
Warum Nosql-Datenbanken skalierbarer sind als relationale Datenbanken
Veröffentlicht: 2022-11-17Nosql-Datenbanken sind aus mehreren Gründen skalierbarer als ihre relationalen Gegenstücke. Erstens sind nosql-Datenbanken so konzipiert, dass sie von Grund auf verteilt werden können, was bedeutet, dass sie von Natur aus skalierbarer sind. Zweitens verwenden nosql-Datenbanken im Allgemeinen einfachere Datenmodelle als relationale Datenbanken , was sie skalierbarer macht. Schließlich sind nosql-Datenbanken in Bezug auf Schema und Datenstruktur tendenziell flexibler, was sie auch skalierbarer macht.
Es ist das System, das sehr große Datenbanken mit extrem hohen Anforderungsraten und sehr geringer Latenz unterstützen kann. Damit eine Website erfolgreich ist, muss sie skalierbar und hochverfügbar sein sowie eine große Benutzerbasis haben. Um mehrere Instanzen gleichzeitig auf Servern laufen zu lassen, wird typischerweise horizontal skaliert.
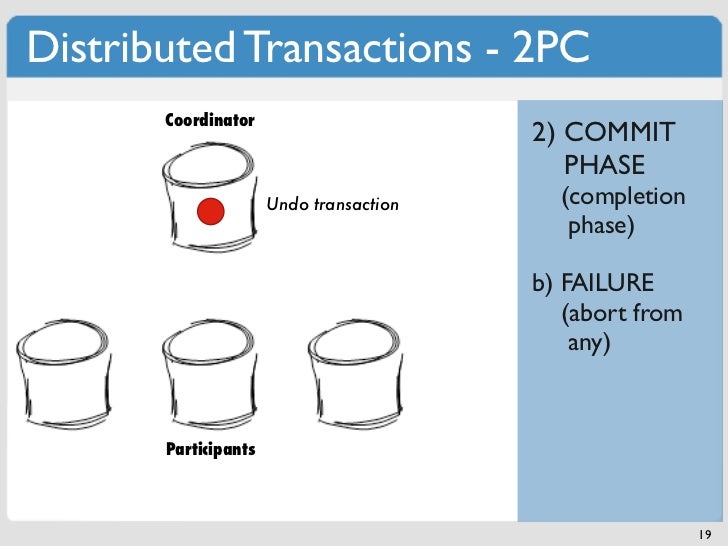
Anstelle des ACID-Modells verwenden NoSQL-Datenbanken normalerweise das BASE-Modell. Sie bieten Skalierbarkeit im Austausch für den Verzicht auf A-, C- und/oder D-Anforderungen. Wenn Sie die Garantien von ACID wünschen, können Sie sich in einigen Fällen dafür anmelden, z. B. bei Cassandra. Obwohl NoSQL-Datenbanken in der Regel skalierbarer sind, erreichen sie dies nicht immer.
