
Die Vor- und Nachteile von Spaltendatenbanken
Veröffentlicht: 2022-11-19NoSQL-Datenbanken sind eine gute Wahl für viele moderne Anwendungen, aber es gibt ein paar wichtige Dinge, die Sie beachten sollten, bevor Sie den Wechsel vornehmen. Ein wichtiger Faktor ist, ob Sie eine relationale Datenbank benötigen oder nicht. In diesem Fall ist eine spaltenorientierte Datenbank möglicherweise nicht die richtige Wahl. Spaltenförmige Datenbanken eignen sich gut für Anwendungen, die große Datenmengen schnell analysieren müssen. Sie sind auch eine gute Wahl für Anwendungen, die nicht das vollständige relationale Modell benötigen und mit einem einfacheren Datenmodell auskommen. Spaltenbasierte Datenbanken haben jedoch einige Nachteile. Sie können schwieriger zu verwenden sein als relationale Datenbanken und unterstützen möglicherweise nicht alle Funktionen, die Sie benötigen. Bevor Sie entscheiden, ob eine spaltenorientierte Datenbank für Ihre Anwendung geeignet ist, stellen Sie sicher, dass Sie die Vor- und Nachteile kennen.
Eine spaltenorientierte Datenbank organisiert und speichert Daten nach Spalten statt nach Zeilen. Sie verwenden Aggregatfunktionen und -operationen, um Datenspalten zu optimieren. Datenbankspalten sind skalierbar und lassen sich im Vergleich zu anderen Datenbanktypen gut komprimieren. In einer spaltenorientierten Datenbank wird jede Datenzeile durch eine Anzahl von Spalten in mehrere Spalten unterteilt. Spaltenförmige Datenbanken eignen sich gut für die Verarbeitung großer Datenmengen, Business Intelligence (BI) und Analysen. Zeilenoperationen haben eine viel langsamere Zeit als Spaltenoperationen. Die IoT-Datensätze enthalten möglicherweise nur eine kleine Anzahl von Datenelementen, da neue Datensätze in einem konsistenten Strom eintreffen. Big Data hat das Potenzial, die Funktionsweise operativer Datenbanksysteme zu verändern.
Die beiden Arten von Datenbankdatenbanken, Zeilen- und Spaltendatenbanken, können Daten laden und Abfragen mit herkömmlichen Datenbankabfragesprachen wie SQL durchführen. In vielen Fällen können Datenbank-Backbones, wie z. B. Zeilen- und Spaltendatenbanken, als Engine für das gemeinsame Extrahieren, Transformieren, Laden und Erstellen von Tools dienen.
Eine spaltenorientierte Datenbank, eine Art Datenbankverwaltungssystem (DBMS), speichert Daten in Spalten statt in Zeilen. Um die Rückgabe einer Abfrage zu beschleunigen, können Spalten in einer spaltenorientierten Datenbank effizient von und auf der Festplatte geschrieben und gelesen werden.
Heute sehen wir uns an, wie Spalten in einer spaltenorientierten Datenbank funktionieren, und vergleichen sie mit einer traditionelleren zeilenorientierten Datenbank (z. B. MySQL). Wir gehen in diesem Artikel darauf ein, was eine Spaltendatenbank ist, sowie auf ihre Vor- und Nachteile.
Was sind einige Beispiele für eine NoSQL-Datenbank? Microsoft SQL Server ist ein von Microsoft entwickeltes Verwaltungssystem für relationale Datenbanken.
Ist Mongodb eine Spaltendatenbank?
Mongodb ist keine spaltenorientierte Datenbank.
Es wird immer beliebter, da es eine verbesserte Abfrageleistung in analytischen Abfragen bietet. Daten in Spaltendatenbanken werden effizienter gespeichert als in datenbankbasierten Datenspeichern, da Daten in Spalten gespeichert werden. Analytische Abfragen, die in spaltenorientierten Datenbanken ausgeführt werden, haben einen größeren Leistungsvorteil. Im Vergleich zur zeilenorientierten Speicherung ist die spaltenorientierte Speicherung in Bezug auf Speicherplatz und Abfrageleistung viel effizienter. Da Daten spaltenweise gespeichert werden, können Daten leichter gelesen und geschrieben werden.
