
Speicherort von Dateien Nosql-Datenbank
Veröffentlicht: 2022-12-17Wenn es darum geht, Dateien in einer NoSQL-Datenbank zu speichern, müssen einige verschiedene Faktoren berücksichtigt werden. Der erste ist der Dateityp, den Sie speichern möchten. NoSQL-Datenbanken eignen sich am besten zum Speichern halbstrukturierter Daten. Wenn Sie also Dinge wie Bilder, Videos oder andere Binärdaten speichern möchten, sollten Sie sich nach anderen Optionen umsehen. Der zweite zu berücksichtigende Faktor ist die Größe der Dateien, die Sie speichern möchten. NoSQL-Datenbanken sind nicht für die Verarbeitung großer Datenmengen ausgelegt. Wenn Sie also Dateien mit einer Größe von einigen Gigabyte speichern möchten, sollten Sie sich nach anderen Optionen umsehen. Schließlich müssen Sie die Sicherheit der Dateien berücksichtigen, die Sie speichern möchten. NoSQL-Datenbanken sind nicht so sicher wie herkömmliche relationale Datenbanken. Wenn Sie also vertrauliche Informationen speichern möchten, sollten Sie sich nach anderen Optionen umsehen.
Es gibt heute zwei große Datenbankverwaltungssysteme auf dem Markt, das RDBMS und das NoSQL (Key-Value Stores, Column Family Stores, Document Databases und Graph Databases). Bei Verwendung relationaler Datenbanken ist es möglich, Daten aus einer nicht strukturierten (BPLOB) Datenbank auszuführen. Es wird typischerweise angenommen, dass Dateidaten in anderen Teilen des Dateisystems und nicht in der Datenbank gespeichert werden, wobei nur der Pfad oder die Referenz in der Datenbank verfügbar ist. GridFS kann für große Dokumente verwendet werden, die nur mit einer Größe von weniger als 16 MB gelesen werden können. Die Technik wird verwendet, um große Datenmengen wie Bilder, Audio, Videos oder irgendetwas anderes in Datenbankdateien zu speichern. Um die Leistung zu verbessern, verwendet GridFS einen Index in jedem Chunk und jeder Datei. Eine Demo-App, bestehend aus Entitäten und Relationen, hatte zwei Datenbankschichten: eine für NoSQL (Kundera) und eine für relationale Datenbanken (Hibernate).
Können Sie Dateien in der Nosql-Datenbank speichern?
Dokumentendatenbanken ähneln eher NoSQL-Datenbanken als relationalen Datenbanken. Infolgedessen wird SQL als „nicht nur SQL“ klassifiziert und alle Datenmodelle werden durch flexible Datenmodelle unterteilt. Eine NoSQL-Datenbank kann aus mehreren Typen bestehen, darunter reine Dokumentendatenbanken, Key-Value-Stores, Wide-Column-Datenbanken und Graph-Datenbanken.
Dank NoSQL können Daten in Dateien statt in einer Datenbank gespeichert werden. Es ist möglich, Einstellungen zu speichern, kleine Daten zu speichern und Dateien zu speichern. Ein NoSQL-Ansatz hat einige Vorteile, wie Benutzerfreundlichkeit und Geschwindigkeit, aber auch einige Nachteile. Dies kann beispielsweise daran liegen, dass Sie die Arbeit mit Ihrem eigenen Code steuern müssen. Daten können in einer Datenbank serialisiert werden, einschließlich temporärer Daten. Wenn Sie kleine Datenmengen speichern müssen, ist auch die Dateispeicherung eine Option. Cache-Dateien können auch nützlich sein, wenn sie große Datenmengen enthalten. Sobald ein oder mehrere Caches oder Abschnitte geleert sind, können diese Dateien automatisch erstellt und bereinigt werden.
Im Katastrophenfall bleibt die Datenkopie erhalten.
Es soll die Speicherung von Daten ermöglichen, die physisch nicht zugänglich sind.
