
Warum der Beitritt zu NoSQL-Datenbanken kompliziert ist
Veröffentlicht: 2022-11-19NoSQL-Datenbanken erfreuen sich zunehmender Beliebtheit als Alternative zu traditionellen relationalen Datenbanken . Eines der Hauptmerkmale relationaler Datenbanken ist jedoch die Möglichkeit, tabellenübergreifende Verknüpfungen durchzuführen. Unterstützt NoSQL Joins? Die Antwort lautet: Es kommt darauf an. Einige NoSQL-Datenbanken unterstützen Verknüpfungen, andere nicht. Und selbst für diejenigen, die Joins unterstützen, kann die Art und Weise, wie sie implementiert werden, erheblich variieren. Schauen wir uns also genauer an, wie Joins in NoSQL-Datenbanken unterstützt werden. Wir beginnen damit, uns diejenigen anzusehen, die Joins nicht unterstützen, bevor wir zu denen übergehen, die dies tun.
Die allgemeinen Join-Operatoren , die in traditionelleren relationalen Datenbanken verwendet werden, werden von Oracle NoSQL Database nicht unterstützt. Es unterstützt jedoch die Verwendung einer eindeutigen Art von Join zwischen Tabellen, die Mitglieder derselben Tabellenhierarchie sind. Da nur kolokalisierte Zeilen verknüpft werden können, können diese Verknüpfungen effizient ausgeführt werden.
Ab sofort unterstützt Oracle NoSQL Database keine allgemeinen Join-Operatoren, die in herkömmlichen relationalen Datenbanken verwendet werden.
MongoDB-Joins können jetzt in MongoDB 3.2 dank einer neuen Lookup-Operation durchgeführt werden, die verwendet werden kann, um Join-Operationen für Sammlungen durchzuführen.
Tritt der Mongodb-Support bei?
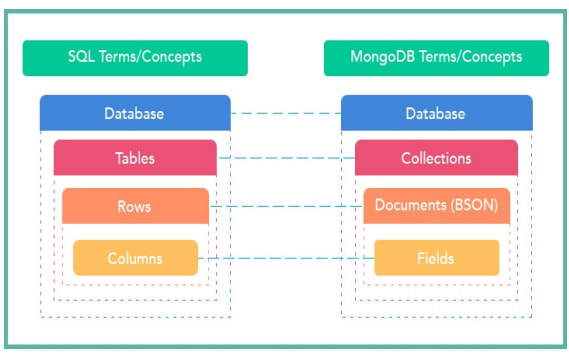
Mongodb unterstützt kein Join, aber es unterstützt die manuelle Referenzverknüpfung. Sie können den $lookup-Operator verwenden, um eine linke Verknüpfung, eine rechte Verknüpfung oder eine vollständige äußere Verknüpfung für zwei Sammlungen auszuführen.
MongoDB unterstützt keine Left Outer Joins, aber Sie können dies mit der $lookup-Phase tun. Sie können angeben, welche Sammlung Sie mit welchen Feldern verbinden möchten und wie die Sammlung verglichen werden soll, indem Sie die Phase $lookup auswählen. Sie können die Stufe $lookup verwenden, um die Mitarbeiter- und Auftragssammlungen derselben Sammlung hinzuzufügen, indem Sie die Felder employee_id und order_id im Feld Mitarbeitersammlung auswählen und angeben, dass die Mitarbeitersammlung zur Auftragssammlung gehören soll. Zurückgegeben werden die identischen Mitarbeiter- und Auftrags-IDs.
Kräfte bündeln: Wie ein Student die Note machte
Ein Var-Grad zeigt einen Var-Grad an. Daten, um die Note eines Schülers zu finden; Noten.Studenten beitreten; und Daten, um die Note eines Schülers zu finden. Die Noten für Benutzer 1 in allen Schülern werden zurückgegeben.
Welche Nosql-Datenbank unterstützt keine Beziehungen und Verknüpfungen?
