
Um einen Wert abzurufen, verwenden Sie die Get()-Methode, die Hash-Tabellen verwendet, um Daten in einer NoSQL-Datenbank zu speichern
Veröffentlicht: 2022-12-04Eine Hash-Tabelle ist eine Datenstruktur, die Schlüssel-Wert-Paare speichert. Es ist eine einfache Möglichkeit, Daten in einer NoSQL-Datenbank zu speichern. Der Schlüssel wird verwendet, um den Wert in der Tabelle nachzuschlagen. Der Wert kann beliebig sein, einschließlich einer anderen Datenstruktur. Hash-Tabellen werden häufig zum Speichern von Daten in einer NoSQL-Datenbank verwendet, da sie einfach und effizient sind. Sie können verwendet werden, um Daten jeden Typs zu speichern, einschließlich Strings, Integers, Floats und Objekte. Hash-Tabellen werden auch als Hash-Maps oder Wörterbücher bezeichnet. Um eine Hash-Tabelle zu verwenden, müssen Sie zuerst eine Tabelle erstellen. Tabellen werden mit der Methode createTable() erstellt. Das erste Argument ist der Name der Tabelle und das zweite Argument ist die Hash-Funktion . Die Hash-Funktion wird verwendet, um Schlüssel auf Werte abzubilden. Nachdem eine Tabelle erstellt wurde, können Sie mit der Methode put() Daten darin einfügen. Das erste Argument ist der Schlüssel und das zweite Argument der Wert. Um einen Wert abzurufen, verwenden Sie die Methode get(). Das erste Argument ist der Schlüssel und das zweite Argument ist der Standardwert. Der Standardwert wird zurückgegeben, wenn der Schlüssel nicht in der Tabelle gefunden wird. Hash-Tabellen sind eine einfache und effiziente Möglichkeit, Daten in einer NoSQL-Datenbank zu speichern. Um eine Hash-Tabelle zu verwenden, müssen Sie zuerst eine Tabelle erstellen. Nachdem eine Tabelle erstellt wurde, können Sie mit der Methode put() Daten darin einfügen.
Was ist Hashing in Nosql?
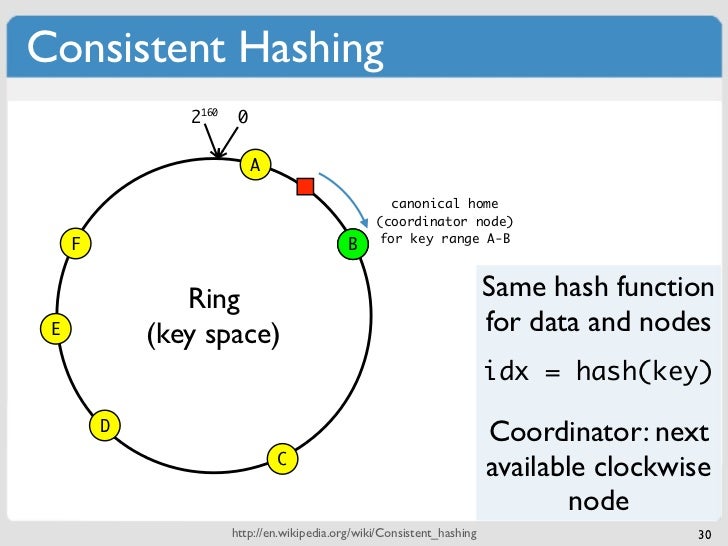
Hashing ist eine Technik zum Indizieren und Abrufen von Elementen in einer Datenbank oder Datenstruktur. Es funktioniert, indem der Schlüssel des Elements in einen Hash umgewandelt wird, der dann verwendet wird, um das Element in der Datenbank oder Datenstruktur zu indizieren.
Die Vorteile von Nosql-Datenbanken
NoSQL-Datenbanken sind derzeit der heißeste Trend in der Technologie. Aufgrund ihrer horizontalen Skalierungsfähigkeiten eignet sie sich besser für große Datenmengen als eine herkömmliche relationale Datenbank. Wenn Sie nach einer großen Datendatenbank suchen, die Ihren wachsenden Datensatz verarbeiten kann, sollten NoSQL-Datenbanken ganz oben auf Ihrer Liste stehen.
Kann Nosql Tabellen haben?