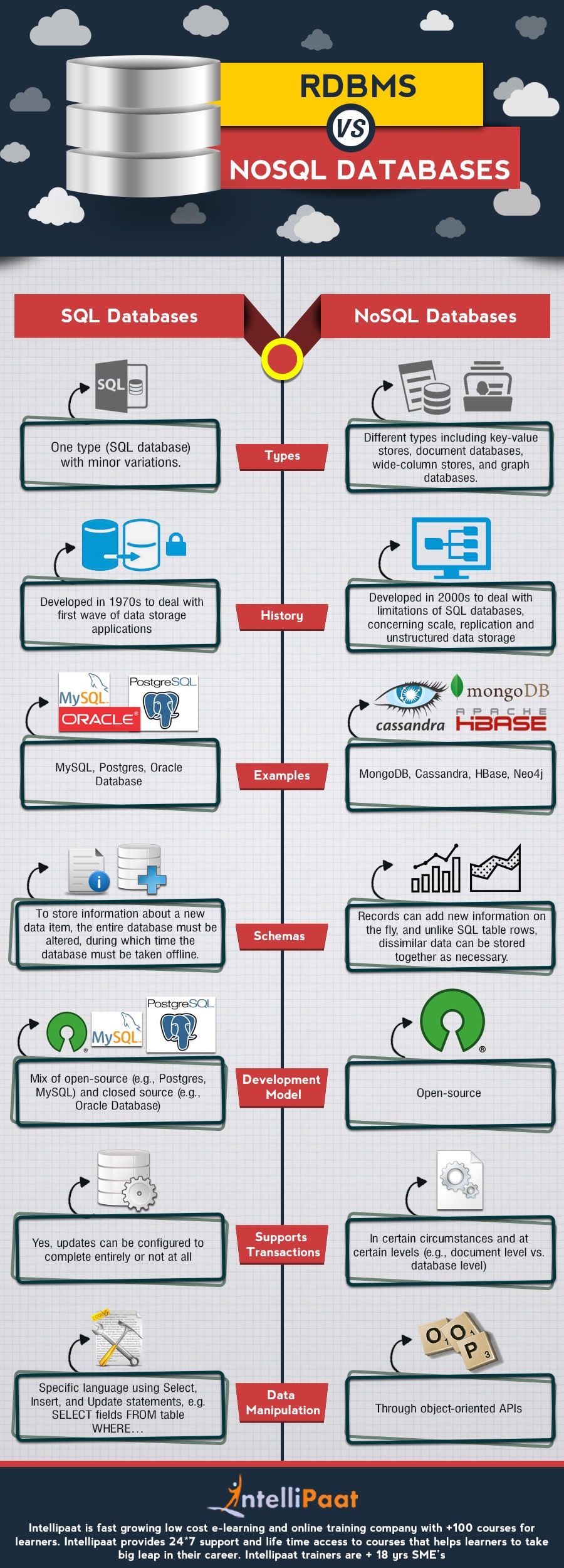
SQL-Datenbanken können wie NoSQL-Datenbanken horizontal skaliert werden, während NoSQL-Datenbanken vertikal skaliert werden können. Datenbankarchitekturen unterscheiden sich zwischen SQL- und NoSQL-Datenbanken darin, dass SQL-Datenbanken tabellenbasiert sind, während NoSQL-Datenbanken dokumentbasierte, Schlüsselwert-, Diagramm- oder Wide-Column-Datenbanken sind. Datenbank NoSQL eignet sich besser für unstrukturierte Daten wie Dokumente oder JSON, während SQL-Datenbanken besser für mehrzeilige Transaktionen geeignet sind.
Mit NoSQL hingegen können Sie reale Web- und Geschäftsanwendungen horizontal skalieren. Apache HBase, MongoDB und Cassandra sind einige der beliebtesten NoSQL-Datenbanken .
Warum sind Nosql-Datenbanken skalierbarer?
Nosql-Datenbanken sind im Allgemeinen skalierbarer als ihre SQL-Gegenstücke, da sie für die Arbeit mit großen Datenmengen ausgelegt sind. Sie sind auch in Bezug auf das Schema flexibler, was bedeutet, dass sie mehr Datentypen und -strukturen verarbeiten können. Schließlich sind nosql-Datenbanken oft so konzipiert, dass sie verteilt werden können, was bedeutet, dass sie auf mehrere Server verteilt werden können, was die Skalierbarkeit weiter verbessern kann.
Es wird immer wichtiger, dass Anwendungen skalierbar sind. Ebenso wichtig ist es, einen Datenspeicher zu haben, der schnell und effizient skaliert werden kann. Ist es in der Hauptdebatte besser, eine „ASL“- oder eine „NoSQL“-Datenbank zu verwenden? SQL-Datenbanken gibt es schon lange, während NoSQL-Datenbanken für ihre einfache Skalierbarkeit bekannt sind. Die Annahme, dass NoSQL-Datenbanken nur in bestimmten Operationen geshardet werden können, ist ihrem Design inhärent. Die Datenbank erwartet jedes Mal, wenn sie eine Datenoperation ausführt, eine Qualifizierung, um den Knoten zu identifizieren, in dem sich Daten befinden. Die Tatsache, dass Daten auf mehreren Maschinen gespeichert werden, macht es sehr einfach, die Datenoperationen selbst auf den ineffizientesten Maschinen auszuführen.
