
Die 21. beliebteste Datenbank der Welt: Neo4j
Veröffentlicht: 2022-11-18Neo4j ist eine kostenlose Open-Source-Grafikdatenbank, die in Java geschrieben wurde. Es ist als transaktionale eingebettete Java-Datenbank mit vollständiger ACID-Semantik implementiert, kann aber auch als eigenständiger Server bereitgestellt werden. Neo4j ist laut DB-Engines die beliebteste Graphendatenbank und war im Dezember 2016 die 21. beliebteste Datenbank der Welt insgesamt. Neo4j wird von Unternehmen wie eBay, Adobe, Telenor und UBS verwendet. Es wird auch in vielen Open-Source-Projekten wie Apache Drill, Apache Kafka und Metronome verwendet. Neo4j wurde als „NoSQL“-Datenbank beschrieben, da es nicht das relationale Modell verwendet, sondern die SQL-ähnliche Abfragesprache Cypher verwendet.
Eine Graphdatenbank ist eine Datenbank, die Java als primäre Quelle verwendet. Wie im vorhergehenden Artikel erwähnt, ist das Ziel dieser Arbeit, einen Überblick über die aktuelle Position von Graphdatenbanken in der NOSQL -Bewegung zu geben. Gemäß der CAP-Theorie gibt es nur zwei der drei verschiedenen Aspekte des Scaling-Outs, die gleichzeitig durchgeführt werden können. Mehrere NOSQL-Datenbanken haben zusätzlich zu den oben genannten die Anforderungen an die Konsistenz gelockert, um eine bessere Verfügbarkeit und Partitionierung zu erreichen. Diese Transaktionen sind nicht klassisch und führen Einschränkungen für Datenmodelle ein, um bessere Partitionsschemata zu ermöglichen. ORM-Schichten wie Hibernate für Java haben gemischte Ergebnisse erzielt. Es bringt keinen Vorteil, das Objektmodell leichter dem relationalen Datenmodell zuzuordnen, aber die Abfrageleistung ist schlecht.
Graphen sind eine Alternative zur relationalen Normalisierung, die erhebliche Auswirkungen auf rekursive Strukturen wie Dateibäume und Netzwerkstrukturen hat. Eine beträchtliche Anzahl von Problemen mit der Graphentheorie wurde gelöst und wird immer noch in einer Vielzahl von Disziplinen gelöst. Heutzutage werden viele Arten von Graphentheoriealgorithmen verwendet, darunter Küstenwegberechnungen, geodätische Wegberechnungen und Maße wie Zentralität, Eigenvektorzentralität und Nähe. Es ist fast ein Jahrzehnt her, seit eine produktionsreife Graphdatenbank-Implementierung erstmals veröffentlicht wurde. Es ist in der Lage, Diagramme mit mehreren Milliarden Knoten, Beziehungen und Eigenschaften zu verarbeiten, ohne dass Programmierkenntnisse erforderlich sind. Es gibt kein festgelegtes Verfahren zum Verbinden in RDBMS, und es gibt keine festgelegten Vorgänge, die die Leistung beeinträchtigen. Wie Sie sehen können, ähnelt die Java-Implementierung dieser.
Das Erstellen einer neuen Graphdatenbank ist so einfach wie das Eingeben von java enum in einen Ordner namens target/neo. Die Traverser-API bietet eine viel ausgefeiltere Möglichkeit, den Matrixgraphen abzufragen, und ermöglicht eine viel breitere Palette von Traversalbeschreibungen und Filtern. Um dies programmgesteuert zu erreichen, können wir die Tiefe unserer Traversierung auf zwei begrenzen, indem wir den StopEvaluator für unseren Traversaltraverser anpassen. Es kann eine Liste von Beziehungen geben, die gekreuzt werden können, sowie die Arten und Richtungen dieser Beziehungen. Die Transaktion wird umschlossen, sodass alle Änderungen am Diagramm oder die Notwendigkeit von Isolationsstufen für Daten ohne Programmierung durchgeführt werden können. Es ist eine Graph-Programmiersprache, die für eine Vielzahl von Graph-bezogenen Projekten entwickelt wurde. Die Verwendung einer Vielzahl von Verfahren zum Konstruieren von Indexstrukturen in dem Graphen reduziert Traversierungsmuster für spezielle Datensätze und Domänen.