Sicherungsdateien für Apache Cassandra werden im selben Verzeichnis wie Datenbankdateien für Apache Cassandra gespeichert. Zur Komprimierung der Sicherungsdateien wurde der Komprimierungsalgorithmus gzip verwendet.
Wenn Sie beabsichtigen, große Datenmengen zu speichern, wird empfohlen, die Apache Cassandra-Datenbank zu verwenden. Es ist kein Problem damit, mit Millionen von Objekten umzugehen; Backups werden im selben Verzeichnis wie die Datenbank gespeichert.
Warum Nosql der beste Weg ist, große Dateien zu speichern
MongoDB kann problemlos mit großen Dateien umgehen, und große Dateien können problemlos in MongoDB gespeichert werden. Das Dateisystem wird nicht mehr verwendet, und es bietet zahlreiche Vorteile gegenüber dem Speichern von Dateien auf dem Computer. Daten in der Datenbank sind kein Problem in der gleichen Weise wie in einem Dateisystem. Darüber hinaus kann die Datenbank verwendet werden, um Dateien zu indizieren, damit sie schnell durchsucht werden können. Eine NoSQL-Datenbank hingegen enthält keine Dateien; vielmehr enthält es Funktionen. Die Wahl eines anderen Dateisystems als NoSQL ist nicht das Beste, wenn Ihre Daten relational sind.
Wo werden Daten in Nosql gespeichert?
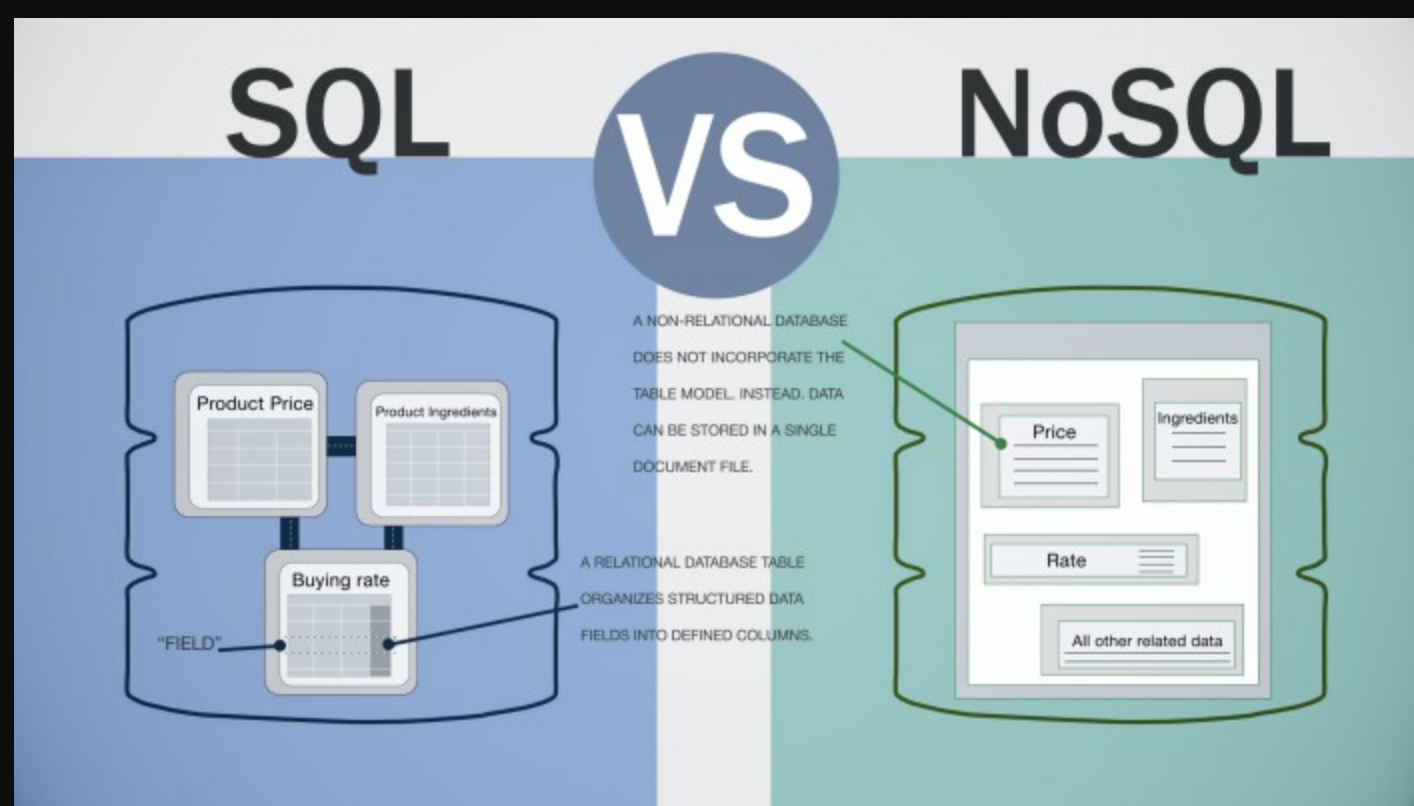
Auf diese Frage gibt es keine spezifische Antwort, da sie von der Art der verwendeten NoSQL-Datenbank abhängt. Beispielsweise könnte ein Schlüsselwertspeicher Daten in einer einfachen Datei oder im Arbeitsspeicher speichern, während eine Dokumentdatenbank Daten in JSON- oder XML-Dokumenten speichern könnte. Eine spaltenorientierte Datenbank speichert Daten möglicherweise in Spalten statt in Zeilen, und eine Diagrammdatenbank speichert Daten möglicherweise in einer Diagrammstruktur.
Der In-Memory-Schlüssel-Wert-Paar-Datenspeicher von Redis ist Open Source und kann aufgerufen werden. Eine Sitzungsdatenbank kann für eine Vielzahl von Zwecken verwendet werden, wie z. B. Caching, Warteschlangenbildung und Datenspeicherung. Die NoSQL-Datenbank wird häufig verwendet, um eine vorhandene relationale Datenbank zu ersetzen oder zu ergänzen. Sie haben unterschiedliche Leistungsmerkmale von einer relationalen Datenbank, wenn es um