
Warum skaliert Nosql besser?
Veröffentlicht: 2022-11-19Nosql-Datenbanken werden oft dafür gelobt, dass sie besser skalieren können als ihre relationalen Pendants. Es gibt einige wichtige Gründe, warum dies der Fall ist. Erstens sind nosql-Datenbanken im Allgemeinen besser horizontal skalierbar. Das bedeutet, dass sie einfach skaliert werden können, indem dem System weitere Maschinen hinzugefügt werden, anstatt die einzelnen Maschinen aufzurüsten. Zweitens sind nosql-Datenbanken so konzipiert, dass sie von Grund auf verteilt werden können. Dies bedeutet, dass sie besser in der Lage sind, mehrere Maschinen zu nutzen, von denen jede an einem anderen Teil des Datensatzes arbeiten kann. Schließlich verwenden nosql-Datenbanken einfachere Datenstrukturen als relationale Datenbanken. Dadurch sind sie in der Regel platz- und zeiteffizienter, was zu einer besseren Skalierbarkeit führt.
Datenbanken mit SQL-Semantik sind vertikal skalierbar, während Datenbanken mit NoSQL-Semantik horizontal skalierbar sind. SQL-Datenbanken speichern Datentabellen, während NoSQL-Datenbanken Daten in Dokumenten, Diagrammen oder breiten Spalten speichern. SQL-Datenbanken können mehrzeilige Transaktionen besser verarbeiten als NoSQL-Datenbanken, aber NoSQL-Datenbanken können auch besser mit unstrukturierten Daten wie Dokumenten und JSON umgehen.
Der Konsistenzaufwand wird durch die Verwendung von NoSQL-Datenbanken reduziert, die flexibel und schnell sind und daher weniger Einschränkungen als SQL-Datenbanken haben. Dadurch kann NoSQL Daten in einer Vielzahl von Formaten speichern, beispielsweise Dokumente (Schlüssel-Wert-Paare) oder Objekte (Objekte).
Warum brauchen wir MongoDB? MongoDB ist eine NoSQL-Datenbank , die keine Beziehung zwischen Daten und Speicher hat. Die Daten sind in JSON-ähnlichen Dokumenten untergebracht, auf die leicht zugegriffen werden kann. Darüber hinaus können die Dokumente durch die horizontale Skalierung einfach auf mehrere Knoten verteilt werden.
Die NoSQL-Datenbank ist in vielerlei Hinsicht besser als die relationale Datenbank. Da NoSQL-Datenbanken über flexible Datenmodelle verfügen, horizontal skalieren, extrem schnell ausgeführt und sehr einfach erstellt werden können, sind Entwickler daran gewöhnt, mit ihnen zu arbeiten. NoSQL-Datenbanken haben typischerweise sehr flexible Schemas.
Warum skalieren Nosql-Datenbanken so gut?
Nosql-Datenbanken lassen sich gut skalieren, da sie von Grund auf für die Verteilung konzipiert sind. Das bedeutet, dass sie mehrere Server nutzen können, die mehr Verarbeitungsleistung und Speicherplatz bieten als ein einzelner Server. Darüber hinaus sind nosql-Datenbanken oft hochverfügbar ausgelegt, dh sie können auch dann weiter funktionieren, wenn ein oder mehrere Server ausfallen.
