
Warum Apache HBase die beste Wahl für Ihr nächstes Big-Data-Projekt ist
Veröffentlicht: 2022-11-16Apache HBase ist eine nicht relationale, verteilte Open-Source-Datenbank, die Googles Bigtable nachempfunden und in Java geschrieben ist. Es wurde im Rahmen des Apache Hadoop-Projekts der Apache Software Foundation entwickelt und läuft auf HDFS (Hadoop Distributed File System) und bietet Bigtable-ähnliche Funktionen für Hadoop. Genau wie Bigtable ist HBase darauf ausgelegt, große Datenmengen mit hohem Durchsatz zu verarbeiten, und eignet sich für Anwendungen, die einen Datenzugriff mit geringer Latenz erfordern.
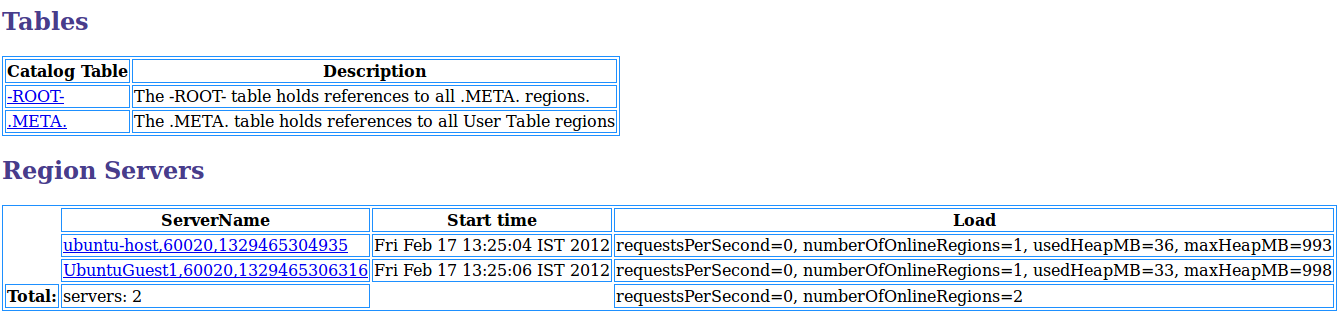
HBase, eine NoSQL-Datenbank, wird zum Speichern und Abrufen von Daten mit wahlfreiem Zugriff verwendet. Das darin enthaltene Datenmodell ist dynamisch und flexibel und ermöglicht es, jede Art von Daten ohne Einschränkungen zu speichern. HBase kann mit MapReduce von Apache Hadoop integriert werden, um Massenoperationen durchzuführen (z. B. Indizierung, Analyse usw.). HBase ist eine spärliche, multidimensionale, sortierte, kartenbasierte Datenbank mit mehreren Versionen eines einzelnen Datensatzes. Mit der integrierten Hadoop MapReduce-Unterstützung kann es große Datenmengen blitzschnell und parallel verarbeiten. Die HBase-Architektur besteht aus vier Hauptkomponenten: HMaster, HRegion, Hlog und HBase. ZooKeeper ist ein Open-Source-Projekt, das neben mehreren wesentlichen Funktionen auch mehrere wesentliche Dienste bereitstellt.
ZooKeeper enthält eine Funktion, die eine verteilte Synchronisierung von Konfigurationsdaten ermöglicht. Wenn ein Knoten in HBase ausfällt, generiert zkQuorum Fehlermeldungen und beginnt mit der Reparatur. Öl und Petroleum, Marketing und Werbung, Banken und der Aktienmarkt sind nur einige der Bereiche, in denen HBase verwendet wird.
Als verteiltes Dateisystem hat die Verwendung von HDFS in HBase einige Vorteile. Die Datenbank kann somit in kurzer Zeit große Datensätze, sogar Milliarden von Zeilen, speichern und so eine schnelle Analyse ermöglichen.
Es verwendet einen spaltenorientierten, nicht relationalen Ansatz für die Datenbankverwaltung. Die Informationen werden in einzelnen Spalten gespeichert und mit einem eindeutigen Zeilenschlüssel indiziert, der für jede Spalte eindeutig ist. Diese Architektur sorgt für einen schnellen und effizienten Abruf einzelner Zeilen und Spalten sowie für einen effizienten Scanvorgang für einzelne Spalten in einer Tabelle.