Mit Neo4j ist es möglich, eine Vielzahl von textbasierten Suchen durchzuführen, einschließlich solcher, die Lucene und Solr verwenden. Darüber hinaus kann es beliebige Knoteneigenschaften in Lucene/Solr mit Transaktionssemantik indizieren. Die Programmiersprache Gremlin ist eine XPath-orientierte, Turing-vollständige Graph-Programmiersprache, die XPath und Turing kombiniert. Da die meisten existierenden Modelle eine Obermenge und am häufigsten Dominatoren mit dem Property Graph Model sind, führt es eine Obermenge und am seltensten Dominator ein. Mit der JUNG-Bibliothek kann ein Graph-Framework (z. B. Gremlin) mit den anderen verknüpft und ein Graph-Traversal auf verschiedenen Implementierungen ausgedrückt werden. Graphen können wie RDBMS und andere Persistenzlösungen nur verwendet werden, wenn ein Problem dies erfordert. Die Daten sind der wichtigste Aspekt, und es ist wichtig zu verstehen, wie die Abfragen und Operationen ausgeführt werden. Nicht-relationale Lösungen als alleinige Begründung für den Einsatz von NOSQL-Datenbanken heranzuziehen, ist häufig weder wünschenswert noch notwendig.
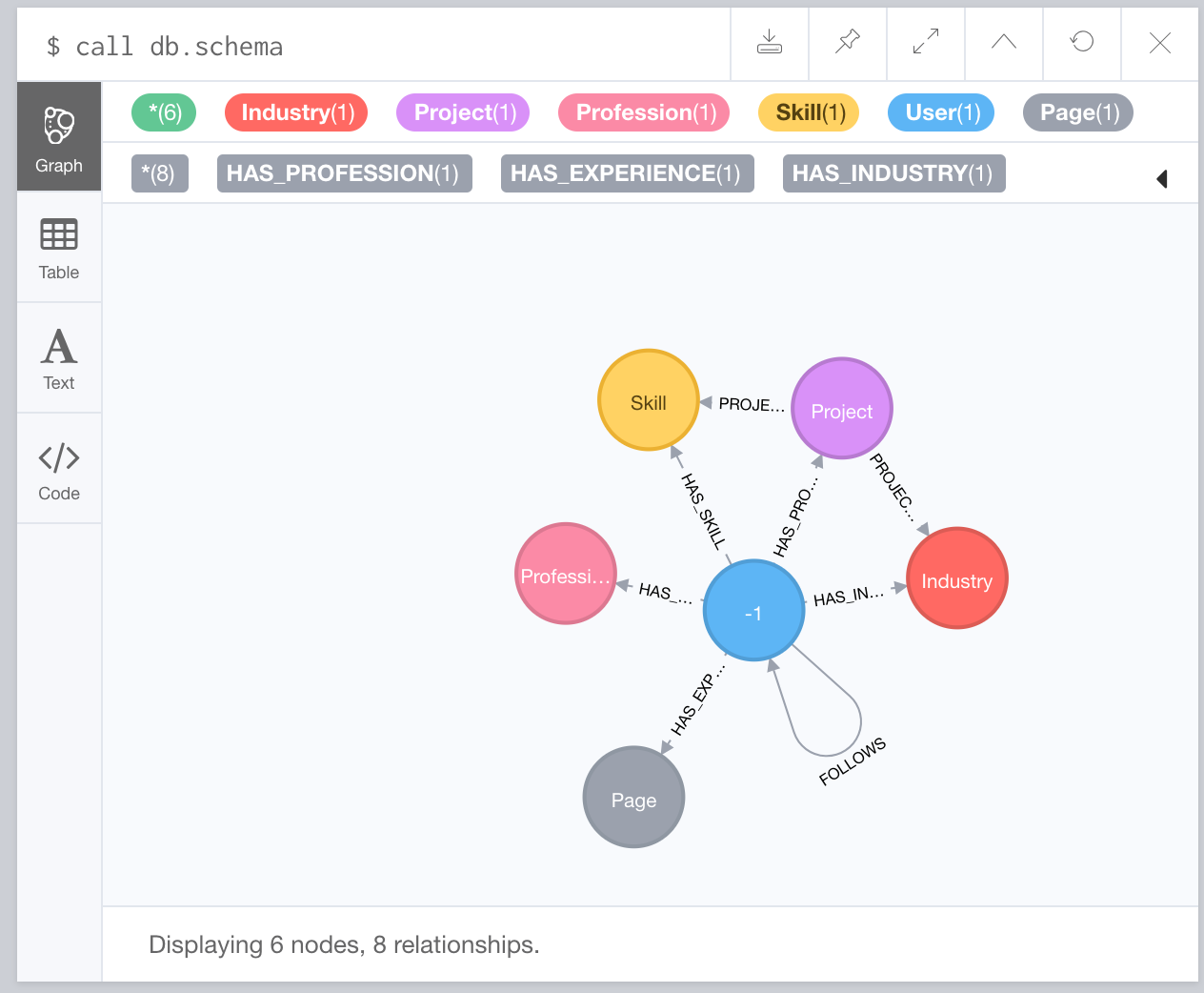
Die folgenden Merkmale definieren einen Neo4j-Eigenschaftsgraphen . Knoten und Beziehungen sind darin zu finden. Beziehungen sind benannt und gerichtet und haben immer einen Start- und Endknoten mit einer Reihe von Eigenschaftspaaren (Schlüssel-Wert-Paaren).