Es ist schwierig, das Problem zu lösen, dass SQL-Joins so komplex sind. Die Aufgabe, zwei Tabellen zu verbinden, erfordert einen erheblichen Aufwand. Ein Beitritt kann mehrere Stunden dauern. Dies ist ein Problem, da das Skalieren einer relationalen Datenbank schwierig ist. Wenn Sie Ihre Datenbank erweitern möchten, müssen Sie weitere Server hinzufügen. Es ist wichtig, Ihrer Datenbank weitere Computer hinzuzufügen, um der gestiegenen Anzahl von Benutzern Rechnung zu tragen. Es ist schwierig, eine relationale Datenbank horizontal zu skalieren. Das Konzept einer relationalen Datenbank besteht darin, dass sie vollständig aus Computern besteht. Es ist unmöglich, Ihrem System einen weiteren Server hinzuzufügen und zu erwarten, dass die Datenbank funktioniert. Um sie verwenden zu können, muss eine neue Datenbank hinzugefügt werden. Das Hinzufügen von Benutzern zu einer relationalen Datenbank ist eine Herausforderung, da dies nur mit großen Schwierigkeiten möglich ist. Sie können Ihrem System keine neuen Computer hinzufügen und erwarten, dass die Datenbank ordnungsgemäß funktioniert. Es gibt keine Möglichkeit, Ihren Server zu ändern. SQL-Abfragen mit unbegrenzter Natur verursachen eine Vielzahl von Problemen. Dies kann durch Eingabe einer SQL-Abfrage in einen Computer erfolgen. Dies ist eine klare Absichtserklärung. SQL-Abfragen können nur wenige Textzeilen in einer Abfrage zurückgeben. Aufgrund der Schwierigkeit, Informationen in einer relationalen Datenbank zu finden, ist dies ein Problem. Sie müssen alle Daten in Ihrer Datenbank durchsuchen, um die gewünschten Informationen zu finden. Der Zugriff auf große Datenbanken kann schwierig sein, da sie eine so große Menge an Informationen enthalten.
Wie ist die Nosql-Datenbank skalierbar?
Der Hauptgrund dafür, dass NoSQL- und nicht-relationale Datenbanken die Verfügbarkeit der Konsistenz vorziehen, liegt darin, dass sie die Fähigkeit schätzen, große Datenmengen zu verarbeiten, selbst wenn die Anzahl der Datenbankknoten abnimmt. Dies ermöglicht die Speicherung großer Datenmengen, wodurch die Skalierbarkeit unterstützt wird.
Warum ist es einfach, Nosql zu skalieren?
Die Vorteile der Verwendung einer NoSQL-Datenbank sind vielfältig, aber einer der wichtigsten Vorteile ist, dass NoSQL-Datenbanken sehr einfach zu skalieren sind. Dies liegt an ihrer stark vereinfachten Struktur im Vergleich zu traditionellen relationalen Datenbanken ; NoSQL-Datenbanken lassen sich deutlich einfacher horizontal skalieren als relationale Datenbanken. Dies bedeutet, dass NoSQL-Datenbanken viel größere Workloads bewältigen und effektiver skalieren können, um die Anforderungen ihrer Benutzer zu erfüllen.
Wie skaliert Nosql horizontal?

NoSQL-Datenbanken hingegen sind horizontal skalierbar, was bedeutet, dass sie bei steigendem Datenverkehr einfach weitere Server zu ihrer Datenbank hinzufügen können, um ihn zu bewältigen. Eine NoSQL-Datenbank kann an die Anforderungen eines großen oder sich ständig weiterentwickelnden Datensatzes angepasst werden, wodurch sie leistungsfähiger und größer wird.
Was ist vertikale und horizontale Skalierung in Nosql?
Wenn Sie horizontal skalieren, können Sie Ihrem Ressourcenpool dadurch weitere Maschinen hinzufügen, während Sie bei vertikaler Skalierung vorhandenen Maschinen mehr Rechenleistung (CPU, RAM) hinzufügen können.
Die Vorteile der Verwendung von Mongodb
Darüber hinaus ermöglichen die Replikationsfunktionen von MongoDB die Verteilung von Daten auf mehrere Knoten im Falle eines Nachfrageanstiegs. Anders ausgedrückt: Selbst wenn Ihre Daten über eine große Anzahl von Knoten verteilt sind, funktionieren Ihre Anwendungen weiterhin ordnungsgemäß.
Welche Vorteile bietet das Erlernen von MongoDB?