Persistenztypen geht. Ein Python-Client ist eine gängige Methode, um mit MongoDB-Instanzen zu kommunizieren. MongoEngine ist ein Python-ORM, das auf PyMongo aufbaut und speziell für MongoDB entwickelt wurde. Unter Verwendung der Begriffe Einführung in Graphdatenbanken und Vergleiche von Graphdatenbanken untersuchen wir Trends in NoSQL-Datenspeichern und vergleichen sie mit anderen Arten von Datenspeichern. Sie erfahren, was NoSQL bedeutet, wie Daten gespeichert werden und was das Consistency, Availability, and Partition-Tolerance Theorem (CAP) bedeutet. Im Allgemeinen werden Sitzungsdaten schneller im Arbeitsspeicher gespeichert als in einer herkömmlichen Datenbank , die Daten kontinuierlich speichert.
Die Vor- und Nachteile von Nosql-Datenbanken
NoSQL-Datenbanken werden aufgrund ihrer Vielseitigkeit und Fähigkeit, Daten in einer Vielzahl von Formaten zu speichern, immer beliebter. DynamoDB, Riak und Redis sind nur einige der NoSQL-Datenbanken, mit denen die Leute vertraut sind. Eine NoSQL-Datenbank unterscheidet sich in vielerlei Hinsicht von einer herkömmlichen relationalen Datenbank. Der Hauptunterschied besteht darin, dass Daten in JSON-Dokumenten und nicht in Spalten und Zeilen gespeichert werden. Folglich eignet sich ein dynamischeres und flexibleres Speichermodell besser für Daten, die für jedes Marktsegment spezifisch sind. Einer der Hauptunterschiede zwischen NoSQL-Datenbanken und herkömmlichen Datenbanken ist die Art und Weise, wie Daten abgefragt werden. Da NoSQL-Datenbanken eine andere Abfragesyntax als relationale Datenbanken verwenden, können sie für Erstbenutzer schwierig zu beherrschen sein. Trotzdem sind NoSQL-Datenbanken aufgrund ihrer Flexibilität und Leistungsfähigkeit hervorragende Kandidaten für komplexere Aufgaben. Die Popularität von NoSQL-Datenbanken wird hauptsächlich durch ihre Fähigkeit angetrieben, eine Vielzahl von Datenformaten zu unterstützen und eine ständig wachsende Palette von Datenquellen zu verwalten. NoSQL-Datenbanken können eine Vielzahl von Aufgaben und Herausforderungen bewältigen, was sie zu einer ausgezeichneten Wahl für Organisationen macht, die mehrere Aufgaben und Herausforderungen bewältigen müssen.