MongoDB ist die beliebteste nicht- relationale Datenbank und unterstützt keine Joins.
Eine NoSQL-Datenbank ist ein hervorragendes Werkzeug zum Speichern von Daten in nicht strukturierter Form wie Dokumenten oder Schlüssel-Wert-Paaren. Die Daten in einer relationalen Datenbank müssen strukturiert und normalisiert abgelegt werden. Eine gut definierte Datenbank kann in einigen Fällen einen Vorteil bieten, wenn sie in Verbindung mit einer relationalen Datenbank verwendet wird. Eine NoSQL-Datenbank entspricht nicht den strukturierten Datenformaten und wird als solche bezeichnet. Die Fähigkeit von NoSQL-Datenbanken, horizontal zu skalieren, beruht auf ihrer Grundlage der Partitionstoleranz. Da die Datenbank keine Struktur für Join-Abfragen vorgibt , sind sie auch nicht sehr gut darin. Hevo Data, eine No-Code-Datenpipeline, ermöglicht die Integration und Replikation von NoSQL-Datenbanken und anderen Datentypen.
Hier gibt es keine Einheitslösung, und Ihre Entscheidung muss auf den Merkmalen der von Ihnen in Betracht gezogenen Verwendungen basieren. Im Folgenden sind einige der Schlüsselfaktoren aufgeführt, die die Entscheidung zwischen relationaler Datenbank und NoSQL beeinflussen. Wenn Sie eine Datenverarbeitung über riesige Datenbanken benötigen, sollten Sie sich so schnell wie möglich für eine NoSQL-Datenbank entscheiden. Das Schreiben in NoSQL-Datenbanken ist in der Regel so vorhersehbar wie es nur geht. Sie können also davon ausgehen, dass Ihre Anwendung alte Daten liest, bis alle Knoten die Daten erhalten. RDBMS unterstützt eine Vielzahl von Abfrage- und Join-Funktionen sowie komplexe Joins . Es ist am besten, NoSQL-Datenbanken zu verwenden, wenn Daten in demselben Format gespeichert werden, in dem sie verwendet werden.
Im Allgemeinen ist High-End-Hardware erforderlich, damit relationale Datenbanken große Datenmengen verarbeiten können. Nur wenn Ihr Datenvolumen groß genug für die Implementierung einer verteilten Datenbank ist, gilt dies. Hevo ist eine Nicht-Code-Datenpipeline, die das Replizieren und Laden von Daten aus häufig verwendeten Quell- und Zieldatenbanken erleichtert. Die Verwendung von Hevo für solche Kopiervorgänge ermöglicht es Entwicklern und Analysten, sich auf ihre Kerngeschäftslogik zu konzentrieren und gleichzeitig Kopiervorgänge mit der geringstmöglichen Geschwindigkeit zu erstellen. Hevo ist ein toller Typ und würde es gerne ausprobieren. Sie können die Hevo-Suite 14 Tage kostenlos testen und alles Wissenswerte darüber erfahren.
MongoDB ist eine ausgezeichnete Wahl, wenn Sie eine NoSQL-Datenbank mit einer großen Datenmenge verwenden möchten. Die Verwendung dieses Programms bietet zahlreiche Vorteile, darunter die Möglichkeit, eine Vielzahl von Programmiersprachen, eine große Anzahl von Datentypen und ein robustes Verwaltungssystem zu verwenden.
Wenn Sie gerade erst anfangen, ist MongoDB eine ausgezeichnete Wahl, da es einfach zu bedienen ist und nicht viel Programmierkenntnisse erfordert. Darüber hinaus ist MongoDB kostengünstig und weit verbreitet, was es einfach macht, einen Server zu finden, der es für Sie hostet.
Im Allgemeinen ist MongoDB der klare Gewinner, wenn es um eine NoSQL-Datenbank geht, die große Datenmengen verarbeiten kann.
Warum unterstützt Mongodb Join nicht?