MongoDB bietet neben seiner Skalierbarkeit eine Reihe von Vorteilen. Es sollte in erster Linie einfach zu erlernen und zu verwenden sein. Es hat auch ein hohes Maß an Geschwindigkeit und Effizienz. Der dritte Vorteil des Programms besteht darin, dass es ein hohes Maß an Datenpersistenz und -konsistenz bietet. Schließlich sind die Kosten des Produkts niedrig.
Wie kann Mongodb horizontal skalieren?
Es bietet einen integrierten Mechanismus zum Verteilen von Daten auf mehrere Server, um horizontal zu skalieren. Die Umschaltfläche auf der Konfigurationsseite der Atlas-Benutzeroberfläche kann verwendet werden, um diesen Vorgang zu aktivieren, der als Sharding bezeichnet wird. Sie können auch durch Sharding Null Ausfallzeiten erreichen.
Die Vorteile einer Graphdatenbank: Neo4j und Kafka
Einer der Vorteile von Neo4j ist, dass es eine unbegrenzte horizontale Skalierbarkeit unterstützt. Mithilfe von Sharding kann Neo4j geschäftskritische Anwendungen in Minuten bis Millisekunden mit deutlich reduziertem Ressourcenverbrauch unterstützen. Das Commit-Log von Kafka wird horizontal verteilt und ermöglicht fehlertolerante, verteilte Operationen. Da waren ein paar ausgefallene Wörter drin, also gehen wir sie einzeln durch und sehen, was sie bedeuten. Der erste Punkt, den man über Diagramme verstehen muss, ist, dass sie nicht dasselbe sind wie herkömmliche Datenbanken. Datenbanktabellen werden in traditionellen Datenbanken verwendet, um strukturierte Daten zu speichern. Die Datenstruktur, die in einer Graphendatenbank verwendet wird, ist dagegen speziell zum Speichern von Graphen ausgelegt. Es gibt zwei Arten von Graphen: Knoten und Kanten. Der Knoten stellt ein Element dar, das durch ein Datenelement dargestellt wird, während die Kante die Verbindung zwischen den beiden Knoten darstellt. Mit anderen Worten, eine Graphdatenbank ist in keiner Weise ähnlich wie eine herkömmliche Datenbank eingeschränkt. Eine herkömmliche Datenbank beispielsweise erlaubt es nicht, mehr als eine Tabelle zu enthalten. Graphdatenbanken hingegen speichern Daten im Arbeitsspeicher oder auf einer Speicher-Engine. Darüber hinaus kann eine Graphdatenbank horizontal skaliert werden, was bedeutet, dass sie eine größere Anzahl von Knoten und Kanten aufnehmen kann als eine Standarddatenbank. Diese Daten sind außerdem fehlertolerant, was ein weiterer wesentlicher Vorteil von Graphdatenbanken ist. Infolgedessen kann es mit einem Ausfall fertig werden und dennoch ordnungsgemäß funktionieren. Ein Knoten im Graphen kann beispielsweise immer noch entfernt werden, wenn er fehlschlägt, aber der Rest der Graphendatenbank funktioniert weiterhin. Herkömmliche Datenbanken hingegen könnten aufgrund des Ausfalls einer ihrer Tabellen nicht mehr funktionieren. Graphdatenbanken sind aufgrund all dieser Funktionen eine leistungsstarke Datenstruktur, die für eine Vielzahl von Anwendungen nützlich sind. Mit dem Leistungsvorteil von Minuten bis Millionen gegenüber anderen Datenbanken ist es die Datenbank für unternehmenskritische Anwendungen. Wenn Sie nach einer Datenbank suchen, die horizontal skaliert werden kann, ist dies die richtige für Sie.

Kann SQL Server horizontal skaliert werden?