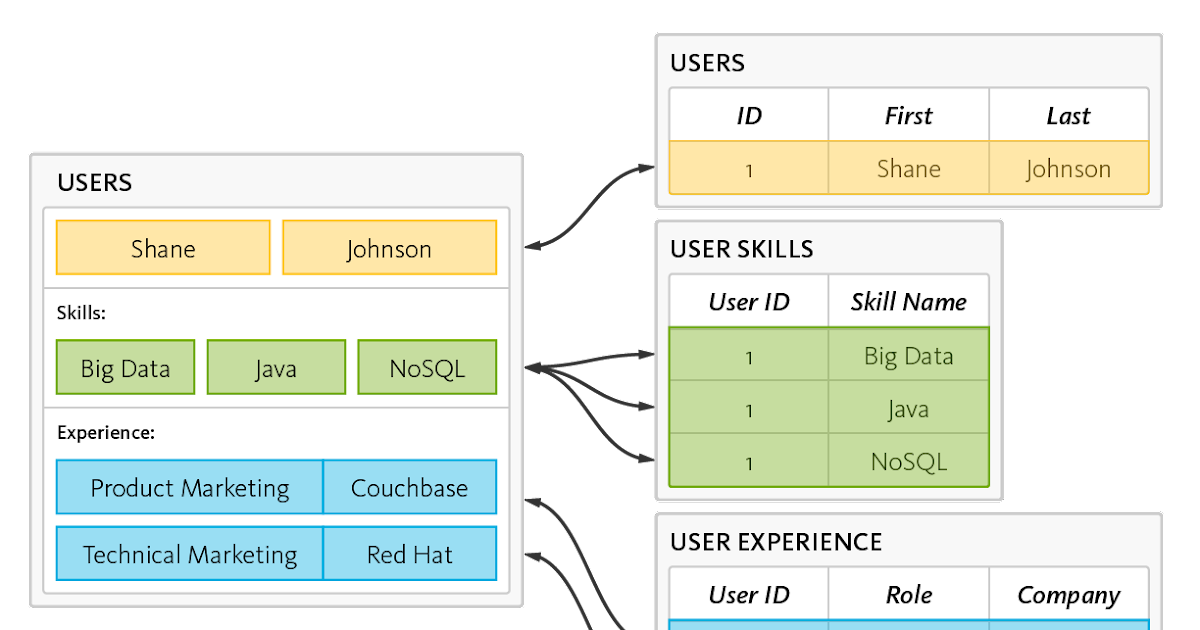
Es gibt kein festgelegtes Format für jedes Dokument. Datenbank mit RDBMS-ähnlichen Zeilen und Spalten: NoSQL -Datenbanken mit breiten Spalten speichern Daten in Tabellen mit RDBMS-ähnlichen Zeilen und Spalten, aber Namen und Formate variieren von Zeile zu Zeile. Datenbankspalten, die miteinander verwandte Spalten enthalten, werden in Datenbanken mit großen Spalten zusammengefasst.
NoSQL hat 2011 ein starkes Comeback erlebt und ist zum nächsten großen Ding in der Systemarchitektur aufgestiegen. Die NoSQL-Datenbank ist in verschiedenen Varianten erhältlich: Einige von ihnen speichern sogar im Tabellenformat. Beziehungen zwischen Daten können nicht hergestellt werden, und allen gemeinsam ist, dass sie dies nicht tun. Selbst wenn Sie eine NoSQL-Datenbank verwenden, ist SQL nicht erforderlich. Eine NoSQL-Datenbank und eine SQL-Datenbank können möglicherweise koexistieren. NoSQL unterscheidet sich von herkömmlichen Ansätzen in Bezug auf Atomarität, Konsistenz, Isolation und Dauerhaftigkeit. Mithilfe von Sharding können Sie einige Daten an eine nicht vertrauenswürdige Gerichtsbarkeit und andere Daten an eine vertrauenswürdige Gerichtsbarkeit senden, da die Daten sicher verschlüsselt sind. Durch die Verwendung von Sharding in NoSQL-Datenbanken, die es mehreren Computern ermöglichen, Daten gleichzeitig zu verarbeiten, können Daten zur richtigen Zeit am richtigen Ort platziert werden.
