
Warum Eventual Consistency für Datenspeicher unerlässlich ist
Veröffentlicht: 2022-11-17Eventual Consistency ist eine Eigenschaft von Datenspeichern, bei denen Daten, die in den Speicher geschrieben wurden, möglicherweise nicht sofort zum Lesen verfügbar sind. Der Speicher stellt die Daten eventuell zum Lesen zur Verfügung, dies kann jedoch nicht garantiert werden. Datenspeichersysteme, die eventuelle Konsistenz aufweisen, können dies aus einer Vielzahl von Gründen tun, einschließlich der Notwendigkeit, die Leistung zu verbessern oder die Verfügbarkeit angesichts von Netzwerkpartitionen sicherzustellen.
Es ist viel schwieriger, eine Dokumentendatenspeicherimplementierung durchzuführen, als ein relationales Modell. Darüber hinaus sind Inflight-Store-Daten viel schwieriger zu konvertieren als RDBMS-Daten. Diese Chance verpassen Bauherren und Architekten, die die Folgen ihrer Fehler fürchten oder sich ihrer nicht bewusst sind. Sie werden das, woraus atomare Transaktionen bestehen sollten, in logische Teile zerlegen und dabei vergessen, dass Replikation und Latenz Dinge sind, und Drittsysteme in sie hineinziehen. Irgendwann wird das gesamte System ausgelagert und jemand anderes übernimmt, wenn die Abteilung schließlich aufgelöst wird.
Infolgedessen unterstützen NoSQL-Datenbanken häufig eher eine graduelle Konsistenz als eine konstante Konsistenz. Eine starke Datenkonsistenz ist nicht erforderlich, da sie keine Datenbanktransaktionen unterstützen. Es ist immer möglich, eine letztendliche Konsistenz zu erreichen, indem sichergestellt wird, dass alle Updates gleichzeitig an alle Replikate geliefert werden.
Die Tatsache, dass sich Eventual Consistency auf den Replikationsprozess zwischen primären und sekundären Knoten bezieht, und die Tatsache, dass Ihre Anwendung beim Lesen von Daten möglicherweise nicht immer auf dem neuesten Stand ist, machen primäre Lesevorgänge zum Weg der Wahl.
Wenn NoSQL-Datenbanken das Eventual Consistency Model verwenden, bieten sie nicht das gleiche Maß an Datenkonsistenz wie SQL-Datenbanken. Wenn die Daten nicht konsistent sind, sind sie für Transaktionen wie Bank- und Geldautomatentransaktionen ungeeignet, die eine sofortige Integrität erfordern.
Was bedeutet eventuelle Konsistenz in Nosql?
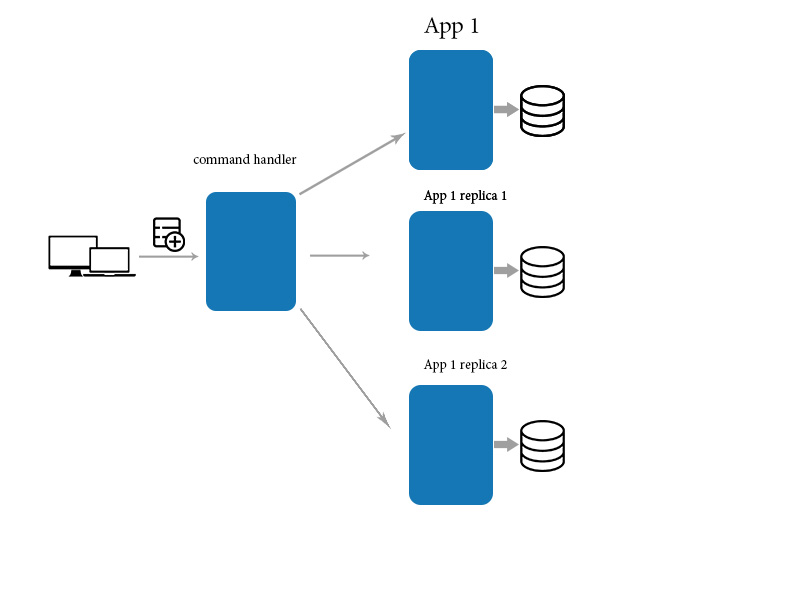
Eventual Consistency ist eine Garantie dafür, dass, wenn keine neuen Aktualisierungen an einem Datenelement vorgenommen werden, schließlich alle Zugriffe auf diese Daten den zuletzt aktualisierten Wert zurückgeben. Dies steht im Gegensatz zu starker Konsistenz , die erfordert, dass jeder Lesevorgang den aktuellsten Schreibvorgang erhält.