Eine traditionelle SQL-Datenbank kann normalerweise nicht horizontal für Schreibvorgänge skaliert werden, da wir keine weiteren Server hinzufügen können, aber wir können immer noch andere Computer über schreibgeschützte Replikate hinzufügen. Mit Write Ahead Log werden alle Schreibvorgänge auf dem Hauptserver ausgeführt und an andere Maschinen weitergeleitet.
Ist die horizontale Skalierung billiger als die vertikale Skalierung?
Es gibt zwei Hauptgründe, warum die horizontale Skalierung möglicherweise kostengünstiger ist als die vertikale Skalierung. Der erste Nachteil des Hinzufügens neuer Server zu einer bestehenden vertikalen Skalierungslösung besteht darin, dass dies schnell zu einer übermäßig teuren und zeitaufwändigen Investition werden kann. Durch die horizontale Skalierung sind die Kosten in der Regel geringer, da zusätzliche Knoten hinzugefügt werden können, ohne dass zusätzliche Kosten entstehen.
Ein Grund für die geringeren Kosten der horizontalen Skalierung ist, dass sie häufig effizienter ist. Um der erhöhten Last gerecht zu werden, müssen Daten zwischen Servern in einer vertikalen Serverfarm übertragen werden, was zu langsameren Antwortzeiten und erhöhtem Datenverkehr führt. Wenn Daten vertikal skaliert werden, lassen sie sich leichter verteilen, was zu einer höheren Leistung führt.
Es ist wichtig, die spezifischen Anforderungen jeder Organisation zu berücksichtigen, wenn Sie eine Entscheidung über die Skalierung treffen, da sowohl die vertikale als auch die horizontale Skalierung ihre eigenen Vor- und Nachteile haben. Bei der Entscheidungsfindung ist es wichtig, alle relevanten Faktoren sorgfältig abzuwägen.
Nosql vs. SQL-Skalierbarkeit
Der Hauptunterschied zwischen Nosql und Sql besteht darin, dass Sql auf dem relationalen Modell basiert, während Nosql auf dem nicht-relationalen oder verteilten Modell basiert. SQL-Datenbanken sind skalierbarer als Nosql-Datenbanken.
Es wird nicht empfohlen, relationale Datenbanken in jeder Anwendung zu verwenden. Obwohl sie gut für Anwendungen geeignet sind, die ein hohes Maß an Verfügbarkeit, Sicherheit und Skalierbarkeit erfordern, sind sie nicht gut für Anwendungen geeignet, die diese Funktionen nicht erfordern. Sie sollten nicht für die Verwendung in relationalen Datenbanken wie NoSQL-Datenbanken in Betracht gezogen werden. MongoDB beispielsweise ist eine NoSQL-Datenbank, die für Anwendungen mit hoher Leistung und Skalierbarkeit verwendet werden kann. Sie eignen sich weniger für Anwendungen, die häufige Verfügbarkeit und Sicherheitsupdates erfordern.
Die Leistungsfähigkeit von Nosql-Datenbanken
Darüber hinaus sind NoSQL-Datenbanken effizienter, da sie sowohl horizontal skalierbar als auch vertikal robust sind. NoSQL-Datenbanken können mehr Anfragen pro Sekunde verarbeiten als herkömmliche SQL-Datenbanken, da sie Daten verteilt speichern.
Nosql-Sharding
Es ist eine Art von Muster, das in der NoSQL-Ära verwendet wird, um Daten zu partitionieren. Partitionierungsmuster platzieren einzelne Festplatten auf potenziell separaten Servern auf der ganzen Welt. Das Scale-out ermöglicht die Unterstützung von Menschen auf der ganzen Welt, um auf verschiedene Teile des Datensatzes zuzugreifen.
Können Sie eine Nosql-Datenbank teilen?
Daten können auf verschiedene Weise in Shards aufgeteilt werden. Sie können entweder SQL- oder NoSQL-Datenbanken verwenden, um Shards zu speichern.