Dadurch können NoSQL-Datenbanken mit einfachen Commodity-Maschinen skaliert werden. Bei der Verwendung eines NoSQL-Systems wird davon ausgegangen, dass der Benutzer die Daten so plant und strukturiert, dass alle erforderlichen Daten für einen bestimmten Vorgang gleichzeitig abgerufen werden können. Das Ziel der Denormalisierung der Daten besteht darin, eine Beschädigung zu vermeiden (vorgekochte Daten für den Betrieb). Es wird nicht erwartet, dass Joins in NoSQL funktionsreich oder optimiert sind, obwohl sie möglich sind. In der Praxis gehen NoSQL-Anwendungen davon aus, dass die Daten im Laufe der Zeit konsistent sind. Viele NoSQL-Systeme bieten aus Konsistenzgründen auch Schalter, um die Konsistenz im gesamten System anzupassen. Bei der Auswahl einer Architektur ist es ein wichtiger Bestandteil, den Anwendungsfall zu bewerten und darauf basierend den geeigneten Datenspeicher auszuwählen.
Dokumentendatenbanken sind eine gute Wahl für Anwendungen mit horizontaler Skalierung, da sie auf mehrere Knoten verteilt werden können. Die Daten sind in MongoDBs eigenständigen MongoDB-ähnlichen Dokumenten untergebracht, bei denen es sich um JSON-ähnliche Dateien handelt. Dadurch kann auf mehrere Knoten einfach zugegriffen werden, indem die Dokumente über einen horizontalen Skalierungsbereich verteilt werden. MongoDB ist auch aufgrund der Verwendung von Sharding-Clustern, die die Übertragung von Daten zwischen mehreren Knoten ermöglichen, äußerst robust. Eine NoSQL-Datenbank hat neben ihren flexiblen Datenmodellen, horizontaler Skalierung, blitzschnellen Abfragen und Benutzerfreundlichkeit zahlreiche Vorteile. Dokumentdatenbanken, Schlüsselwertdatenbanken, Wide-Column-Stores und Graphdatenbanken sind nur einige der Arten von NoSQL-Datenbanken. Eine NoSQL-Datenbank ist ideal für Anwendungen, die eine horizontale Skalierung erfordern, da sie einfach auf mehrere Knoten verteilt werden kann. MongoDB ist eine ausgezeichnete Wahl für Anwendungen, die eine horizontal skalierbare Plattform erfordern, da sie einfach auf mehrere Plattformen verteilt werden kann.
Wie ist die Nosql-Datenbank skalierbar?
Eine NoSQL-Datenbank hingegen ist horizontal skalierbar, was bedeutet, dass sie einen erhöhten Datenverkehr bewältigen kann, indem sie weitere Server hinzufügt. NoSQL-Datenbanken sind nicht nur größer und leistungsfähiger, sondern können auch für große oder sich ständig ändernde Datensätze verwendet werden.
Wie Rahim Yaseen von Couchbase erklärt, können wir ein Verständnis für mehrere entscheidende Konzepte gewinnen. Angesichts der explosionsartigen Zunahme von Daten suchen Unternehmen zunehmend nach Möglichkeiten, diese zu verwalten, zu speichern und Wert daraus zu ziehen. Soll ich meine Datenbank vergrößern oder verkleinern? Ein manuelles Sharding-System ermöglicht die Verteilung von Registrierungsinformationen über eine Reihe von Check-in-Schaltern. Es funktioniert, weil es eine gute Vorstellung davon gibt, wie das Schema aussehen wird. Infolgedessen müssten Sie im Falle von Autosharding zu jeder Kabine gehen, um herauszufinden, wer mit dem Nachnamen S eingecheckt hat. Muster für den direkten Zugriff auf Schlüssel in einer Dokumentendatenbank erfordern normalerweise den Zugriff auf ein bestimmtes Dokument über einen einzigen Schlüssel, wie z sowie die Möglichkeit, über eine zugehörige Taste zu einem anderen Dokument zu navigieren. Um diese Aufgabe zu erfüllen, ist es unerlässlich, eine große Anzahl von Datensätzen zu indizieren und abzufragen.