Das Konzept des schließlich konsistenten Verhaltens gewann erstmals Ende der 1970er Jahre an Bedeutung. Amazon veröffentlichte DynamoDB vor einem Jahrzehnt, was die Popularität des Begriffs auslöste. Die Datenbank NoSQL wurde entwickelt, um soziale Medien und Streaming-Dienste zu unterstützen. Unstrukturierte Daten wie Bilder, Videos und Audiodateien können problemlos verwaltet werden. Mit dem Volt Active Data-Modell kann sichergestellt werden, dass Daten in Echtzeit über mehrere Datenbanken hinweg repliziert werden. Datenplattformen sind sofort konsistent und verhindern inkonsistente Schreib- und Lesevorgänge. Infolgedessen sind sie in der Lage, die Latenzanforderungen von 5G zu erfüllen, indem sie diesen Prozess schnell abwickeln.
Konsistenz kann ein wertvolles Merkmal eines verteilten Systems sein. Es stellt sicher, dass Werte gespeichert und von mehreren Knoten konsistent abgerufen werden, unabhängig davon, ob diese Knoten gleichzeitig aktualisiert werden. Für Systeme wie das Domain Name System ist es von entscheidender Bedeutung, dass sie eine konsistente Ansicht der Daten beibehalten können.
Die Konsistenz, die mit dem Abschluss eines Projekts einhergeht, kann manchmal schwierig zu erreichen sein. Aufgrund der Vielfalt der verfügbaren Methoden kann es schwierig sein, sicherzustellen, dass alle Knoten die gleichen Updates erhalten. Der Wert der Konsistenz ist unbestreitbar, und Systeme, die sie verwenden, können auf lange Sicht zuverlässiger sein.
Was ist eventuelle Konsistenz in Cassandra?

Cassandra erreicht all diese Funktionen mit einem konsistenten Speichersystem, das die Anforderungen an Leistung, Zuverlässigkeit, Skalierbarkeit und Verfügbarkeit in der Produktion erfüllen kann. Schließlich bedeutet konsistent, dass alle Updates schließlich mit allen Replikaten geteilt werden.
Konsistenz ist etwas, das Cassandra mit seiner einstellbaren Konsistenz erreichen kann. Das Ergebnis R=w <=N sollte konsistent sein, wenn N die Anzahl der Knoten ist. Um Konsistenz zu erreichen, wird jede Spalte und jedes Feld jeder Spalte von Cassandra gesichert. Hinter diesem Zustand steckt ein Mechanismus, der es ihm ermöglicht, konsistent zu sein. R + W ist ein Körper, wenn N durchgehend fest ist. Der Client muss die entsprechende Konsistenzebene auswählen (Null, Beliebig, Eins, Quoram oder Keine). Die Konsistenz tritt nicht sofort ein, da Schreibvorgänge trotz des Replikationsfaktors von 1:1 auf dem Knoten gepuffert werden, an den Sie sie senden.
Cassandra verwendet konsistentes Hashing, was bedeutet, dass, wenn ein Satz von Schlüsseln mit demselben Algorithmus und denselben Hash-Funktionsparametern gehasht wird, die Hash-Funktion immer dasselbe Ergebnis liefert.
Dies ist von entscheidender Bedeutung, da Sie einen Schlüssel in mehreren Buckets aufbewahren können, ohne sich Sorgen machen zu müssen, dass er mit irgendetwas kollidiert.
Infolgedessen wird angenommen, dass konsistentes Hashing effizienter ist, da es Cassandra ermöglicht, mehr Daten auf demselben Speicherplatz zu speichern.
Sie müssen sicherstellen, dass Ihre Schreib- und Lesezähler konsistent sind, wenn Sie eine starke Konsistenz erreichen möchten. Die Konsistenz von Cassandra basiert auf der Annahme, dass alle Client-Lesevorgänge immer auf dem neuesten Stand gehalten werden, indem automatisch die neuesten geschriebenen Daten abgerufen werden. Konsistentes Hashing wird verwendet, um sicherzustellen, dass die Hash-Funktion immer das gleiche Ergebnis für zwei verschiedene Schlüssel liefert, wenn sie mit demselben Algorithmus und denselben Hash-Funktionsparametern zusammen gehasht werden. Es ist wichtig, einen Schlüssel in mehreren Buckets aufzubewahren, da Kollisionen kein Problem darstellen. Cassandra hat eine höhere Leistungsrate, da es bei konsistentem Hashing mehr Daten im gleichen Speicherplatz speichern kann.