Was sind Nosql-Datenbanken?
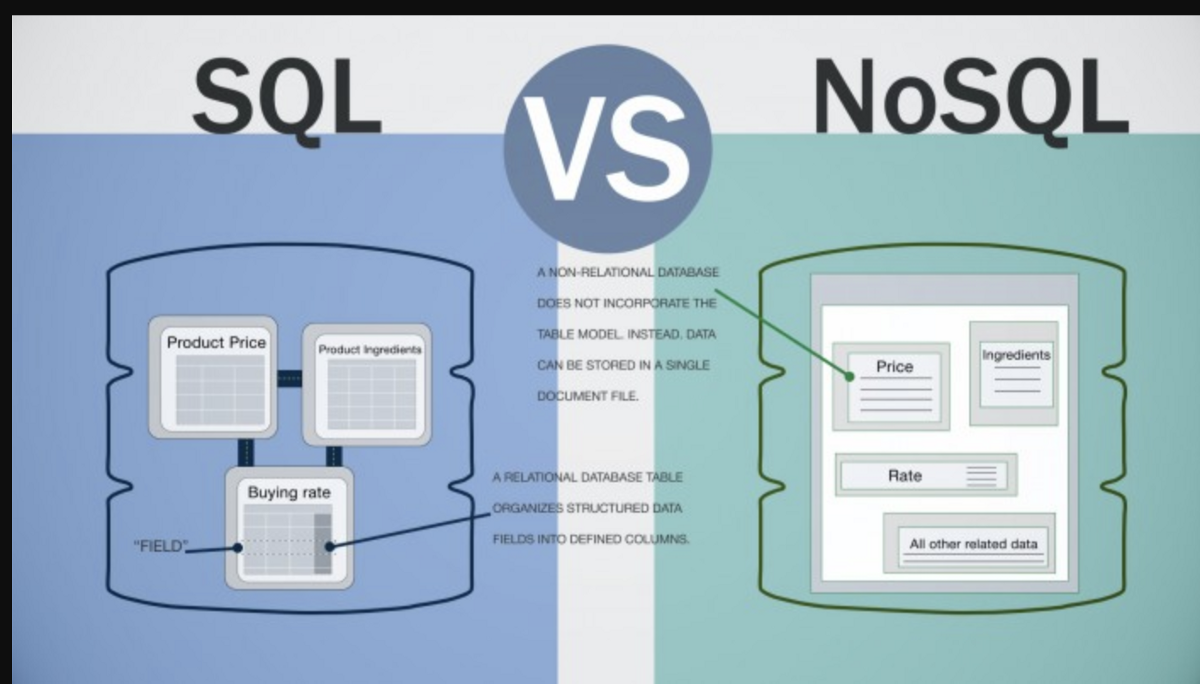
NoSQL-Datenbanken sind Datenbanken, die nicht das traditionelle relationale Datenbankmodell verwenden. Stattdessen verwenden sie eine Vielzahl unterschiedlicher Modelle, darunter Dokument-, Diagramm-, Schlüsselwert- und Spaltenmodelle. NoSQL-Datenbanken sind oft besser geeignet, um große Datenmengen zu verarbeiten, die für das relationale Modell nicht gut geeignet sind.
Ein NoSQL-System ist eine Art Datenbank, die nicht auf SQL basiert. Das vom Datenmodellierungsteam verwendete Datenmodell unterscheidet sich vom traditionellen Zeilen- und Spaltentabellenmodell, das in Verwaltungssystemen für relationale Datenbanken verwendet wird. NoSQL-Datenbanken sind nicht nur sehr unterschiedlich, sondern auch sehr unterschiedlich. Dokumentendatenbanken werden typischerweise mit einer Scale-out-Architektur für die gängigsten Dokumententypen implementiert. E-Commerce-Plattformen, Handelsplattformen und die Entwicklung mobiler Apps sind Beispiele dafür, wie diese Plattformen einem Unternehmen zugute kommen können. Das primäre Ziel des Vergleichs von MongoDB und Postgres ist ein detaillierter Vergleich der führenden NoSQL-Datenbanken. Die Fähigkeit einer spaltenorientierten Datenbank, den Wert einer einzelnen Spalte zu aggregieren, ist ideal für die schnelle Analyse einer bestimmten Spalte.