Was sollte ich in Nosql speichern?
Auf diese Frage gibt es keine endgültige Antwort, da dies von den spezifischen Anforderungen Ihrer Anwendung abhängt. Einige allgemeine Richtlinien umfassen jedoch das Speichern von Daten, auf die häufig zugegriffen oder die häufig aktualisiert werden, Daten, die nicht leicht relational sind, und Daten, die unstrukturiert oder halbstrukturiert sind.
Es ist eine Programmiersprache, die nicht traditionelle Methoden zum Speichern von Daten verwendet, anstatt herkömmliche Methoden zum Speichern von Daten. Abhängig vom verwendeten Datenmodell und der Methode zur Verteilung der Replikation stehen verschiedene Arten von NoSQL-Lösungen zur Verfügung. Eine Beschreibung jedes dieser Typen und des Bereichs, in dem sie angewendet werden, wird bereitgestellt. Die region_id und industry_id werden in der Darstellung eines Profils eher mit fremden Tabellen als mit Textstrings wie Philanthropy oder Seattle Area verknüpft. Dies geschah aus verschiedenen Gründen, einschließlich der Möglichkeit strafrechtlicher Anklagen. Da das Duplizieren von Daten erforderlich ist, kann eine Textzeichenfolge oder eine ID nicht separat gespeichert werden. Es braucht mehr als nur datenbanktechnische Fähigkeiten, um eine Datenbank zu normalisieren; dazu braucht es auch mehr als eine Dokumentenstruktur wie Couchbase.
Obwohl NoSQL-Datenbanken immer beliebter werden, bedeutet dies nicht, dass sie für jede Anwendung ideal sind. Eine NoSQL-Umgebung ermöglicht Ihnen keine Laufzeitflexibilität, daher müssen Sie dies vollständig vermeiden.
In dieser Kategorie ist MongoDB aufgrund seiner Leistung und Skalierbarkeit der klare Gewinner. Darüber hinaus schätzen Entwickler die Benutzerfreundlichkeit, die es bietet.
Wenn Sie also nach einer NoSQL-Datenbank suchen, die insgesamt gut funktioniert und eine hervorragende Benutzerfreundlichkeit bietet, ist MongoDB eine gute Wahl.
So speichern Sie Bilder in der Nosql-Datenbank
Es gibt viele Möglichkeiten, Bilder in einer nosql-Datenbank zu speichern. Eine Möglichkeit besteht darin, die Bilder als base64-codierte Zeichenfolgen in der Datenbank zu speichern. Eine andere Möglichkeit besteht darin, die Bilder in einem Dateisystem zu speichern und den Dateipfad in der Datenbank zu speichern.
Es herrscht ein heiliger Krieg darüber, ob Bilder in einer Datenbank oder im Dateisystem gespeichert werden sollen. Meistens komme ich auf die Seite des Dateisystems, weil es viel größer ist. Unabhängig davon, wie Sie vorgehen, werden beide Optionen höchstwahrscheinlich gut mit der Größe Ihres Projekts funktionieren. Riak wurde in diesem Bereich als bahnbrechend beschrieben. Um zu verhindern, dass Riak einen riesigen Server zum Absturz bringt, muss die richtige Konfiguration verwendet werden. Wenn Sie Python verwenden, kann das Modul y_serial von sourceforge.net verwendet werden, um Bilder (beliebige Python-Objekte, einschließlich Webseiten) in komprimierter Form zu speichern und darauf zuzugreifen, und im Fall von NoSQL kann von jedem Python-Programm darauf zugegriffen werden.