Was ist die Standardkonsistenzstufe in Cassandra?
Rufen Sie einfach QUBEDBUILDER auf, um den Java-Treiber zu verwenden. Legen Sie theConsistencyLevel fest, um sicherzustellen, dass die Konsistenzebene für jede Einfügung in insertInto festgelegt ist. Beim Schreiben und Lesen wird allen Operationen ein Konsistenzlevel von eins zugeordnet.
So stellen Sie die Datenkonsistenz mit Cassandra sicher
Der Hauptgrund dafür ist, dass die Schlüssel nicht in Buckets gespeichert werden, bis sie gehasht werden. Cassandra speichert auch den Schlüssel und den Zeiger auf den Bucket in derselben Zeile in der Tabelle. Cassandra vergleicht die Zeile für den Schlüssel und den Zeiger für einen Wert über einem Schlüsselwert, um zu bestimmen, welche Zeile welchem Schlüssel entspricht. Wenn beide wahr sind, nimmt Cassandra den Wert aus dem Bucket am Pointer. Der Wert eines Schlüssels wird immer in derselben Zeile gespeichert, unabhängig davon, wie oft er abgefragt wird, solange er in derselben Zeile gespeichert wird. Bei mehrmaliger Wiederholung einer Messung bleiben die Daten konstant. Wenn Sie die Konsistenzebene für Ihre aktuelle Sitzung ändern möchten, verwenden Sie einfach den Befehl CONSISTENCY aus der Cassandra-Shell (CQLSH). Wenn Sie sehen möchten, wie weit Sie auf Ihrem Konsistenzniveau sind, können Sie CONSISTENCY verwenden; aus der Schale. [E-Mail geschützt] | Konsistenz: Konsistenz Die aktuelle Konsistenzstufe ist eins.
Was ist Update-Konsistenz in Nosql

Die Aktualisierungskonsistenz in NoSQL ist der Prozess der Aktualisierung von Daten über mehrere Knoten in einer NoSQL-Datenbank . Dieser Prozess stellt sicher, dass alle Knoten in der Datenbank über dieselben Daten verfügen und dass die Daten über alle Knoten hinweg konsistent sind.
Was ist Update-Konsistenz in Nosql?
Die Konsistenz der Kopien derselben Daten innerhalb desselben replizierten Datenbanksystems [1], im Gegensatz dazu, wie sich die Daten ändern, ist einfach eine Frage der Wahl. Dies tritt auf, wenn die Messwerte für ein bestimmtes Datenobjekt nicht mit der vorherigen Aktualisierung übereinstimmen.

Was ist Update-Konsistenz in der Datenbank?
Das Konzept der Konsistenz in Datenbanksystemen bringt die Anforderung mit sich, dass jede gegebene Datenbanktransaktion nur die Änderung betroffener Daten in der erlaubten Weise erlaubt. Daten, die in die Datenbank geschrieben wurden, müssen alle definierten Regeln einhalten, wie z. B. Einschränkungen, Kaskaden, Trigger und beliebige Kombinationen davon.
Eventuelle Konsistenz Mongodb

Eventual Consistency ist ein technischer Begriff, der bedeutet, dass die Daten, die Sie lesen, nicht immer konsistent sind; es wird sich jedoch mit der Zeit verbessern. Die einzige Möglichkeit, dies zu tun, besteht darin, aus sekundären Quellen zu lesen, indem Sie eine der readPreferences verwenden, die aus sekundären Quellen lesen können.
Als ersten Schritt werde ich einige aktuelle MongoDB-Codebeispiele durchgehen, die gegen die Causal Consistency Guarantee verstoßen. Beim ersten Versuch, dies zu lösen, wird die Mehrheits-Lese- und Schreibmethode verwendet. Als Ergebnis werden wir uns logische Uhren und korrelierte Sitzungen in Mongo ansehen. Wir werden den Mongo C#-Treiber für diese Anwendung verwenden, aber ich möchte ihn in Ruhe lassen. Eine Mehrheit der Replikatsatzmitglieder muss einen Majority Read signieren, wenn Daten von einer Abfrage bestätigt wurden. Wenn wir ein Mehrheitslesen gefolgt von einem Mehrheitsschreiben verwenden, kann es so aussehen, als könnten wir unser „Read Your Write“-Problem lösen. Ein sekundärer Server verwaltet einen In-Memory-Snapshot des letzten Majority Write.