Da jeder Knoten an der Abfrageausführung teilnehmen muss, ist die Implementierung einer Map-Reduce-Technik sinnlos. Wenn das Datenvolumen wächst, wird die Skalierung im RDBMS-Stil immer weniger effektiv. Eine Scale-up-Architektur, die einen großen Datensatz untermauert, ist höchstwahrscheinlich zum Scheitern verurteilt, ebenso wie ein einzelner sehr großer Fehlerpunkt. Das Internet ist ein hervorragendes Beispiel für einen Shared-Nothing-Cluster, der extrem groß und extrem verteilt ist.
Die vertikale Skalierung kostet mehr und ist in einigen Fällen möglicherweise nicht erforderlich. Da Probleme auf eine größere Anzahl von Maschinen verteilt werden können, ist die horizontale Skalierung kostengünstiger.
Es ist entscheidend, die richtige Skalierungslösung auszuwählen, um Leistungsprobleme, erhöhte Komplexität und Datenverluste zu vermeiden, die aus falschen Skalierungsentscheidungen resultieren könnten.
Wann sollte ich skalieren?
Es gibt mehrere Faktoren, die zu berücksichtigen sind, bevor Sie entscheiden, ob Sie skalieren möchten oder nicht. Das erste, was Sie wissen sollten, ist, mit wie vielen Daten Ihre Anwendung umgeht. Eine einzelne Datenbankmaschine kann eine relativ große Datenmenge verarbeiten, wenn die Daten relativ klein sind. Ein größeres Datenvolumen führt voraussichtlich auch zu einem größeren Verarbeitungsaufwand, der für die Ausführung der Anwendung erforderlich ist, und der Computer kann es möglicherweise nicht mehr verarbeiten.
Wenn die Daten relativ klein sind, kann die Last von einer einzigen Datenbankmaschine gehandhabt werden.
Wann sollten Sie eine Skalierung in Betracht ziehen?
Wenn Sie ein Problem haben, das durch Aufteilen einer großen Anzahl von Computern in kleinere gelöst werden kann, ist Scale-out möglicherweise die beste Option für Sie. Wenn Sie eine Website haben, die viele Server benötigt und nicht über genügend CPU oder RAM verfügt, um alle in Ihrem Rechenzentrum unterzubringen, können Sie möglicherweise weitere Server zu Ihrem Rechenzentrum hinzufügen und diese die Last bewältigen lassen.
In bestimmten Situationen kann es kosteneffektiver sein, die Anzahl der Server in Ihrem Rechenzentrum zu erhöhen, z. B. beim Umgang mit einer großen Anzahl von Computern, die verteilt sein können.

Skalierung Ihres Servers: Die Vor- und Nachteile der vertikalen und horizontalen Skalierung
Die vertikale Skalierung ist normalerweise teurer, wodurch es schwierig wird, das gleiche Leistungsniveau zu erreichen. Obwohl die horizontale Skalierung im Allgemeinen effizienter ist, kann sie schwieriger einzurichten sein.
Warum sind Nosql-Datenbanken besser?

Nosql-Datenbanken werden aus einer Reihe von Gründen oft als besser angesehen als ihre relationalen Gegenstücke. Erstens sind sie im Allgemeinen viel einfacher einzurichten und zu verwenden – es ist kein kompliziertes Schemadesign oder objektrelationales Mapping erforderlich. Zweitens sind sie hochgradig skalierbar und können problemlos mit großen Datenmengen umgehen. Schließlich sind sie in Bezug auf die Datenmodellierung tendenziell flexibler, was das Speichern und Abfragen komplexer Datenstrukturen erleichtert.