Apache HbaseFirmennameWebsiteEinnahmenFacebookwww.Facebook.com117 Milliarden DollarHortonworks Incwww.hortonworks.com75 MillionenJP Morgan Chasewww.JPMorganChase.com130 Milliarden Palo Alto Networks Incwww.palo Alto
In MongoDB stehen mehrere Arten von Projektionen, Filter- und Aggregatfunktionen zur Auswahl. Im Gegensatz zu Hbase, das Daten mit Schlüsselwerten paart, können Schlüsselwerte mit anderen Anwendungen geteilt werden. MongoDB ermöglicht Ihnen die Durchführung einer Textsuche, indem es native Textindizes sowie HBase-Datenreplikation bereitstellt.
Ist Hadoop eine Nosql-Datenbank?

Hadoop ist ein Open-Source-Software-Framework zum Speichern und Verarbeiten von Big Data. Es verwendet ein verteiltes Dateisystem (HDFS) und MapReduce, um Daten zu verarbeiten und zu analysieren. Hadoop ist keine traditionelle relationale Datenbank, kann aber auf ähnliche Weise zum Speichern und Verarbeiten von Daten verwendet werden.
In MongoDB werden keine Dokumente benötigt, da die Datenbank auf dem Datenmodell JavaScript Object Notation (JSON) basiert. Es soll schnell und einfach zu bedienen sein und über einen gut definierten Index und Suchfunktionen verfügen. Ein Map/Reduce-Algorithmus wird verwendet, um riesige Datensätze in Hadoop, einem verteilten Speichersystem, zu verarbeiten. Dieses Produkt wurde entwickelt, um eine kostengünstige Lösung für die Datenanalyse und -archivierung bereitzustellen.
Verwendet Hbase SQL?
HBase ist keine relationale Datenbank und verwendet kein SQL zum Abfragen von Daten. HBase verwendet ein Key/Value-Store-Design, das für schnellen Lese-/Schreibzugriff auf große Datensätze optimiert ist.
Aufgrund seiner hohen Skalierbarkeit, der Unterstützung für Hadoop-Map-Reduce-Programmierung und der Implementierung des bekannten Google BigTable-Whitepapers ist HBase eine hervorragende Wahl für die Speicherung unstrukturierter Daten. Die Benutzerfreundlichkeit von HBase ist ein großer Vorteil für Warehouse-Anwendungen, die große Datenmengen schnell verarbeiten müssen.
Was ist die Hbase-Abfragesprache?
Mit der Jaspersoft HBase Query Language, einer deklarativen Sprache im JSON-Stil, können Sie angeben, welche Daten von HBase abgerufen werden sollen. Bei Verwendung der HBase-REST-Server-Schnittstelle wandelt der Konnektor die Abfrage in einen passenden API-Aufruf um, der dann auf der HBase-Instanz ausgeführt wird.
Die Vorteile der Verwendung einer Hbase-Tabelle
Was ist eine Säulenfamilie? Eine Spaltenfamilie kann sich auf eine Sammlung von Spalten beziehen, die einen gemeinsamen Namen und Datentyp haben. Mitarbeiternamen könnten die Spalten id,name,hired_on,fired_on enthalten. Welche Vorteile bietet die Verwendung von HBase-Tabellen ? Eine HBase-Tabelle bietet die folgenden Vorteile: Das spaltenorientierte Design von HBase erleichtert das Speichern von und den Zugriff auf spärliche oder unstrukturierte Daten. Aufgrund seiner Fehlertoleranz kann HBase gelegentlichen Datenverlusten oder -beschädigungen standhalten. Da HBase so einfach zu verwenden ist, können Sie schnell mit der Nutzung von Big Data Storage beginnen. Da HBase skalierbar ist, können Sie Ihrem Cluster weitere Server hinzufügen, um größere Datensätze zu verarbeiten.
Wofür ist Hbase nicht gut?