Sie sind ideal zum Speichern von Daten, die sich im Laufe der Zeit nicht stark oder sehr schnell ändern. Ein Backup von einem anderen Server im Netzwerk kann auch kopiert werden, da die Daten nur eine einzige Datei sind. Trotz der Vorteile herkömmlicher Datenbanken erfordern viele Anwendungen immer noch die Art von Beschränkungen, Konsistenz und Sicherheitsvorkehrungen, die eine herkömmliche Datenbank bietet. Die Neuartigkeit von NoSQL-Datenbanken wurde längst von traditionellen relationalen Datenbanken übertroffen. Die Implementierung einer NoSQL-Datenbank kann schwierig sein und erfordert ein hohes Maß an Management und Anbieter. Da NoSQL-Datenbanken immer beliebter werden, wächst die Nachfrage nach NoSQL-Fähigkeiten, da große Unternehmen Hochgeschwindigkeitsdaten benötigen. Wenn Sie helfen können, die relationale oder nicht-relationale Datenbank eines anderen Unternehmens zu unterstützen, könnten Sie ein gutes Gehalt verdienen.
Wie heißen Tabellen in Nosql?
NoSQL-Datenbanken (auch bekannt als SQL) können Daten auf andere Weise speichern als relationale Datenbanken und werden daher normalerweise nicht zum Speichern von Daten in einer Tabelle verwendet. Im Allgemeinen bestehen NoSQL-Datenbanken basierend auf ihren Datenmodellen aus einer Reihe von Datentypen. Dokumenttypen, Schlüsselwerttypen, Breitspaltentypen und Diagrammtypen sind die häufigsten.
Mongodb-Sammlungen: A Prime
Bei MongoDB-Sammlungen sind einige Dinge zu beachten. Datenbankobjekte sind Sammlungen, die in einer Datenbank gespeichert werden. Zur Erstellung stehen sowohl der Mongo-Shell-Befehl als auch der MongoDB-Treiber für PHP zur Verfügung.
Datenbanktabellen können nicht zum Erstellen von Sammlungen verwendet werden. Es ist unmöglich, Daten in eine Sammlung so einzufügen, wie sie in eine Tabelle eingefügt werden können. Anstatt Daten mit ihren Methoden in die Sammlung einzufügen, fügen Sie sie mit den Methoden der Sammlung ein.
Der Zugriff auf ein Dokument in einer Sammlung ist möglich, indem sein Name als Parameter für die Find-Methode des Dokuments verwendet wird.
Auf ein Dokument kann auch von einer Sammlung zugegriffen werden, in der es sich befindet. Der Pfad enthält einen Schrägstrich, gefolgt vom Sammlungsnamen und dem Dokumentnamen.
Eine Sammlung unterscheidet sich von einer Tabelle darin, dass Dokumente in einer Sammlung möglicherweise nicht immer in chronologischer Reihenfolge organisiert sind. MongoDB betrachtet den Dokumentenindex als Maß für die Reihenfolge, in der Dokumente in einer Sammlung organisiert sind, wenn der Index berechnet wird.
Ein Dokument kann in eine Sammlung eingegeben werden, indem Sie dem Code im folgenden Beispiel folgen. Anschließend erstellt der Code eine neue Sammlung und fügt ein Dokument darin ein.
*br* Erstellen Sie eine neue Sammlung von Grund auf neu. Die var-Sammlung wird verwendet, um die Sammlung darzustellen. MongoDB() fügt alternativ eine Collection in myCollection hinzu.
Dies kann erreicht werden, indem Sie es aus dem Dropdown-Menü der Sammlung auswählen. Eingefügt. Der Name des Mannes ist John. Ich bin 27 Jahre alt.
Können Sie Nosql-Tabellen beitreten?
Eine gemeinsame Klausel kombiniert Zeilen aus zwei oder mehr Tabellen, indem sie eine zugehörige Spalte zwischen ihnen verwendet. Wenn ein Benutzer versucht, Daten aus Tabellen zu extrahieren, die hierarchisch verknüpft sind, werden Joins normalerweise in Oracle NoSQL-Datenbanken verwendet.
Die Vor- und Nachteile von Nosql
NoSQL hingegen bietet eine Reihe von Vorteilen, darunter Skalierbarkeit, schneller Datenzugriff, einfache Entwicklung und niedrige Wartungskosten.
