
Warum Nosql-Datenbanken einfacher zu replizieren sind
Veröffentlicht: 2022-12-26Nosql-Datenbanken sind einfacher zu replizieren, da sie nicht durch die starre Struktur herkömmlicher relationaler Datenbanken eingeschränkt sind. Diese Flexibilität ermöglicht es, nosql-Datenbanken einfach zu skalieren und auf mehrere Server zu duplizieren. Darüber hinaus können nosql-Datenbanken einfach gesichert und wiederhergestellt werden, was sie ideal für datenintensive Anwendungen macht.
Die Datenreplikation ist für die Pflege der Datenbank und das Bedienen von Abfragen unerlässlich. Die RAID-Stufen 3, 4, 5 oder 10 werden häufig verwendet, um die Zuverlässigkeit großer Speichersysteme zu verbessern. Ich kann meinen Cluster am Laufen halten, wenn ich erneut auf die Daten auf den ausgefallenen Festplatten zugreifen kann, bevor der dritte Ausfall auftritt. Eine Festplatte in einem R=3-Cluster enthält Datenblöcke, die auf andere Festplatten an anderer Stelle im Cluster repliziert werden. Ein Rebuild findet zwischen 10 Systempaaren statt, indem eine Platte pro Systempaar kopiert wird. 100 Server müssten verwendet werden, um den gesamten Datensatz auf einem ausgefallenen Server wiederherzustellen, wenn er zehn Festplatten hätte. Alle Daten der Datenbank können gelesen werden, solange wir bei R1 sind.
Ein einzelner Fehler kann dazu führen, dass der Cluster nach R0 wechselt, wo einige Daten nicht gelesen werden können. Betrachten wir eine Regel, dass sich nur eine Kopie eines Chunks auf einer Festplatte, einem Server, einer PDU (Stromversorgung) oder einem Netzwerk-Switch befinden kann. Wenn Teile der Festplatte oder des Servers vor R2 ausfallen, kann ein Cluster möglicherweise die für R2 aufgewendete Zeit reduzieren. Infolgedessen ist es wahrscheinlicher, dass der Cluster in Zukunft fehlschlägt, was zu R1- und R0-Clustern führt. Wenn Zeilen zum Ausfall einer Datenbank führen, können die drei Replikate des Blocks, der die Zeile enthält, alle gleichzeitig ausfallen.
Da replizierte Daten von mehreren Servern gemeinsam genutzt werden können, wird kein Server mit Benutzerabfragen überlastet. Sie werden effizienter. Wenn der Server weniger mit Abfragen überlastet ist, kann er möglicherweise weniger Benutzern eine bessere Leistung bieten. Der Laden ist sehr gefragt.
Ein Replikatsatz ist das Äquivalent von MongoDB zu einer Gruppe von Mongod-Prozessen, die denselben Datensatz behalten. Die Fähigkeit, mit Replikaten ein hohes Maß an Redundanz und Verfügbarkeit bereitzustellen, macht sie ideal für Produktionsbereitstellungen.
NoSQL-Datenbanken schneiden in Bezug auf Skalierung, Skalierbarkeit und Leistung besser ab als relationale Datenbanken. Darüber hinaus sind ihre Datenmodelle flexibler und einfacher zu verwenden als relationale Modelle, was sie im Vergleich zu anderen Plattformen zu einer schnelleren Entwicklungsoption macht.
NoSQL-Datenbanken verarbeiten unstrukturierte Daten mithilfe flexibler Schemata, um eine effiziente Speicherung und Analyse von Daten zu ermöglichen, die verteilt und für datengesteuerte Anwendungen verwendet werden. Durch die Verringerung der Datenkonsistenz und die Vereinfachung der Datenzugriffsbeschränkungen von SQL-basierten Datenbanken ermöglichen NoSQL-Datenbanken eine geringe Latenz, Skalierbarkeit und hohe Leistung.
Unterstützt Nosql die Replikation?