MongoDB unterstützt Joins nicht, da es sich um eine NoSQL-Datenbank handelt. NoSQL-Datenbanken sind so konzipiert, dass sie skalierbar sind und mit großen Datenmengen arbeiten können. Sie sind außerdem flexibel gestaltet, was bedeutet, dass sie leicht geändert werden können, um die Anforderungen einer bestimmten Anwendung zu erfüllen.
MongoDB ist eine NoSQL-Datenbank, die Open Source ist und zum Speichern großer Datenmengen verwendet werden kann. Tabellen und Zeilen werden in traditionellen Datenbanken verwendet, während Sammlungen und Dokumente in MongoDB verwendet werden. Die Schlüssel-Wert-Paare werden von MongoDB-Dokumenten verwendet, die die Bausteine der Datenbank sind. In diesem Beitrag werden MongoDB-Joins verwendet, die wichtigsten Typen von Joins und Lookup-Befehlen, die in diesem Blog besprochen werden. Eine neue Lookup-Operation in MongoDB 3.2 kann Join-Operationen für Sammlungen durchführen. Ab MongoDB 5.0 kann eine prägnante Syntax für korrelierte Unterabfragen verwendet werden. Bei der Verwendung von MongoDB-Joins gibt es einige Einschränkungen oder Beschränkungen.
Das folgende Snippet erstellt Sammlungen, Restaurants und Bestellungen basierend auf den folgenden Dokumenten: Bestellen Sie die Sammlung, an der Sie interessiert sind. Bitte geben Sie den Namen des Restaurants sowie die Adresse ein. Der Name jeder Bestellung muss mit einer $in-Array-Übereinstimmung zwischen ihnen übereinstimmen. Getränke und Getränke sind in der folgenden Reihenfolge aufgeführt. Die Ausgabe würde unten aufgelistet werden.
Mongodb: Keine Joins, aber $lookup bietet eine Problemumgehung
Die MongoDB-Datenbank ist nicht relational und unterstützt daher keine Joins. Die Join-Funktion ist eine gängige Funktion in relationalen Datenbanken, MongoDB soll sie jedoch nicht unterstützen. Dadurch wird die Datenbank effizienter und schneller, da für das Fügen keine teuren Maschinen erforderlich sind. Diese Funktion ermöglicht es uns, Dokumente mithilfe der $lookup (Aggregation)-Funktion von MongoDB in eine Sammlung aufzunehmen. Wenn Daten zusammengeführt werden, erstellt die Funktion daher eine Linksverknüpfung mit einer Sammlung, sodass Daten aus beiden Sammlungen gefiltert werden können.
Was gilt nicht für Nosql?
Nosql ist eine nicht-relationale Datenbank, die nicht das traditionelle tabellarische Schema einer relationalen Datenbank verwendet. Es wird häufig zum Speichern großer Datenmengen verwendet, die für eine relationale Datenbank nicht gut geeignet sind.
Sie sollten anhand der jeweiligen Vor- und Nachteile entscheiden, welche die beste Option ist. Mit dieser Art von Datenbank können Sie Daten nicht relational statt in tabellarischer Form verwalten. Eine NoSQL-Datenbank kann in vier Typen eingeteilt werden. Dokumentdatenbanken werden erstellt, indem ein assoziatives Array (Zuordnung oder Wörterbuch) verwendet wird, um einen Satz von Schlüssel-Wert-Paaren darzustellen, die durch das Datenmodell dargestellt wurden. Webanwendungen, die sie für die Sitzungsverwaltung und das Caching verwenden, finden sie äußerst nützlich. Graph Stores organisieren Daten als Knoten und Kanten basierend auf ihrer Funktion als Knoten und Kanten. Modelle wie diese sind in einer Vielzahl von Branchen nützlich, darunter Kundenbeziehungsmanagementsysteme, Straßenkarten und Reservierungssysteme.