Die Vorteile der Normalisierung Ihrer Daten
Bei der Arbeit mit nicht standardmäßigen Daten kann es schwierig sein sicherzustellen, dass Abfragen schnell ausgeführt werden und die Daten leicht lesbar und verständlich sind. Indem Sie Ihre Daten anpassen, können Sie sicherstellen, dass sie sich vorhersehbarer verhalten und einfacher zu handhaben sind.
Verwendet Mongodb Sharding?
Das Verteilen von Daten zwischen mehreren Maschinen wird als Scattering bezeichnet. In MongoDB-Bereitstellungen gibt es viele große Datenmengen und viele Operationen mit hohem Durchsatz, daher ist Sharding eine großartige Option. Ein Server mit einer Kapazität von weniger als 1 kann durch eine große Datenbank mit vielen Daten oder eine Anwendung mit hohem Durchsatz herausgefordert werden.
Vorteile einer Datenbank mit mehreren Knoten
Dieser Ansatz bringt mehrere Vorteile mit sich. Bei einem Knotenausfall gehen Daten verloren. Ein Knoten kann mehr Lese- und Schreibvorgänge verarbeiten als nur ein Knoten. Beim Hinzufügen oder Entfernen von Knoten müssen Sie zuerst Daten neu zuweisen.
Welche Db eignet sich am besten zum Sharding?
Putty, auch bekannt als horizontale Partitionierung, ist ein bekannter Scale-out-Ansatz für Datenbankvorgänge. Amazon RDS (Amazon Relational Database Service) ist ein Cloud-basierter verwalteter relationaler Datenbankdienst, der viele Funktionen für einfaches Sharding bietet.
Indizierung vs. Sharding: Was ist der Unterschied?
Der Begriff „Sharding“ bezieht sich auf den Prozess der Aufteilung einer Tabelle in mehrere Teile, damit sie von mehreren Computern verarbeitet werden kann. Wenn Daten als Teil eines Shards über Computer verteilt werden, sind sie besser zu verwalten. Die Daten werden auf diese Weise verarbeitet, damit verschiedene Teile des Systems leicht darauf zugreifen können.
Indizierung ist eine Technik zum Speichern von Spalten in einer Datenstruktur wie B-Tree oder Hashing. Je schneller Sie mithilfe eines Index suchen oder eine Abfrage verknüpfen können, desto weniger Zeit müssen Sie mit der Suche nach den richtigen Werten verbringen. Abgesehen von Indizes werden sie für andere Zwecke benötigt, beispielsweise zur Beschleunigung des Datenabrufs aus Datenbanken. Die Hauptfunktion von Sharding hingegen besteht darin, Daten zu speichern.
In ähnlicher Weise können Indizierung und Sundowning zum Verwalten von Daten verwendet werden. Die Datenbankindizierung hingegen speichert Daten in einer Datenbank, während Sharding Daten auf Maschinen verwaltet. Im Allgemeinen unterscheiden sich die beiden darin, dass Indizes für den Sharding-Vorgang erforderlich sind, der Datenabruf jedoch nicht.
Was ist Sharding und Replikation in Nosql?
Was ist der Unterschied zwischen Sharding und Replikation? Datenreplikation ist die Übertragung von Daten von einem primären Serverknoten zu einem anderen. Als Backup kann dies die Datenverfügbarkeit verbessern und gleichzeitig die Wiederherstellung des primären Servers unterstützen, wenn dieser ausfällt. Es kann verwendet werden, um auf der Grundlage eines Shard-Schlüssels über mehrere Server hinweg zu skalieren.
Abwägen der Vor- und Nachteile von Replikation und Sharding
Sowohl Replikation als auch Sharding sind gute Optionen für die Verwaltung Ihrer Daten. Eine Replikation kann bei der horizontalen Skalierung von Lesevorgängen helfen, aber ein Shard kann bei der horizontalen Skalierung von Datenschreibvorgängen helfen, indem Daten mithilfe eines Shard-Schlüssels auf mehrere Server verteilt werden. Um Zugriff auf einen Shard zu erhalten, müssen Sie zunächst einen guten Schlüssel auswählen.