Welche Datenbank zum Speichern von Bildern?
Große statische Objekte sollten auf einem Server gespeichert werden, z. B. einem AWS S3, HDFS, einem Content Delivery Network (CDN), einem Webserver, einem Dateiserver oder was auch immer für Ihren spezifischen Anwendungsfall und Ihr Budget am besten geeignet ist.
Können wir Bilddaten in einer Datenbank speichern?
Wenn Sie eine Datenbank erstellen, können Sie verschiedene kleine Bilder und andere Informationen in einer Datenbanktabelle speichern. Um beispielsweise ein Online-Fotoalbum mit einer Liste Ihrer Fotos zu erstellen, ist keine Datenbanktabelle erforderlich. In Ermangelung einer Sicherung sollte das Speichern von Bildern in einer Datenbanktabelle vermieden werden.
Kann eine SQL-Datenbank Bilder enthalten?
SQL Server hat den IMAGE-Datentyp erstellt, um die Bilddateien zu speichern. Da IMAGE in einer zukünftigen Version von MS SQL Server auslaufen wird, hat Microsoft damit begonnen, VARBINARY (MAX) als Alternative zum Speichern einer großen Datenmenge in einer einzelnen Spalte vorzuschlagen.
Datenbank zum Speichern von Dateien
Eine Datenbank zum Speichern von Dateien kann verwendet werden, um eine Vielzahl von Dateien zu speichern, darunter Bilder, Videos und Dokumente. Diese Art von Datenbank kann verwendet werden, um Dateien für einen bestimmten Zweck zu speichern oder Dateien mit anderen zu teilen. Eine Datenbank zum Speichern von Dateien kann verwendet werden, um eine Sicherungskopie von Dateien zu erstellen, Dateien organisiert zu halten oder Dateien für eine spätere Verwendung zu speichern.

Der Begriff „Datei“ bezieht sich auf alles, was größer als tausend Wörter oder weniger ist. Es gibt mehrere Arten von Blobs in Datenbanken, bei denen es sich um große, willkürliche Bytefolgen handeln kann, und sie werden von einer großen Anzahl von Datenbanken verarbeitet. Können Sie sich eine Begrenzung (z. B. auf wenige Megabyte) für die Größe Ihrer Datei leisten? Dateneigentum, Datenverwaltung, Mtime und Berechtigungen sind ebenfalls weit verbreitet. Unter Linux wird empfohlen, die inotify(7)-Einrichtungen so zu konfigurieren, dass sie über Ereignisse im Zusammenhang mit Dateisystemen (z. B. ext4) informieren. Da Dateien eine Abstraktion Ihres Betriebssystems sind, können sie unabhängig von Ihrer Datenbank gefunden werden (vorausgesetzt, sie existieren auf diese Weise). Einige externe Programme können erstellt, gelesen, geschrieben oder gelöscht werden. Da viele DBMS den Inhalt des Arrays einschränken, ist es üblich, dass Sie das Gegenteil von dem tun, was Ihre Frage impliziert.
Die Vor- und Nachteile des Speicherns von Dateien in einer Datenbank
Eine Datenbank kann Dateien aus verschiedenen Gründen enthalten, darunter eine schnellere Datenwiederherstellung und eine sicherere Speicherung. Es ist wichtig, sowohl die Vor- als auch die Nachteile der beiden Optionen abzuwägen, bevor Sie eine Entscheidung treffen. In diesem Artikel werden wir sowohl das Speichern von Dateien in einer Datenbank als auch das Speichern an anderer Stelle untersuchen, um festzustellen, was für eine Anwendung besser ist.