Wie wird die Hash-Tabelle in der Datenbank verwendet?
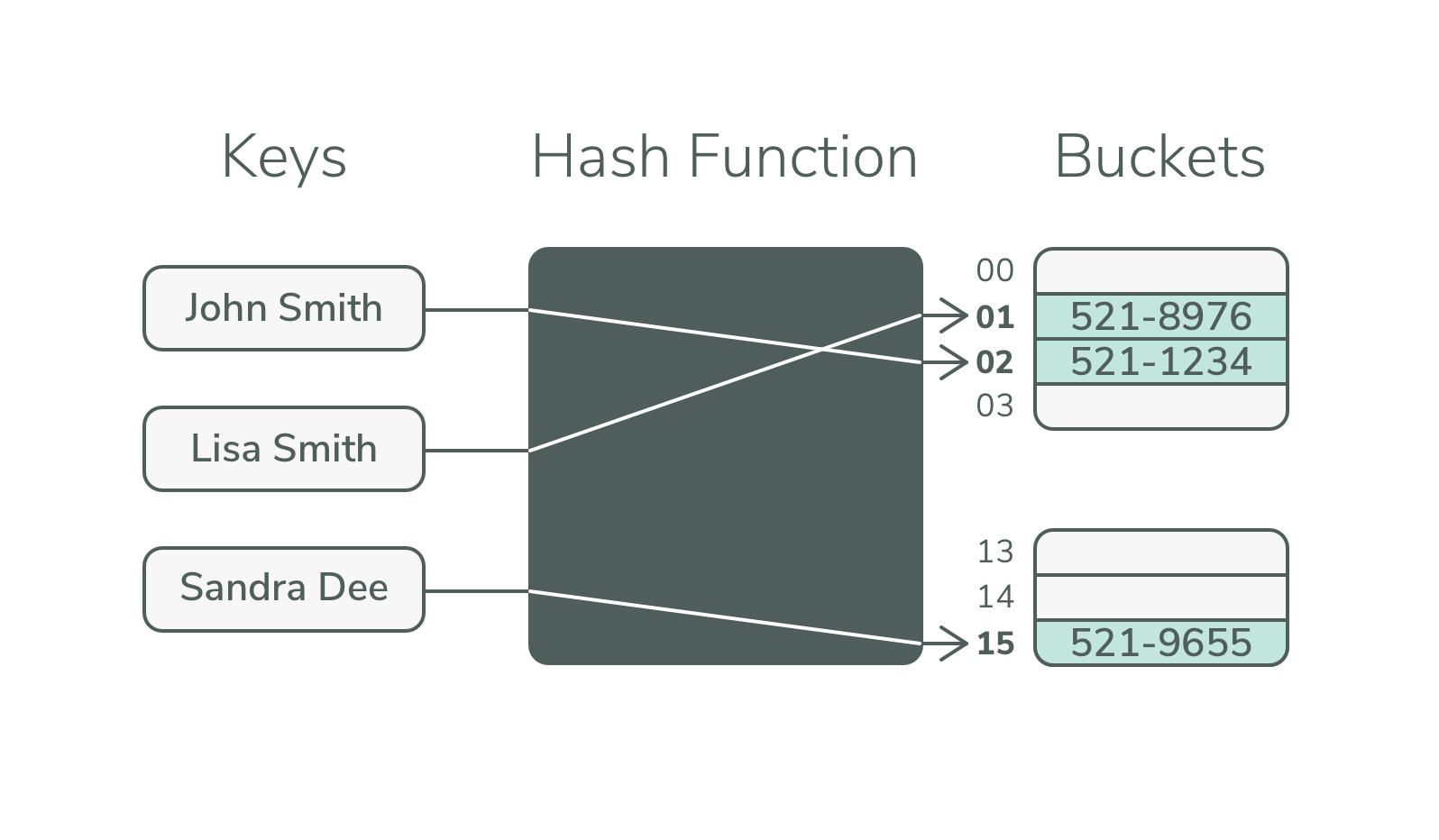
Eine Hash-Tabelle speichert Daten in einer Datenstruktur, die eine Kombination aus Schlüsseln und Wertepaaren ist. Es berechnet einen Index, indem es eine Hash-Funktion verwendet, um ein Element in einem Array zu platzieren, wo es eingefügt oder gesucht werden kann. Wenn Sie die richtige Hash-Funktion verwenden , können die Ergebnisse ausgezeichnet sein.