Darüber hinaus kann das Speichern von Daten in einem Shard die Verfügbarkeit von Daten verbessern, indem mehreren Servern der Zugriff auf dieselben Daten ermöglicht wird, wenn einer ausfällt. Schwieriger kann es allerdings sein, Daten abzufragen, die auf mehrere Server verteilt sind.
Es ist wichtig, die Vor- und Nachteile jeder Option abzuwägen, bevor Sie eine Entscheidung treffen.
Nosql-Bewegung
In letzter Zeit hat es in der Softwareentwicklungs-Community eine Bewegung in Richtung sogenannter „NoSQL“-Datenbanken gegeben. Dies sind Datenbanken, die nicht das herkömmliche relationale Modell verwenden und stattdessen ein flexibleres Datenmodell ohne Schema verwenden. Dadurch eignen sie sich besser für moderne Webanwendungen, bei denen das Datenmodell oft flüssiger ist und sich häufiger ändert.
Nosql-Datenbanken auf dem Vormarsch: Warum sie immer beliebter werden
Die steigende Popularität von NoSQL-Datenbanken in den letzten Jahren lässt sich auf eine Vielzahl von Faktoren zurückführen. Das erste Problem mit relationalen Datenbanken war, dass sie während des Höhepunkts der Popularität des Internets in den 1990er Jahren nicht mit der Nachfrage Schritt halten konnten. Als Folge dieser Entwicklung reagierten nicht-relationale Datenbanken besser auf den Datenzufluss.
Ein weiterer Grund für die Beliebtheit von NoSQL-Datenbanken besteht darin, dass sie eine größere Flexibilität bei der Behandlung von Daten bieten. MongoDB-Datenbanken können eine größere Ausdruckskraft erreichen, indem sie ein beliebiges Datenmodell verwenden, das ausdrucksstark genug ist, anstatt das traditionelle tabellenbasierte Modell zu verwenden. Dadurch haben Entwickler mehr Freiheit, Daten so effizient wie möglich zu speichern.
NoSQL-Datenbanken stehen vor einigen Herausforderungen, bieten jedoch erhebliche Vorteile gegenüber herkömmlichen relationalen Datenbanken in Bezug auf Flexibilität und Effizienz.
Nosql-Datenbanken
Eine Nosql-Datenbank ist eine Datenbank, die nicht das traditionelle SQL als Abfragesprache verwendet. Nosql-Datenbanken werden häufig für Big-Data-Anwendungen verwendet, bei denen der Umfang der Daten die Verwendung von SQL unpraktisch macht.
Was sind Nosql-Datenbanken?
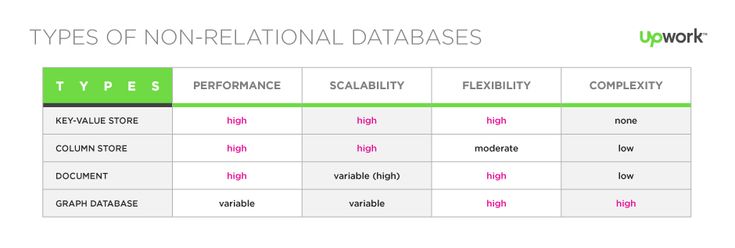
Daten werden in NoSQL-Datenbanken (auch bekannt als SQL) anders gespeichert als in relationalen Datenbanken. Anhand ihres Datenmodells lassen sich NoSQL-Datenbanken in verschiedene Typen einteilen. Dokumenttypen, Schlüsselwerttypen, Breitspaltentypen und Diagrammtypen sind die häufigsten.
Was ist ein Beispiel für ein Nosql?
Auf dem Markt sind tabellenbasierte NoSQL-Datenbanken wie Cassandra, HBase und Hypertable zu finden.