Die Popularität von NoSQL-Datenbanken ergibt sich aus ihrer Fähigkeit, Big Data, kostengünstige, einfache Skalierbarkeit und Open-Source-Funktionen zu integrieren. Die Sicherheitsfunktionen von NoSQL-Datenbanken sind aufgrund ihrer eingeschränkten Funktionalität eingeschränkt. Ihre Präferenzen, geschäftlichen Anforderungen, das Volumen und die Vielfalt der Daten werden alle die Datenbank beeinflussen, die für Sie am besten geeignet ist.
NoSQL sollte jedoch nicht in Anwendungen verwendet werden, die ACID-Eigenschaften wie Finanztransaktionen garantieren müssen. In diesem Fall sollten Sie eine Migration zu SQL-Datenbanken in Erwägung ziehen. Benötigt man Flexibilität in der Laufzeit, sollte auf NoSQL verzichtet werden.
Nosql-Datenbanken: Keine Einheitslösung
Eine NoSQL-Datenbank ist keine Einheitslösung. Da sie nicht auf ein starres, zentralisiertes Datenmodell beschränkt sind, das auf einem einzelnen Server untergebracht ist, können sie unterschiedliche Datenbankmodelltypen verbinden, die über eine Vielzahl von Servergrößen verteilt sein können. NoSQL unterstützt keine Transaktionen, was jedoch nicht bedeutet, dass sie nicht in einer Vielzahl von Anwendungen implementiert werden können. Die NoSQL-Datenbank ermöglicht das Speichern und Abrufen von Daten in jedem anderen Format als der tabellarischen Speicherung, sodass auf sie zugegriffen und sie in einer Vielzahl anderer Formate als der tabellarischen Speicherung gespeichert werden können. Externe Tabellen sind zum Abrufen oder Speichern von Daten nicht erforderlich.
Nosql-Join-Äquivalent
Das Nosql-Join-Äquivalent ist eine Möglichkeit, Daten aus zwei oder mehr Nosql-Datenquellen zu kombinieren. Dies ist nützlich, wenn Sie Daten aus mehreren Quellen kombinieren müssen, um eine einzige Datenansicht zu erstellen. Beispielsweise müssen Sie möglicherweise Daten aus einer Kundendatenbank und einer Bestelldatenbank kombinieren, um einen Bericht zu erstellen, der Kundenbestellungen anzeigt.

Beide Arten von Datenbanken erfordern Verknüpfungsvorgänge, um ordnungsgemäß zu funktionieren. In diesem Artikel vergleichen wir eine relationale MySQL-Datenbank mit einer NoSQL-Datenbank (MongoDB). Um Join-Operationen mit dem Schlüsselwort $lookup durchzuführen, können wir die Aggregat-Pipeline verwenden. In einigen Fällen erfordern Abfragen die Verknüpfung beider Datenbanken. Die aggregierte Pipeline von MongoDB ist besonders nützlich, da sie zum Ausführen einer Vielzahl von Funktionen wie Filtern, Sortieren, Gruppieren usw. in einer einzigen Pipeline verwendet werden kann. In einer regulären Select-Anweisung schreiben wir nur die Namen der auszuwählenden Spalten. Wenn wir Tabellen verknüpfen, geben wir die Spalten an, die für Spalten aus der Tabelle verwendet werden, die SQL versteht.
In der Join-Phase der $lookup-Operation wählen wir „$location“ als ID der Dokumente, die basierend auf dem Standort gruppiert werden sollen. Dann spezifizieren wir, wie wir in den folgenden Abschnitten sehen werden, die Funktion $avg sowie das zu aggregierende Feld. Um das Filterkriterium zu verwenden, müssen wir zuerst die Stufe $match zur Pipeline hinzufügen.
Postgres ist die beste Datenbank für Joins
Zusammenfassend lässt sich sagen, dass PostgreSQL eine bessere Leistung erbringt und stabiler ist als jede andere Datenbank.