Da die Art und Weise, wie Daten geschrieben werden, es schwierig macht, konsistent zu sein, müssen sie sich auf eine Vielzahl von Quellen stützen. Graphdatenbanken sind für das Erfassen und Suchen von Verbindungen zwischen Datenelementen optimiert, um diese zu erfassen und zu suchen. Der Overhead, der mit dem JOINING mehrerer Tabellen in SQL verbunden ist, wird durch die Verwendung dieser Methoden eliminiert.
MongoDB speichert Dokumente normalerweise in einer Sammlung, die als Sammlung bezeichnet wird. Es ist die Sammlung von Dokumenten, die durch irgendeinen Aspekt miteinander verbunden sind. Daten in Sammlungen werden normalerweise von mehreren Anwendungen zum Speichern von Daten verwendet.
Die Daten von MongoDB werden in einem B-Baum gespeichert, was bedeutet, dass sie als Bucket oder Ebene organisiert sind. Ein Bucket ist eine Sammlung von Daten, auf die häufig von einem Browser zugegriffen wird. Das Level ist größer, weil mehr Eimer darin sind. Die Daten in einem B-Baum können in aufsteigender Reihenfolge nach Schlüsseln sortiert werden.
Da MongoDB so einfach zu skalieren ist, ist es eine fantastische Plattform für die Skalierung. Wenn die Last Ihres Clusters zunimmt, müssen Sie möglicherweise weitere Server hinzufügen. Darüber hinaus kann MongoDB geclustert werden, um HA-Daten (High-Availability) bereitzustellen.
Warum Nosql-Datenbanken immer beliebter werden
Auch wenn NoSQL-Datenbanken in vielen Fällen immer beliebter werden, sind sie immer noch eine Alternative zu relationalen Datenbanken. Daten, die nicht in einer relationalen Datenbank gespeichert werden können, wie große Grafiken oder Daten, die sich regelmäßig ändern, sind für sie besonders reizvoll.
Beispiel für eine spaltenförmige Nosql-Datenbank
Eine spaltenorientierte Datenbank ist ein Datenbankverwaltungssystem (DBMS), das Daten in Spalten statt in Zeilen speichert. Spaltenorientierte Systeme sind für Analyse-Workloads oft schneller als herkömmliche zeilenorientierte Systeme.
Beispielsweise könnte eine spaltenorientierte Datenbank Mitarbeiterdaten speichern, wobei jede Spalte Daten wie Mitarbeiter-ID, Name, Berufsbezeichnung, Gehalt usw. enthält. Eine zeilenorientierte Datenbank würde dieselben Daten speichern, wobei jede Zeile die ID, den Namen, die Berufsbezeichnung, das Gehalt usw. eines Mitarbeiters enthält.
NoSQL ist ein wichtiger Fortschritt im Bereich relationaler Daten, da es hoch spezialisierte oder zeitaufwändige Systeme überflüssig macht. Dokument-, Diagramm-, Spalten- und Zeilenwert-NoSQL-Datenbanken sind die vier Haupttypen. Dokumentenspeicher enthalten sowohl komplexe Datenschemata als auch assoziative Schlüsselpaare. Datenbankspalten organisieren Daten in Spalten und funktionieren genauso wie relationale Datenbanken. In Spaltendatenbanken ist eine Gitterskalierbarkeit von horizontal bis unendlich verfügbar. Komprimierung ist eine gut gemachte Speichermethode, und Column-Stores bieten viel Speicherplatz. Die Geschwindigkeit, mit der Aggregationsabfragen ausgeführt werden, ist normalerweise höher als die einer relationalen Datenbank.
