe von W3C-Standards, die den maschinenlesbaren Austausch von Daten (und Informationen über Beziehungen zwischen Daten) ermöglichen. MarkLogic ermöglicht es Ihnen, diese Art von Daten mit nativem SPARQL und SPARQL Update sowie JavaScript, XQuery und REST zu speichern, zu durchsuchen und zu verwalten. Sie können die Verwaltung binärer Daten mit den Mechanismen von MarkLogic Server optimieren.

Ein binäres Dokument kann basierend auf seiner Größe gespeichert werden, die durch eine Reihe von Schwellenwerten bestimmt wird. MarkLogic ist eine Singlethread-Anwendung, die für mehrere Prozessoren gleichzeitig entwickelt wurde. Es gibt zahlreiche Socket-Ports, die für die externe Kommunikation verwendet werden können. Die MarkLogic-Plattform soll sowohl Geschwindigkeit als auch Skalierbarkeit bieten. Erweiterte Abfragen in MarkLogic werden in Terabyte an Daten geschrieben. Die größten Live-Bereitstellungen haben inzwischen 200 Terabyte und eine Milliarde Dokumente überschritten. Beim Einsatz von Clustern wird eine hohe Verfügbarkeit erreicht.
Diese Art von Server ist normalerweise in einer Box mit 4 oder 8 Kernen, 64 oder 128 GB oder größerer Kapazität untergebracht. Elastic Load Balancer (ELBs) sind in die Amazon Elastic Compute Cloud (EC2) integriert, wodurch MarkLogic-Cluster den Anwendungsdatenverkehr automatisch verteilen und ausgleichen können. Um die Verfügbarkeit der EC2-Umgebung zu verbessern, können D-Nodes am selben Standort geclustert werden.
Was ist die Marklogic-Datenbank?
MarkLogic ist eine leistungsstarke NoSQL-Datenbank, die es Entwicklern ermöglicht, Anwendungen schneller zu erstellen, indem sie ihnen die Tools zur Verfügung stellt, die sie für die Arbeit mit allen Arten von Daten benötigen. MarkLogic ist die einzige NoSQL-Datenbank, die die Leistungsfähigkeit einer dokumentenorientierten Datenbank mit der Flexibilität eines Schlüsselwertspeichers kombiniert und damit die ideale Plattform für die modernen Anwendungen von heute darstellt.
Es ist eine leistungsstarke Datenverwaltungsplattform, die ein einheitliches System zur Verwaltung von Daten bietet. Es werden Dokumentdatenmodelle in XML und JSON verwendet und die Dokumente in einem Transaktions-Repository gespeichert. Der Data Hub befindet sich über dem Data Lake und enthält qualitativ hochwertige, kuratierte, sichere, deduplizierte, indizierte und abfragbare Daten. Darüber hinaus wurde der MarkLogic Data Hub entwickelt, um riesige Datensätze mit automatisiertem Data Tiering zu verwalten, das Daten sicher speichert und aus einem Data Lake abruft.
Warum Graphdatenbanken die Oberhand gewinnen
Graphdatenbanken entwickeln sich schnell zur bevorzugten Option zum Speichern von Daten in einer Vielzahl von Formaten, die manuell nur schwer zu verwalten sind. Herkömmliche SQL-Datenbanken können diese Art von Abfragen nicht verarbeiten, und sie können beim Umgang mit dieser Art von Abfragen sehr hilfreich sein. Wenn Sie Daten auf eine Weise abfragen müssen, die von SQL-Datenbanken verarbeitet werden kann, und wenn Sie Daten in Diagrammen speichern müssen, ist MarkLogic eine gute Option.
Marklogic-Datenbank gegen Mongodb
Die NoSQL-Unternehmensdatenbank von MarkLogic enthält alle erforderlichen Funktionen auf einer Plattform. MongoDB hingegen wird verwendet, um große Ideen zu organisieren. MongoDB ist ein MongoDB-Dienst, der Daten in JSON-ähnlichen Dokumenten speichert, die auf verschiedene Weise strukturiert werden können.
Wenn Sie META-Daten haben, können Sie MarkLogic verwenden, weil es alles so schnell abruft. Es gibt bessere Alternativen zur Verwendung einer relationalen Datenbank, falls eine benötigt wird. MongoDB ist aufgrund seiner unglaublichen Flexibilität und Benutzerfreundlichkeit ein unglaubliches Tool für eine Vielzahl von Anwendungen. Trotz der Tatsache, dass Open Source in fast allem anderen verwendet wird, ist die Backend-Datenbank von entscheidender Bedeutung. Der Kundensupport von MarkLogic ist äußerst reaktionsschnell und professionell. Sie reagieren schnell auf wichtige Probleme und Probleme mit der Produktionsqualität. Ich freue mich darauf, die Ressourcen von MongoDB zu nutzen, um von seiner Leistungsfähigkeit zu profitieren.