Funktionen wie SQL können nicht mit HBase HBase ausgeführt werden. Da es keine SQL-Struktur unterstützt, gibt es keine Abfrageoptimierung. HBase ist CPU- und speicherintensiv, mit großem sequentiellen Eingabe- oder Ausgabezugriff, während Map Reduce-Jobs typischerweise Eingabe- oder Ausgabe-gebunden mit festem Speicher sind und CPU- und speicherintensiv sind.
Hbase: Die beste Datenspeicherlösung für zufällige Lese- und Schreibvorgänge
Es ist ideal für Anwendungen, die sowohl wahlfreie Lese- als auch wahlfreie Schreiboperationen ausführen, sowie für solche, die wahlfreie Lese- und wahlfreie Schreiboperationen verwenden. HBase ist auch eine gute Wahl für Anwendungen, die Echtzeit-Datenzugriff erfordern.
Ist Hbase wie Cassandra?

Im Gegensatz zu Cassandra, das auf mehreren Servern und Versionen derselben Datei ausgeführt wird, wird Hbase auf einem Datenserver ausgeführt. Daher ist der Zugriff auf Hbase-Lesevorgänge einfacher als auf Cassandra-Lesevorgänge. Die Daten von Hbase werden in HDFS gespeichert, wo sie über Bloom-Filter und Block-Caches verfügen, die schnellere Lesevorgänge ermöglichen.
Diese NoSQL-Datenbanken, die große Datensätze verarbeiten können, wurden von Cassandra und HBase erstellt. Sie haben viele Eigenschaften gemeinsam, einschließlich ihrer gemeinsamen Merkmale. Auf den ersten Blick sind beide unterschiedlich. In diesem Artikel werden wir uns ansehen, wie sich HBase und Cassandra in Bezug auf die beteiligten Faktoren unterscheiden. Cassandra verfügt wie HBase über eine Hadoop-Infrastruktur , aber auch über unterschiedliche DBMS und Infrastruktur. Cassandra benötigt keine zusätzliche Rechenleistung. Die Indizierung über Bloom-Filter ist das, was HBase tut.
Mit Cassandra können mehrere Zeilen von einer einzigen WAN-Adresse mit zufälligen Partitionen repliziert werden. Es ist besser, eine einzige Datenquelle als mehrere Datenquellen für Cassandra zu haben. Außerdem ist die Installation von Cassandra Cluster einfacher als die von HBase Cluster .
Hbase Vs Cassandra: Was ist besser?
Sowohl Cassandra als auch HBase können gleichzeitig gelesen und geschrieben werden, aber Cassandra ist schneller. Darüber hinaus ist Cassandra schneller als HBase.
Hbase gegen Mongodb
Beim Vergleich von HBase und MongoDB gibt es keinen klaren Sieger. Beide Systeme haben ihre eigenen Stärken und Schwächen. HBase eignet sich besser für die Handhabung großer Datenmengen, während MongoDB flexibler und benutzerfreundlicher ist.
Nach 4 Jahren bei Couchbase sind wir zu MongoDB gewechselt, und der Übergang verlief nahtlos. Obwohl wir Enterprise-Support erhalten haben, hatten wir eine schreckliche Erfahrung mit Couchbase. Bei der Volltextsuche werden häufig mehrere Arten von Ergebnissen zurückgegeben, wenn Sie eine Vielzahl von Abfragen ausführen. Es gibt keine Möglichkeit, Indizes in Windows korrekt zu konfigurieren. Ein Produktionsserver kann bis zu sechs Benutzer unterstützen. Zusätzlich zur Handhabung des In-Memory-Cache ist eine kleinere Memcached-Instanz in Couchbase enthalten. Jedes der 5000 Dokumente belegt 8 GB RAM. Es besteht kein Zweifel daran! Es gab weniger als 5000 Dokumente in einer Couchbase-Instanz, weniger als 20 Indizes und der RAM-Verbrauch lag immer über 8 GB.
Der Hauptunterschied zwischen Amazon DynamoDB und Apache HBase besteht darin, dass Amazon DynamoDB auf HDFS aufbaut, das schnelle Datensatzsuchen (und Aktualisierungen) für große Tabellen ermöglicht. Ein verteiltes Dateisystem wie HDFS ist ideal zum Speichern großer Dateien. HBase hingegen baut auf HDFS auf und kann problemlos Datensatzsuchen (und Aktualisierungen) für große Tabellen durchführen.