Mongodb tritt bei
Mit MongoDB-Joins können Sie Dokumente aus verschiedenen Sammlungen in einer einzigen Abfrage kombinieren. Dies kann nützlich sein, wenn Sie Daten aus mehreren Sammlungen in einem einzigen Vorgang abrufen müssen. Beispielsweise könnten Sie einen Join verwenden, um Daten aus einer Benutzersammlung und einer Beitragssammlung zu kombinieren, um einen Feed mit allen Beiträgen aller Benutzer zu erstellen.
MongoDB ist nicht offiziell mit dem Beitritt kompatibel. Bedeutet das, dass wir zwei Sammlungen nicht miteinander verbinden können? Ich würde mich freuen, wenn Sie mir darauf antworten könnten. Es gibt zwei Methoden zum Auflösen von Referenzen in diesem Bereich. Sie können das Problem manuell lösen, indem Sie Ihre eigene Funktion schreiben, oder Sie können es automatisieren. Alternativ kann MongoDB DBRefs verwenden, wodurch Beziehungen Client für Client verwaltet werden können. Das Referenzverhalten von MongoDB ist eher dem Lazy Loading als dem Joining sehr ähnlich.
Auf der Website mongodb.org können Sie Vorträge zum Schemadesign ansehen und anhören. Wenn Sie Nosql-Datenbanken wie MongoDB verwenden, müssen Sie ein Schema implementieren. Infolgedessen werden Ihre Sammlungen immer weniger wie eine SQL-Datenbank aussehen. Mit diesem Paket können Sie serverseitige Komponenten hinzufügen (ich bin mir nicht sicher, ob ein anderes Framework dies tut). Es gibt keine Joins in MongoDB, aber wir brauchen zum Beispiel Verweise auf Dokumente in anderen Sammlungen. Die Verwendung von StackOverflow ist so einfach wie das Befolgen der Schritte in dieser StackOverflow-Antwort.
Die Geschwindigkeit von Mongodb ist mit einigen Einschränkungen verbunden
Trotz seiner Geschwindigkeit hat MongoDB einige Nachteile. Eine der Einschränkungen besteht darin, dass es kein Cross-Linking unterstützt. Wenn es also um Dinge wie aggregierte Daten geht, müssen Sie diese einzeln durchführen. Dies ist zwar langsamer als eine relationale Datenbank, aber dennoch extrem schnell.
Nosql-Datenbanken
Nosql-Datenbanken sind ein Datenbanktyp, der nicht das traditionelle relationale Modell verwendet, das von den meisten Datenbanken verwendet wird. Stattdessen wird ein Schlüsselwertspeicher, Dokumentspeicher oder Graphspeicher verwendet. Dadurch sind nosql-Datenbanken skalierbarer und flexibler als relationale Datenbanken.
Der Hauptvorteil von NoSQL-Datenbanken gegenüber herkömmlichen Datenbanken besteht darin, dass sie eine größere Flexibilität bieten. NoSQL-Datenbanken speichern Daten in einer einzigen Datenstruktur, z. B. einem Dokument, im Gegensatz zu relationalen Datenbanken, die normalerweise mehrere Datenzeilen enthalten. Da dieses Datenbankdesign kein Schema zur Verwaltung großer und typischerweise unstrukturierter Datensätze benötigt, ist es hochgradig skalierbar. Da NoSQL-Datenbanken keine Daten teilen, können Tabellen nicht verknüpft werden. Aufgrund seiner vielfältigen Datenstrukturen hat NoSQL das Potenzial, in einer Vielzahl von Bereichen eingesetzt zu werden, darunter Datenanalyse, soziale Netzwerke und mobile Apps. Trotz der Tatsache, dass jeder Datenbanktyp von seinen eigenen Eigenschaften profitiert, verwenden die meisten Unternehmen NoSQL und relationale Datenbanken. Dokumentdatenbanken speichern Daten als Dokumente, wodurch sie bei der Verwendung in Anwendungen organisiert bleiben.