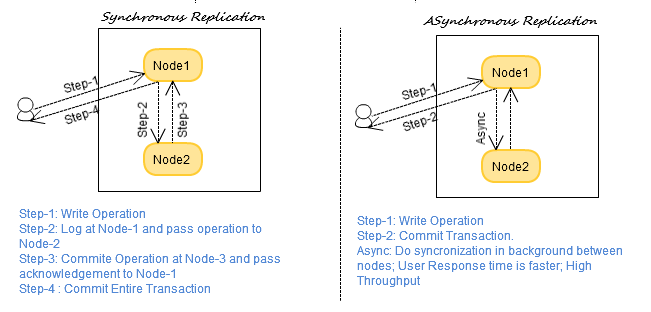
Die Peer-to-Peer-NoSQL-Datenreplikation wurde als Mittel zum Speichern von Daten entwickelt, die zwischen Kopien einer Datenbank ausgetauscht werden. Diese Methode kann nur verwendet werden, wenn alle Kopien dasselbe Schemaformat enthalten und denselben Datentyp speichern. Darüber hinaus erfordert diese Datenreplikationstechnik die Verwendung einer Datenbank.
Die CloverDX-Plattform ist ein ideales Framework für die Datenintegration in der Cloud, vor Ort oder in hybriden Umgebungen. Redis Enterprise ist ein Datenstrukturspeicher, der als Datenbank, Cache oder Nachrichtenbroker in einem In-Memory-Datenstrukturspeicher verwendet werden kann. Die Net Cloud Platform ist eine Open-Source-Cloud-Computing-Plattform. Datenbankverwaltungssoftware wie GraphDB kann Unternehmen dabei helfen, Daten zu indexieren. In-Memory-Datenspeicher und Cache-Umgebungen können in der Cloud mit Amazon ElastiCache verwaltet werden, das mit Redis und Memcached kompatibel ist. Riak KV ist eine Open-Source- NoSQL-Datenbanklösung , mit der Unternehmen Daten aus mehreren Quellen verwalten, replizieren, abrufen und verteilen können. Actian Zen läuft auf einer Vielzahl von Betriebssystemen, darunter Windows, Linux, Android, iOS, macOS und virtuellen Maschinen, und ist eine eingebettete Datenbank, die auf Containern und Containern ausgeführt werden kann. Eine AES-Verschlüsselung ist in der Lage, bis zu 128 Bit Daten zu verarbeiten.
Was ist Replikation in der Nosql-Datenbank?
Die Replikation in einer NoSQL-Datenbank bezieht sich auf den Vorgang des Kopierens von Daten aus einer primären Datenbank in eine oder mehrere sekundäre Datenbanken. Der Zweck der Replikation besteht darin, die Datenverfügbarkeit sicherzustellen und die Leistung zu verbessern, indem Daten auf mehrere Server verteilt werden. Es gibt verschiedene Replikationsstrategien, die in einer NoSQL-Datenbank verwendet werden können, wie z. B. die Master-Slave-Replikation und die Peer-to-Peer-Replikation. Bei der Master-Slave-Replikation wird die primäre Datenbank als Master und die sekundären Datenbanken als Slaves bezeichnet. Der Master schreibt Daten an die Slaves, die die Daten vom Master lesen. Bei der Peer-to-Peer-Replikation ist jede Datenbank sowohl Master als auch Slave, und Daten werden zwischen den Datenbanken in beide Richtungen repliziert. NoSQL-Datenbanken bieten normalerweise eine hohe Verfügbarkeit durch die Verwendung von Replikation. Wenn beispielsweise ein Datenbankserver ausfällt , kann von einem anderen Server immer noch auf die Daten zugegriffen werden.
Die Möglichkeit, Daten zu replizieren, ermöglicht es Ihnen, die Datenverfügbarkeit zu erhöhen, indem Sie sie serverübergreifend replizieren. Eine Schreiboperation wird an den primären Server (Knoten) gesendet und auf die Daten auf sekundären Servern angewendet. Es ist notwendig, MongoDB auf drei oder mehr Knoten zu installieren, damit es in MongoDB repliziert werden kann. Legen Sie den Namen des Ports Ihrer Mongod-Instanz (für Remote-Clients) und den Namen ihrer IP-Adresse (für lokale Clients) mit den Befehlszeilenoptionen –replSet und –bind_ip fest. Wenn Sie die vollständige rs.initiate()-Funktion in der Mongo-Shell ausführen, ruft sie das Replikatsatzmitglied 0 auf. Es kann jeweils nur eine Kopie des Replikatsatzes ausgeführt werden, und nur die erste Kopie muss ausgeführt werden. Die Tools auf Systemebene können Ihnen helfen, mehr über Replikation und Sharding zu erfahren.