Der Inhalt der Dateien kann in einer Datenbank gespeichert werden, oder er kann woanders gespeichert und mit der Datenbank indiziert werden. In diesem Artikel demonstrieren wir diese beiden Techniken anhand einer einfachen Image Archive-Anwendung.
Eine SQL Server-Datenbank kann aufgrund der FileTable-Funktion unstrukturierte Dateidaten und Verzeichnishierarchien speichern. Auf dateibasierte Daten kann dank der Funktion ohne Transaktionen zugegriffen werden, wodurch auch Windows-Anwendungen den dateibasierten Zugriff unterstützen können.
Häufig wird angenommen, dass das Speichern von Dateien in einer Datenbank die bequemere Option ist, da sie eine bessere Datenwiederherstellung bietet und sicherer ist.
Mongodb-Dateispeicherung
MongoDB bietet eine Vielzahl von Funktionen, einschließlich Dateispeicherung. Mit MongoDB können Dateien in Datenbanken gespeichert werden, was die Verwaltung und den Zugriff erleichtert. Darüber hinaus bietet die Dateispeicherfunktion von MongoDB Sicherheits- und Datenschutzfunktionen, die sicherstellen, dass Dateien geschützt und sicher sind.
Kunden können die GridFS-Implementierung in ihren eigenen Anwendungen verwenden. Da jeder Teil der Datei- oder Chunks-Sammlung abgerufen werden kann, führt jede Abfrage zu demselben Ergebnis. Bei kleinen Dateien direkt aus dem RAM ist zwar keine hohe Leseleistung zu erzielen, aber eine hohe Schreibleistung wäre ebenso machbar. Es gibt keine große Datei. Die durchschnittliche Chunk-Größe beträgt 256 KB, was bedeutet, dass eine 600-GB-Datei ungefähr 3.069 Seiten enthält. Um dies zu lösen, muss man mit einer einzelnen Datei über eine große Anzahl von Shards hinweg beginnen. Es stimmt, dass S3 in Formaten mit reduzierter Redundanz am besten für MongoDB funktioniert, aber es kann bis zu zehnmal so viel Speicherplatz beanspruchen wie normale MongoDB .
Das Erstellen eines MongoDB-Datenverzeichnisses ist so einfach wie das Kopieren von Daten von einem Ort zum anderen. Starten Sie zunächst die Eingabeaufforderung und geben Sie md c:/data/db ein. Wenn der Erstellungsprozess abgeschlossen ist, wird das MongoDB-Datenverzeichnis erstellt und die Eingabeaufforderung lautet „Fertig“. Der folgende Befehl ändert den Speicherort des MongoDB-Datenverzeichnisses: MongoDB-Datenverzeichnis c:/data/db/mynewdir.
Gridfs ist eine großartige Möglichkeit, große Dateien in Mongodb zu speichern
MongoDB hat eine fantastische Funktion namens GridFS, die zum Speichern großer Dateien verwendet werden kann. Wenn Sie ein Dateisystem haben, das die Anzahl der Dateien in einem Verzeichnis begrenzt, kann GridFS so viele Dateien behalten, wie Sie benötigen. Mit GridFS können Sie auch mehrere Dateien gleichzeitig im selben Verzeichnis speichern.
Speichern von Dateien in relationalen Datenbanken
Das Speichern von Dateien in relationalen Datenbanken ist ein Prozess, bei dem Daten in Dateien gespeichert werden, die miteinander in Beziehung stehen. Dieser Prozess kann verwendet werden, um Daten in einer Vielzahl von Formaten zu speichern, darunter Text, Bilder und SQL.