Die Hash-Technik kann verwendet werden, um ein bestimmtes Objekt zu identifizieren, indem eine Gruppe ähnlicher Objekte untersucht wird. Durch die Verwendung von Hash-Funktionen können die großen Schlüssel in kleine Schlüssel umgewandelt werden. Danach werden die Werte in einer als Hash-Tabelle bezeichneten Datenstruktur gespeichert. Eine Hashing-Methode wird in zwei Phasen entwickelt: Initialisieren und Validieren. Der Hash-Schlüssel wird verwendet, um das Element schnell aus der Hash-Tabelle abzurufen. Eine Hash-Tabelle ist eine Datenstruktur, die Schlüssel/Wert-Paare speichert. Der Index wird mithilfe einer Hash-Funktion berechnet, die verwendet wird, um einen Index für jedes Paar von Schlüsseln oder Werten zu berechnen.

Der Index einer bestimmten Zeichenkette ist gleich der Summe der ASCII-Werte multipliziert mit ihrer jeweiligen Reihenfolge in der Zeichenkette, wonach sie zu Modulo (2069) wird. Eine der häufigsten Kollisionsauflösungstechniken ist Hashing. Typischerweise wird es durch das Verknüpfen von Listen implementiert. Eine verknüpfte Liste ist in jedem Element einer Hash-Tabelle als Teil ihrer Verkettung enthalten. Lookups kosten Geld, weil sie das Durchsuchen der Einträge in der verknüpften Liste nach dem erforderlichen Schlüssel erfordern. Bei der Hash-Funktion wird eine Ganzzahl im Bereich von 0 bis 19 zurückgegeben. Bei der Verwendung offener Adressen anstelle von verknüpften Listen werden alle Eintragsdatensätze im Array selbst gespeichert.
Eine offene Adresse ist ein Name, der darauf hinweist, dass der Ort oder die Adresse eines Elements nicht durch den Hash-Wert des Elements bestimmt wird. Lineare Sonden werden verwendet, um die Hash-Kollisionen bei der offenen Adressierung zu lösen. Der CodeMonk- und der Hashing-Index werden auf denselben Index gehasht (dh 2, also sollte Hashing in diesem Fall bei 3 liegen), und das Intervall zwischen aufeinanderfolgenden Sonden muss eins sein. Angenommen, der gehashte Index für einen Eintrag ist index und es gibt einen besetzten Slot bei index. Wenn Sie noch keinen leeren Slot gefunden haben, müssen Sie zunächst eine bestimmte Sequenz durchlaufen.
Die Verwendung einer Hash-Tabelle in einer Datenstruktur ist eine kostengünstige Methode zum Speichern von Daten mit fester Größe. Sie eignen sich besonders gut für Operationen, die das Suchen eines Elements mit einem bestimmten Schlüssel, das Indizieren von Datenstrukturen usw. beinhalten. Eine Hash-Tabelle ist nicht für alle Operationen geeignet. Hash-Tabellen hingegen unterstützen nicht alle Elemente, deren Schlüssel in einem bestimmten Bereich liegen. Im Gegensatz dazu werden beim dynamischen Hashing Daten-Buckets nach Bedarf hinzugefügt und entfernt, ohne dass Änderungen erforderlich sind. Dies ermöglicht ein besseres Verständnis einiger Operationen, z. B. das Finden des Elements mit den größten oder kleinsten Schlüsseln. Im Durchschnitt ist der O(log n)-Teint nahezu farblos. Hash-Tabellen sind im Allgemeinen effizient, aber nicht für alle Datentypen. In einigen Fällen kann dynamisches Hashing eine bessere Lösung als statisches Hashing bieten, z. B. das Finden eines Elements mit dem höchsten oder kleinsten Schlüssel.
Wie wird Hashing in Datenbanken verwendet?
Die Hash-Methode indiziert und ruft Elemente aus Datenbanken ab, da es schneller ist, mit einem kürzeren Hash-Schlüssel nach einem bestimmten Element zu suchen, als den ursprünglichen Wert zu verwenden. Wenn Sie den Speicherort eines Datensatzes auf einer Festplatte suchen, ohne Indexstrukturen zu verwenden, ist Hashing eine hervorragende Möglichkeit, dies zu tun.