Es ist möglich, dass lang andauernde primäre Operationen Replikationen verhindern. Sie sollten erwägen, eine Mehrheitsanforderung zu schreiben, um sicherzustellen, dass große Vorgänge ordnungsgemäß repliziert werden. Sie replizieren einen Pizzakuchen auf jedem Server, genau wie Sie es alleine tun würden. Sie können Pizzastücke per Sharding an mehrere Replikat-Sets senden. Dadurch sind selbst die empfindlichsten Teile des Pizzakuchens zugänglich. MongoDB Atlas ermöglicht auch die Bereitstellung global verteilter Replikate. Es rationalisiert und automatisiert Ihre Replikatsätze und macht den Prozess für Sie viel einfacher.
Bei der nicht transaktionalen Datenbankreplikation werden Daten aus einer primären Datenbank auf eine Replikatinstanz repliziert, Änderungen werden jedoch nicht in der Reihenfolge repliziert, in der sie in der primären Datenbank auftreten. Eine nicht- transaktionale Replikationsstrategie wird verwendet, um die Leistung zu steigern. Wenn es um die Replikation Ihrer Datenbank geht, können Sie entweder die Transaktionsreplikation oder die Nicht-Transaktionsreplikation verwenden. Wenn Änderungen an der Datenbank vorgenommen werden, wird sie mithilfe der Transaktionsreplikation in Echtzeit repliziert. Dadurch wird sichergestellt, dass die Datenkonsistenz gewährleistet ist. Bei einer nicht transaktionalen Replikation werden Änderungen, die in der primären Datenbank vorgenommen werden, nicht in der gleichen Reihenfolge repliziert wie die in der Replikatinstanz vorgenommenen. In diesem Fall kann die Replikation beschleunigt werden, ist aber möglicherweise nicht so konsistent.
Warum ist Nosql flexibler?
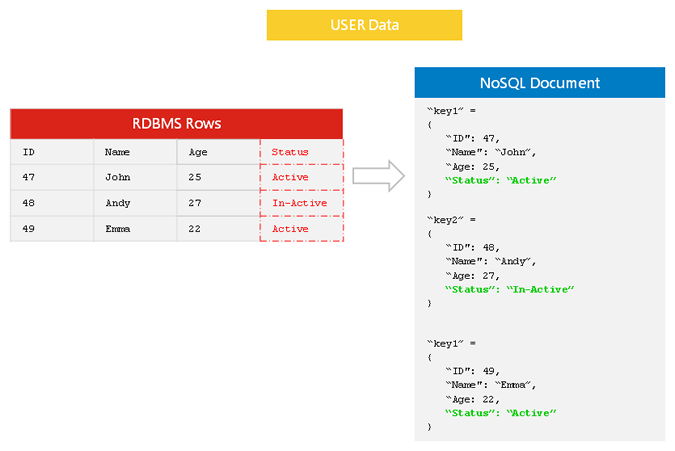
Es gibt viele Gründe, warum NoSQL-Datenbanken flexibler sind als ihre SQL-Pendants. Zum einen benötigen NoSQL-Datenbanken kein festes Schema, was bedeutet, dass sie Änderungen an Ihren Daten leichter aufnehmen können. Darüber hinaus sind NoSQL-Datenbanken im Allgemeinen skalierbarer als SQL-Datenbanken, was bedeutet, dass sie größere Datenmengen effizienter verarbeiten können. Schließlich sind NoSQL-Datenbanken oft performanter als SQL-Datenbanken, was bedeutet, dass sie einen schnelleren Zugriff auf Daten bieten können.

Die Möglichkeit, Daten in einer NoSQL-Datenbank zu kontrollieren und zu manipulieren, wird mit zunehmender Popularität immer wichtiger. Es ist ideal für Anwendungen, bei denen große Datenmengen verarbeitet werden müssen, ohne dass ein strenges Schema befolgt werden muss.
Was kann der häufigste Grund für die Verwendung einer Nosql-Datenbank sein?

Aus den folgenden Gründen können NoSQL-Datenbanken für Sie geeignet sein: zum Speichern großer Datensammlungen, bei denen es sehr unwahrscheinlich ist, dass sie strukturiert sind. Eine NoSQL-Datenbank kann eine Vielzahl von Datentypen unterstützen und ermöglicht es Ihnen, Datentypen entsprechend Ihren Anforderungen zu ändern.