Dokumentendatenbanken werden häufig für Content-Management-Systeme und Benutzerprofile verwendet. Der Hauptvorteil einer Datenbank mit breiten Spalten besteht darin, dass sie Daten in Spalten speichert, sodass Benutzer nur dann auf bestimmte Spalten zugreifen können, wenn sie sie benötigen. Zu diesen Datenbanktypen gehören Apache Cassandra und Apache HBase. Graphdatenbanken werden verwendet, um ein Netzwerk von Verbindungen zwischen Elementen in einem Graphen zu verwalten und zu speichern. Eine speicherbasierte Datenbank speichert Daten statt auf einer Festplatte, sodass schneller darauf zugegriffen werden kann. Da sie die Notwendigkeit eines einzigen, gemeinsam genutzten Datenspeichers für eine gesamte Anwendung eliminieren, sind Microservices eine praktikable Option. PaaS- und NoSQL-Datenbanken sind von IBM in einer Vielzahl von Anwendungen erhältlich. Fügen Sie die IBM Data Management Platform for MongoDB Enterprise Advanced kostenlos zu IBM Cloud Pak for Data hinzu. Dieser Dienst ist kompatibel mit Apache CouchDB, PouchDB und Bibliotheksökosystemen sowie beliebten Web- und Mobilentwicklungs-Stacks.
NoSQL-Datenbanken wurden insgesamt durch ihren Mangel an Skalierbarkeit und Leistung behindert. Inzwischen gibt es innovative Start-ups und führende Unternehmen, die beginnen, diese Einschränkungen anzugehen.
Scale-out-Datenbanken sind die am weitesten verbreitete Art von NoSQL-Datenbanken. Die Architektur ermöglicht das Speichern mehrerer Kopien von Daten über mehrere Knotentypen hinweg, obwohl Masterless Computing verwendet wird. Diese Technologie ermöglicht eine massive Skalierbarkeit, die entscheidend ist, wenn Ausfallzeiten vermieden werden sollen.
Diese Funktion ermöglicht die Speicherung von Daten an mehreren Standorten und ist entscheidend für Hochverfügbarkeit und Notfallwiederherstellung. Die Datenreplikation ist auch erforderlich, wenn Sie eine Data-Warehousing- und Multi-Tenancy-Umgebung erstellen.
Ein weiteres wichtiges Merkmal von NoSQL-Datenbanken ist ihre Fähigkeit, flexible Datenstrukturen zu erstellen. Darüber hinaus ist es einfach, neue Datentypen hinzuzufügen und Daten mit ihnen einfach zu manipulieren. Es ist entscheidend für das Data Warehousing und die schnelle Entwicklung neuer Anwendungen.
Die Vorteile von Nosql-Datenbanken
Daten, die in NoSQL-Datenbanken gespeichert sind, können auf verschiedene Arten gespeichert werden, was sie zu einem beliebteren Datenbanktyp macht. Sie können verwendet werden, um unstrukturierte Daten sowie jede Art von Daten zu speichern. Auch bei der Verarbeitung großer Datenmengen sind sie effizienter als herkömmliche Datenbanken.
In NoSQL-Datenbanken gibt es keine Begrenzung für die Arten von Daten, die gespeichert werden können. Darüber hinaus können Daten in Dateien oder in Graphdatenbanken gespeichert werden.
Oracle Nosql-Datenbank
Eine Oracle NoSQL-Datenbank ist ein skalierbarer, verteilter NoSQL-Datenbankdienst , der hohe Leistung, hohe Verfügbarkeit und automatisches Sharding bietet. Oracle NoSQL Database basiert auf der Oracle Berkeley DB Java Edition und bietet eine einfache Java-API für den Zugriff auf die Datenbank.