Nur wenige Aspekte können verbessert oder vereinfacht werden. Wenn Sie noch keinen DBA oder Systemadministrator haben, der sich mit MongoDB auskennt, sollten Sie sich an einen MongoDB-Hosting-Anbieter wenden, der auf diesem Gebiet spezialisiert ist. Wenn Ihr Datensatz wächst, können Sie die Speicher-Engine von Cassandra verwenden, um konstante Schreibvorgänge zu erstellen. MongoDB kann für Analysen mit nativer Hadoop-Unterstützung verwendet werden.
Marklogic Graph-Datenbank
MarkLogic ist eine Graphdatenbank. Es verwendet ein Diagrammdatenmodell zum Speichern und Abfragen von Daten. Eine Graphdatenbank ist eine Datenbank, die ein Graphdatenmodell zum Speichern und Abfragen von Daten verwendet.
Der Entwicklerleitfaden für semantische Graphen ist ein Muss für jeden, der sich für das Gebiet der semantischen Graphen interessiert. Zu den in diesem Handbuch enthaltenen Themen gehören: Die Daten können heruntergeladen werden. Mit dem vollständigen DBPedia-Beispiel von Persondata (sowohl in Turtle als auch in Englisch) können Sie ihnen zeigen, wie man ein Turtle- oder englisches Wort verwendet. Die Dokumentendatenbank verfügt über einen dreifachen Index und ein Sammlungslexikon, die standardmäßig aktiviert werden können. Bevor Sie eine Datenbank für Tripel verwenden, vergewissern Sie sich, dass beide Optionen aktiviert sind. mlcp ist eine ideale Methode zum Massenladen von Triples in einer Windows-Desktopumgebung. Die native SPARQL-Funktion oder die integrierte sem:sparQL-Funktion sind beide akzeptable Methoden zum Ausführen von MarkLogic-Abfragen . Der Abschnitt Downloading Dataset geht davon aus, dass Sie das Beispiel-Dataset geladen haben.
Marklogic Data Hub
Data Hub von MarkLogic ist eine kostenlose Open-Source-Softwareschnittstelle, die Daten aus mehreren Quellen aufnimmt, harmonisiert, verwaltet und anschließend durchsucht und analysiert. Die Lösung wird auf MarkLogic Server ausgeführt und soll eine einheitliche Plattform für unternehmenskritische Anwendungen bieten.
Wofür wird Marklogic verwendet?
MarkLogic ist eine leistungsstarke Datenbank, mit der Sie Daten effektiver speichern, verwalten und durchsuchen können. Es wird von Organisationen in einer Vielzahl von Branchen verwendet, um ihre Anwendungen und Websites zu betreiben. MarkLogic eignet sich besonders gut für die Verarbeitung großer Datenmengen und komplexer Abfragen.
Marklogic-Server
MarkLogic Server ist eine leistungsstarke NoSQL-Datenbankplattform , mit der Entwickler schnell und einfach anspruchsvolle Anwendungen erstellen können, die alle ihre Daten nutzen, unabhängig von ihrer Struktur oder ihrem Speicherort. MarkLogic Server basiert auf einer einzigartigen Architektur, die das Beste aus der relationalen und der NoSQL-Welt kombiniert und Entwicklern die Flexibilität gibt, mit ihren Daten so zu arbeiten, wie es ihren Anforderungen am besten entspricht.
DocumentManager, eine DatabaseClient-Instanz, die speziell für die Dokumentenverwaltung erstellt wurde, kann zum Verwalten von Dokumenten verwendet werden. Um zu demonstrieren, wie ein XML-Dokument gelesen wird, verwenden Sie das Java-basierte ReadXMLDocument.java von Marklogic. Die Java ReadMetadata-Bibliothek zeigt Ihnen, wie Sie den empfangenen Dokumenttyp erkennen und richtig damit umgehen. Das Einfügen eines Textdokuments ähnelt dem Einfügen eines PDF-Dokuments, aber Sie müssen ein StringHandle verwenden oder das Format wie im vorherigen Beispiel gezeigt bereitstellen. Über die Java-API kann auf vielfältige Weise auf Dokumente und Metadaten zugegriffen werden. Die DeleteDocument.java-Methode kann verwendet werden, um mehrere Dokumente auf einmal zu löschen. Dokumenten-Downloads in großem Umfang.
Ein Dokument nach dem anderen kann kostspielig sein, wenn Digest-Authentifizierungsschemata verwendet werden, da nur ein Dokument hochgeladen werden muss. Wir verwenden Begriffe wie Suchen und Abfragen in MarkLogic auf die gleiche Weise, unabhängig vom Kontext, in dem wir sie verwenden. Wenn Sie ein breites Spektrum an Suchergebnissen ausdrücken möchten, ist eine Abfragesyntax eine einfache und leistungsstarke Möglichkeit, dies zu tun. Der Suchtext wird mit der setCriteria-Methode unseres Abfragemanagers angegeben, nachdem eine anfängliche String-Abfrageinstanz von unserem Abfragemanager abgerufen wurde. Es stimmt, dass selbst eine einfache Suche sehr leistungsfähig sein kann, wenn sie in der Standardsuchkonfiguration von MarkLogic verwendet wird. Wie in der Abfragedefinition angegeben, werden drei Methoden verwendet, um jede Abfrage zu implementieren. Mit den ersten beiden Optionen können Sie einen Abfragespeicherort oder einen Sammlungssatz angeben.