Verwendet SQL Hashtable?
Wenn SQL Server dies erfordert, generiert es seine eigenen Hashtabellen. Es ist unmöglich, eine Struktur wie einen Index oder ein indexbezogenes Programm zu erstellen. Beispielsweise wird der Hash-Join von SQL Server mithilfe von Hash-Tabellen ausgeführt.
Verwendet MySQL Hash-Tabellen?
Sowohl Hash-Indizes als auch Datenbanken können in MySQL verwendet werden, aber Hash-Indizes sind für die Datenbanknutzung langsamer. Da lange Schlüssel (insbesondere Zeichenketten) normalerweise nicht groß genug sind, um einen Index zu unterstützen, sind Hash-Indizes normalerweise nur sinnvoll, wenn sie mit langen Schlüsseln (insbesondere Zeichenketten) verwendet werden.
Was ist eine Hash-Tabelle in SQL?
Daten können assoziativ in einer Hash-Tabelle gespeichert werden. In einer Hash-Tabelle ist der Indexwert jedes Datenwerts ein eigener, der in einem Array-Format gespeichert wird. Wir können viel schneller auf Daten zugreifen, wenn wir verstehen, was im Index der gewünschten Daten steht.
Können wir Nosql für Transaktionen verwenden?
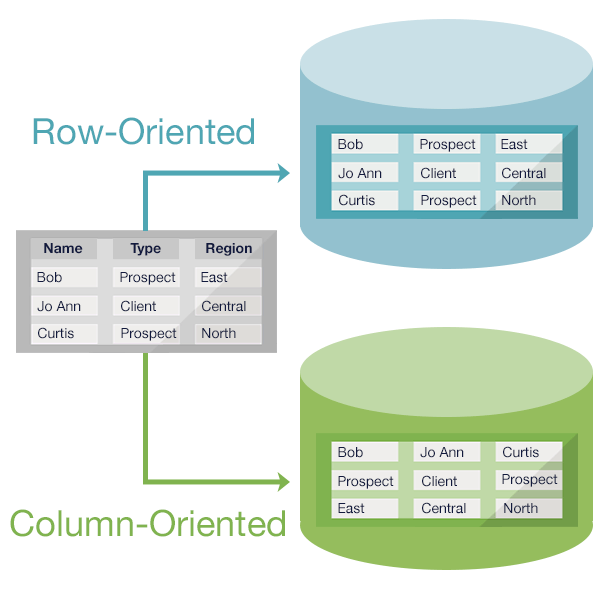
Transaktionen mit mehreren Schlüsseln werden von NoSQL-Datenbanken nicht unterstützt. Mehrere Datenelemente werden atomar gruppiert und in einem einzigen Vorgang verarbeitet, sodass Sie mehrere Transaktionen mit mehreren Schlüsseln durchführen können. Eine NoSQL-Datenbank ist typischerweise so strukturiert, dass jeder Tastenoperation eine einfache Put- und Get-Operation folgt.
NoSQL-Lösungen haben eine geringere transaktionale Semantik als relationale Datenbanken, können aber auf einer gewissen Ebene atomare Operationen aufnehmen. Wenn Sie mit Node.js oder Ruby/Rack vertraut sind, können Sie mit Heroku.com schnell ein kleines Modell erstellen. Ich möchte mich dafür entschuldigen, dass ich es noch nicht implementiert habe. Die Eigenschaften von Datenbankverwaltungssystemen werden benötigt, um Transaktionen zu verarbeiten. Die meisten NoSQL-Tools verbessern die Konsistenzkriterien der Operationen, um Fehlertoleranz und Skalierungsverfügbarkeit sicherzustellen. Erwägen Sie die Verwendung von speicherinternen, spaltenorientierten und verteilten Datenbanken wie VoltDB. Sie können 'Optimistische Transaktionen' verwenden, um dies zu erreichen, aber ich würde Ihnen raten, sicherzustellen, dass Sie die Atomaritätsgarantien der Datenbankimplementierung verstehen (z. B. welche Art von Schreib- und Leseoperationen atomar sind).