Da NoSQL-Datenbanken geschäftskritische Anwendungen verarbeiten können, ist der Markt dafür gewachsen. Eine NoSQL-Datenbank speichert Informationen anders als eine relationale Datenbank, die auf einer festen Tabelle gespeichert ist. Um das Erlebnis einer App zu personalisieren, muss sie eine große Datenmenge verarbeiten und die Benutzereinstellungen müssen ständig geändert werden. Es ist nicht möglich, das Volumen, die Geschwindigkeit oder die Vielfalt von Sensordaten in einer relationalen Datenbank zu handhaben. Eine NoSQL-Datenbank kann die Daten von Millionen angeschlossener Geräte gleichzeitig verarbeiten. Muss für jede Web- und Mobile-App eine NoSQL-Datenbank entworfen werden? Wenn Ihre Anwendung jedoch der anderer Entwickler ähnelt, sollte NoSQL in Betracht gezogen werden.
NoSQL-Datenbanken bieten mehr Flexibilität in ihren Schemas, da sie sich an sich ändernde Datenumgebungen anpassen können. Aufgrund des vordefinierten Schemas sind Daten in einer relationalen Datenbank häufig auf schwer manipulierbare Weise strukturiert. Eine NoSQL-Datenbank hingegen bietet mehr Flexibilität bei der Speicherung von Daten, sodass sich Anwendungen bei Bedarf schnell an neue Informationen anpassen können. Darüber hinaus können NoSQL-Datenbanken keine Transaktionen unterstützen, was den Umfang einiger Anwendungen einschränken kann. Das Problem kann durch die Verwendung einer relationalen Datenbank gemildert werden, die komplexe Transaktionen verarbeiten kann. NoSQL-Datenbanken bieten im Allgemeinen ein flexibleres Schema, das für sich ändernde Datenumgebungen geeignet ist, während relationale Datenbanken ein traditionelleres Schema bieten, das stabiler ist.
Nosql Read Replica
Nosql-Datenbanken werden oft verwendet, um große Datenmengen zu speichern, auf die schnell zugegriffen werden muss. Eine Nosql-Read Replica ist eine Kopie einer Nosql-Datenbank, die zur Verbesserung der Leistung verwendet wird, indem sie eine Möglichkeit bietet, Daten schnell aus der Datenbank zu lesen.
Daten können ohne Verwendung von Syntax- oder Formbeschränkungen in NoSQL-Datenbanken verwaltet werden. Selbst wenn Sie Ihre Daten in einer nicht-relationalen Datenbank speichern, können Sie sie problemlos skalieren. Ebenso ist die NoSQL-Datenreplikation eine robuste Funktion, mit der Sie Ihre strukturierten, unstrukturierten und halbstrukturierten Daten nahtlos kopieren und speichern können. Mit Hevo können Sie Geld und Zeit sparen, indem Sie Daten in Minuten statt in Stunden replizieren. Die Geschwindigkeit, Einfachheit und Zuverlässigkeit von Hevo machen es zur einfachsten, einfachsten und zuverlässigsten Datenreplikationsplattform. Die robuste > integrierte Transformationsschicht von Hevo ermöglicht es Ihnen, granulare Rohdaten zu verarbeiten und anzureichern, ohne Code schreiben zu müssen. Dokumentendatenbanken in NoSQL haben eine ähnliche Funktion wie Key-Value-Datenbanken, da sie über die Dokumente selbst mit bestimmten Schlüsseln verknüpft sind.
Mehrere Zeilen können in Spaltenfamilien-NoSQL-Datenbanken unterschiedliche Spalten enthalten, und Sie können sogar jeder Zeile jederzeit Spalten hinzufügen. Mit der automatisierten No-Code-Plattform von Hevo Data erhalten Sie alles, was Sie zum Replizieren von Daten benötigen. Ein Master-Slave-Ansatz zum Replizieren Ihrer NoSQL-Datenbanken bietet mehrere Vorteile. Eine Peer-to- Peer-NoSQL-Datenreplikationstechnik hat zusätzlich zu den oben aufgeführten Nachteilen eine Reihe von Nachteilen. Eine der häufigsten Anwendungen von No-SQL-Datenbanken ist die Identitätsprüfung und Betrugserkennung. Die No SQL-Plattform bietet E-Commerce-Unternehmen eine robuste Möglichkeit, Produkt- und Marketingdaten zu speichern. Keine SQL-Datenreplikation ist eine beliebte und äußerst nützliche Technik, die Unternehmen zum Replizieren von Daten verwenden. Bevor Sie Abfragen ausführen oder Datenanalysen für Ihre Rohdaten durchführen können, müssen Sie sie zunächst in ein Data Warehouse exportieren. Mit Hevo Data können Sie Ihre Datenübertragungsprozesse automatisieren, sodass Sie sich auf andere Aspekte Ihres Unternehmens wie Analytik, Kundenmanagement usw. konzentrieren können.