Die NoSQL-Datenbankbranche wuchs in den späten 2000er Jahren mit einem Fokus auf Skalierung, schnellen Abfragen und einfacherer Programmierung. Die Flexibilität von NoSQL-Datenbanken sowie ihre Fähigkeit, horizontal zu skalieren und flexible Datenmodelle aufzunehmen, machen sie ideal für Entwickler. SQL-Datenbanken (Structured Query Language) sind bekannt für ihre starren, komplexen und tabellarischen Schemata sowie für hohe vertikale Skalierungsanforderungen. In der Version 4.0 fügte MongoDB ACID-Transaktionen für mehrere Dokumente hinzu, und in der Version 4.2 erweiterte MongoDB die Unterstützung auf geteilte Cluster. Nr. 1 enthält Datenmodelle. Daten in NoSQL-Datenbanken werden in der Regel eher für Abfragezwecke als für die Datenduplizierung optimiert.
Die Komprimierung ist auch in einigen Nr. NoSQL-Datenbanken verfügbar, um den Speicherbedarf zu reduzieren. Graph-Datenbanken können zum Beispiel für die Analyse von Beziehungen nützlich sein, aber sie liefern möglicherweise nicht genügend Informationen für den täglichen Gebrauch. Wenn Sie nach einer Datenbank für einen bestimmten Anwendungsfall suchen, kann Ihnen das Whitepaper Where to Use MongoDB dabei helfen, herauszufinden, welche Datenbank die richtige für Sie ist. MongoDB Atlas ist eine großartige NoSQL-Datenbank für den Anfang, da sie eine der am einfachsten zu verwendenden ist. Mit der MongoDB University, die völlig kostenlose Online-Schulungen anbietet, können Sie MongoDB in nur 24 Stunden erlernen.
Nosql bietet eine andere Art der Datenverarbeitung
Es ist vorzuziehen, NoSQL zum Speichern und Verwalten von Daten zu verwenden. Die Einfachheit und Skalierbarkeit dieser Anwendung machen sie ideal für den Einsatz. Eine NoSQL-Datenbank ist zuverlässiger und hat eine bessere Zugänglichkeit.
Nosql vs. Sql-Skalierbarkeit
SQL-Datenbanken sind vertikal skalierbar, was bedeutet, dass sie durch Hinzufügen weiterer Ressourcen (CPU, Arbeitsspeicher usw.) zu einem einzelnen Server skaliert werden können. NoSQL-Datenbanken sind horizontal skalierbar, was bedeutet, dass sie durch Hinzufügen weiterer Server skaliert werden können.
Es kann schwierig sein, zwischen der Vielzahl der heute verfügbaren Datenbanksysteme zu unterscheiden. Der DBA sollte mit den Unterschieden zwischen SQL, NoSQL und einzelnen DBMS vertraut sein. Im Allgemeinen verlassen sich NoSQL-Datenbanken, denen relationale Eigenschaften fehlen, nicht auf herkömmliche RDBMSs. Die beiden Produkte weisen fünf Hauptunterschiede sowie einige wichtige Unterschiede auf, die sie voneinander unterscheiden. Die Master-Slave-Architektur von NoSQL-Datenbanken skaliert horizontaler mit zusätzlichen Servern oder Knoten. Gemäß dem CAP-Theorem, das besagt, dass in jeder verteilten Datenbank nur zwei der folgenden Eigenschaften gleichzeitig garantiert werden können: Es ist entscheidend, die Gemeinschaft zu unterstützen und zu unterstützen. SQL-Datenbanken gibt es schon seit langer Zeit, sie sind bekannt und haben eine lange Erfolgsbilanz in Bezug auf Zuverlässigkeit.
NoSQL-Datenbanken sind nicht so sicher wie relationale Datenbanken, da sie weniger Datenstrukturen enthalten. Sie sind jedoch skalierbarer, wodurch sie immer beliebter werden. Trotz ihrer Sicherheit sind relationale Datenbanken möglicherweise nicht für jede Anwendung die beste Wahl.