Readconcern-Einstellung von Mongodb
Ein Client muss bestimmen, wie viele Daten er lesen darf, damit readConcern erfüllt wird, bevor er mit der Erfüllung von readConcern beginnen kann. In MongoDB sollte readConcern vorzugsweise auf maxRead gesetzt werden.
Eventuelle Konsistenz vs. starke Konsistenz
Sie liefert aktuelle Daten mit geringerer Latenz als andere Technologien, erfordert aber auch ein hohes Maß an Persistenz. Da die Datenbank möglicherweise nicht auf allen Knoten über aktualisierte Daten verfügt, kann die letztendliche Konsistenz eine geringe Latenzzeit bieten, aber möglicherweise nicht immer auf Leseanforderungen mit veralteten Daten antworten.
Konsistenz bezieht sich im Allgemeinen auf die Fähigkeit einer Datenbank, Transaktionen zu verarbeiten und gleichzeitig die Datenintegrität zu wahren. Datenbanksysteme, die den ACID-Vorschriften entsprechen, sind in der Regel langsam, schwer zu skalieren und unerschwinglich teuer in Wartung und Betrieb. Einige RDBMS-Systeme mildern ACID-Garantien. Die Basisgarantien einer NoSQL-Datenbank werden als NoSQL-Algorithmen bezeichnet. Dadurch kann die Basis zur Erhöhung der Verfügbarkeit genutzt werden und gleichzeitig die Lockerung starrer Standards ermöglichen. Infolgedessen erfordern NoSQL-Datenbanken ein erhebliches Maß an Konsistenz, um stabiler zu sein. Wenn die endgültige Konsistenz von DynamoDB durch eine Ringtopologie bestimmt wird, wird sie zu Cassandra.
Um konsistente Ergebnisse zu verarbeiten, wird in Redis eine Master-Slave-Topologie verwendet. ScyllaDB ist ein Echtzeit-Big-Data-Datenbankunternehmen mit Sitz in den Niederlanden. Außerdem kann damit für jede Operation (Lesen oder Schreiben) ein Konsistenzlevel angegeben werden. Da sich Daten möglicherweise auf einem Koordinatorknoten geändert haben, aber noch nicht auf allen erforderlichen Replikaten aufgezeichnet und gespeichert wurden, liefern ScyllaDB-Cluster konsistente Ergebnisse.
Einer der wichtigsten Aspekte der Computersystemkonsistenz ist seine Konsistenz. Daten können auf diese Weise gehandhabt werden, unabhängig davon, wie sie gespeichert sind, da dies Konsistenz gewährleistet. Infolgedessen übernehmen beispielsweise Finanzinstitute häufig Systeme, die im Laufe der Zeit konsistent sind. Die meisten Transaktionen werden als Ergebnis dieses Prozesses so schnell wie möglich abgeschlossen. Die Bearbeitung einer Transaktion kann bis zu 24 Stunden dauern, dies kann jedoch nicht garantiert werden. Dieses Phänomen wird durch ein allgemeines Muster konsistenter Systeme verursacht, die schließlich existieren werden.
Datenkonsistenz: So wählen Sie den richtigen Typ für Ihre Anforderungen aus
Wenn es um Daten geht, gibt es zwei Arten: starke und schwache.
Da alle Daten in einem Knoten unabhängig davon, wo sie sich befinden, konsistent sind, sind sie immer gleich. Diese Methode ist die zuverlässigste Methode zur Datenkonsistenz, kann jedoch schwierig zu implementieren sein.
Der Mangel an Konsistenz weist darauf hin, dass es keine Garantie dafür gibt, dass alle Knoten gleichzeitig über dieselben Daten verfügen. Diese Konsistenz ist anfälliger für Korruption, kann aber manchmal auch effizienter sein.