Was macht Key-Value-Nosql-Datenbanken leistungsfähig für grundlegende Crud-Operationen?
Es gibt viele Gründe, warum Schlüsselwert-NoSQL-Datenbanken für grundlegende CRUD-Vorgänge leistungsfähig sind. Ein Grund dafür ist, dass Schlüsselwertdatenbanken hochgradig skalierbar sind. Sie können sehr effizient mit großen Datenmengen umgehen. Ein weiterer Grund ist, dass Key-Value-Datenbanken sehr schnell sind. Sie können Daten schnell und einfach abrufen. Schließlich sind Key-Value-Datenbanken sehr flexibel. Sie können für eine Vielzahl von Datentypen und Datenstrukturen verwendet werden.
Nicht relationale Datenbanken (NoSQL) sind solche, die keine feste Struktur haben und daher nicht auf einzuhaltende Beziehungen angewiesen sind. Schlüsselwertspeicher, spaltenorientierte, dokumentbasierte, Graph- und Graphdatenbanken sind die vier Haupttypen von Datenbanken. Als eine der am wenigsten komplexen Arten von NoSQL-Datenbanken ist eine Key-Value-Datenbank eine gute Wahl. Es kann zum Speichern, Abrufen und Entfernen von Daten auf sehr einfache Weise verwendet werden. Datenbankabfragesprachen, die in Schlüsselwertspeicher-Datenbanken verwendet werden, werden von ihnen nicht unterstützt. Die Daten sind nicht eindeutig und werden durch die Anforderungen der Anwendung bestimmt, die sie verarbeitet. Eine Schlüsselwertdatenbank wird verwendet, um Anmeldungen in Anwendungen aufzuzeichnen, die diese erfordern.
Eine weitere Option ist ein Warenkorb, der Daten über einzelne Online-Einkäufe speichert, was ein spezialisierterer Anwendungsfall ist. Es ist von Vorteil, Key-Value-Stores in der Weihnachtszeit sowie während Schlussverkäufen und Sonderaktionen skalieren zu können. Darüber hinaus verhindert es mit seiner eingebauten Redundanz, dass Artikel im Warenkorb verloren gehen. Schlüsselwertdatenbanken sind spezifisch für einen bestimmten Zweck und verfügen über Funktionen, die einigen einen Mehrwert verleihen, anderen jedoch Einschränkungen auferlegen.
Konsistenz in Nosql
Daher haben NoSQL-Datenbanken eine gewisse Konsistenz, um breiter verfügbar zu sein. Anstatt eine starke Konsistenz bereitzustellen, bieten sie eine langfristige Konsistenz. Mit anderen Worten, ein Datenspeicher, der die Integrität eines Datensatzes garantiert, kann es gelegentlich versäumen, die Ergebnisse des letzten WRITE zu senden.
Die Implementierung eines Dokumentendatenspeichers ist weitaus schwieriger zu beheben als die Implementierung eines relationalen Modells. Ebenso ist das Refactoring der Daten eines Bordspeichers viel schwieriger als das einfache Transformieren von RDBMS-Daten in ein neues Format. Entwickler und Architekten, die das nicht verstehen oder Angst haben, ihren Job zu verlieren, wenn sie einen Fehler machen, können an dieser Gelegenheit nicht teilnehmen. Am Ende zerlegen sie atomare Transaktionen in Transaktionsreihen und ignorieren die Tatsache, dass Replikation und Latenz tatsächlich Funktionen sind und dass Drittsysteme in die Mischung hineingezogen werden. Das gesamte System wird schließlich auslaufen, und die Abteilung wird ausgelagert, damit sie von jemand anderem gewartet wird.