Es ist allgemein bekannt, dass das Speichern von Binärdateien in einer Datenbank keine gute Idee ist. Dies gilt als besonders besorgniserregend im Hinblick auf das Lesen und Schreiben. Dies ist eines der grundlegendsten Merkmale einer relationalen Datenbank: Sie ist vollständig ACID. Wenn Sie Daten für sensible Zwecke in der Datenbank speichern, kann es von Vorteil sein, die Speicherung von Dateien in der Datenbank als BLOBs (erneut) in Erwägung zu ziehen. Oracle SecureFiles ist, wie der Name schon sagt, in erster Linie als Marketingtool gedacht, kann aber zur Lösung einer Vielzahl von BLOB-Problemen verwendet werden. SecureFiles ist auch extrem einfach zu bedienen. Es ist genau wie jede andere Art von Flüssigkeit.
Beim Erstellen einer BLOB-Spalte können Sie einfach STORE AS SECUREFILE in der Spalte CREATE BLF angeben. Wenn Oracle FUSE unterstützt, sollte Linux in der Lage sein, ein SecureFile BLOB als Dateisystem zu mounten. Anstatt in Oracle gesperrt zu sein, sind Ihre Binärdateien nicht unbedingt in irgendeiner Weise gesperrt.
Die verschiedenen Möglichkeiten, Daten in einer relationalen Datenbank zu speichern
Tabellendaten sind eine notwendige Komponente einer relationalen Datenbank. Tabellendaten speichern Informationen in einer bestimmten Reihenfolge, ähnlich wie Ordnerdaten, aber sie werden auch von Spalten und Zeilen begleitet. Jede Tabelle hat ihren eigenen Namen und jede Spalte darin ist einem bestimmten Datentyp zugeordnet. Ein Tabellenname für Personen könnte beispielsweise eine Spalte für den Namen der Person, den Nachnamen und die E-Mail-Adresse enthalten. Jede Zeile enthält ein Dokument. Die Struktur jedes Dokuments in einer Tabelle variiert, aber alle Dokumente in der Tabelle werden in derselben Reihenfolge gespeichert. Jede Spalte in einer Tabelle stellt ein Feld in einem Dokument dar, während jedes Feld in einem Dokument eine Spalte in einer Tabelle darstellt. Beispielsweise kann eine Tabelle mit der Spalte Personen ein Feld mit dem Vornamen enthalten. Die Datenbank untersucht zunächst das Dokument in der Tabelle, um festzustellen, ob es sich um ein Dokument handelt, auf das zugegriffen werden kann. Ein Dokument kann nicht gefunden werden, wenn es nicht in den Indizes der Tabelle sichtbar ist; die Datenbank sucht dann danach. Wenn ein Dokument nicht in den Indizes gefunden werden kann, sucht die Datenbank in den Dateien der Tabelle danach. Daten in einer relationalen Datenbank können in tabellenbasierter Speicherung gespeichert werden, was die häufigste Art der Datenspeicherung ist. Ein tabellenbasiertes Speichersystem erstellt für jedes Dokument eine separate Tabelle. Der Tabellenname hat denselben Namen wie der Dateiname des Dokuments. Die indexbasierte Datenspeicherung, auch als relationale Datenbankspeicherung bekannt, ist eine weitere gängige Methode zum Speichern von Dokumenten in einer relationalen Datenbank. Jedes Dokument wird separat in einem indexbasierten Speichersystem gespeichert. Der Indexname hat die gleiche Struktur wie der Dateiname. Die spaltenbasierte Speicherung ist eine dritte gängige Art der Datenspeicherung, die für Dokumente in einer relationalen Datenbank verwendet wird. Jedes Dokument im spaltenbasierten Speicher wird in einer separaten Spalte untergebracht. Wenn der Spaltenname mit dem Dateinamen identisch ist, gibt es keinen Unterschied zwischen den beiden. Es ist wichtig, sich daran zu erinnern, dass jede Art der Datenspeicherung ihre eigenen Vor- und Nachteile hat. Die tabellenbasierte Speicherung ist die häufigste Art der Datenspeicherung. Der Nachteil der tabellenbasierten Speicherung besteht darin, dass es schwierig sein kann, ein Dokument zu finden, wenn Sie seinen Tabellennamen nicht kennen. Ein Vorteil der tabellenbasierten Speicherung besteht darin, dass Dokumente einfach hinzugefügt oder gelöscht werden können.