Aufgrund der horizontalen Natur des Datendesigns können OLTP-Apps nicht in Verbindung mit Columnar Stores verwendet werden. Column Stores als Lösung haben das Potenzial, extrem leistungsfähig zu sein, aber sie haben auch das Potenzial, extrem begrenzt zu sein. Obwohl Spalten weniger Konsistenz- und Isolationsgarantien bieten als Zeilen, muss jede Zeile mehrmals neu geschrieben werden. NoSQL-Datenbanken sind aufgrund fehlender nativer Sicherheitsfunktionen anfälliger für Online-Angriffe. Wenn Cybersicherheit für Sie eine hohe Priorität hat, sollten Sie ein relationales Modell verwenden oder Ihr Schema definieren.
Nosql-Datenbank
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das traditionelle tabellenbasierte relationale Datenbankmodell verwendet. NoSQL-Datenbanken werden häufig für Big Data und Echtzeit-Webanwendungen verwendet.
Datenbank NoSQL-Datenbanken speichern keine Daten in herkömmlichen relationalen Datenbanken . Dokumenttypen, Schlüsselwerttypen, Breitspaltentypen und Diagrammtypen sind die häufigsten. Die Kosten für die Speicherung von Daten sind in den letzten Jahren dramatisch gesunken, was zur Entwicklung von NoSQL-Datenbanken geführt hat. Sie können eine große Menge unstrukturierter Daten speichern, sodass Entwickler auswählen können, welche Aspekte der Daten sie speichern möchten. Dokumentdatenbanken, Schlüsselwertdatenbanken, Wide-Column-Stores und Graphdatenbanken sind Beispiele für NoSQL-Datenbanken. Da keine Verknüpfungen erforderlich sind, werden Abfragen schneller ausgeführt. Datenintensive Anwendungsfälle wie Finanzanalysen und IoT-Messwerte von intelligenten Katzentoiletten können verwendet werden, während weniger ernsthafte Anwendungen wie lustige und unterhaltsame Anwendungsfälle wie intelligente Lebensmittelverpackungen verwendet werden können.
In diesem Tutorial gehen wir darauf ein, wann und warum Sie NoSQL-Datenbanken in Betracht ziehen sollten. Darüber hinaus werden wir uns mit einigen der häufigsten Missverständnisse über NoSQL-Datenbanken befassen. Laut DB-Engines ist MongoDB die beliebteste NoSQL-Datenbank der Welt. In diesem Tutorial erfahren Sie, wie Sie eine MongoDB-Datenbank abfragen, ohne etwas auf Ihrem Computer zu installieren. Datenbank-Cluster sind ein Beispiel für eine MongoDB-Datenbank. Sobald Sie einen Cluster haben, beginnt Atlas mit der Speicherung von Daten. Sie haben drei Optionen zum Erstellen einer Datenbank in Atlas Data Explorer, MongoDB Shell oder MongoDB Compass: manuell oder automatisiert.
In diesem Fall wird der Beispieldatensatz von Atlas importiert. Neben ihren flexiblen Datenmodellen, horizontaler Skalierung, blitzschnellen Abfragen und Benutzerfreundlichkeit bieten NoSQL-Datenbanken zahlreiche Vorteile. Mit dem Datenexplorer können neue Dokumente eingefügt, bestehende Dokumente bearbeitet und gelöscht werden. Die Verwendung des Aggregations-Frameworks ist ein äußerst leistungsfähiges Werkzeug zur Analyse Ihrer Daten. Die Verwendung von Diagrammen zur Visualisierung von Daten, die in Atlas und Atlas Data Lake gespeichert sind, ist der einfachste Weg, dies zu tun.
Eine Schlüssel-Wert-Datenbank ist die einfachste Art von NoSQL, mit mehreren Tabellen, die Schlüssel und Werte enthalten. Der Schlüssel wird nur für den Datenzugriff benötigt, was das Lesen und Schreiben vereinfacht. Dieser Datenbanktyp ist jedoch nicht für große Datensätze geeignet, da jeder Schlüssel in der Datenbank eindeutig sein muss.
