
Warum Nosql-Datenbanken besser für Big Data sind
Veröffentlicht: 2022-11-19Nosql-Datenbanken eignen sich aus mehreren Gründen besser für Big Data . Sie sind so konzipiert, dass sie horizontal skalierbar sind, was bedeutet, dass sie mehr Daten verarbeiten können, indem sie weitere Server hinzufügen. Sie sind außerdem auf Hochverfügbarkeit ausgelegt, d. h. sie können auch dann weiterlaufen, wenn einige Server ausfallen. Und sie können einen hohen Durchsatz bewältigen, was bedeutet, dass sie viele Lese- und Schreibvorgänge bewältigen können.
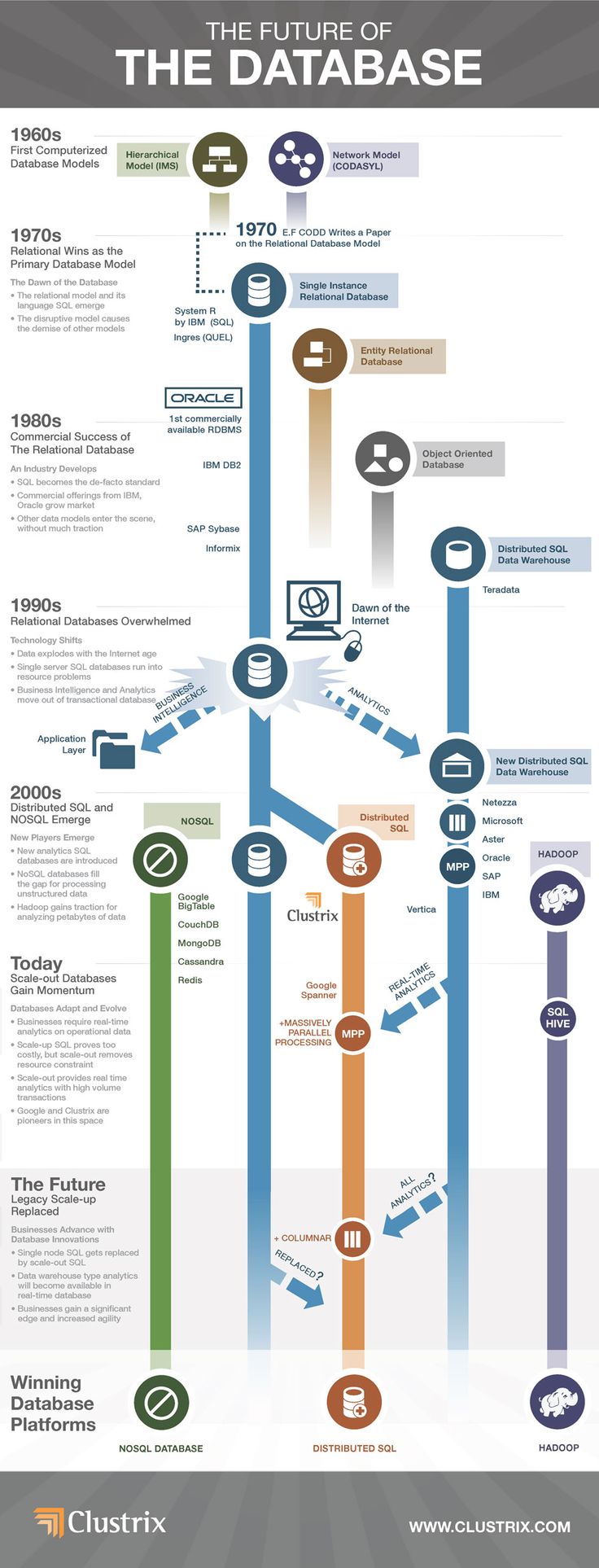
Die Verwendung von NoSQL-Datenbanken war bei Internetunternehmen wie Amazon, Google, LinkedIn und Facebook als Reaktion auf die Nachteile von RDBMS beliebt. Da die Anforderungen an die Datenverarbeitung steigen, ist NoSQL eine anpassungsfähige und Cloud-basierte Lösung zur Verwaltung unstrukturierter Daten. Laut Esprdo de Oliveira, Director of Business Development bei FairCom, gibt es einige Probleme mit NoSQL, die eine herkömmliche Datenbank nicht bewältigen kann. Es wird verwendet, um Datenbanktechnologie in der Cloud, im Web, in Big Data und bei den großen Benutzern voranzutreiben. NoSQL-Datenbanken sind eine Teilmenge von Datenbanken, die Daten auf verschiedene Weise speichern. Die beliebtesten Typen sind Diagramme, Schlüssel-Wert-Paare, Spalten und Dokumente. Unternehmen, die stark auf Daten angewiesen sind, wie Amazon, eBay usw., benötigten eine Datenbank wie NoSQL oder SQL, die am besten zu dem sich ändernden Datenmodell passt und es ihnen ermöglicht, ihre Abläufe effizienter zu verwalten.