Darüber hinaus ist Amazon DynamoDB ein Schlüssel/Wert- und Dokumentenspeicher, im Gegensatz zu Apache HBase, das ein Schlüssel/Wert- und Dokumentenspeicher ist. Für einen umfassenderen Vergleich von Amazon DynamoDB und Apache HBase als NoSQL-Datenspeicher betrachten Sie das Schlüssel/Wert-Datenmodell für Amazon DynamoDB.

Hbase Vs Mongodb: Welche Datenbank ist die bessere?
Mit HBase ist es einfach, große Datenmengen zu speichern und abzufragen. Dieses Cloud-basierte System ist anpassungsfähig, langlebig und verfügt über eine Reihe einzigartiger Funktionen, die es zur idealen Wahl für eine Vielzahl von Unternehmen machen. MongoDB ist eine ausgezeichnete NoSQL-Datenbank für speicherintensive Anwendungen, aber Hadoop bietet eine bessere Speicherplatzverwaltung.
Hbase gegen Kassandra
Die Hbase-Plattform wird für die Datenspeicherung in großen Datenbanken verwendet, während die Cassandra-Plattform für die Aufnahme und Datenspeicherung großer Mengen verwendet werden kann. In Echtzeit ist es am besten, Cassandra für die interaktive Daten- und Transaktionsverarbeitung zu verwenden.
(Speicher) Cassandra vs. Hbase – Was ist der Unterschied? Apache Cassandra wird als NoSQL-Systemklasse angesehen, da es darauf ausgelegt ist, die stabilsten und skalierbarsten Daten-Array-Repositories zu erstellen. Benutzer von Cassandra konnten zur Community beitragen, indem sie die Open-Source-Komponente nutzten, die es ihnen ermöglichte, alle Probleme und Fragen zu diskutieren. Das Datenbankverwaltungssystem von Cassandra ist äußerst effizient. Die Entwickler werden in der Lage sein, die Fähigkeiten mehrerer Multi-Core-Maschinen zu nutzen. Die Spalte von Cassandra enthält die Gewichtung der Präferenz des Benutzers in Zeilen. Die Hadoop-Infrastruktur, die Zookeeper, Hbase-Master, Datenknoten und Namensknoten umfasst, wird zum Ausführen von Hbase verwendet.
Cassandra verwendet eine spezifische Abfragesprache und CQL nach dem Vorbild von SQL. Das Zookeeper-Protokoll wird verwendet, um Daten von anderen Knoten zu sammeln. Cassandra hingegen eignet sich besser für die Aufnahme und Speicherung von Daten in großem Maßstab als Hbase, das zum Speichern kleiner Informationen in großen Datenbanken verwendet wird.
Warum Cassandra die beste Nosql-Lösung für Netflix ist
In der Welt von Cassandra und HBase sind sie sehr unterschiedlich. Die Architektur von HBase soll nur die Datenverwaltung unterstützen, während die Architektur von Cassandra die Datenspeicherung und -verwaltung unterstützen soll, ohne auf ein anderes System angewiesen zu sein.
HBase wird derzeit von mehreren Organisationen verwendet und von allen intern verwendet. Wenn wir einen NoSQL-Speicher benötigen, kann er eine Vielzahl von Problemen lösen und eine Vielzahl einzigartiger Lösungen bieten. Die NoSQL-Speicherlösungen von HBase sind die besten auf dem Markt.
Cassandra ist nicht nur eine Infrastrukturkomponente für den weltweit verbreiteten Streaming-Dienst von Netflix, sondern auch auf Amazon Web Services verfügbar.
Apache Hbase
HBase ist ein verteilter, spaltenorientierter Open-Source-Speicher, der dem Bigtable von Google nachempfunden ist. So wie Bigtable die vom Google-Dateisystem bereitgestellte verteilte Datenspeicherung nutzt, bietet HBase Bigtable-ähnliche Funktionen zusätzlich zu Hadoop und HDFS. Zu den HBase-Funktionen gehören lineare und modulare Skalierbarkeit, konsistente Lese- und Schreibvorgänge mit geringer Latenz sowie automatisches und konfigurierbares Sharding von Tabellen.