Auf SQL kann darüber nicht zugegriffen werden.
Neo4j kann eine Vielzahl von Datenbanken verwalten und ist damit ein Datenbankmanagementsystem (DBMS). Ein DBMS kann sowohl eigenständige Server als auch Gruppen von Servern in einem kausalen Cluster verwalten. Die Neo4j-Instanz ist ein Java-Prozess, der versucht, den Servercode von Neo4j auszuführen.
Die Graphdatenbank Neo4j eignet sich hervorragend zur Modellierung komplexer Zusammenhänge, da sie blitzschnell durch große Datenmengen laufen kann.
Welche Art von Datenbank ist Neo4j?
Seit 2007 können Sie Neo4j, eine Open-Source- NoSQL-Datenbank mit einem ACID-konformen Transaktions-Backend, als Teil Ihrer Anwendungen verwenden.
Die Neo4j Graph Database ist die weltweit führende Open-Source-Datenbank. Es ist in Java geschrieben und kostenlos. Eine abstrakte Darstellung einer Menge von Objekten, bei der einige Objektpaare durch eine Verknüpfung verbunden sind. Unter Verwendung einer ASCII-Art-Syntax verwendet die deklarative Abfragesprache Neo4j, um den Graphen visuell darzustellen. Sie müssen KEINE komplexen Verknüpfungen durchführen, um verknüpfte/zusammenhängende Daten abzurufen. ACID-Regeln (Atomizität, Konsistenz, Isolation und Dauerhaftigkeit) sind in Neo4j integriert. Es kann die Datenbank skalieren, indem es die Anzahl der Lese-/Schreibvorgänge und das Volumen erhöht, ohne die Abfrageverarbeitungsgeschwindigkeit oder Datenintegrität zu beeinträchtigen.
Welche Art von Nosql-Datenbank ist Neo4j?
Neo4j ist ein von Neo4j, Inc. entwickeltes Verwaltungssystem für Graphdatenbanken. Von seinen Entwicklern als ACID-konforme Transaktionsdatenbank mit nativer Graphspeicherung und -verarbeitung beschrieben, ist Neo4j laut DB-Engines-Ranking die beliebteste Graphdatenbank und die 21. beliebteste Datenbank insgesamt.
Viele große Unternehmen wie eBay, Wal-Mart und Cisco haben damit begonnen, Graphdatenbanken zur Implementierung von Big-Data-Analysen zu verwenden. Da traditionelle Datenbanken nicht in der Lage sind, große Mengen komplexer Daten zu verarbeiten, können sie die Informationen nicht in großer Zahl sichten. Infolgedessen sind transaktionale Commits und Rollbacks in Neo4j alles oder nichts, wenn Datenbankoperationen durchgeführt werden. Diese Datenbank enthält die folgenden Merkmale: große Skalierbarkeit, Flexibilität, Konsistenz und Blitzgeschwindigkeit. Da MongoDB Open BSON (Binary JavaScript Object Notation) unterstützt, können wir Dokumente in diesem Format erstellen. Aufgrund seiner Geschwindigkeit und Fähigkeit, Daten hin und her zu übertragen, ist MongoDB eine beliebte Wahl für große Organisationen, die mit Dokumenten im Petabyte-Bereich zu tun haben. Eine Graphdatenbank wird als NoSQL-Datenbank bezeichnet, während eine Neo4j NoSQL-Datenbank als NoSQL-Datenbank bezeichnet wird. (

Membrey, Hows, 2014). MongoDB speichert binäre Daten bis zu 4 MB pro Dokument in der GridFS-Implementierung (Membrey, Hows, 2014). Datenbankversionen werden in CouchDB gepflegt.