Daten werden in Tabellen gespeichert, die Spalten enthalten, die die Schlüssel und Werte von spaltenbasierten Datenbanken speichern. Aufgrund ihrer Vielseitigkeit kann eine spaltenbasierte Datenbank Daten über einen längeren Zeitraum speichern als eine Datenbank ohne Spalten.
Dokumentdatenbanken speichern im Gegensatz zu Spaltendatenbanken Daten in Tabellen mit Spalten, die Schlüssel und Werte speichern. Dokumentenbasierte Datenbanken hingegen speichern Daten ähnlich wie E-Mails in Dateien. Da Dokumente einfach zu lesen und zu verstehen sind, können Daten auf einfache Weise gesucht und angezeigt werden.
Eine graphbasierte Datenbank ähnelt einer dokumentbasierten Datenbank darin, dass die Daten in Tabellen gespeichert werden, die Spalten mit Schlüsseln und Werten enthalten. Im Gegensatz dazu werden Graphen, die in Bezug auf die Datenspeicherung Netzwerken ähneln, in graphbasierten Datenbanken gespeichert. Datenknoten können verbunden und Muster einfach identifiziert werden.

Nosql-Datenbanktypen für jeden Bedarf
Dokumentendatenbanken wie MongoDB eignen sich gut für Anwendungen, die Informationen in einem flexiblen und modularen Format speichern müssen. In MongoDB werden JSON, Text und BSON unterstützt. Dies macht es zu einer ausgezeichneten Wahl für Anwendungen wie Blogs und Wikis, die große Mengen an unstrukturierten Daten speichern.
Cassandra und andere spaltenbasierte Datenbanken sind hervorragende Optionen für Anwendungen, die große Datenmengen in einem Spaltenformat speichern müssen. Datenformate wie das eigene Binärformat von Avro und Cassandra können zusätzlich zur textbasierten Speicherung in HBase verwendet werden. Da es Daten speichern kann, die nicht in eine relationale Datenbank passen, eignet es sich gut für Anwendungen, die große Datenmengen erfordern.
DynamoDB und andere Schlüsselwertdatenbanken eignen sich gut für Anwendungen, die normalerweise kleine bis mittlere Datenmengen speichern. DynamoDB unterstützt beispielsweise JSON und binäre Datenformate. Dies macht es zu einer ausgezeichneten Wahl für Anwendungen, die Daten speichern, die zu klein für eine relationale Tabelle sind und auf die häufig zugegriffen wird, aber kein bestimmtes Format erfordern, sowie für Anwendungen, die Daten speichern müssen, auf die häufig zugegriffen wird, aber kein bestimmtes Format erfordern Format.
Es eignet sich gut für Anwendungen, die die Integration von Datenelementen erfordern, die in Graphdatenbanken wie Neo4j gespeichert sind. Beispielsweise können Datenformate wie JSON, Atom und Graph in Graphdatenbanken verwendet werden. Es ist ideal für Anwendungen, die Daten speichern müssen, die zu komplex sind, um in einer relationalen Datenbank gespeichert zu werden, oder die Daten speichern, auf die häufig zugegriffen wird, die jedoch nicht in einem bestimmten Format gespeichert werden müssen.
Open-Source-Spaltendatenbank
Eine spaltenorientierte Datenbank ist ein Datenbanktyp, der Daten in Spalten statt in Zeilen speichert. Dieser Datenbanktyp wird häufig für Data Warehousing- und Analyseanwendungen verwendet, da er eine bessere Leistung und Skalierbarkeit als eine herkömmliche zeilenbasierte Datenbank bieten kann.
Es gibt eine Reihe von spaltenorientierten Open-Source-Datenbanken wie Apache Cassandra, Apache HBase und Apache Drill. Jede dieser Datenbanken hat ihre eigenen Stärken und Schwächen, daher ist es wichtig, die richtige für Ihre spezifischen Bedürfnisse auszuwählen.