Eventuelle Konsistenz Cassandra
Eventual Consistency ist ein Konsistenzmodell, das in verteilten Systemen verwendet wird. In einem schließlich konsistenten System kann es einige Zeit dauern, bis sich Operationen verbreiten und an allen Knoten sichtbar werden. Eine Schreiboperation gilt als erfolgreich, wenn sie an dem Knoten, an dem sie ausgegeben wurde, dauerhaft ist. Eine Leseoperation gilt als erfolgreich, wenn sie die letzte Schreiboperation zurückgibt. Eventual Consistency wird häufig in Systemen verwendet, die über mehrere Rechenzentren verteilt sind. In diesen Systemen ist es wegen der erhöhten Latenz und der Möglichkeit von Fehlern nicht praktikabel, eine starke Konsistenz aufrechtzuerhalten. Eventual Consistency ermöglicht es dem System, auch bei Ausfällen weiter zu arbeiten. Cassandra ist eine verteilte Datenbank, die Eventual Consistency verwendet. Cassandra wurde entwickelt, um große Datenmengen mit hoher Verfügbarkeit zu verarbeiten. Cassandra wird von einigen der größten Unternehmen der Welt verwendet, darunter Facebook, Netflix und Instagram.
Es ist eine Open-Source-NoSQL-Datenbank mit einer hochverfügbaren und skalierbaren Architektur. Die Cluster-übergreifende Replikation von Daten ist erforderlich, um eine hohe Verfügbarkeit in Cassandra zu erreichen. Es stehen zwei Replikationsstrategien zur Verfügung: SimpleStrategy und NetworkTopology. Die Konsistenz, wie jede Datenzeile durch Replikate dargestellt wird, spiegelt wider, wie aktuell und synchron sie sind. Die Konsistenzebene gibt an, wie viele Replikknoten auf die neuesten konsistenten Daten antworten müssen, bevor der Koordinator die Daten erfolgreich an den Client zurücksenden kann. Abhängig von der vom Client angegebenen Konsistenzebene können wir entweder die Konsistenzebene für jede Schreibabfrage oder die Konsistenzebene für jede globale Abfrage festlegen. Denken Sie beim Schreiben an den Consistency Level (CL).
In 5.1 gibt nur ein Replikatknoten Daten zurück, während in 5.2 51 % der Replikatknoten in allen Rechenzentren Daten zurückgeben. Wir begannen mit der Definition einer gewünschten Konsistenzebene (CL) für Cassandra-Schreib- und -Lesevorgänge. Daher lesen Sie unabhängig davon, wie lange es zwischen dem letzten Schreibvorgang und dem nächsten dauert, die zuletzt geschriebenen Daten in den Cluster ein. Um Konsistenz zu gewährleisten, können wir ein globales oder ein Write-Query-Konsistenzniveau angeben. Hier sind einige Beispiele für CL on read, die Sie im Diagramm unten sehen können.
Was ist Eventual Consistency in Microservices?
Tatsächlich ist Eventual Consistency eine Methode, um die Datenkonsistenz und -verfügbarkeit durch asynchrone Kommunikation aufrechtzuerhalten und sicherzustellen, dass Fehler in einem bestimmten Prozess behoben werden, ohne zum vorherigen Zustand des Prozesses zurückkehren zu müssen.
In den meisten Fällen sind wir auf Probleme mit Dateninkonsistenzen in einem Softwaresystem gestoßen. Es basiert auf einem dezentralen Ansatz und ist von der Natur inspiriert. Da Cloud Computing, Elastic Computing und Storage immer beliebter werden und Container-Technologie und -Orchestrierung immer beliebter werden, wird eine beträchtliche Anzahl neuer Anwendungen unter Verwendung des Microservices-Architekturstils erstellt. Wenn atomare Transaktionen mehrere Dienste umfassen, werden sie als eine Kette einfacher atomarer lokaler Transaktionen auf jeder Dienstebene betrachtet. Wenn eine Transaktion in dieser Kette aufgrund eines bestimmten Umstands fehlschlägt, löst dies im Wesentlichen eine Undo-Operation aus. Auch ein Kompensationsaufruf oder eine Transaktion kann fehlschlagen. Datenkonsistenz und -integration sind zwei der gängigsten Ansätze für das Datenmanagement, nämlich Kafka und CDC.
CDC eignet sich für große verteilte Architekturen, da es nicht übermäßig leistungsorientiert ist. Die Inflexibilität der CDC bei Schemaänderungen ist einer der größten Nachteile. Dies schränkt die Weiterentwicklung des Service-DB-Schemas stark ein.