Nosql-Datenbank
Eine NoSQL-Datenbank ist eine Datenbank, die nicht die traditionelle tabellenbasierte relationale Datenbankstruktur verwendet. NoSQL-Datenbanken werden häufig zum Speichern großer Datenmengen verwendet, die nicht ohne weiteres in einer relationalen Datenbank gespeichert werden können.
Datenbank NoSQL-Datenbanken speichern Daten in Dokumenten und nicht in Tabellen, die relationaler Natur sind. Ein Data Warehouse ist eine Sammlung von Softwarekomponenten, die so konfiguriert werden können, dass sie die Datenverwaltungsanforderungen eines modernen Unternehmens flexibel, skalierbar und schnell erfüllen. Eine NoSQL-Datenbank kann aus einem oder mehreren Arten von Datenbanken bestehen, darunter reine Dokumentdatenbanken, Schlüsselwertspeicher, Wide-Column-Datenbanken und Graphdatenbanken. Global-2000-Unternehmen führen NoSQL-Datenbanken schnell ein, um unternehmenskritische Anwendungen zu unterstützen. Grund dafür sind fünf Trends, die in den meisten relationalen Datenbanken nur schwer umzusetzen sind. Relationale Datenbanken sind aufgrund ihres festen Datenmodells für die agile Entwicklung unwirksam und damit ein erhebliches Hindernis. NoSQL-Modelle basieren auf den Anwendungsmodellen und beinhalten ein Datenmodell.
Der Einsatz von NoSQL bedeutet nicht, dass die Daten für immer modelliert werden müssen. JSON ist das De-facto-Format zum Speichern von Daten in einer dokumentenorientierten Datenbank. Dadurch werden ORM-Frameworks verkleinert und die Anwendungsentwicklung vereinfacht. In Couchbase Server 4.0 wurde die Abfragesprache N1QL (ausgesprochen Nickel) eingeführt. Dieses Programm unterstützt auch Aggregation (GROUP BY), Sortierung (SORT BY), Verknüpfungen (LEFT OUTER) und andere Arten von Anweisungen zusätzlich zu Standard-SELECT / FROM / WHERE. Eine verteilte NoSQL-Datenbank kann eine Reihe überzeugender betrieblicher Vorteile bieten, da sie eine Scale-out-Architektur verwendet und keinen Single Point of Failure aufweist. Die Verfügbarkeit wird zu einem kritischen Thema, da immer mehr Kunden online über Web- und mobile Apps mit Unternehmen interagieren.
NoSQL-Datenbanken sind einfach einzurichten, zu konfigurieren und zu skalieren. Sie wurden speziell für Lese-, Schreib- und Speichervorgänge entwickelt. Sie können in jeder Größe verwendet werden, und sie können verwendet werden, um Cluster unterschiedlicher Größe zu verwalten und zu überwachen. Eine NoSQL-Datenbank ist so aufgebaut, dass sie zwischen mehreren Rechenzentren repliziert werden kann, ohne dass zusätzliche Software erforderlich ist. Darüber hinaus bietet es sofortiges Failover über Hardware-Router, sodass Anwendungen ihre eigene Notfallwiederherstellung durchführen können, wenn die Datenbank ausfällt. Heute wird NoSQL in einer wachsenden Zahl von Web-, Mobil- und Internet of Things (IoT)-Anwendungen verwendet.
Warum Nosql-Datenbanken die Führung übernehmen
Es ist nicht ungewöhnlich, dass NoSQL-Datenbanken aufgrund einer Vielzahl von Faktoren beliebt sind. Sie bieten eine neue Sichtweise auf Daten, die für eine bestimmte Anwendung effizienter sein kann. Darüber hinaus können sie aufgrund ihrer Skalierbarkeit größere Datenmengen verarbeiten als herkömmliche Datenbanken. Drittens sind das Design und die Wartung dieser Datenbanken erheblich einfacher als die herkömmlicher Datenbanken.