Die Speicherung und Verarbeitung von Daten in Echtzeit kann durch NoSQL-Datenbanken erreicht werden, die weit ausgefeilter sind als relationale Datenbanken. Aufgrund der zunehmenden Geschwindigkeit und Datenvielfalt wird die Landschaft der Datenbanken mit einer erhöhten Datengeschwindigkeit, einer wachsenden Datenvielfalt und einem explodierenden Datenvolumen überschwemmt, die alle von Big Data-Anwendungen benötigt werden. NoSQL-Datenbanken wie HBase, Cassandra und Couchbase sind das Das Konzept der CAP-Prioritäten (Consistency-Availability-Partition Tolerance) ist ein NoSQL- Datenbankkonzept .
Das Datenbankschema ist in relationalen Datenbanken festgelegt. Es gibt keine Konsistenz in NoSQL-Datenbanken. In NoSQL-Datenbanken gibt es keine Transaktionen (sie unterstützen nur einfache Transaktionen). In einer relationalen Datenbank werden Transaktionen (sowie komplexe Transaktionen mit Joins) unterstützt.
Dass NoSQL-Datenbanken in den letzten Jahren immer beliebter wurden, hat einen Grund: Sie sind einfach zu verstehen und erfordern keine komplexen Datenmodelle wie SQL-Datenbanken. Darüber hinaus ermöglichen NoSQL-Datenbanken Entwicklern häufig, die Datenstruktur direkt zu ändern.
Entwickler können auf vielfältige Weise von NoSQL-Datenbanken profitieren, darunter schnellere Abfrageergebnisse, flexible Datenmodelle, horizontale Skalierung und ein optimierter Entwicklungsprozess. Dokumentendatenbanken, Key-Value-Datenbanken, Wide-Column-Stores und Graph-Datenbanken sind nur einige Beispiele für NoSQL-Datenbanken.
Ist Nosql gut für große Datenmengen?
Es ist entscheidend, dass Speicherlösungen für Big Data in der Lage sind, große Datenmengen zu verarbeiten und zu speichern, um sie zu verarbeiten und zu analysieren. Eine NoSQL-Datenbank, auch bekannt als nicht relationale Datenbank, ist darauf ausgelegt, große Datenmengen zu verarbeiten und gleichzeitig horizontal zu skalieren.
Wie MongoDB und Apache Cassandra und HBase gezeigt haben, haben NoSQL-Datenbanken im Laufe der Zeit ein beispielloses Wachstum erfahren. Im Vergleich zu Open-Source-Software ist NoSQL die bessere Wahl für Unternehmen, die eine schnelle Verarbeitung und Analyse großer Mengen unterschiedlicher und unstrukturierter Daten benötigen. Diese Datenbanken bieten im Vergleich zu herkömmlichen RDBMS-Produkten Vorteile in Bezug auf Reaktionsfähigkeit, Skalierbarkeit und Verfügbarkeit. Eine NoSQL-Datenbank wird von Organisationen bevorzugt, die große Mengen strukturierter, halbstrukturierter und unstrukturierter Datendateien und -sätze speichern und analysieren möchten – insbesondere in Echtzeit. Je mehr Daten im Cluster wachsen, desto mehr physische Server sind erforderlich. NoSQL-Datenbanken verwenden eine horizontal skalierende Architektur, die sie effizient macht. NoSQL-Datenbanken haben aufgrund ihrer Open-Source-Natur niedrigere Kosten pro Transaktion als herkömmliche Datenbanken. NoSQL und RDBMS sowie deren Stärken können gemeinsam genutzt werden, um ein effizientes Datenmanagementsystem zu schaffen.