Diese Datenbanken sind ideal für einen effizienten Analyse-Workflow, da sie schnell sind und gleichzeitig skalierbar sind. Anstatt Daten in Zeilen zu speichern, werden in der Columnar Database Spalten verwendet. Die Verwendung von spaltenbasiertem Speicher verbessert die Datenbankabfrageleistung, indem die Anzahl der E/A-Versuche erheblich reduziert wird. Es wurde verwendet, um Amazon Redshift und Snowflake sowie andere relationale Warehouses zu betreiben. Um den Durchsatz von spaltenorientierten Datenbanken zu verbessern, werden kostengünstige Hardware-Cluster verwendet, um sie zu skalieren. In herkömmlichen Datenbanken werden Zeilen in verschiedene Datenabschnitte unterteilt. Die relevantesten Elemente in einer Columnar Database sind in Sekundenschnelle zugänglich.
Selbst wenn die Datenbank groß ist, erhöht dies die Abfragegeschwindigkeit. Auch die Kosten für die Verarbeitung und Speicherung der gestiegenen Datenmenge steigen. Parquet und ORC sind zwei der am häufigsten verwendeten Formate für Spalten in Datenbanken. Parquet wird verwendet, um flache Datenspalten effektiver darzustellen. ORC ist ein Dateiformat, das speziell für Hadoop-Workloads entwickelt und für große Streaming-Lesevorgänge optimiert wurde. Hevo Data, eine No-Code-Datenpipeline, ermöglicht es Ihnen, Daten aus verschiedenen Datenbanken mit über 100 anderen Quellen zu integrieren und in Ihr bevorzugtes BI-Tool zu laden. Apache Druid ist eine Echtzeit-Analysedatenbank, die auf Open-Source-Software basiert und OLAP-Abfragen für große Datensätze viel schneller ausführen kann.
Die verteilte Open-Source-Datenspeicher-Engine Apache Kudu wird verwendet, um schnelle Analyseprozesse auf riesigen Informationsmengen auszuführen. Das Speichermodell von MonetDB basiert auf vertikaler Fragmentierung, und seine Abfrageausführungsarchitektur basiert auf modernen Computern. Die analytische Reporting-Engine von ClickHouse ermöglicht die Generierung von Berichten in Echtzeit. BigQuery ist ein Ergebnis von Googles Distributed Query Engine, bekannt als Dremel. Die serverlose Architektur von Dremel kann Terabytes an Daten in Sekunden verarbeiten, indem verteiltes Computing genutzt wird. Komprimierung, Just-in-Time-Projektion und horizontale und vertikale Partitionierung sind einige der Vorteile der spaltenbasierten Speicherung. Daten können in Zeilen in einer spaltenorientierten Datenbank gespeichert werden, die eine zeilenorientierte Datenbank ist.
Sie skalieren, indem sie Cluster mit kostengünstiger Technologie verwenden, um den Durchsatz zu erhöhen. Spaltenförmige Datenbanken können für eine Vielzahl von Zwecken in der Big-Data-Verarbeitung, Business Intelligence (BI) und Analytik verwendet werden. Die Geräte des Internet of Things (IoT) speichern eine große Datenmenge in ihren Rechenzentren.
Die drei beliebtesten spaltenorientierten Datenspeicherdatenbanken
Apache Cassandra ist ein bekanntes Datenspeichersystem in einer Vielzahl von spaltenorientierten Datenbanken. Cassandra ist ein serverseitiges Open-Source-Projekt, das riesige Datenmengen auf vielen Commodity-Servern verarbeiten kann. DynamoDB hingegen verwendet ein NoSQL-Datenbankmodell und kann jede Art von Daten speichern. MariaDB behält das relationale Modell und SQL bei und ermöglicht gleichzeitig eine schnellere und einfachere Generierung analytischer Abfragen, was es zu einer beliebten Wahl für viele spaltenorientierte Datenbanken macht.