NoSQL-Datenbanken speichern wie herkömmliche Datenbanken Daten nicht in Tabellen oder Zeilen, sondern in Sammlungen von Dokumenten. Ihre Fähigkeit, mehr Daten kompakter zu handhaben, ermöglicht es ihnen folglich, größere Datenmengen effizienter zu handhaben. Viele große Unternehmen, darunter Facebook, Google und LinkedIn, verwenden MongoDB als NoSQL-Datenbank.
Ist Graph Database Sql oder Nosql?
Graphdatenbanken speichern Daten im Allgemeinen als Netzwerke unter Verwendung eines NoSQL-Datenbankmodells .
Es wurde 2010 als eine Technologie eingeführt, mit der Daten in extrem großen Mengen verwaltet werden können, unabhängig davon, ob sie strukturiert, halbstrukturiert oder unstrukturiert sind. Es unterstützt Organisationen bei der Integration, Analyse und dem Zugriff auf Daten aus einer Vielzahl von Quellen und ermöglicht es ihnen, den Wert ihrer großen Daten- und Social-Media-Analyseinitiativen zu extrahieren. Eine NoSQL-Graphdatenbank muss nicht neu definiert werden, bevor neue Daten hinzugefügt werden. Die von Graphdatenbanken verwendeten W3C-Standards stellen Daten im Internet dar, und die W3C-Standards wurden weltweit übernommen. Durch die Verwendung von Standardpraktiken werden Datenintegration, -austausch und -zuordnung vereinfacht. Es verbessert die Graphdatenbank, indem es neues Wissen schafft und es Organisationen ermöglicht, alle ihre Daten einheitlicher zu sehen. Organisationen können auch Semantic Technology und NoSQL verwenden, um soziale Medien zu analysieren.
Beziehungen zwischen Entitäten sind wichtig für Graphdatenbanken. Um dies zu erreichen, generiert MongoDB aus jedem Dokument ein Feld namens _id. Die Dokument-ID ist für das System eindeutig. Wenn das Dokument nicht explizit in der Dokumenthierarchie angegeben wurde, kann dieses Feld verwendet werden, um es zu finden.
Die Phase graphLookup in MongoDB macht es einfach, die Beziehungen zwischen Entitäten in einem MongoDB-System zu untersuchen. Sie können es verwenden, indem Sie zuerst einen kostenlosen MongoDB-Atlas-Cluster erstellen. Wenn Sie graphLookup aktivieren, können Sie auf eine MongoDB-Instanz mit aktivierter Phase zugreifen.
Der nächste Schritt besteht darin, mit MongoDB Atlas einen Cluster zu erstellen und in einem Terminalfenster zum Speicherort des Clusters zu navigieren. Die folgenden Befehle werden verwendet, um an die Arbeit zu kommen:
Eine Mongograph-Suche kann kostenlos von der Website heruntergeladen werden.
Die Beziehungen zwischen Entitäten in Ihrem System werden in diesem Befehl angezeigt. Die Knoten und Kanten eines Graphen können durch Anklicken erkundet werden.
Graphdatenbanken werden immer beliebter, da sie eine genauere Darstellung von Entitätsbeziehungen bieten. Wenn Sie die Phase graphLookup in MongoDB verwenden, können Sie leicht sehen, wie viele Entitäten miteinander verbunden sind.
Nosql vs. SQL: Welche Datenbank ist die bessere für Ihre API?
Graphdatenbanken werden immer beliebter, mit bemerkenswerten Beispielen wie Neo4J, GraphQL und MongoDB. Jede dieser Datenbanken hat ihren eigenen Satz von Tabellenstrukturen und Tools, aber alle haben eine Funktion, die das Speichern und Navigieren von Beziehungen ermöglicht. Wenn Sie eine NoSQL-Datenbank für Ihre API benötigen, ist GraphQL eine praktikable Option. Die SQL-Abfragesprache ist die beste Wahl, wenn Sie SQL-Abfragen auf einem relationalen Datenbanksystem durchführen möchten.