Welche Datenbank eignet sich am besten für große Datenmengen?
Auf diese Frage gibt es keine endgültige Antwort, da sie von verschiedenen Faktoren abhängt, wie z. B. den spezifischen Bedürfnissen des Benutzers, der Art der zu speichernden Daten und dem Budget. Einige weit verbreitete Datenbanken für große Datensätze sind jedoch Apache Hadoop, Apache Cassandra und MongoDB.
Warum Nosql besser ist

Es gibt viele Gründe, warum NoSQL als bessere Wahl für modernes Datenmanagement angesehen wird. Erstens sind NoSQL-Datenbanken aufgrund ihrer horizontalen Skalierungsfähigkeiten sehr gut im Umgang mit großen Datenmengen. Sie können auch problemlos in Big-Data-Lösungen integriert werden. Zweitens bieten NoSQL-Datenbanken ein viel reichhaltigeres Datenmodell als traditionelle relationale Datenbanken , wodurch sie besser für den Umgang mit komplexen Daten geeignet sind. Schließlich sind NoSQL-Datenbanken im Allgemeinen viel einfacher zu verwenden und erfordern weniger Wartung als relationale Datenbanken.
Die Daten sind eine Schlüsselkomponente aller Teilbereiche der Datenwissenschaft. Es ist wahrscheinlicher, dass Sie Daten in einem Datenbankverwaltungssystem (DBMS) speichern müssen. Bei der Interaktion und Kommunikation mit dem DBMS ist dessen Sprache erforderlich. SQL (Structured Query Language) ist die Sprache, die für die Interaktion mit DBMSs verwendet wird. Ein weiterer Begriff, der in letzter Zeit im Bereich der Datenbanken aufgetaucht ist, sind NoSQL-Datenbanken. NoSQL-Datenbanken, wie z. B. nicht relationale Datenbanken, speichern keine Daten in Tabellen oder Datensätzen. Die Datenspeicherstruktur ist stattdessen so konfiguriert, dass sie bestimmte Anforderungen erfüllt.
Die vier häufigsten Typen sind Graphdatenbanken, spaltenorientierte Datenbanken, dokumentorientierte Datenbanken und Schlüssel-Wert-Paare. Dokumentorientierte Datenbanken wie MongoDB sind ein Beispiel für eine Python-Datenbank. Wenn Sie eine NoSQL-Datenbank verwenden, können Sie einfacher eine Datenstruktur erstellen. SQL-Datenbanken hingegen haben eine starrere Struktur und einen niedrigeren Datentyp. Wenn Sie als Anfänger SQL lernen möchten, beginnen Sie mit SQL und wechseln Sie dann zu NoSQL. Es gibt zahlreiche Vor- und Nachteile für jedes dieser Programme, und Sie sollten ihre Vor- und Nachteile basierend auf Ihren Daten, Ihrer Anwendung und dem, was die Entwicklung erleichtert, berücksichtigen. Es besteht kein Zweifel, dass SQL NoSQL oder der Art und Weise, wie es geschrieben ist, überlegen ist. Wenn Sie auf Ihre Daten hören, treffen Sie die beste Entscheidung für Sie.
SQL vs. Nosql für Big Data
SQL schneidet auch bei komplexen Abfragen besser ab, da es eine höhere Geschwindigkeit und Wiederherstellung bietet. Wenn Sie jedoch die Standardstruktur von RDBMS erweitern oder ein flexibles Schema erstellen möchten, sind NoSQL-Datenbanken die beste Wahl.