Gibt es Diskussionen über HBase-Transaktionen im Netz? Im Allgemeinen verwendet NoSQL Schlüssel/Wert-Datenspeicher: Sie können dies in Ihrem bevorzugten RDBMS verwenden und die guten Dinge wie Transaktionen, ACID-Eigenschaften und DBA-Unterstützung behalten, während Sie die Vorteile der Leistung und Flexibilität von NoSQL nutzen. Wenn die Compare-and-Set-Funktion aktiviert ist, können optimistische Transaktionen zusätzlich zu NoSQL-Lösungen implementiert werden.
Welche Datenbank eignet sich am besten für Transaktionen?
SQL-Datenbanken sind wahrscheinlich die effektivste Option in Fällen, in denen die überwiegende Mehrheit Ihrer Daten strukturiert ist. Beim Einsatz in transaktionsorientierten Systemen wie Customer-Relationship-Management-Tools, Buchhaltungssoftware oder E-Commerce-Plattformen sind SQL-Datenbanken eine gute Wahl.
Wann sollte Nosql nicht verwendet werden?
Wenn Sie für Ihre Anwendung eine flexible Laufzeitflexibilität benötigen, sollten Sie NoSQL ebenfalls vermeiden. Wenn es auf Konsistenz ankommt und keine großen Änderungen des Datenvolumens erfolgen sollen, sind SQL-Datenbanken die bessere Wahl.
Was sind die Einschränkungen von Nosql?
Was sind die Vor- und Nachteile der NoSQL-Datenbanktechnologie ? Einer der Hauptnachteile von NoSQL-Datenbanken besteht darin, dass sie keine ACID-Transaktionen (atomar, konsistent, isoliert und haltbar) über mehrere Dokumente hinweg unterstützen. Wenn ein Schema richtig entworfen ist, kann man davon ausgehen, dass Einzeldatensatz-Atomizität für eine Vielzahl von Anwendungen möglich ist.
Was gilt nicht für Nosql?
Was sind die verschiedenen Arten von NoSQL-Datenbanken und wie werden sie verwendet? Die Microsoft SQL Server-Plattform verwaltet und vereinfacht eine Vielzahl von Datenbankanwendungen.
Nosql-Datenbankbeispiel
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die kein festes Schema benötigt. NoSQL-Datenbanken werden häufig für die Handhabung großer Mengen unstrukturierter Daten verwendet. Ein Beispiel für eine NoSQL-Datenbank ist MongoDB. MongoDB ist ein kostenloses und plattformübergreifendes dokumentenorientiertes Open-Source-Datenbankprogramm. Als NoSQL-Datenbankprogramm klassifiziert, verwendet MongoDB JSON-ähnliche Dokumente mit Schemas.
Eine NoSQL-Datenbank, auch bekannt als Big Data Store, hat eine Reihe von Vorteilen gegenüber einer herkömmlichen relationalen Datenbank, wie z. B. Skalierbarkeit, Leistung und die Fähigkeit, eine große Anzahl von Objekten zu verarbeiten.
Das Wachstum von NoSQL-Datenbanken wurde durch mehrere Faktoren vorangetrieben, darunter ihre Skalierbarkeit, Leistung und Fähigkeit, eine große Anzahl von Objekten zu verarbeiten.
So erstellen Sie eine Hash-Tabelle in SQL Server
Eine Hash-Tabelle ist eine Datenstruktur, die zum Speichern von Schlüssel-Wert-Paaren verwendet wird. In SQL Server ist eine Hashtabelle als Tabelle mit zwei Spalten implementiert, eine für die Schlüssel und eine für die Werte. Die Schlüssel werden verwendet, um die Tabelle zu indizieren, und die Werte sind die Daten, die in der Tabelle gespeichert sind.
Nosql-Datenbank Couchbase
Eine NoSQL-Datenbank ist eine nicht relationale Datenbank, die nicht das traditionelle tabellenbasierte relationale Datenbankmodell verwendet. Stattdessen verwendet es ein schemafreies Datenmodell, wodurch es flexibler und skalierbarer ist. Couchbase ist eine Art NoSQL-Datenbank, die ein dokumentenorientiertes Datenmodell verwendet. Es wurde für interaktive Online-Anwendungen entwickelt, die große Datenmengen verarbeiten müssen.