Spring Data kann mit dem Oracle NoSQL SDK für Spring Data implementiert werden. Sie können es verwenden, um eine Verbindung zu einem Oracle NoQL Database-Cluster oder zu Oracle NoQL Cloud Service herzustellen. Auf das SDK kann zugegriffen werden, wenn Sie eine Maven-Abhängigkeit von der phar.xml Ihres Projekts verwenden. Dies sind einige der besten Optionen für die Bequemlichkeit. www.oracle.com/nosql Rufen Sie die folgende Methode ab: NosqlDbConfig. Eine Entitätsklasse kann wie folgt definiert werden. Es wird empfohlen, dass Sie ein Repository für die Nosql-Erweiterung erstellen. Mit dem Schreiben der Anwendungsklasse können Sie beginnen. Es erfordert die Installation von Abhängigkeiten auf org.springframework.boot:spring-boot.
Die vielen Vorteile von Mongodb
MongoDB ist die einzige Datenbank, die sowohl nach Volltextdateien als auch nach Dokumenten mit eingebetteten Strukturen suchen kann.
Fangen Sie … Mongodb-Aggregation
Mit der Aggregationsfunktion von Mongodb können Sie Dokumente gruppieren, um Analysen Ihrer Daten durchzuführen. Dies ist eine leistungsstarke Funktion, mit der Sie eine Vielzahl von Fragen zu Ihren Daten beantworten können. Beispielsweise können Sie die Aggregation verwenden, um den Durchschnittspreis eines Produkts für alle Ihre Kunden zu ermitteln oder Kunden nach Standort zu gruppieren.
Das Aggregations-Framework von MongoDB ist in der Lage, jede Art von Daten zu verarbeiten. Ein Name für einen Ausdrucksoperator kann entweder in einem Array von Argumenten oder in einem einzelnen Argument gefunden werden. Eine der häufigsten Anwendungen von Akkumulatoren ist die Berechnung von Summen, Maxima, Minima und anderen Werten in speziellen Ausdrücken. Einige Akkumulatoren können in anderen Stufen verwendet werden, jedoch nicht als Akkumulatoren, da sie den Zustand nicht beibehalten. Der $let-Operator besteht aus zwei Teilen: Variablen und Ausdrücken, mit denen Variablen zugewiesen und in Berechnungen verwendet werden können. Intern definierte, aber in vars geänderte Variablen ändern keine Werte, da nur die ursprünglichen Werte sichtbar sind. Wenn Sie die Pipeline speichern, kann sie später in Compass erneut geladen werden.
MongoDB Compass enthält mehrere Tools für die Aggregation, wie z. B. den Aggregation Pipeline Builder. Die Aggregationspipeline zerlegt das Problem in kleinere Teile. Pipelines können auch verwendet werden, um Phasen beim Debugging oder Prototyping zu kommentieren. Die Sperrstufen müssen sorgfältig entworfen werden, um die Leistung der Pipeline zu verbessern. Die MongoDB 2.2-Shell enthält ein Aggregationsframework, das vollständig mit dem Helferaggregat() implementiert ist. MongoDB 1.14 enthält den MongoDB Aggregation Pipeline Builder. Die Stufen wurden durch das Hinzufügen von $graphLookup, $bucket, $facet, $addFields und $replaceRoot verbessert. Import/Export ist jetzt eine Funktion, die in Compass 1.15 (August 2018) verfügbar ist. Im November 2018 wurde MongoDB 4.2 veröffentlicht und MongoDB 4.4 wurde im Januar 2019 veröffentlicht.
Mongodb: Eine gute Wahl für die Aggregation
Eine MongoDB-Datenbank ist eine ausgezeichnete Wahl für die Datenaggregation, da sie eine Vielzahl von Datentypen verarbeiten kann. Mit Export Aggregation Results können Sie Datenergebnisse einfach in eine Vielzahl von Formaten importieren. MongoDB kann langsam sein, wenn Sie mit großen Sammlungen arbeiten, aber es kann schnell sein, wenn Sie mit indexfreiem $lookup arbeiten.