Es ist wichtig, entweder eine relationale Datenbank (SQL) oder eine nicht-relationale Datenbank (Nosql) auszuwählen, um Ihre Datenbankinvestitionen optimal zu nutzen. Um eine fundierte Entscheidung über den für ein Projekt erforderlichen Datenbanktyp zu treffen, müssen Sie zunächst die Unterschiede zwischen den beiden verstehen. Elastizität ist eine entscheidende Voraussetzung für NoSQL-Datenbanken, weshalb sie besser für Big Data geeignet sind. Je nach Anforderung können dies Schlüssel-Wert-Paare, dokumentenbasierte Graphdatenbanken oder Wide-Column-Stores sein. Dadurch kann jedes Dokument seine eigene eindeutige Struktur haben, was es ermöglicht, Dokumente ohne eine definierte Struktur zu erstellen. In Bezug auf NoSQL gibt es zahlreiche Fragen, insbesondere im Zusammenhang mit Big Data und Data Analytics. Einige NoSQL-Datenbanken erfordern internes Fachwissen, um eingerichtet und verwaltet zu werden, während andere stark auf die Unterstützung durch die Community angewiesen sind.
Die allgemeine Regel lautet, dass NoSQL nicht schneller als SQL ist, genauso wie es schneller ist, Lese- oder Schreibvorgänge auf einer einzelnen Datenentität durchzuführen. Da NoSQL-Datenbanken große Datenmengen ermöglichen, sind sie ideal für Google, Yahoo und Amazon. Bestehende relationale Datenbanken waren nicht in der Lage, den gestiegenen Bedarf an Datenverarbeitung zu decken. Eine NoSQL-Datenbank hat das Potenzial, bei Bedarf zu wachsen und leistungsfähiger zu werden. Diese Art von Anwendung ist ideal für Anwendungen ohne spezifische Schemadefinitionen, wie z. B. Content-Management-Systeme, Big-Data-Anwendungen und Echtzeitanalysen.
Eignet sich Nosql für große Datensätze?
Es liegt in ihrer Verantwortung, unstrukturierte und halbstrukturierte Daten in ein Format zu konvertieren, das von Analysetools verwendet werden kann. Diese besonderen Anforderungen haben NoSQL-Datenbanken (nicht relational) wie MongoDB zu einer leistungsstarken Wahl für die Speicherung großer Datenmengen gemacht.
Ist SQL gut für Big Data?
Hadoop-basierte SQL-on-Hadoop-Engines können zur Handhabung großer Datenbanken verwendet werden. Der Mythos, Big Data sei zu groß für SQL-Systeme, ist mittlerweile widerlegt und stimmt überhaupt nicht. Es ist in der Tat ein Mythos. SQL ist ein hervorragendes Framework zum Erstellen von Big-Data-Systemen.
Wie sind Big Data und Nosql-Datenbanken identisch?
Auf diese Frage gibt es keine einheitliche Antwort, da die beiden Begriffe für verschiedene Menschen unterschiedliche Bedeutungen haben können. Im Allgemeinen werden Big Data und nosql-Datenbanken jedoch häufig synonym verwendet, um auf Datenspeicher zu verweisen, die für die Aufnahme großer Datenmengen ausgelegt sind und nicht auf dem traditionellen relationalen Datenbankmodell basieren.
Datenbank NoSQL , auch bekannt als Open Source, basiert auf einer Open-Source-Datenbank. Die Kategorien von NoSQL-Datenbanken werden durch das Datenmodell der Datenbank bestimmt. Jedes der Datenmodelle besteht aus einem Schlüsselwertspeicher, einem Dokument, einer Spalte – Eingabe und einem Diagrammdatenmodell. Auf eine mobile Datenbank kann auf einer Vielzahl von Geräten und Orten zugegriffen werden. Es gibt auch eine Tendenz zum Multitasking im Allgemeinen. Die Flexibilität von NoSQL-Datenbanken sowie das Fehlen eines festen Schemas ermöglichen es ihnen, flexibler als herkömmliche Datenbanken zu sein, wenn es darum geht, die Vielfalt der Datenmerkmale zu berücksichtigen, für die Big Data bekannt ist. Aufgrund der ACID-Eigenschaften von Datenbanken sind sie aufgrund des Fehlens eines vollständigen oder vollständigen Transaktionsabschlusses nicht hochverfügbar.