Hadoop speichert und verarbeitet riesige Datenmengen mithilfe des verteilten Dateisystems und MapReduce. HBase, eine verteilte spaltenorientierte Datenbank, baut auf Hadoop auf. Das Projekt ist sowohl Open Source als auch horizontal skalierbar. Die große Tabelle von Google, die der von Google ähnelt, ermöglicht den wahlfreien Zugriff auf strukturierte Daten. HBase hingegen befindet sich auf dem Hadoop-Dateisystem und bietet Lese- und Schreibzugriff auf das Dateisystem. Das HDFS-Dateisystem kann zum Speichern von Daten verwendet werden, entweder direkt oder über HBase. HBase, eine spaltenorientierte Datenbank, ist so aufgebaut, dass Zeilen sortiert werden. Eine Tabelle kann mehr als eine Spaltenfamilie haben, und jede Spaltenfamilie kann mehr als eine Spalte haben.
Hadoop vs. Hbase
Große, spärliche Datensätze werden von Hadoop effizienter gehandhabt. Wenn Daten in Echtzeit verarbeitet werden, sind die Verarbeitungsfunktionen von HBase denen anderer Plattformen überlegen.
Hbase gegen Hive
Hive und HBase sind zwei verschiedene Technologien, die in Hadoop funktionieren, wobei Hive eine SQL-ähnliche Engine ist, die MapReduce-Jobs ausführt, und HBase eine NoSQL-Schlüssel/Wert-Datenbank ist. Hive ist eine robuste Abfrage-Engine, mit der Sie Abfragen in Echtzeit durchführen können, während HBase eine robuste Abfrage-Engine ist, mit der Sie Abfragen in Echtzeit durchführen können.
Apache Hadoop und Apache HBase sind zwei unterschiedliche Big-Data-Technologien, die in fast allen Fällen verschiedenen Zwecken dienen können. Jede Technologie muss in den Augen von Big-Data-Systemen miteinander kombiniert werden. Was sind die Unterschiede zwischen Hive und HBase? Apache Hadoop MapReduce und HBase können kombiniert werden, um eine NoSQL-Datenbank zu erstellen. Eine der größten Lücken in HBase ist das Fehlen von Diensten, die die Möglichkeit eines wahlfreien Zugriffs ermöglichen. Es ist auch bekannt, horizontal mit handelsüblichen regionalen Servern zu skalieren, um hochverfügbar, konsistent und nur am unteren Ende des Spektrums von Latenz-No-SQL-Datenbanken zu sein. Hadoop wird auf zwei verschiedene Arten verwendet: Hive und HBase. Hive ist eine SQL-ähnliche Engine, die MapReduce-Jobs ausführt, während HBase eine NoSQL-Datenbank mit Schlüsseln und Werten ist. Anstatt einen Konkurrenten zu haben, sollten diese beiden Technologien zusammenarbeiten.
Hive oder Hbase für Ihr nächstes Datenprojekt?
Hive gibt es schon lange. Die Verwendung von HBase hat gegenüber anderen Data Warehouses auf dem Markt einige Vorteile, steckt aber noch in den Kinderschuhen. Hive ist in vielen Unternehmen eine beliebte Wahl für Data Warehouse-Bereitstellungen. Es ist eine ausgezeichnete Wahl für Situationen, in denen Sie nicht alle Funktionen einer NoSQL-Datenbank benötigen, aber dennoch einen NoSQL-Speicher benötigen. Die NoSQL-Speicherlösungen von HBase sind die besten auf dem Markt.
Kassandra Nosql
Cassandra ist eine leistungsstarke NoSQL-Datenbank, die sich perfekt für Anwendungen eignet, die eine hohe Verfügbarkeit und horizontale Skalierbarkeit erfordern. Cassandra ist einfach zu bedienen und bietet eine robuste Reihe von Funktionen, die es zur idealen Wahl für eine Vielzahl von Anwendungen machen.