Sind Graphdatenbanken Nosql?
Die Graphdatenbank NoSQL („nicht nur SQL“) kann extrem große Mengen strukturierter, halbstrukturierter oder unstrukturierter Daten verarbeiten. Organisationen können es verwenden, um Daten aus verschiedenen Quellen zu analysieren und darauf zuzugreifen, was die Entwicklung von Big Data und Social-Media-Analysen unterstützt.
Dies ist eine andere Möglichkeit zum Speichern von Daten als reguläres SQL, auch bekannt als NoSQL. Graphdatenbanken können verwendet werden, um große Datenmengen zu speichern, schnell mit sich ändernden Anforderungen zu iterieren und schnell zu skalieren. In diesem Artikel gehen wir auf die grundlegenden Funktionen von NoSQL-Graphdatenbanken ein. Ein gerichteter Graph, wie durch diese Gleichung definiert, ist eine Graphbeziehung, die in die Richtung zeigt, in der sie gezeichnet wurde. Zyklische Graphen sind beliebte Graphalgorithmen, aber Zyklen können dazu führen, dass sie an Ort und Stelle hängen bleiben und sich endlos wiederholen. Ein Spannbaum ist ein Baum, bei dem alle Knoten in einem Diagramm und alle Beziehungen entfernt sind, wodurch Zyklen aus dem Diagramm entfernt werden. Es ist wichtig, die Eigenschaften von Diagrammen zu verstehen, um die besten Algorithmen und Strukturen für Ihre Anwendung zu implementieren. Die Verwendung von NoSQL-Grafikdatenbanken ist entscheidend für die Verwaltung großer Datenmengen, schnelle agile Iterationen und die Skalierung. Graphformen, Dichte und Eigenschaften wie Verbundenheit, Richtung, Gewichte und Zyklen wurden eingehend untersucht.
Große Unternehmen setzen zunehmend NoSQL-Datenbanken ein, da sie es ihnen ermöglichen, Daten zu speichern, die normalerweise nicht in relationalen Datenbanken zu finden sind. DynamoDB, Riak und Redis sind Schlüsselwertspeicher, die Daten sortiert verarbeiten und in sortierten Sätzen anzeigen. Dadurch können Daten darin abgelegt werden, die unstrukturiert sind oder ständig aktualisiert werden müssen.
Vergleich von Apache Accumulo und Mongodb
In der Apache Accumulo-Bibliothek werden Schlüsselwerte in Spalten gespeichert, was sie zu einem verteilten, hochleistungsfähigen, spaltenorientierten Schlüsselwertspeicher macht.
Es ist eine dokumentenorientierte Datenbank, die Daten in einem Diagrammformat speichert.
Nosql Graph-Datenbank
Eine NoSQL-Graphdatenbank ist eine Datenbank, die Graphstrukturen zum Speichern von Daten verwendet. NoSQL-Graphdatenbanken werden häufig für Anwendungen verwendet, die ein hohes Maß an Flexibilität und Echtzeitzugriff auf Daten erfordern.
Datenbank mit Diagrammen ist eine Art von Datenbank, die zur Darstellung von Daten verwendet wird. Diese Art von Datenbank wird allgemein als NoSql-Datenbank bezeichnet, da ihre Daten in Knoten, Beziehungen und Eigenschaften und nicht in herkömmlichen Datenbanken gespeichert werden. Graphdatenbanken wie Neo4j, Oracle DB und Graphbase sind für die Verwendung mit NoSQL-Datenbanken verfügbar. Aufgrund der Verbindungen zwischen Daten und Diagrammen können Benutzer mithilfe von Diagrammdatenbanken Traversal-Abfragen durchführen. Graphalgorithmen werden auch verwendet, um Muster, Pfade und andere Beziehungen zu finden, die eine gründlichere Analyse der Daten unterstützen. Daten können auf vielfältige Weise in einer Graphdatenbank gespeichert werden, aber sie kann die traditionelle Datenbank nicht vollständig ersetzen.
Apache Spark: Die Zukunft des maschinellen Lernens und der Big-Data-Verarbeitung
Apache Spark ist ein Framework für maschinelles Lernen und Big-Data-Verarbeitung, das auf Apache basiert. Diese Engine kann große Graph-Datenbanken schnell und effizient abfragen, da es sich um eine Graph-Verarbeitungs-Engine handelt.