Da NoSQL Open Source ist, bedeutet dies, dass es wirtschaftlich rentabel ist. Aufgrund all dieser Vorteile und des Aufstiegs der Branche wird die Zahl der Personen zunehmen, die mit NoSQL-Datenbanken arbeiten können. Craigslist ist eine Website für Kleinanzeigen und Stellenausschreibungen, die 570 Städte in 50 Ländern auf der ganzen Welt bedient. Coursera6, eine 2001 gegründete Online-Bildungsplattform, bietet Universitäten auf der ganzen Welt Bildungsmöglichkeiten. Es ist in den letzten zehn Jahren durch die Verwendung von NoSQL, Cassandra-Datenbanken und einer herkömmlichen Datenbank auf 10 Millionen Studenten angewachsen.
Nosql-Datenbanken: Warum sie immer beliebter werden
Die Merkmale einer NoSQL-Datenbank sind folgende: Ihr Design erlaubt es, große Datenmengen zu verarbeiten. Sie sind als „Skalen“ bekannt. Mit ihnen können Daten auf vielfältige Weise verarbeitet werden. Die Datenmenge in diesen Datenbanken ist größer als die in herkömmlichen Datenbanken.
Nosql-Datenanalyse
Es ist leicht zu verstehen, warum NoSQL für „Not Only SQL“ steht. In diesem Fall werden die Daten nicht in mehrere Tabellen aufgeteilt, da dadurch der gesamte Datensatz in einer einzigen Struktur enthalten sein kann. Bei der Arbeit mit großen Datenmengen ist die Abfrageleistung in einer NoSQL-Datenbank kein Problem.
Nosql vs. SQL: Was ist die beste Datenbank für Big Data?
Big-Data-Analysen erfordern NoSQL-Datenbanken, weil sie überlegene Vorteile bieten. SQL-Datenbanken hingegen werden schon lange zur Datenanalyse eingesetzt. Da die meisten BI-Tools wie Looker keine Abfragefunktionalität für NoSQL-Datenbanken unterstützen, ist dies keine Option.
Wenn Ihre Daten sehr strukturiert sind und ACID-Konformität erforderlich ist, ist SQL eine großartige Option für Sie. Während NoSQL für diejenigen von Vorteil sein kann, die ihre Datenanforderungen nicht kennen oder über unstrukturierte Daten verfügen, kann es auch für diejenigen von Vorteil sein, die dies tun. Eine NoSQL-Datenbank benötigt keine vordefinierten Schemas wie SQL-Datenbanken.
Diese Flexibilität ist notwendig für den reibungslosen Betrieb komplexer Datensätze und die Erleichterung flexibler Entscheidungsfindung. Darüber hinaus unterstützt MongoDB leistungsstarke Abfragefunktionen, mit denen Sie große Datenmengen schnell analysieren und abrufen können. Mit unseren R-Verbindungen können wir im Handumdrehen erweiterte Datenanalysen durchführen.