Apache Cassandra ist ein weit verbreitetes Apache-Community-Projekt, das frei verfügbar ist. Apache Cassandra ermöglicht die Speicherung und Verwaltung von strukturierten und unstrukturierten Hochgeschwindigkeitsdaten auf mehreren Commodity-Servern. Cassandra, das in Verbindung mit Google Bigtable und Amazon Dynamo arbeitet, ermöglicht es Benutzern, Datenbanken von jedem Ort aus zu verwalten. Es bietet eine hohe Verfügbarkeit und ist frei von größeren Problemen. Cassandra wurde von einigen der größten IT-Unternehmen eingesetzt. Jeden Tag lädt Instagram etwa 80 Millionen Fotos in die Cassandra-Datenbank hoch. Es besteht aus Apache Cassandra und MongoDB. Ein Cassandra-Cluster mit mehreren Knoten ist eine sehr einfache Möglichkeit, Cassandra einfach zu skalieren, um einen plötzlichen Nachfrageanstieg zu bewältigen.
Ist Cassandra Nosql?
Eine NoSQL-Datenbank wie Cassandra kann verteilt werden. NoSQL-Datenbanken sind leichtgewichtig, Open Source, nicht relational und in ihrem Design fair verteilt. Sie zeichnen sich durch ihre Fähigkeit zur horizontalen Skalierung sowie durch ihre Fähigkeit aus, Schemata flexibel zu definieren.
Mongodb Nosql
Dokumentmodelle in MongoDB sind nicht relational, was sie zu einer Datenbank macht. Sie unterscheidet sich von traditionellen relationalen Datenbanken wie Oracle, MySQL und Microsoft SQL Server dadurch, dass es sich um eine sogenannte NoSQL-Datenbank (NoSQL = Not-only-SQL) handelt.
MongoDB ist eine der am weitesten verbreiteten NoSQL-Datenbanken und kann Daten im JSON-Format speichern. Die Leistung, Skalierbarkeit und Verfügbarkeit von MongoDB ähneln denen anderer Datenbankskript-/Analysesprachen wie SQL, Oracle und Oracle. Der Zweck dieses Kapitels ist es, die grundlegenden Konzepte und Typen von NoSQL zu erklären.
Welche Art von Nosql ist Mongodb?
Eine Dokumentendatenbank besteht aus mehreren Schlüsseln, die durch eine komplexe Datenstruktur miteinander verknüpft sind. Ein Dokument kann sowohl verschachtelt sein als auch eine Vielzahl von Schlüssel-Wert-Paaren, Schlüssel-Array-Paaren usw. enthalten. MongoDB ist als Dokumentendatenbank Google Docs sehr ähnlich.
Ist Mongodb das beste Nosql?
Die drittbeste NoSQL-Datenbank ist MongoDB, die als Allzweck-Dokumentendatenbank dienen soll. Da es dokumentorientiert ist, kann es alle Ihre Informationen an einem einzigen Ort organisieren, sodass Sie ganz einfach auf alle Informationen zu einem einzigen Thema zugreifen können.
Welche Datenbank ist die beste für Sie?
Am Ende gibt es keinen klaren Gewinner zwischen den beiden Datenbanken, die jeweils Stärken und Schwächen haben. Die Datenbank sollte auf Ihre speziellen Bedürfnisse und Präferenzen zugeschnitten sein.
Wie funktioniert Mongodb Nosql?
MongoDB ist eine kostenlos verfügbare NoSQL-Datenbank. Als nicht-relationale Datenbank kann sie strukturierte, halbstrukturierte und unstrukturierte Daten und jedes Dateiformat verarbeiten. Es werden ein dokumentenorientiertes Datenmodell und eine unstrukturierte Abfragesprache verwendet. MongoDB ist äußerst flexibel und kann mehrere Datentypen speichern und kombinieren.
Mongodb: Die erste Wahl für große und kleine Unternehmen
MongoDB ist eine ausgezeichnete Wahl für geschäftskritische Anwendungen, da es skalierbar ist und eine hervorragende Leistung bietet. Infolgedessen gehören Netflix, Uber und Airbnb zu den Unternehmen, die es seit Jahren für ihre anspruchsvollsten und größten Anwendungen einsetzen.
Die MongoDB-Plattform macht die Nutzung für Startups und kleine Unternehmen einfach. Darüber hinaus eignet es sich gut für Cloud-Speicher, sodass Unternehmen je nach Bedarf nach oben oder unten skalieren können.