Mit letzterem können Sie eine Abfrage mit einer Reihe von benutzerdefinierten Suchoptionen verknüpfen, die auf dem Server gespeichert sind. Nachfolgend finden Sie eine Liste der Suchergebnisse. Wenn Sie das Programm ausführen und die Konsole untersuchen, können Sie sehen, wie MarkLogic seine Suchergebnisse in XML darstellt. Das Lernprogrammprojekt enthält ein Java-Skript namens Search ResultsAsJSON. Java. Wenn Sie das Programm ausführen, sehen Sie die rohen JSON-Suchergebnisse, die vom Server abgerufen wurden. Rufen Sie Suchergebnisse im POJO-Format ab, indem Sie die Methode getMatchResults() aufrufen.
Sie können ein Array von MatchDocumentSummary-Objekten erhalten, indem Sie ihm eine Zeichenfolge übergeben. Wenn ein Dokument einen Suchtreffer enthält, kann dieser durch ein MatchLocation-Objekt dargestellt werden. Eine benannte Standardoption wird verwendet, wenn Sie keinen Namen explizit angeben. Constraint wird wegen seiner Bedeutung in Mark Logic häufig verwendet. Die Konfiguration für einen gesamten Optionssatz wird beim Erstellen oder Ersetzen eines Optionssatzes unter src/main/ml-options/options gespeichert. Die hier aufgeführten Einschränkungen sind in einer Vielzahl von Formen verfügbar. Machen Sie ein Programm.
Diese Methode sollte die gleichen Ergebnisse wie CollectionSearch Java zurückgeben. Als Ergebnis dieser neuen Suchzeichenfolge wird das Shakepeare-Erfassungskriterium nun als Teil der Suchzeichenfolge durch die Tag-Einschränkung bereitgestellt. Wie Sie sehen können, verwenden wir den folgenden Befehl, um unsere Konfiguration bereitzustellen. Sie könnten stattdessen eine neue Eingabeaufforderung öffnen und zu mlwatch navigieren, wo Änderungen an Ihrem Skript an Mark Logic übertragen werden. Der Kontext eines Wortes wird eher als sein Schlüssel oder Element in Bezug auf eine Wortbeschränkung getestet, die einer Wertbeschränkung ähnlich ist. Passende Wörter werden auch durch Stammstämme gebildet, was bedeutet, dass ähnliche Wörter verwendet werden, wie z. B. Strategien und Strategien. Wir müssen die folgenden Dateien erstellen/ändern, um Stemming zu aktivieren: src/main/ml-config/databases/content-database.
Das Ausführen des folgenden Befehls wird Ihnen helfen, das Verfahren zu verstehen. Das gradle mlUpdateIndexes-Modul wird zum Aktualisieren von Indextabellen im gradle mlReindexDatabase-Modul verwendet. Mithilfe der Eigenschaftsbeschränkung können wir anhand von Metadaten nach den Eigenschaften eines Dokuments suchen. Wir verwenden unsere Metadaten, die während der Aufnahme extrahiert und als Dokumenteigenschaften gespeichert werden, um unsere Bilder zu generieren. Wenn wir eine Wortsuche nach „Eigenschaften“ eingeben, wird sie nur auf diese Dokumenteigenschaft angewendet. Die Methode search() wird im Abfragemanager verwendet, um die Abfrage auszuführen.
Wofür wird Marklogic verwendet?
MarkLogic Server ist ein Softwaretool, das eine Vielzahl von Daten speichert und verwaltet, um Transaktions-, Betriebs- und Analyseanwendungen auszuführen.
Der Data Hub: Ihre One-Stop-Lösung für das Datenmanagement
Data Hubs geben Ihnen die vollständige Kontrolle darüber, wie Daten aus einem Data Lake verwaltet und abgerufen werden. In MarkLogic sorgt automatisiertes Data Tiering dafür, dass Daten sicher gespeichert und von einem Data Lake aus abgerufen werden, und vereinfacht die Datenintegration.
Wie verbinde ich mich mit Marklogic?
Navigieren Sie nach der Installation und dem Start von MarkLogic zur browserbasierten Verwaltungsschnittstelle (unter http://localhost:8001/), wo Sie erfahren, wie Sie eine Entwicklerlizenz erhalten und einen Administrator konfigurieren.
Marklogic: Der App-Server mit einer Rest-API
Die Verwendung von REST-API-Client-Anwendungen zur Interaktion mit MarkLogic Server über eine REST-API-Instanz wird immer häufiger. MarkLogic beschäftigt 500 Mitarbeiter und ist einer der größeren App-Server-Anbieter auf dem Markt. Ihren Umsatzprognosen zufolge werden sie im Jahr 2021 einen Spitzenumsatz von 100,0 Millionen US-Dollar erzielen, bei einem durchschnittlichen Umsatz pro Mitarbeiter von 200.000 US-Dollar.