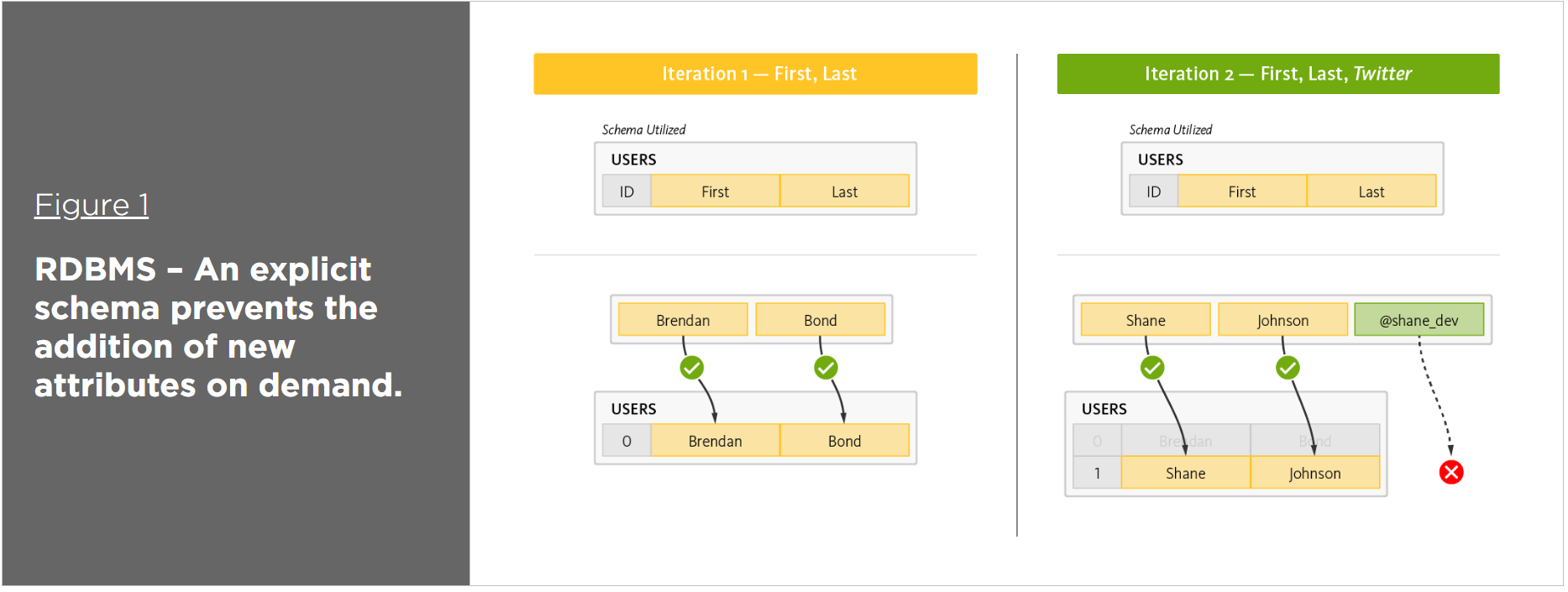
Warum Rdbms nicht für Big Data geeignet ist
Es ist nicht möglich, die Normalisierung zu beseitigen. Automatisches Sharding von Daten ist unter keinen Umständen nahezu unmöglich (Alptraum). Ein System mit hoher Verfügbarkeit ist schwierig zu implementieren.
Jedes interne RDBMS-Tool (Relational Database Management System) erklärt seine Bedeutung in Big Data. Warum ist die Skalierung so schwierig? Dafür gibt es mehrere Gründe, aber der Hauptgrund ist, dass wir unzufrieden sind. Wir sind nicht in der Lage, die genaue Komplexität der Abfrage zu bestimmen, die erforderlich ist, um die gewünschten Ergebnisse aus der Datenbank zu extrahieren. Wenn die Daten größer sind als die Speichergröße unseres Systems, können wir sie nicht verarbeiten. Bei Big Data müssen erhebliche Datenmengen zusammengeführt werden, um Erkenntnisse zu generieren. Daten werden an mehreren Orten gespeichert, daher sind RDBMS-Tools ineffizient und nicht in der Lage, mit dieser Situation umzugehen.
Die Fähigkeit zum Beitritt ist aufgrund von Sharding nicht möglich. Nach Durchführung eines Sharding-Verfahrens kann ein einzelner Datenrahmen auf mehrere Knoten aufgeteilt werden. Ein Dienst gilt als „hochverfügbar“, wenn er immer verfügbar ist, und wenn einige seiner Eigenschaften nicht erfüllt werden, wird seine Leistung von selbst festgelegt. Es gibt eine Vielzahl von Gründen, warum eine hohe Verfügbarkeit äußerst schwierig zu erreichen ist, siehe die folgenden Abschnitte.
Warum Rdbmss Big Data nicht verarbeiten kann
Big Data wird von herkömmlichen RDBMS nicht unterstützt. Die Systeme sind langsam und können die Datenschwankungen nicht bewältigen. Hadoop kann zum Speichern großer Datenmengen verwendet werden, ist jedoch nicht speziell für diesen Zweck konzipiert.