Beste spaltenförmige Datenbank
Diese Frage lässt sich nicht pauschal beantworten, da sie von individuellen Vorlieben und Bedürfnissen abhängt. Einige der beliebtesten Spaltendatenbanken sind jedoch Amazon Redshift, Google BigQuery und Microsoft SQL Server. Diese Datenbanken sind alle hochgradig skalierbar und bieten eine hervorragende Leistung für Data-Warehousing- und Analyse-Workloads.
Die Daten in einer spaltenorientierten Datenbank werden in Spalten und nicht in Zeilen gespeichert. Im Vergleich zu herkömmlichen Zeilendatenbanken bieten spaltenorientierte Datenbanken eine Vielzahl von Vorteilen, darunter Geschwindigkeit und Effizienz. Sadas Engine ist das leistungsstärkste und flexibelste spaltenbasierte Datenbankverwaltungssystem, das sowohl lokal als auch in der Cloud verfügbar ist. ClickHouse ist ein benutzerfreundliches Open-Source-Datenbankverwaltungssystem. Amazon Redshift, das schnellste Cloud Data Warehouse der Welt, wächst weiter an Geschwindigkeit. ClickHouse nutzt das gesamte Potenzial aller verfügbaren Hardware, um jede Anfrage so schnell wie möglich zu bearbeiten. Die Such- und Analyse-Engine von Rockset unterstützt Live-Dashboard-Anzeigen und Echtzeit-Apps.
Vertica ist die schnellste und am besten skalierbare fortschrittliche analytische Datenbank auf dem Markt. Die ANSI-SQL-Sprache ist ideal für die Petabyte-Analyse, da sie Daten blitzschnell verarbeiten und gleichzeitig den Betriebsaufwand eliminieren kann. Skalierbare On-Demand-Analysen mit um 26 % bis 34 % niedrigeren Drei-Jahres-Betriebskosten als Cloud-Data-Warehouse-Alternativen. Sie können Ihre Daten bei Bedarf und zu Hause mit Verschlüsselungsschlüsseln verschlüsseln, die vom Unternehmen verwaltet werden, oder Sie können sie nach Belieben auf Verschlüsselung einstellen. Greenplum Database ist eine Open-Source-Plattform für massiv parallele Daten, die Funktionen für Analyse, maschinelles Lernen und künstliche Intelligenz bietet. Das Tool bietet blitzschnelle Echtzeit-Datenanalysen von Datenmengen im Petabyte-Bereich. Mit seinem Kerndesign kombiniert Druid Ideen aus Data Warehouses, Zeitreihendatenbanken und Suchsystemen, um eine leistungsstarke Analysedatenbank in Echtzeit zu erstellen.
Apache 2 ist der Quellcode für dieses Projekt. MariaDB Platform, eine Open-Source-Unternehmensdatenbank, ist die Grundlage dieser Lösung. Diese Plattform kann eine breite Palette von Transaktions-, Analyse- und Hybrid-Workloads unterstützen. MariaDB kann je nach Art der verwendeten Hardware auf handelsüblicher Hardware oder in einer öffentlichen Cloud bereitgestellt werden. Studenten, Lehrer, Forscher, Unternehmer, kleine Unternehmen und multinationale Konzerne aus der ganzen Welt können der MonetDB-Community beitreten. Wir bieten Database-as-a-Service für CrateDB, das vollständig verwaltet wird. Tabellenspeicher erleichtert die Skalierung Ihrer Daten, da kein manuelles Sharding mehr erforderlich ist.