Skalierbarkeit relationaler und nicht relationaler Datenbanken
Die Datenbankskalierung ist in nicht-relationalen Datenbanken wie Dokumentendatenbanken anders als in relationalen Datenbanken, die nur vertikal skaliert werden können (CPU, Festplattenspeicher usw.). Bei der Datenbankreplikation werden mehrere Datenbanken auf mehreren Servern erstellt, wodurch die Daten synchron bleiben.
In seiner Forschungsarbeit A Relational Model of Data for Large Shared Data Banks aus dem Jahr 1970 prägte EF Codd von IBM den Begriff „relationale Datenbank“. Die Schlüssel werden verwendet, um Informationen aus mehreren Tabellen in einer relationalen Datenbank zu verknüpfen. Microsoft SQL Server, Oracle Database, MySQL und IBM DB2 sind die weltweit am häufigsten verwendeten Datenbanken. Die Verwendung eines relationalen Datenbankmanagementsystems (RDBMS) ist eine hervorragende Möglichkeit, Ihre Daten genau und konsistent zu halten. Um ferentielle Integrität zu erreichen, müssen sowohl eine Primär- als auch eine Fremdschlüsselbeziehung verwendet werden. Ein Datensatz muss unabhängig davon gelöscht werden, ob er sich auf einen Primärschlüssel oder einen anderen Datensatz bezieht. Dadurch wird verhindert, dass ein verwaister Datensatz gespeichert wird.
Tabellen, Zeilen, Primärschlüssel oder Fremdschlüssel können in einer nicht relationalen Datenbank nicht gefunden werden, wie dies in einer relationalen Datenbank der Fall ist. Im Gegensatz dazu verwendet eine NoSQL-Datenbank ein optimiertes Speichermodell für die Art der zu speichernden Daten. Dokumentdatenspeicher, Spaltendatenspeicher, Schlüsselwertspeicher, Diagramm-, Index- und Diagrammdatenbanken sind die am häufigsten verwendeten NoSQL-Datenbanken. Eine Graphdatenbank soll das Speichern von Informationen zwischen Entitäten vereinfachen. Object-Relational Mapping (ORM) ist eine neue Funktion, die in NoSQL-Datenbanken als Ersatz für Structure Query Language (SQL) eingeführt wurde. Eine Reihe von NoSQL-Sprachen sind verfügbar, darunter Java, Javascript,. NET und PHP.
Es ist aus zwei Gründen wichtig, zwischen zwei Arten von Datenbanken zu unterscheiden: ihrem Nutzen an sich und den Anwendungsfällen, denen sie dienen. Keine Datenbank ist besser als die andere, aber keine hat das Monopol darauf, besser als die andere zu sein. Berücksichtigen Sie bei der Auswahl eines Datenbanktyps für Ihr Projekt die Anforderungen der Organisation sowie die Funktionalität ihrer Anwendung.
Cassandra ist eine Architektur, die darauf ausgelegt ist, große Datenmengen mit geringer Latenz zu verarbeiten. Cassandra erreicht dies durch die Verwendung eines Ringpuffer-Replikationsschemas. Das Ringpuffer-Replikationsschema in einem System ermöglicht es ihm, Daten zwischen zwei oder mehr Knoten zu replizieren. Das Replikationsschema ermöglicht es dem System, zu wachsen, ohne die Verfügbarkeit von Daten zu beeinträchtigen. Apache Cassandra ist außerdem fehlertolerant ausgelegt. Wenn also ein Knoten ausfällt, kann ein anderer Knoten im System möglicherweise die Daten auf den ausgefallenen Knoten replizieren. Das Ergebnis dieser Fehlertoleranz ist, dass ein System wachsen kann, ohne die Datenverfügbarkeit zu beeinträchtigen. Es handelt sich um eine große und zuverlässige Datenbank, die eine große Anzahl von Transaktionen effizient verarbeiten kann.
Was ist einfacher zu skalieren Rdbms oder Nosql?
Trotz ihrer fehlenden Skalierungsfähigkeiten skalieren RDBMS normalerweise nicht, während neuere NoSQL-Datenbanken neue Knoten nutzen sollen und normalerweise mit Blick auf kostengünstige Standardhardware entwickelt wurden.