Dreimal werden die gespeicherten Daten einer Region mithilfe von georedundantem Speicher repliziert. Mit dem einfachen Datenmodell von Kudu ist es einfach, ältere Anwendungen zu portieren oder neue zu erstellen. Parquet ermöglicht die Angabe von Komprimierungsschemata pro Spalte und ist zukunftssicher, sodass bei Bedarf neue Komprimierungsschemata hinzugefügt werden können. Hypertable ist, wie der Name schon sagt, darauf ausgelegt, das Skalierbarkeitsproblem zu seinen eigenen Bedingungen zu lösen. Es wurde entwickelt, um OLAP-Workloads basierend auf dem spaltenorientierten DBMS InfiniDB zu unterstützen. Die Leistung der QikkDB bei Big Data und komplexen Polygonoperationen ist beispiellos. Die qikkDB-Datenbank ist mit den folgenden Merkmalen aufgebaut: Sie ist eine hochleistungsfähige, plattformübergreifende historische Zeitreihen-Datenbank in Spaltenform mit einer In-Memory-Compute-Engine.
Q, ein Streaming-Prozessor und eine Programmiersprache, soll es Ihnen ermöglichen, sich in Echtzeit auszudrücken. Sortierter Index, Bitmap-Index und invertierter Index sind die drei Indizierungstechnologien, die angeschlossen werden können. Apache Version 2.0 wurde für dieses Projekt lizenziert.
Spaltenorientierte Datenbanken sind die Zukunft
Eine große Anzahl von Datenbanken wurde in den letzten Jahren um Spalten herum entworfen. Da diese Datenbanken Daten in Zeilen und Spalten speichern, sind sie einfach zu verwenden und zu verwalten. Es sind mehrere spaltenorientierte Datenbanken verfügbar, darunter MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu, Apache Parquet, Hypertable und MonetDB. Dokument-, Diagramm- und Spaltendaten können innerhalb von DynamoDB mithilfe eines NoSQL-Datenbankmodells generiert werden. MongoDB, das Unternehmen hinter der Dokumentenspeicherdatenbank, kündigte die Veröffentlichung der Columnstore-Indizierung an, die es Entwicklern ermöglicht, analytische Abfragen in ihre Anwendungen einzubauen.
Beispiel einer spaltenförmigen Datenbank
Eine spaltenorientierte Datenbank ist ein Datenbanktyp, der Daten in Spalten statt in Zeilen speichert. Dieser Datenbanktyp wird häufig für Data Warehousing- und Analyseanwendungen verwendet, da er eine bessere Leistung und Skalierbarkeit als eine herkömmliche zeilenbasierte Datenbank bieten kann. Ein Beispiel für eine spaltenorientierte Datenbank ist Apache HBase.
Datenbankoperationen unterscheiden sich von denen anderer Datenbanken dadurch, dass Spalten Informationen normalerweise in Zeilen verteilen. Die Fähigkeit, große Datenmengen zu analysieren, ist besonders attraktiv für spaltenorientierte Datenbanken. Dokumentenspeicher, die NoSQL-Datenbanken verwenden, haben in den letzten Jahren an Popularität gewonnen. Auch Graphdatenbanken erfreuen sich immer größerer Beliebtheit, weil sie immer mehr Menschen nutzen, weil sie hochgradig vernetzte Daten sehr genau abbilden können. Seit langem werden spaltenorientierte Datenbankverwaltungssysteme verwendet. Trotz der Tatsache, dass noch einige Implementierungen verfügbar sind, wurden mehrere Systeme entwickelt. Der Zugriff auf Transaktionsanwendungen unterscheidet sich typischerweise vom Zugriff auf andere Anwendungen. Diese Aufgabe würde in einer spaltenorientierten Datenbank viel langsamer ausgeführt als in einer herkömmlichen Datenbank .
Warum spaltenorientierte Datenbanken immer beliebter werden
Spaltenorientierte Datenbanken wie Cassandra, MariaDB und CrateDB werden immer beliebter als Datenspeicherlösungen für Anwendungen, die große Datenmengen verarbeiten. Da Daten in einer Datenbank mit mehreren Zeilen derselben Tabelle (Spaltenfamilie) gespeichert werden können, ist es einfacher, Daten zu speichern und die Leistung zu verbessern.
Es stehen mehrere spaltenorientierte Datenbanken wie MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu und Apache Parquet zur Verfügung. Alle diese Datenbanken sind Open Source und wurden erfolgreich in einer Vielzahl von Anwendungen eingesetzt.